
Delta Lake란
데이터 레이크 위에 Lakehouse 아키텍처를 구축할 수 있는 오픈소스 프로젝트
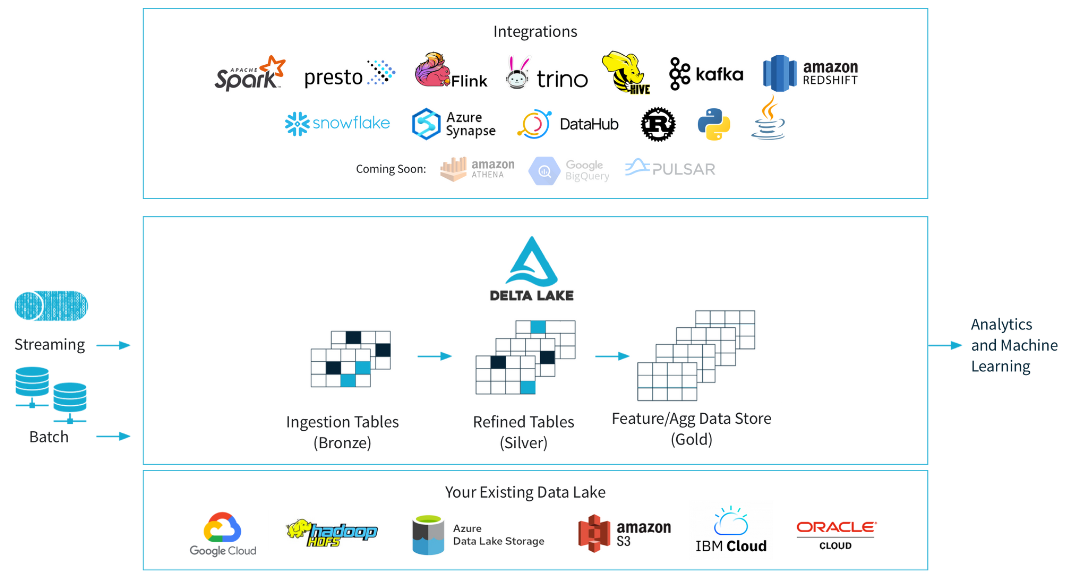 이미지 출처:delta.io
이미지 출처:delta.io
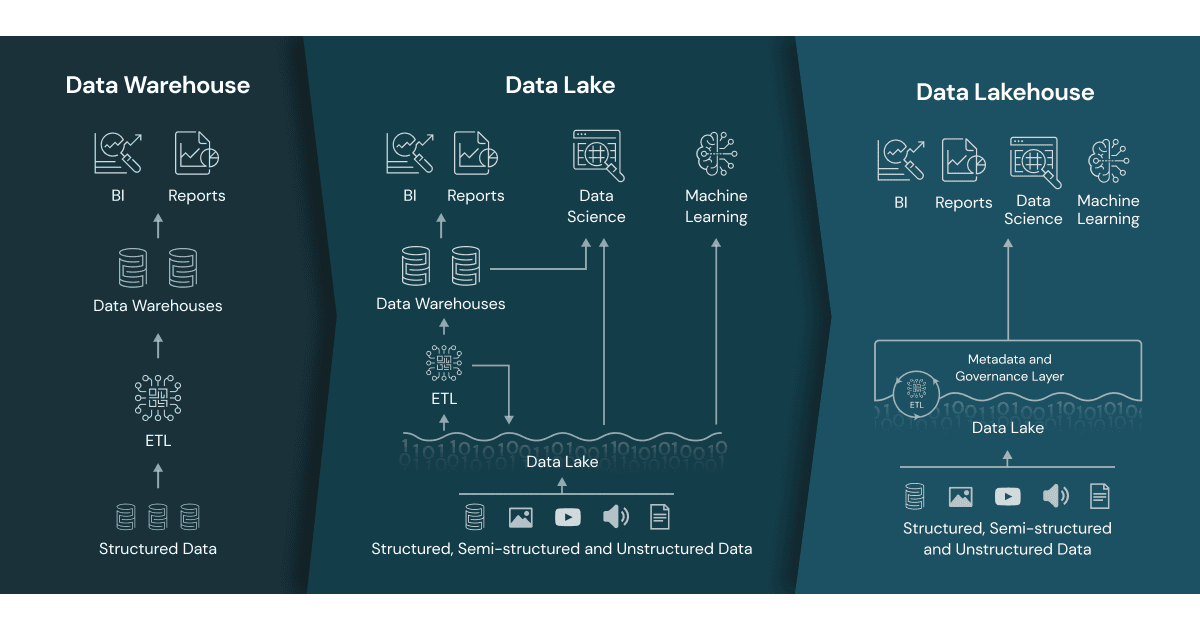
- 아래의 메달리온 아키텍처는 레이크하우스에 논리적으로 데이터를 정리하는 데 사용하는 데이터 설계 패턴
- 이 아키텍처의 목표는 데이터가 아키텍처의 각 레이어를 통과하는 동안(브론즈 ⇒ 실버 ⇒ 골드 레이어 테이블) 데이터의 구조와 품질을 증분적, 점진적으로 개선함
Bronze
- Raw 데이터가 Data Lake Storage에 적재됨.
