
1. Hash Table
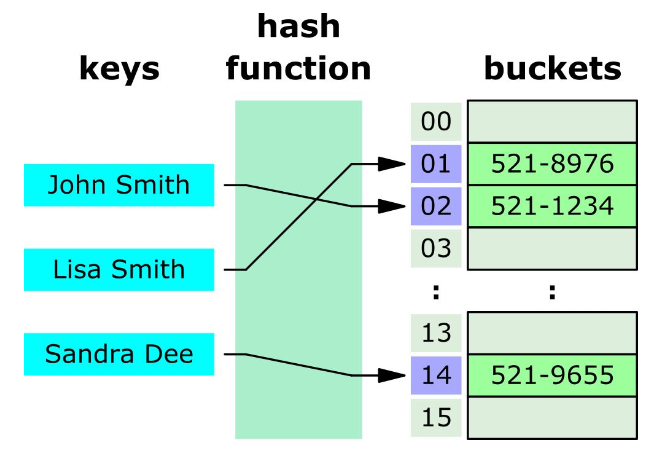
해시(Hash)는 데이터를 저장하는 자료구조 중 하나로, 효율적인 데이터 검색을 위해 사용됩니다. 해시 테이블은 키(Key)와 값(Value)을 매핑하는 구조로, 각 키를 해시 함수를 사용하여 고유한 해시 코드(Hash code)로 변환하고, 해당 해시 코드에 대응되는 값을 저장합니다.
- 해시 테이블은 Key 값을 해시함수(Hash Function)를 사용하여 변환한 값을 색인(index)으로 삼는다.
- 해시 함수(Hash Function)를 사용해 Key 값을 색인(index)으로 변환하는 과정을 해싱(Hashing)이라고 한다.
1-1. Hash 특징
- 해시 함수: 해시 테이블은 해시 함수를 사용하여 키를 고유한 해시 코드로 변환합니다. 이 과정에서 같은 키는 항상 같은 해시 코드로 변환되어야 합니다. 해시 함수는 키의 개수보다 작은 범위의 값을 반환하여 충돌(Hash Collision)이 발생할 수 있습니다.
- 충돌 해결: 해시 함수의 결과가 같은 경우 두 개 이상의 키가 동일한 해시 코드에 저장될 수 있습니다. 이러한 충돌을 해결하기 위해 다양한 방법이 사용됩니다. 주요 충돌 해결 기법으로는 개체 체이닝(Open Chaining)과 개방 주소법(Open Addressing) 등이 있습니다.
- 검색과 삽입: 해시 테이블은 평균적으로 상수 시간(O(1))에 데이터를 검색하고 삽입할 수 있습니다. 이는 해시 함수가 충돌을 최소화하여 빠른 데이터 액세스를 가능하게 합니다.
- 메모리 소요: 해시 테이블은 메모리를 효율적으로 사용할 수 있습니다. 하지만 충돌이 발생하면 추가적인 메모리를 사용하여 충돌을 해결해야 할 수도 있습니다.
- 순서가 보장되지 않음: 해시 테이블은 일반적으로 데이터의 순서를 보장하지 않습니다. 삽입 순서나 키의 값 순서로 데이터를 접근할 수 없습니다.
1-2. 해시 함수(Hash Function)
해시 함수(Hash function)는 입력 데이터를 고정 크기의 해시 코드(Hash code)로 변환하는 함수입니다. 해시 함수는 임의의 길이를 가진 입력 데이터를 고정된 길이의 해시 코드로 매핑하는 작업을 수행합니다.
특징
- 일관성: 동일한 입력에 대해 항상 동일한 해시 코드를 반환해야 합니다. 즉, 동일한 키에 대해 항상 같은 해시 코드를 생성해야 합니다.
- 고유성: 서로 다른 입력에 대해 서로 다른 해시 코드를 반환해야 합니다. 해시 함수는 고유한 해시 코드를 생성하여 서로 다른 키들이 다른 버킷에 매핑되도록 해야 합니다.
