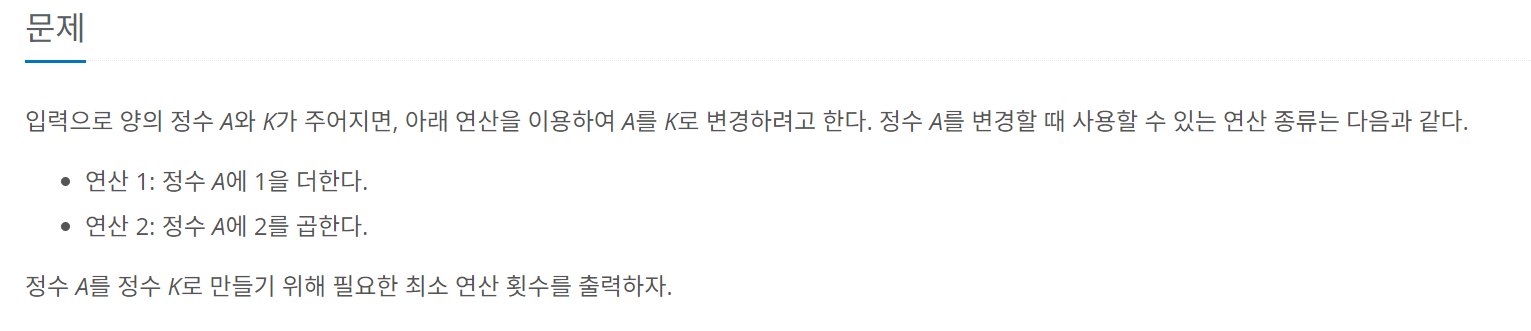
문제는 위와 같다. while문에 if문을 걸어서도 해결할 수 있지만 BFS 풀이 능력을 키우기 위해 고른 문제기 때문에 해당 방법으로 풀어보려고 처음 시도한 코드는 아래와 같다.
첫번째 시도
A, K = map(int, input().split())
cnt = 0
queue = []
cnt = 0
queue.append((A,cnt))
fin = 0
while fin != K:
queue.append((queue[0][0]*2,queue[0][1]+1))
queue.append((queue[0][0]+1,queue[0][1]+1))
fin, cnt = queue.pop(0)
#print(fin, cnt)
#print(fin)
print(cnt)너비 우선 탐색이 그래프에 같은 깊이에 있는 노드를 탐색하는 것으로 자료구조 큐를 이용했던 것이 생각나 위와 같은 코드를 구성했다. 큐에 맨 처음 a를 집어넣고, 후에 할 수 있는 연산 종류 *2와 +1을 한 값을 큐에 계속 넣어 뽑아내면서 카운트 한 후. K값이 나오면 while문을 멈추고 카운트를 프린트하는 것이다.
하지만 위처럼 코드를 짤 경우 k값을 뽑아낼 때. 끝이 나기 때문에 a를 연산을 통해 k값이 이미 만들어졌어도 큐에서 뽑아내지지 않고 남아있다면 계속해서 연산을 이어가 저장하기 때문에 시간 초과가 된다.
두번째 시도
a, k = map(int, input().split())
queue = [a]
visited = {a: 0}
while queue:
current = queue.pop(0)
if current == k:
break
for next_val in [2 * current, current + 1]:
if next_val not in visited and next_val <= k:
visited[next_val] = visited[current] + 1
queue.append(next_val)
print(visited[k])
위에 대한 문제를 해결하기 위해 새로 짠 코드가 위와 같다.
visited라는 딕셔너리를 만들어 큐에 값이 들어갈 때마다 당시의 카운트 값을 저장하고 연산한 값이 k보다 작거나 같을 때까지만 해당 연산을 반복할 수 있도록 코드를 수정하였다. 하지만 이는 리스트를 이용해 pop()하기 때문에 성능이 다소 떨어져 이도 시간 초과 문제가 걸렸다.
세번째 시도
from collections import deque
a, k = map(int, input().split())
queue = deque([a])
visited = {a: 0}
while queue:
current = queue.popleft()
if current == k:
break
for next_val in [2 * current, current + 1]:
if next_val <= k and next_val not in visited:
visited[next_val] = visited[current] + 1
queue.append(next_val)
print(visited[k])그렇게 파이썬에서 제공되는 deque라이브러리를 이용해 성능을 개선하여 이 문제를 해결하였고 통과했따~
