
Trino는 빅데이터 분석을 위한 대화식 데이터 쿼리 서비스로 분산 SQL 쿼리 엔진 (ANSI SQL 질의 가능)으로 클러스터로로 구성되어 병렬로 대량의 데이터에 대한 SQL 쿼리 처리가 가능
- 페이스북 내부 직원 1,000명은 맹리 300PB(페타바이트) 데이터를 조회
- Presto 라는 이름을 리브랜딩
- PrestoDB 용랑 1.1G vs Trino 용량 670MB
- Amazon Athena은 Presto 0.276기반으로 서버리스 상품을 제공하고 있다. 운영 관점에서 서버가 필요 없다는 것은 장점이나, 절대적인 기능은 최신 버전의 Presto , Trino 부터 부족함
- 다양한 소스를 지원해주는데 Hive, Cassandra, RDB, AWS S3 등에서 데이터를 읽을 수 있다.
- Hive는 처리할 때 중간 결과를 디스크에 저장하지만 Presto는 메모리에 저장하기 때문에 속도가 훨씬 빠르지만 리소스를 더 사용하게 된다.
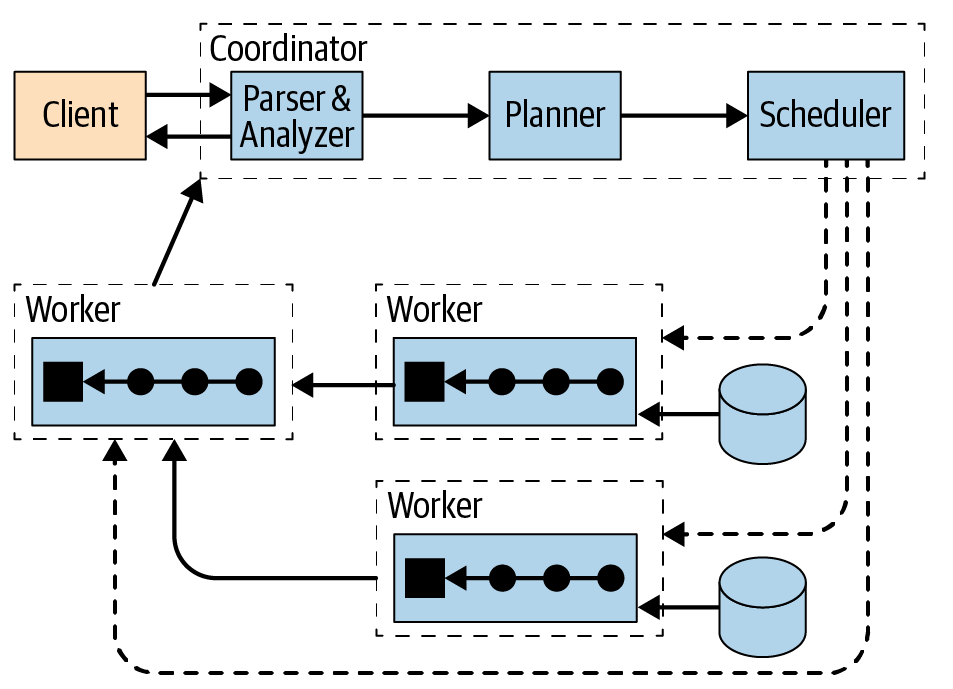
Coordinator와 Worker 아키텍처
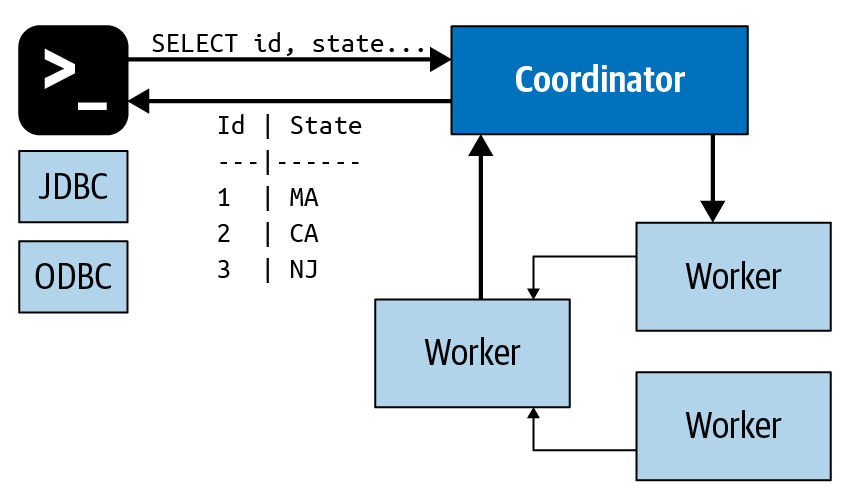
- Trino 사용자는 JDBC 드라이버 또는 Trino CLI를 사용하는 도구와 같은 클라이언트로 Coordinator에 연결합
- Coordinator는 사용자로부터 SQL 문을 수신하고 이러한 명령문을 구문 분석하고 쿼리를 계획
- Client, Coordinator 및 Worker 간의 모든 통신 및 데이터 전송은 HTTP/HTTPS를 통한 REST 기반 상호 작용
- Coordinator에서 Worker로 수행해야 할 태스크를 전달
- Worker는 Connector 플러그인을 통해 데이터 소스(Data Sources)로부터 데이터를 읽음
- Worker는 메모리에서 태스크를 수행
- 실행 결과를 바로 Client에 전달
SQL문을 처리하는 Client, Coordinator, Worker의 Flow
- Worker가 데이터를 처리할 때 결과는 Coordinator에 의해 검색되고 출력 버퍼의 Client에 노출
- Client가 출력 버퍼를 완전히 읽으면 Coordinator는 Client를 대신하여 Worker에게 더 많은 데이터를 요청