- 충돌 최소화: 서로 다른 입력에 대해 같은 해시 코드를 반환하는 충돌(Collision)을 최소화해야 합니다. 완전히 충돌을 피할 수는 없지만 좋은 해시 함수는 충돌이 발생할 확률을 최소화하여 해시 테이블의 성능을 향상시킵니다.
- 효율성: 해시 함수는 빠르게 계산되어야 합니다. 해시 테이블은 데이터 검색과 삽입에 빠른 성능을 제공하므로 해시 함수의 계산 시간이 짧아야 합니다.
public int simpleHash(String input) {
int hash = 0;
for (char c : input.toCharArray()) {
hash += (int) c;
}
return hash % 100; // 100개의 버킷을 가지는 해시 테이블에서 사용하기 위해 100으로 나눈 나머지를 반환
}1-3. 해시 충돌(Hash Collision)
키 값이 다른데, 해시 함수의 결과값이 동일한 경우
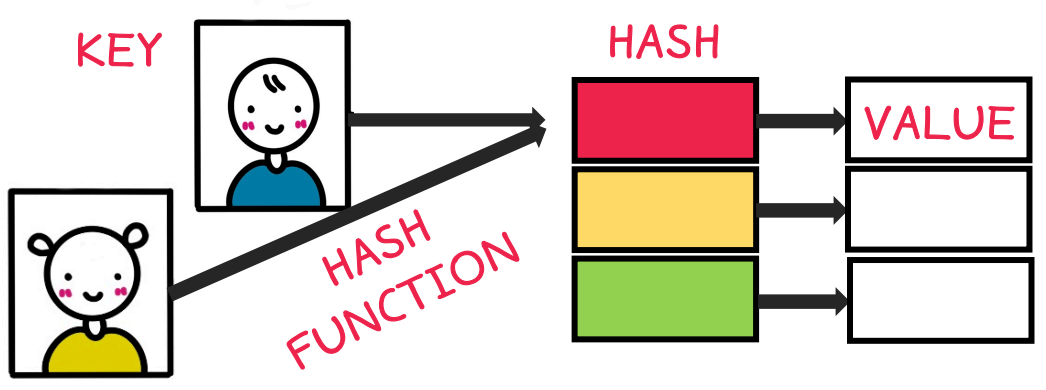
해결법으로 분리 연결법(Separate Chaining)과 개방 주소법(Open Addressing)등이 있다.
분리 연결법(separate Chaining)
체이닝은 저장소(Bucket)에서 충돌이 일어나면 기존 값과 새로운 값을 연결리스트로 연결하는 방법이다.
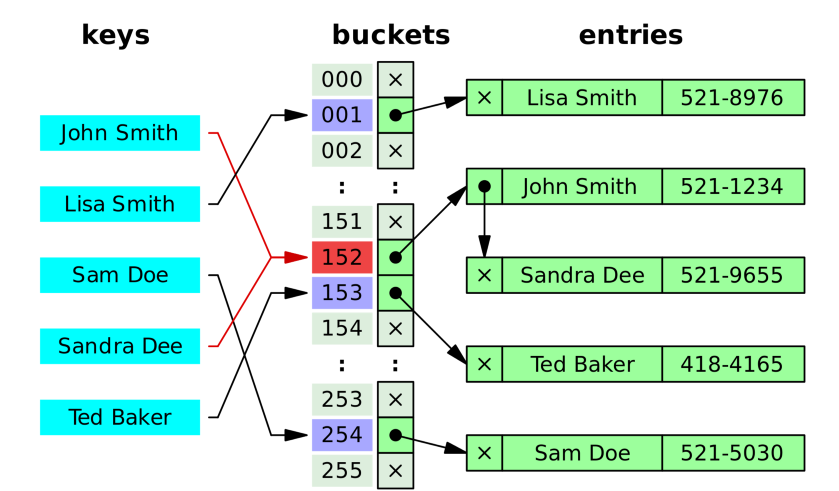
- 장점
- 미리 충돌을 대비해서 공간을 많이 잡아놓을 필요가 없다. 출돌이 나면 그때 공간을 만들어서 연결만 해주면 된다.
