
안녕하세요👻
최근에 스프링 부트를 공부하고 있는데, 아키텍처 부분에서 헷갈리는 경우가 종종 있습니다. 이것을 해결하기 위해서는 기본 지식들에 대해 확실히 짚고 넘어가야 내 스스로 이해가 더 잘 될 거 같다는 생각이 들었습니다🤔
그래서 오늘은 스프링 웹 애플리케이션의 계층 구조에 대해서 제대로 한 번 알아보겠습니다.
API를 만들기 위해서는 총 3개의 클래스가 필요합니다.
- Request 데이터를 받을 Dto
- API 요청을 받을 Controller
- 트랜잭션, 도메인 기능 간의 순서를 보장하는 Service
스프링의 웹 계층
다음은 스프링의 웹 계층을 나타낸 그림입니다.
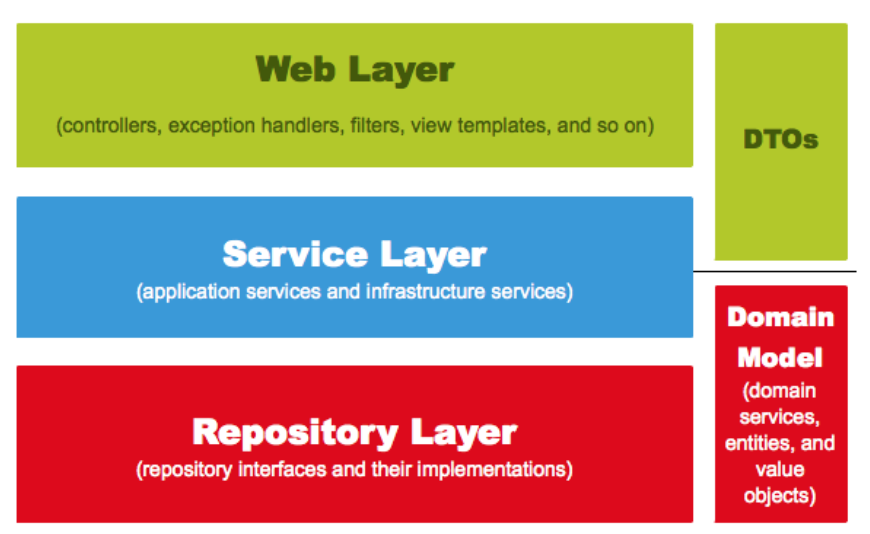
간단하게 각 영역에 대해서 알아보겠습니다.
Web Layer
- 흔히 사용하는 컨트롤러(
@Controller)와 JSP/Freemarker 등의 뷰 템플릿 영역입니다. - 이외에도 필터(
@Filter), 인터셉터, 컨트롤러 어드바이스(@ControllerAdvice) 등 외부 요청과 응답에 대한 전반적인 영역을 이야기합니다.
Service Layer
@Service에 사용되는 서비스 영역입니다.- 일반적으로 Controller와 Dao의 중간 영역에서 사용됩니다.
@Transactional이 사용되어야 하는 영역이기도 합니다.
Repository Layer
- Database와 같이 데이터 저장소에 접근하는 영역입니다.
- Dao(Data Access Object) 영역이라 불리기도 합니다.
Dtos
- Dto(Data Transfer Object)는 계층 간의 데이터 교환을 위한 객체를 이야기하며 Dtos는 이들의 영역을 얘기합니다.
- 예를 들어 뷰 템플릿 엔진에서 사용될 객체나 Repository Layer에서 결과로 넘겨준 객체 등이 이들을 이야기합니다.
Domain Modle
- 도메인이라 불리는 개발 대상을 모든 사람이 동일한 관점에서 이해할 수 있고 공유할 수 있도록 단순화시킨 것을 도메인 모델이라고 합니다.
- 비즈니스 로직을 처리합니다.
@Entity가 사용된 영역 역시 도메인 모델입니다.- 다만, 무조건 데이터베이스의 테이블과 관계가 있어야 하는 것은 아닙니다. (VO처럼 값 객체들도 도메인 모델에 해당하기 때문)
스프링 계층 간 흐름도
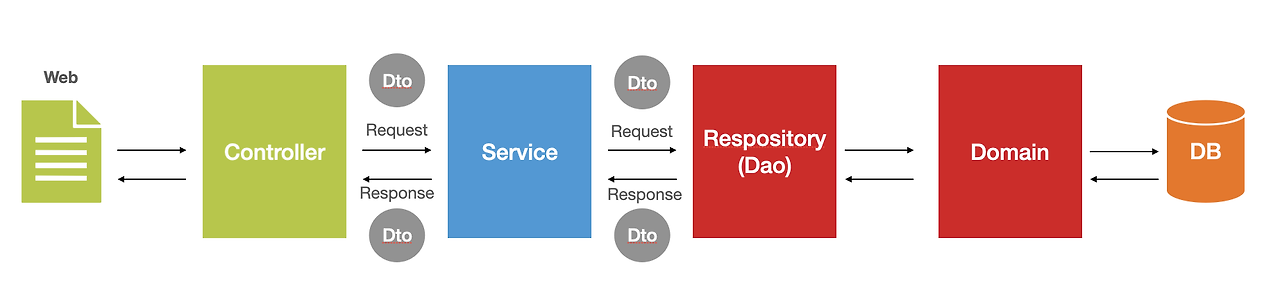
비즈니스 로직 처리
비즈니스 로직을 도메인에 넣는 이유
기존에 서비스로 비즈니스 로직을 처리하던 방식은 트랜잭션 스크립트라고 합니다. 모든 로직이 서비스 클래스 내부에서 처리하게 되면 서비스 계층이 무의미해지며, 객체란 단순히 데이터 덩어리 역할만 하게 됩니다.