- Worker는 차례로 데이터 소스와 상호 작용하여 데이터를 가져옴
- 그 결과 쿼리 실행이 완료될 때까지 Client에서 지속적으로 데이터를 요청하고 데이터 소스에서 Worker가 데이터를 제공
특징
Web UI 제공
- QUEUED: 큐에 대기중인 상태
- PLANNING: 쿼리 계획중인 상태
- STARTING: 쿼리 실행 시작하는 상태
- RUNNING: 쿼리에 실행중인 Task가 존재하는 상태
- BLOCKED: 쿼리가 차단되고 메모리, 버퍼 공간 등을 기다리는 상태
- FINISHING: 쿼리가 커밋이 진행중이고 완료되는 상태
- FINISHED: 쿼리 실행이 완료된 상태
- FAILED: 쿼리 실행이 실패한 상태
구성요소
Presto 서비스를 구성하는 컴포넌트는 크게 두 가지로 Coordinator, Worker가 있습니다. Coordinator는 Master 역할로 한 개, Worker는 Slave 역할로 여러 개 존재할 수 있습니다. Coordinator와 Worker, Worker 노드끼리 통신할 때는 REST API를 사용합니다.
Coordinator
- Client로부터 요청을 받음
- SQL 구문 파싱, 쿼리 플래닝
- 쿼리를 실행할 Worker 노드 조정, Worker 노드의 활동 트래킹
worker
- Worker는 Coordinator에서 전달받은 태스크를 수행하고, 데이터를 처리합니다. 태스크 수행 결과는 바로 Worker에서 Client로 전달합니다.
SQL TOOL
JDBC를 통해 Clinet 에서 원격이 가능하다.(DBeaver에서 Trino 연결하는 방법)
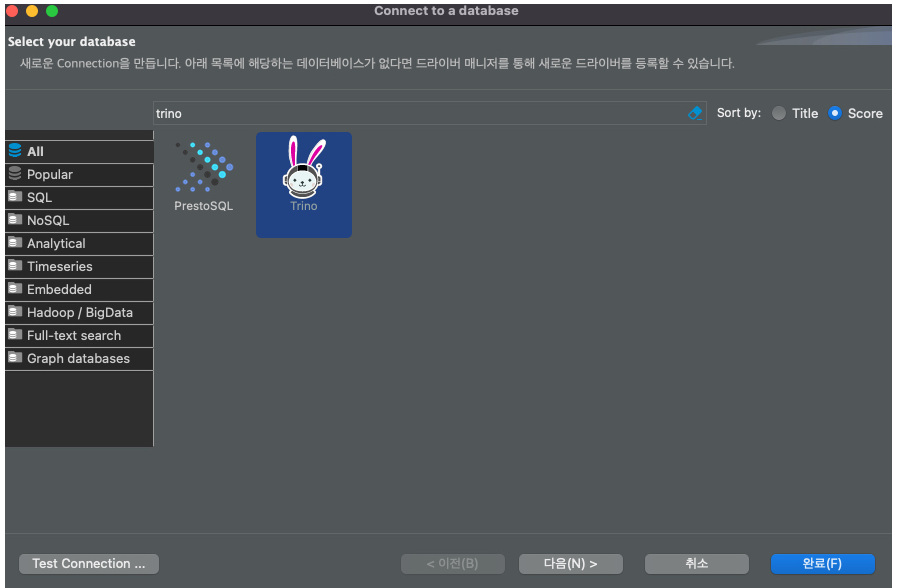
새로운 커넥션을 추가 할 때 trino 로 검색하고 다음을 누른다.
다양한 Connectors 제공
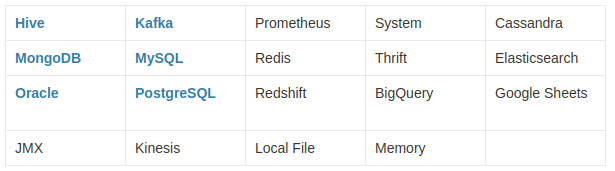
비용
오픈 소스 비용 없음
제약
제공하는 Coordinator HA(High Availiablity) 구성이 없다.
하둡 관리 패키지가 아니다 보니 운영에 필요한 부분 (모니터링, 보안 등)을 구성하는데 비용(시간)이 꽤 든다.

Data/AI Solution Architect