- 단점
- 추가 메모리 사용: 충돌이 발생한 경우 연결 리스트를 위한 추가적인 메모리가 필요합니다. 따라서 데이터의 개수가 적은 경우에도 상대적으로 많은 메모리를 사용할 수 있습니다.
- 캐시 성능 저하: 연결 리스트는 데이터를 연속적으로 저장하지 않으므로 캐시 메모리의 성능을 저하시킬 수 있습니다.
개방 주소법(Open Addressing)
- 선형 탐색
충돌이 발생한 경우 다음 빈 버킷을 찾아 데이터를 저장하는 방법
- 장점
- 구현이 비교적 간단합니다.
- 데이터를 연속적으로 저장하므로 캐시 메모리의 성능을 향상시킵니다.
- 단점
- 클러스터링(Clustering) 문제: 충돌이 발생하면 선형 탐사로 인해 클러스터링이 발생할 수 있습니다. 즉, 연속된 버킷에 데이터가 몰리는 현상이 발생하여 충돌이 더 자주 발생할 수 있습니다.
- 로드 팩터(Load Factor)의 제약: 로드 팩터가 높을 경우(해시 테이블에 저장된 데이터 수가 버킷 수에 비해 많을 경우) 성능이 저하될 수 있습니다.
- 제곱 탐색
제곱 탐사는 선형 탐색의 클러스터링 문제를 완화하기 위한 방법입니다. 충돌이 발생하면 일정한 간격(제곱 수열 등)으로 다음 빈 버킷을 검사하여 데이터를 저장합니다.
- 장점
- 선형 탐사보다 클러스터링 문제를 완화할 수 있습니다.
- 단점
- 클러스터링 문제가 완전히 해결되는 것은 아닙니다.
- 로드 팩터의 제약이 여전히 존재합니다.
- 이중 해시
이중 해싱은 해시 충돌을 해결하기 위해 두 번째 해시 함수를 사용하는 방법입니다. 충돌이 발생한 경우 두 번째 해시 함수를 사용하여 다음 빈 버킷을 검사하여 데이터를 저장합니다.
- 장점
- 클러스터링 문제를 좀 더 효과적으로 완화할 수 있습니다.
- 로드 팩터의 제약이 상대적으로 덜합니다.
- 단점
- 구현이 복잡합니다.
1-4. 구현
MyLinkedHashTable
package com.example.datastructure.Hash;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.List;
public class MyLinkedHashTable<K, V> {
private static final int DEFAULT_BUCKET_SIZE = 1024;
private List<Node>[] buckets;
private int size;
private int bucketSize;
public MyLinkedHashTable(){
this.buckets = new List[DEFAULT_BUCKET_SIZE];
this.bucketSize = DEFAULT_BUCKET_SIZE;
this.size = 0;
for(int i = 0; i< bucketSize; i++){
this.buckets[i] = new LinkedList<>();
}
}
// 사용자 사이즈 정의
public MyLinkedHashTable(int bucketSize){
this.buckets = new List[DEFAULT_BUCKET_SIZE];
this.bucketSize = DEFAULT_BUCKET_SIZE;
this.size = 0;
for(int i = 0; i< bucketSize; i++){
this.buckets[i] = new LinkedList<>();
}
}
public void put(K key, V value){
int idx = this.hash(key);
List<Node> bucket = this.buckets[idx];