서비스에서 비즈니스 로직 처리
주문 취소 로직인 psudo code 하나를 예시로 들어보겠습니다.
@Transactional
public Order cancleOrder(int orderId){
1) 데이터베이스로부터 주문정보(Orders), 결제정보(Billing), 배송정보(Delivery) 조회
2) 배송 취소를 해야 하는지 확인
3) if(배송중이라면) {
배송 취소로 변경
}
4) 각 테이블에 취소 상태 Update
이 로직을 모두 서비스 클래스에 작성해보겠습니다.
@Transactional
public Order cancelOrder(int orderId){
OrdersDto order = ordersDao.selectOrders(orderId);
BillingDto billing = billingDao.selectBilling(orderId);
DeliveryDto delivery = deliveryDao.selectDelivery(orderId);
String deliveryStatus = delivery.getStatus();
// "배송 취소" 해야 하는지 확인
if("IN_PROGRESS".equals(deliveryStatus)){
// 배송 취소로 변경
delivery.setStatus("CANCEL");
deliveryDao.update(delivery);
}
// 각 테이블 취소 상태 update
order.setStatus("CANCEL");
ordersDao.update(order);
billing.setStatus("CANCEL");
billingDao.update(billing);
return order;
}반면 도메인에서 처리할 경우
@Transactional
public Order cancelOrder(int orderId){
OrdersDto order = ordersRepository.findById(orderId);
BillingDto billing = billingRepository.findByOrderId(orderId);
DeliveryDto delivery = deliveryRepository.findByOrderId(orderId);
// 배송 취소 로직
delivery.cancel();
// 각 테이블에 취소 update
order.cancel();
delivery.cancel();
return order;
}order, billing, delivery가 각자 본인의 취소 이벤트 처리를 하며, 서비스 메소드는 트랜잭션과 도메인 간의 순서만 보장해주게 됩니다.
이렇게 비즈니스 로직을 도메인에 집중시킴으로써 얻는 장점에는 어떤 것들이 있을까요? 🤔
비즈니스 로직을 도메인에 작성함으로써 얻는 장점
비즈니스 로직을 도메인 객체에 작성해줌으로써 얻는 장점에는 이런 것들이 있습니다.
📍 객체지향스러운 개발을 할 수 있다.
일반적으로 객체는 속성과 기능을 가져야 합니다. 그리고 객체들은 단순 속성(데이터)만 갖기 보다는 기능(함수)를 구현함으로써 메세지를 주고받아야 합니다. 이러한 구현이 정말 객체지향스러운 개발이고, 이는 코드를 간결하게 해주며 가독성이나 이해를 쉽게 할 수 있도록 도와줍니다.
📍 도메인 객체의 응집도를 높일 수 있다.
기존의 빈약한 객체를 기반으로 한다면 해당 객체와 관련된 비지니스 로직을 파악하기 위해 전체 서비스 레이어를 살펴봐야 합니다. 하지만 해당 도메인 객체와 연관된 비지니스 로직을 파악하기 위해서는 해당 객체만 보면 됩니다.
📍DI(Dependency Injection)를 줄일 수 있다.
만약 비즈니스 로직이 서비스 계층에만 있다면 항상 해당 비즈니스 로직을 갖는 서비스 계층을 DI 해야 합니다. 하지만 해당 비즈니스 로직이 객체에 있다면 불필요한 DI를 상당히 줄일 수 있습니다.
📍서비스 계층의 코드가 간결하다.
이러한 방식으로 개발하면 도메인 객체가 스스로 처리 가능한 비즈니스 로직을 갖고 있어 서비스 계층의 코드를 간결하게 유지할 수 있습니다. 그리고 이것은 코드 리딩이나 유지보수성 등을 높여줄 것이며 불필요한 중복 로직의 개발을 막을 수도 있습니다.
오늘은 이렇게 스프링의 계층 구조에 대해서 알아보고, 비즈니스 로직을 도메인에 작성하면 좋은 점에 대해서도 알아보았습니다!
개념을 다시 공부하고 정리해보니 왜 그동안 비즈니스 로직을 도메인에 작성하도록 배웠는지 확실히 이해가 되네요😂
그럼 다음 포스트로 찾아뵙겠습니다. 읽어주셔서 감사합니다 :)
📚Reference
스프링 부트와 AWS로 혼자 구현하는 웹 서비스 - 이동욱
도메인 주도 설계 및 개발과 도메인 계층
비즈니스 로직을 처리하는 패턴
