
📋 TO-DO LIST
신입 연수원 활동 [o]
2주 2일차 강의 [o]
인턴교육 직후 사수 도움 요청 업무 [o]
팀장님 지시 업무 [o]
중간/일일 업무 보고 작성 [o]
정기 팀/동기 스터디 모임 참석 및 성실도 [o]
📍 학습 내용 정리
[MySQL] SQL 기본 문법
SELECT - 조회할 데이터 지정
-- SELECT '컬럼명' FROM '테이블명'
SELECT users_id, name FROM users;
-- SELECT 와 FROM 사이에 *를 적으면 테이블의 모든 컬럼을 조회한다.
SELECT * FROM users;
-- 두 SQL은 동일한 기능을 한다.
SELECT * FROM test.users;
SELECT * FROM users;
--기본적으로 테이블 이름은 스키마명.테이블명 으로 표현한다.WHERE
-- users 테이블에서 users_number 컬럼 값이 5이상인 데이터 조회
SELECT * FROM users
WHERE users_number >= 5;
-- WHERE절을 사용해 특정 조건에 해당하는 데이터만 조회할 수 있다.
-- 관계 연산자 / 논리 연산자 사용 가능논리 연산자 AND,OR 사용가능
SELECT TRUE OR FALSE AND FALSE; // 1
SELECT (TRUE OR FALSE) AND FALSE; // 0
-- 여러 조건이 필요한 경우 논리 연산자를 사용하면 된다.
-- AND가 OR보다 우선 순위를 가진다.
-- MySQL에서는 &&나 ||도 사용 가능하다. BETWEEN - 범위 표현식
-- users 테이블에서 height 컬럼 값이 160이상 165이하인 데이터 조회
SELECT * FROM users
WHERE height between 160 and 165;
-- between 연산자를 이용하여 특정 범위에 해당하는 데이터를 조회할 수 있다.
-- 하지만 인덱스를 사용할 수 없으므로 주의IN() - 여러 값 매칭
-- addr 컬럼값이 경기, 전남, 경남인 데이터 조회
SELECT * FROM users
WHERE addr IN('경기', '전남', '경남');
SELECT * FROM users
WHERE addr = '경기' AND addr = '전남' AND addr = '경남';
-- IN() 연산자를 이용하여 특정 값이 포함된 데이터를 조회할 수 있다.
-- IN 연산자는 동등비교 '=' 를 여러번 수행하는 효과를 가진다. 따라서 인덱스를 최적으로 활용할 수 있다.LIKE - 문자열의 일부 글자 검색
-- usr_name 컬럼 값이 '블'로 시작하는 4글자 글자 데이터 조회
SELECT * FROM users WHERE usr_name LIKE '블___';
-- usr_name 컬럼 값이 '블'로 시작하는 모든 데이터 조회
SELECT * FROM users WHERE usr_name LIKE '블%';
-- usr_name 컬럼 값에 '블'이 들어가는 모든 데이터 조회
SELECT * FROM users WHERE usr_name LIKE '%블%';
-- 문자열의 일부 글자 검색
-- _ : 한 글자만 매치
-- % : 몇 글자든 매치서브쿼리
SELECT usr_name, height
FROM users
WHERE height > (select height from users where usr_name LIKE 'example');
-- 2개의 SQL 문을 하나로 만듦ORDER BY - 조회된 데이터를 정렬
-- debut_date 값을 기준으로 정렬 (기본 ASC)
SELECT * FROM users
ORDER BY debut_date;
-- ORDER BY 절은 데이터를 정렬한다.
-- WHERE 절 다음에 나와야 함
-- ASC (ascending order) : 오름차순 → (생략시 기본값)
-- DESC (descending order) : 내림차순-- height 컬럼 값이 164 이상인 데이터를 조회하여
