DDD의 개념
- 소프트웨어 설계 시 고객의 요구사항을 정확히 이해하는 것이 중요하다.
- 과거에는 기술 중심의 방법론 (메모리, 리소스 관리)이 사용되어 위를 이해하기 어려웠다.
위와 같은 문제점을 해결하기 위해 DDD가 나왔다
도메인 전문가가 참여하여 도메인(이커머스,금융,...) 에 대한 이해를 돕고, 이해관계자들과 개발자까지 모두 지식을 공유, 소통하여 비즈니스와 기술 간의 간극을 좁힌다. 복잡한 시스템에서 발생할 수 있는 문제들을 효과적으로 해결하는 것에 목적을 두고 있다.
- 비즈니스에서 실질적으로 필요한 기능을 구현한다.
유비쿼터스 언어
도메인에서 사용하는 용어를 코드에서 적용한다.
- 전문가, 관계자, 개발자가 도메인과 관련된 공통의 언어를 만들어, 대화, 문서, 도메인 모델, 코드, 테스트 등 모든 곳에서 동일하게 사용하는 것
- 이렇게 새로 발견한 용어는 코드와 문서에도 반영하여 최신의 모델을 유지한다.
- 실무에서
용어 사전과 같은 단어장을 만드는 사례도 많다.
ex) step1, step2 대신 wainting, preparing 등
도메인 모델
- 도메인 주도 설계(DDD)에서 핵심 “개념”을 표현하는 방법
- 특정 문제 영역(도메인)에 대한 지식, 규칙, 그리고 로직을 추상화하여 개념적으로 표현한 것
예를 들어, 전자상거래(E-Commerce) 시스템에서 도메인 모델은 주문, 결제, 배송 같은 개념과 그들 간의 관계를 표현할 수 있습니다.
도메인 모델을 만들기 위해서는 핵심 구성 요소, 규칙, 기능을 파악해야 합니다. 서비스의 요구사항을 분석하고 관련 기능들을 묶으면, 아래와 같은 구조를 만들 수 있습니다.
Entity - Value
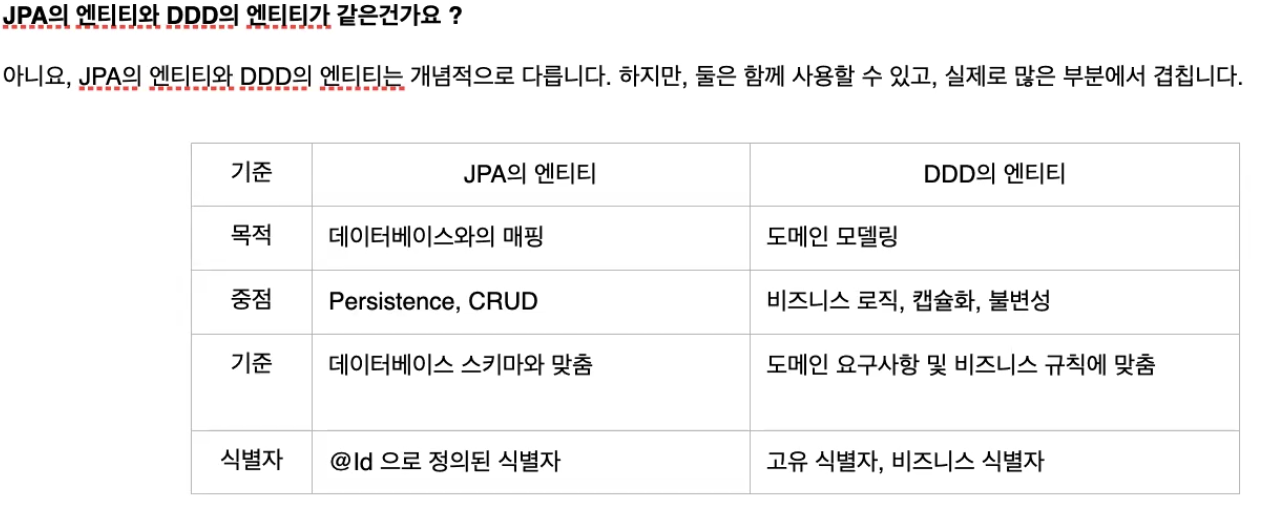
Entity
고유의 식별자 (Id) 를 갖는 객체
자신의 Life Cycle을 갖는다.