for(Node node : bucket){
if(node.key.equals(key)){
node.data = value;
return;
}
}
Node node = new Node(key, value);
bucket.add(node);
size++;
}
public V get(K key){
int idx = this.hash(key);
List<Node> bucket = this.buckets[idx];
for(Node node : bucket){
if(node.key.equals(key)){
return node.data;
}
}
return null;
}
public boolean delete(K key){
int idx = this.hash(key);
List<Node> bucket = this.buckets[idx];
for(Iterator<Node> iter = bucket.iterator(); iter.hasNext();){
Node node = iter.next();
if(node.key.equals(key)){
iter.remove();
this.size--;
return true;
}
}
return false;
}
public boolean contains(K key){
int idx = this.hash(key);
List<Node> bucket = this.buckets[idx];
for(Node node : bucket){
if(node.key.equals(key)){
return true;
}
}
return false;
}
public int size(){
return this.size;
}
private int hash(K key) {
int hash = 0;
for(Character ch : key.toString().toCharArray()){
hash += (int) ch;
}
return hash % this.bucketSize;
}
private class Node{
K key;
V data;
Node(K key, V date){
this.key = key;
this.data = data;
}
}
}
List<Node>[]
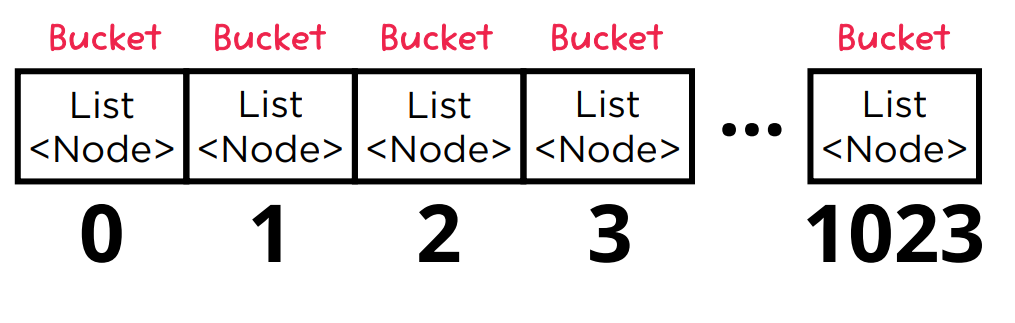
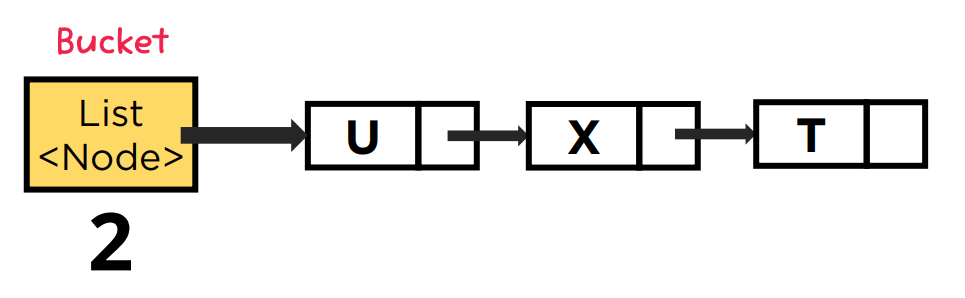
1-5. 관련 알고리즘
백준 1920. 수 찾기
package com.example.datastructure.Hash;
import java.util.HashSet;
import java.util.Scanner;
import java.util.Set;
/*
1920. 수 찾기
*/
public class Baekjoon_1920 {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
int N = sc.nextInt();
Set<Integer> A = new HashSet<>();
for(int i = 0; i < N; i++){
int n = sc.nextInt();
A.add(n);
}
int M = sc.nextInt();
StringBuilder result = new StringBuilder();
for(int i = 0; i < M; i++){
int m = sc.nextInt();
if(A.contains(m)){
result.append(1 + "\n");
}else{
result.append(0 + "\n");
}
}
System.out.println(result);
}
}