- 데이터는 Raw 형식으로 가져와서 처리를 위해 개방형 트랜잭션 Delta Lake 형식으로 변환
Silver
- Bronze 의 Raw 데이터를 ETL 및 스트림 처리 작업을 수행
- 데이터를 Silver 큐레이팅 데이터 세트로 필터링, 정리, 변환, 조인, 집계 처리함
- 머신러닝을 지원하며, 데이터 엔지니어, 데이터 사이언티스트가 활용
Gold
- Silver 에서 분석결과를 기준으로 테이블에는 분석과 보고에 사용할 수 있는 풍부한 데이터가 포함
- 고객 분석, 제품 품질 분석, 재고 분석, 고객 세그먼테이션, 제품 추천, 마케팅/영업 분석 등의 비즈니스 레벨의 데이터를 적재
- BI를 연동하여 시각화에 활용
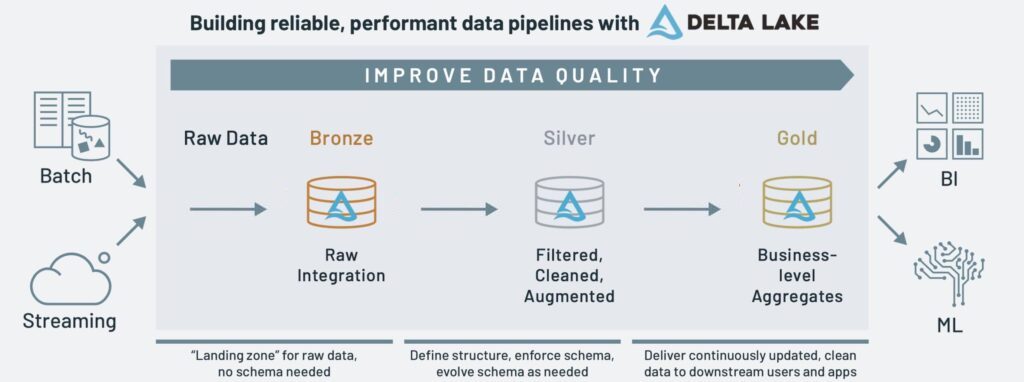
이미지 출처:databricks
기존 문제점
데이터 레이크와 데이터 웨어하우스의 문제점
- 데이터 레이크는 큰 데이터를 저장할 수 있지만 체계가 정확하게 잡히지 않으면 데이터 늪이 되기 쉬움
- 데이터 웨어하우스는 조직 구조에 맞지 않은 데이터는 삭제/변경을 하여 원본데이터가 유지되지 않고 손실됨
S3와 같은 클라우드 스토리지 문제점
- key-value로 구현이 되어있어서 ACID 트랜잭션과 같은 고성능을 구현이 어려움
- listing object와 같은 메타데이터 동작은 비싸며 일관성 보장은 제한적임
스키마 관리의 어려움
- Hive(확장 가능한 분산 데이터 저장소)의 ALTER는 메타데이터만 수정하고, 과거에 저장된 데이터의 구조를 변경하려면 다시 전체 데이터를 새롭게 만들어야함
- 스키마 수정 이후에 처리된 데이터와 과거의 데이터가 불일치하여 데이터의 정합성이 안맞는 경우 발생
- 스키마 변경 이력을 파악이 어려움
Delta Lake 장점
- 위의 문제점에 대해서 ACID 성질을 가질 수 있게 하여 트랜잭션을 제공
- 테이블에서의 시간 여행을 가능
- 기존과 다른 스키마의 데이터가 append 되는 순간 에러를 발생하여 데이터 유입 초기 단계에서 데이터 구조 변화를 확인할 수 있고 빠른 대응이 가능