데이터 구조 / 데이터와 함께 기능을 제공하는 객체
- 기능을 구현하고, 기능 구현을 캡슐화 하여 데이터가 임의로 변경되는 것을 막을 수 있다.
주문, 회원, 상품 등 도메인의 고유한 개념
=/= JPA의 엔티티 이지만, 많은 부분이 겹친다.
Value
고유의 식별자를 갖지 않는 객체
개념적으로 하나인 값을 표현할 때 사용
엔티티의 속성으로 사용 / 다른 Value 타입의 속성으로 사용
주소, 금액 등의 속성
도메인 서비스
특정 엔티티에 속하지 않는 도메인 로직을 담당
할인 금액 계산 : 상품, 쿠폰, 회원 등급, 금액 등의 다양한 조건을 고려한다.
이 처럼 로직의 주체가 명확하지 않을 경우 도메인 서비스에서 구현
Aggregate (애그리거트)
- 관련된 객체를 모아 하나의 단위로 취급하는 개념 (그룹화)
- 상위 객체의 개념을 파악하고, 코드를 변경 및 확정이 용이하도록 한다.
루트 엔티티
애그리거트에 속한 모든 객체가 일관된 상태를 유지하도록 애그리거트 전체를 관리하는 주체
상위 애그리거트가 없이는 하위 애그리거트가 존재할 수 없다.
- 하나의 애그리거트 : 하나의 루트 엔티티 : N개의 엔티티와 밸류 객체들
- 애그리거트 내의 엔티티, 벨류 객체를 이용해 애그리거트가 수행해야 할 기능들을 제공한다.
Order Entity 내에 addProduct, removeProduct 등의 메서드를 선언하여 OrderProduct (하위 엔티티)에 접근
하위 애그리먼트 하나의 ID에 대해서만 수정이 필요할 경우
1. findById_User_Id 같은 메서드를 사용
2. OneToMany의 관계가 많아지고, N+1의 문제가 발생하거나 쿼리가 너무 길어질 경우 DDD 원칙에서는 좀 벗어나더라도 별도의 애그리먼트로 분리할 수도 있다. 이 경우 트레이드오프 (구현 시 고민해볼 문제)
이를 통해 하위 엔티티들은 루트 엔티티의 라이프 사이클에 따르게 된다.
하위 엔티티의 관리를 위해서는 상위 엔티티에 접근해야 하므로 구현 자체가 캡슐화 된다.
+) JPA에서 JPARepository를 루트 애그리먼트에만 구현하면 된다.
Order 내에서 OrderProduct를 불러오고, Receipt를 불러와서 수정한다.
하위의 Repository를 따로 두어 변경할 수 있게 둘 경우, 수정 가능 로직이 여러 Repository에 나뉘게 되어 캡슐화가 깨진다.
MSA에서의 DDD
- 모놀리식 어플리케이션을 MSA로 전환할 때, 도메인 개념을 기준으로 마이크로 서비스를 구축하게 된다.
- DDD는 도메인 모델을 중심으로 비즈니스 로직을 정의하고, 독립적인 도메인 경계로 나눈다.
- 이 결과 각 마이크로 서비스는 단일 책임 원칙을 따른다.
Repository 패턴
DDD에서는 비즈니스 로직 - 도메인 모델 간의 결합도를 낮추기 위해 repository 패턴을 권장한다.
특정 도메인을 관리하는 메소드를 repository 이름의 클래스로 구성, 특정 도메인의 변경은 특정 repository만을 통해서만 가능하다고 제한한다.
User - UserRepository 사용. User에서 update 수행해도 DB에는 반영되지 않는다.
- Spring JPA에서의 JPARepository와 유사하여 JPA 사용 시 별다른 구성 없이 repository 패턴을 사용할 수 있다.
- JPA를 사용할 경우 DB 테이블에 대한 매핑을 하면서도 도메인 모델의 순수성을 유지할 수 있다.
- 즉, JPA와 DDD는 자연스럽게 어울릴 수 있다. > Entity의 캡슐화만 신경쓰자!