- upsert를 구현할 수 있고, 아주 큰 데이터에서 쿼리를 빠르게 실행
- 언제든 원시 데이터에서 테이블 생성 가능
성능
전반적인 성능
- 테이블을 로드하고 쿼리하는 전반적인 성능은 Delta가 Iceberg보다 1.7배 , Hudi보다 4.3배 더 빠름
- Delta에 데이터를 로드하고 TPC-DS 쿼리를 수행하는데 1.75시간이 걸렸고 iceberg는 2.97시간 , Hudi는 7.65시간이 소요됨
TPC-DS는 DS(Decision Supporting) 시스템에 최적화 된 데이터셋과 99개의 쿼리를 갖고 있으며 이를 통한 측정하는 표준 벤치 마크
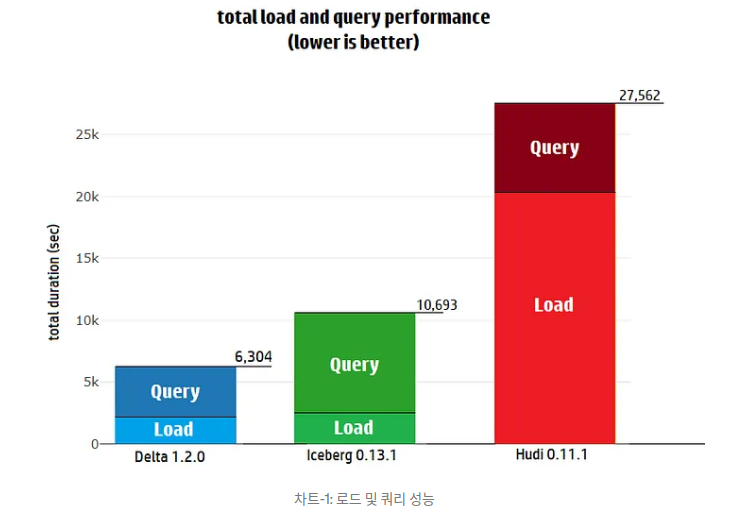
출처) https://databeans-blogs.medium.com/delta-vs-iceberg-vs-hudi-reassessing-performance-cb8157005eb0
설치
환경 : Ubuntu 22.04
개발언어 : Python 3.10.6 , Java-1.17.0-openjdk
JAVA 설치
# sudo apt update
# sudo apt install openjdk-17-jdkJava 를 환경변수로 등록
# vi .bashrc
JAVA_HOME='/usr/lib/jvm/java-1.17.0-openjdk-amd64'
PATH=$PATH:$JAVA_HOME/bin설정이 되었는지 확인
# source ~/.bashrc
# echo $PATH
/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/lib/jvm/java-1.17.0-openjdk-amd64/bindelta lake 설치
# pip install delta-spark==2.2.0예시
테이블생성
• delta.compatibility.symlinkFormatManifest.enabled=true 으로 설정해주면 데이터 insert가 발생할때마다 뒤에서 설명할 manifest 파일을 업데이트 할 수 있습니다.