Layered Archtiecture

- 위의 계층에서 아래 계층에는 접근이 가능하지만, 아래에서 위로는 불가능하다.
- 불가피하게 상위 계층의 코드를 사용할 경우의존역전원칙 (DIP)를 사용하여 하위 계층에 의존하지 않도록 개발해야 한다.- 이를 지키지 않을 경우 애그리먼트 단위의 캡슐화 자체가 깨지게 된다.
- 한 계층의 관심사와 관련된 어떤 것도 다른 계층에 배치되어서는 안 된다.
Presentation (표현) (Controller)
사용자 요청에 대해 해석, 응답하는 일을 책임진다.
- 사용자에게 UI를 제공 / 클라이언트에 응답을 다시 보내는 역할을 하는 모든 클래스
- dtos (request, response)
- controllerApplication (응용) (Service)
비즈니스 로직을 정의하고, 정상적으로 수행될 수 있도록 도메인 계층과 인프라 계층을 연결한다.
- 많은 정보를 가지고 있지 않아야한다.
- 실질적인 데이터의 상태 변화는 도메인에서 진행해야 한다.
- DTO 변환 / 트랜잭션의 단위 / 엔티티 조회 및 저장 / 사용자 인증, 인가 (데이터 중복 검증 등 DB와의 대조) / 파라미터 검증
- dtos (base dto)
- serviceDomain (도메인) (Model)
업무 상황을 반영하여 상태를 제어하는 역할에 집중한다.
- entity
- repository
- service (비즈니스 로직이 아닌 도메인 로직)Infrastructure (인프라)
외부와의 통신 (DB, 메시징 시스템 등)을 담당하는 계층이다.
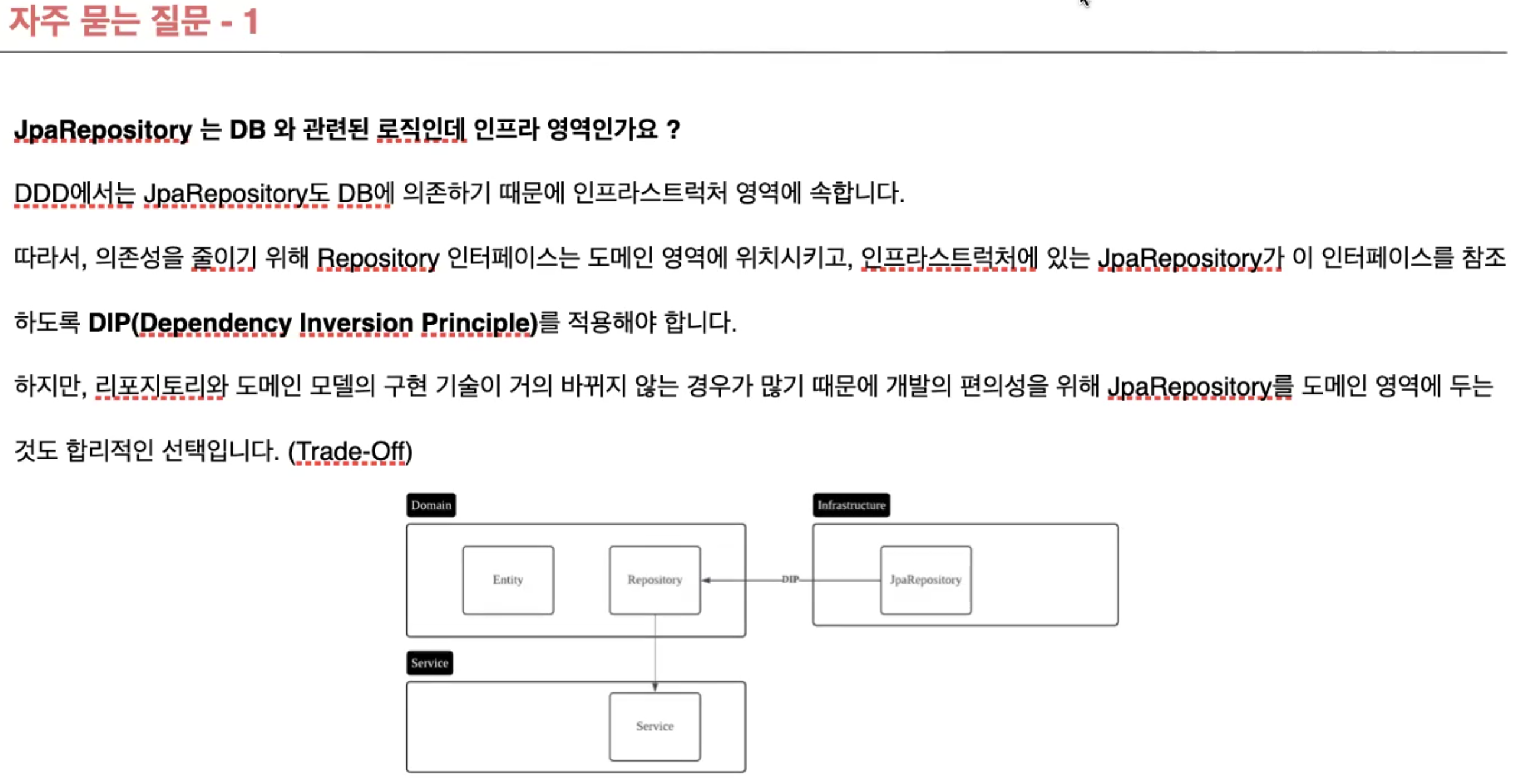
- repository (Impl)repository는 어느 계층에 있어야 할까?
- Domain
-
DDD 원칙 상 시스템이 제공할 도메인 규칙을 정의하고, 실질적인 연동은 Infra에서 처리할 것을 권장한다.
-
그러나 도메인 객체, 엔티티를 각각 만들어줘야 한다는 단점 등으로 인해 편의성을 위해 도메인 계층에서 사용하기도 한다.
- Infra
- infra 계층을 제외한 계층은 특정 기술에 종속적이지 않게 된다.
- java / kotlin의 변경이나 DBMS의 변경 등에 유연하다.
둘 다 배치!
- infra 계층에는 RepositoryIpml을 설정
실질적인 Repository와의 연결은 infra에서 수행 (JPARepository와의 분리)
import com.sparta.ddd.domain.entity.user.User;
import com.sparta.ddd.domain.repository.UserRepository;
import org.springframework.data.jpa.repository.JpaRepository;
//TODO: JpaRepository 를 Interface 계층에 위시시키는 방법
public interface UserRepositoryImpl extends JpaRepository<User, Long>, UserRepository {
// JPA 구현 상 선언해야 할 메소드가 있다면 작성한다.
}- domain에서 Repository 설정
interface로 구현하여 데이터를 다룬다.
import java.util.List;
import java.util.Optional;
//TODO: Interface 계층에 존재하는 JpaRepository 를 분리하기 위한 Interface 구현 예제
@Repository
public interface UserRepository {
List<User> findAll();
Optional<User> findById(Long id);
User save(User user);
}
+) 서비스를 나누는 것이 어려울 경우, 큰 단위로 나눈 뒤 세세하게 나누는 게 좋다.
이후 라이프 사이클 별로 묶는다.
하지만 합친 데이터가 너무 비대해질 경우 작게 다시 나눠야 한다.
예를 들어 업체 - 상품의 경우 업체가 사라지면 상품도 사라지므로, 한 도메인에 묶는다.
허브 - 유저의 경우 생성 주체와 라이프 사이클이 다르므로 다른 도메인에 묶는다.
그러나 허브에 의해서도 상품이 관리되고, 업체에 의해서도 관리될 경우 상품은 어느 하나의 라이프 사이클에 구애받지 않고 오롯이 존재할 수 있으므로 하나의 루트 애그리거트가 될 수 있다.
https://dev-coco.tistory.com/166
https://github.com/Kkaekkae/ddd_lecture_source
https://velog.io/@tlarbals824/%EC%9A%B0%EB%A6%AC%EB%8A%94-DDD%EC%99%80-Layered-Architecture-%EC%9E%98-%EC%93%B0%EA%B3%A0-%EC%9E%88%EB%8A%94%EA%B1%B8%EA%B9%8CJPA%EB%8A%94-Infra-%EA%B3%84%EC%B8%B5%EC%9D%B8%EA%B1%B8%EA%B9%8C