import pyspark
from delta import *
builder = pyspark.sql.SparkSession.builder.appName("MyApp3") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
spark = configure_spark_with_delta_pip(builder).getOrCreate()
# Log Level
spark.sparkContext.setLogLevel("WARN") # ALL, DEBUG, ERROR, FATAL, INFO, OFF, TRACE, WARN
# Talbe path and name
data_path = "/home/user/data/delta-table-create"
# Create Table
# data = spark.range(0, 5)
# data.write.format("delta").save(data_path)
# Create Table(SQL)
create_sql = "CREATE TABLE IF NOT EXISTS delta.`/home/user/data/delta-table-create` ( \
`key` STRING, \
`value` STRING, \
`topic` STRING, \
`timestamp` TIMESTAMP, \
`date` STRING \
) \
USING DELTA \
PARTITIONED BY (date) \
LOCATION '/home/user/data/delta-table-create' \
TBLPROPERTIES ( \
'delta.compatibility.symlinkFormatManifest.enabled'='true' \
)"
spark_created_sql = spark.sql(create_sql)
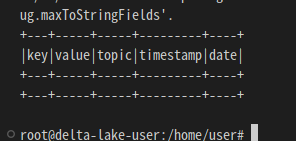
df = spark.read.format("delta").load(data_path)
df.show()아래와 같이 테이블 생성 확인됨
기본
- 테이블 생성 및 데이터 생성
- 데이터 읽기
- 데이터 업데이트
import pyspark
from delta import *
builder = pyspark.sql.SparkSession.builder.appName("MyApp3") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
spark = configure_spark_with_delta_pip(builder).getOrCreate()
# Log Level
spark.sparkContext.setLogLevel("WARN") # ALL, DEBUG, ERROR, FATAL, INFO, OFF, TRACE, WARN
# Talbe path and name
data_path = "/home/user/data/delta-table-quickstart"
#Create Table
data = spark.range(0, 5)
data.write.format("delta").save(data_path)
# Read Data
df = spark.read.format("delta").load(data_path)
df.show()
# Update Data
data = spark.range(30, 40)
data.write.format("delta").mode("overwrite").save(data_path)
read_df = spark.read.format("delta").load(data_path)
read_df.show()아래와 같이 최초 생성된 데이터와 업데이터 된 데이터를 확인 할 수 있음

Time travel 예제
- 데이터를 변경하면 자동으로 version 이 생성이 됨
- 데이터를 예전 버전으로 되돌릴 수 있음
- 데이터를 날짜별로 Dataframe에 불러와서 통계 분석 하는 방식으로 time travel을 활용있음
- 데이터 버전의 보존 기간은 직접 수동으로 설정할 수 있음
- vacuum 명령어를 사용하여 명시적으로 오래된 버전의 데이터를 영구 삭제 가능
- spark.read.format("delta").load(data_path) 으로 실행하면 최신 데이터를 읽음
- spark.read.format("delta").option("versionAsOf", version).load(data_path) 로 과거 데이터를 읽음
import pyspark
from delta import *
builder = pyspark.sql.SparkSession.builder.appName("MyApp3") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
spark = configure_spark_with_delta_pip(builder).getOrCreate()
# Log Level
spark.sparkContext.setLogLevel("WARN") # ALL, DEBUG, ERROR, FATAL, INFO, OFF, TRACE, WARN
# Talbe path and name
data_path = "/home/user/data/delta-table-timetravel"
#Create Table
data = spark.range(0, 5)
data.write.format("delta").save(data_path)
# History select
history = spark.sql("DESCRIBE HISTORY delta.`/home/user/data/delta-table-timetravel`")
latest_version = history.selectExpr("max(version)").collect()
print("latest_version >>>>>>>>>>>>>>>: {}".format(latest_version))
# Read Data
print("########### current ###########")
df = spark.read.format("delta").load(data_path)
df.show()
print("########### version 0 ###########")
df0 = spark.read.format("delta").option("versionAsOf", 0).load(data_path)
df0.show()
# Update Data
data = spark.range(30, 40)
data.write.format("delta").mode("overwrite").save(data_path)
print("########### version 0 ###########")
updatedf = spark.read.format("delta").option("versionAsOf", 0).load(data_path)
updatedf.show()
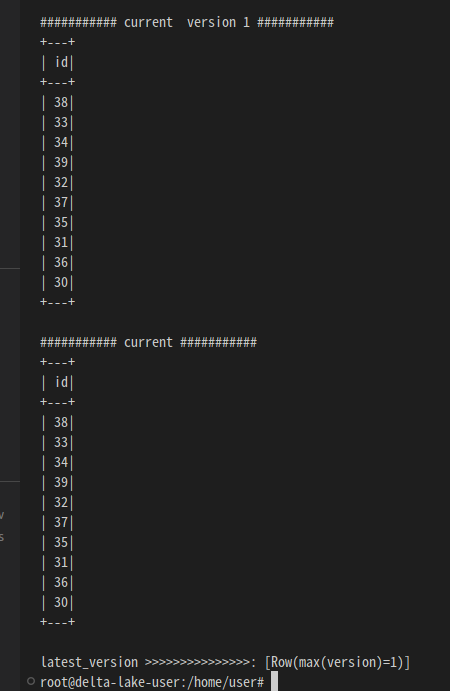
print("########### current version 1 ###########")
updatedf1 = spark.read.format("delta").option("versionAsOf", 1).load(data_path)
updatedf1.show()
print("########### current ###########")
df1 = spark.read.format("delta").load(data_path)
df1.show()
history = spark.sql("DESCRIBE HISTORY delta.`/home/user/data/delta-table-timetravel`")
latest_version = history.selectExpr("max(version)").collect()
print("latest_version >>>>>>>>>>>>>>>: {}".format(latest_version))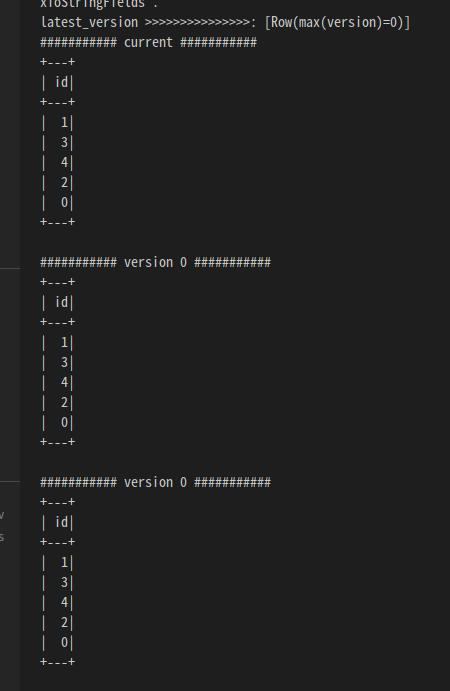
DeltaTable 예시
- 데이터 변경
- 데이터 삭제
- 데이터 수정 및 입력
from delta.tables import *
from pyspark.sql.functions import *
import pyspark
from delta import *
builder = pyspark.sql.SparkSession.builder.appName("MyApp2") \
.config("spark.sql.extensions", "io.delta.sql.DeltaSparkSessionExtension") \
.config("spark.sql.catalog.spark_catalog", "org.apache.spark.sql.delta.catalog.DeltaCatalog")
spark = configure_spark_with_delta_pip(builder).getOrCreate()
spark.sparkContext.setLogLevel("WARN") # ALL, DEBUG, ERROR, FATAL, INFO, OFF, TRACE, WARN
data_path = "/home/user/data/delta-table-quickstart"
print("################ origin data ################")
deltaTable = DeltaTable.forPath(spark, data_path)
deltaTable.toDF().show()
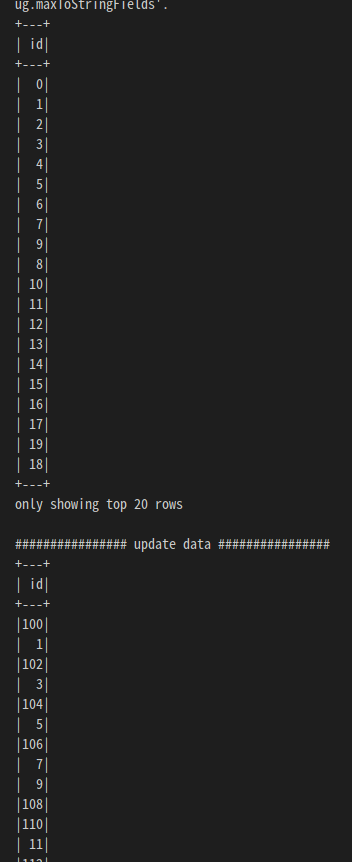
print("################ update data ################")
# Update every even value by adding 100 to it
deltaTable.update(
condition = expr("id % 2 == 0"),
set = { "id": expr("id + 100") })
deltaTable.toDF().show()
print("################ delete data ################")
# Delete every even value
deltaTable.delete(condition = expr("id % 2 == 0"))
deltaTable.toDF().show()
# Upsert (merge) new data
newData = spark.range(0, 20)
print("################ update insert data ################")
deltaTable.alias("oldData") \
.merge(
newData.alias("newData"),
"oldData.id = newData.id") \
.whenMatchedUpdate(set = { "id": col("newData.id") }) \
.whenNotMatchedInsert(values = { "id": col("newData.id") }) \
.execute()
deltaTable.toDF().show()아래와 같이 읽어온 데이테를 업데이트, 삭제, 변경, 입력이 되었음
update, insert 에서 기존 행이 업데이트되고 새 행이 삽입된 것을 확인할 수 있습니다.

Data/AI Solution Architect