-- height 값 기준 내림차순 정렬하고 동일한 값이라면 debut_date 값 기준 오름차순 정렬
SELECT * FROM users
WHERE height >= 164
ORDER BY height DESC, debut_date;
-- 콤마 , 로 여러 정렬 조건 지정 가능LIMIT - 출력 개수 제한
SELECT * FROM users
LIMIT 3; -- 상위 3건만 조회
SELECT * FROM users
LIMIT 3, 2; -- 3번째 데이터부터 2건만 조회
LIMIT 2 OFFSET 3; -- 위와 동일
-- LIMIT 시작, 개수
-- LIMIT 뒤에 하나의 숫자만 입력시 처음부터 N까지의 데이터만 가져옴
-- LIMIT 과 OFFSET 조합으로도 출력 개수를 제한할 수 있다.DISTNCT - 중복 데이터 제거
-- addr 의 모든 컬럼 값을 중복을 제거하여 조회
SELECT DISTINCT addr
FROM users;
-- DISTINCT를 열 이름 앞에 붙이면 중복된 값은 1개만 출력된다.GROUP BY - 그룹화
-- mem_id가 같은 데이터를 그룹으로 묶음
-- 그룹핑된 데이터에서 mem_id와 amount의 합계를 구함
SELECT users_id, SUM(amount) AS "합계"
FROM buy
GROUP BY users_id
ORDER BY users_id;
-- 컬럼이 같은 데이터를 그룹화 해주는 기능
-- 보통 집계 함수와 같이 쓰임집계함수
SUM() : 컬럼의 합계를 반환
AVG() : 컬럼의 평균을 반환
MIN() : 컬럼의 최소값을 반환
MAX() : 컬럼의 최대값을 반환
COUNT() : 행의 개수를 셈
COUNT(DISTINCT) : 행의 개수를 셈
-- 집계 함수 안에서 연산도 가능
SELECT users_id, SUM(amount*price) AS "총 금액"
FROM buy
GROUP BY users_id
ORDER BY users_id;
-- 집계 함수 내에서 사칙 연산도 가능하다.HAVING - 그룹조건
-- users_id 를 기준으로 그룹화
-- 그룹화된 데이터를 기준으로 amount*price 합계가 1000 이상인 그룹만 남김
-- 조건에 걸러진 그룹에서 amount*price 의 합계를 조회
SELECT SUM(amount*price) AS "총 금액"
FROM buy
GROUP BY users_id
HAVING SUM(amount*price) >= 1000;
-- 그룹화된 데이터에 대해서 조건을 제한함
-- GROUP BY 뒤에 와야함해보기
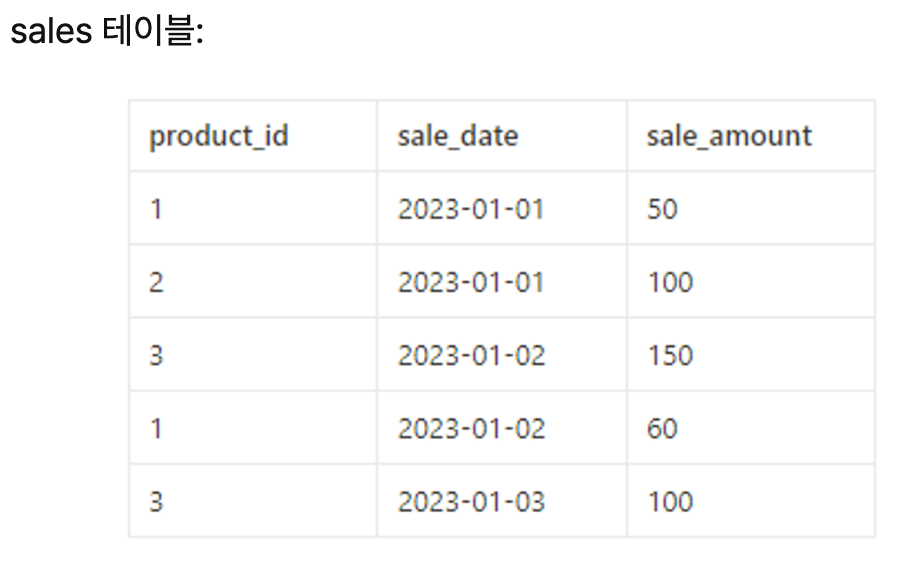
상품별 매출 합계를 계산하고, 매출이 높은 상품부터 낮은 상품 순으로 정렬하여 출력하는 SQL 쿼리를 작성
SELECT SUM(sale_amount)as total_sales
FROM sales
GROUP BY product_id
ORDER BY total_sales DESC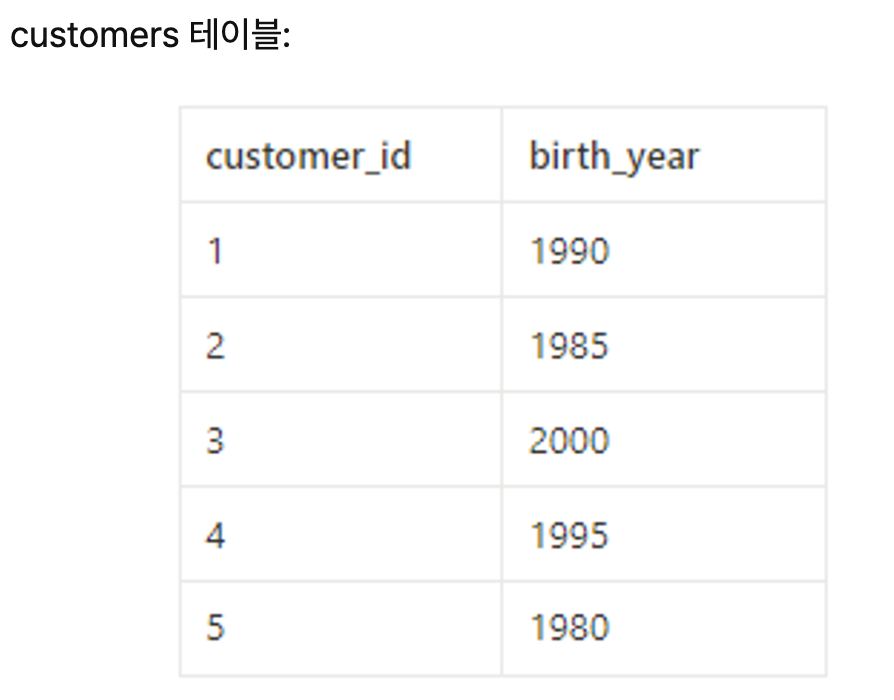
고객의 나이를 기준으로 10년 단위의 연령대별로 고객 수를 계산하는 SQL 쿼리를 작성 현재 년도: 2023 가정
SELECT
FLOOR((2023 - birth_year) / 10) * 10 AS age_group,
COUNT(*) AS customer_count
FROM
customers
GROUP BY
age_group
ORDER BY
age_group;
-- age_group : 연령대
-- customer_count : 고객 수ERD
ERD(엔터티 관계 다이어그램)는 데이터베이스 내의 요소가
어떻게 관련되어 있는지 보여 주는 데이터베이스의 시각적 표현입니다.
간단히 ERD 작성할 때 사용하는 유용한 사이트 dbdiagram
📍 일일보고
부족한 점 : SQL 조회한 데이터들을 그룹화하고 정렬을 하는 연습을 착실히 해야할 것 같다.
스스로 시도해본 것들 :
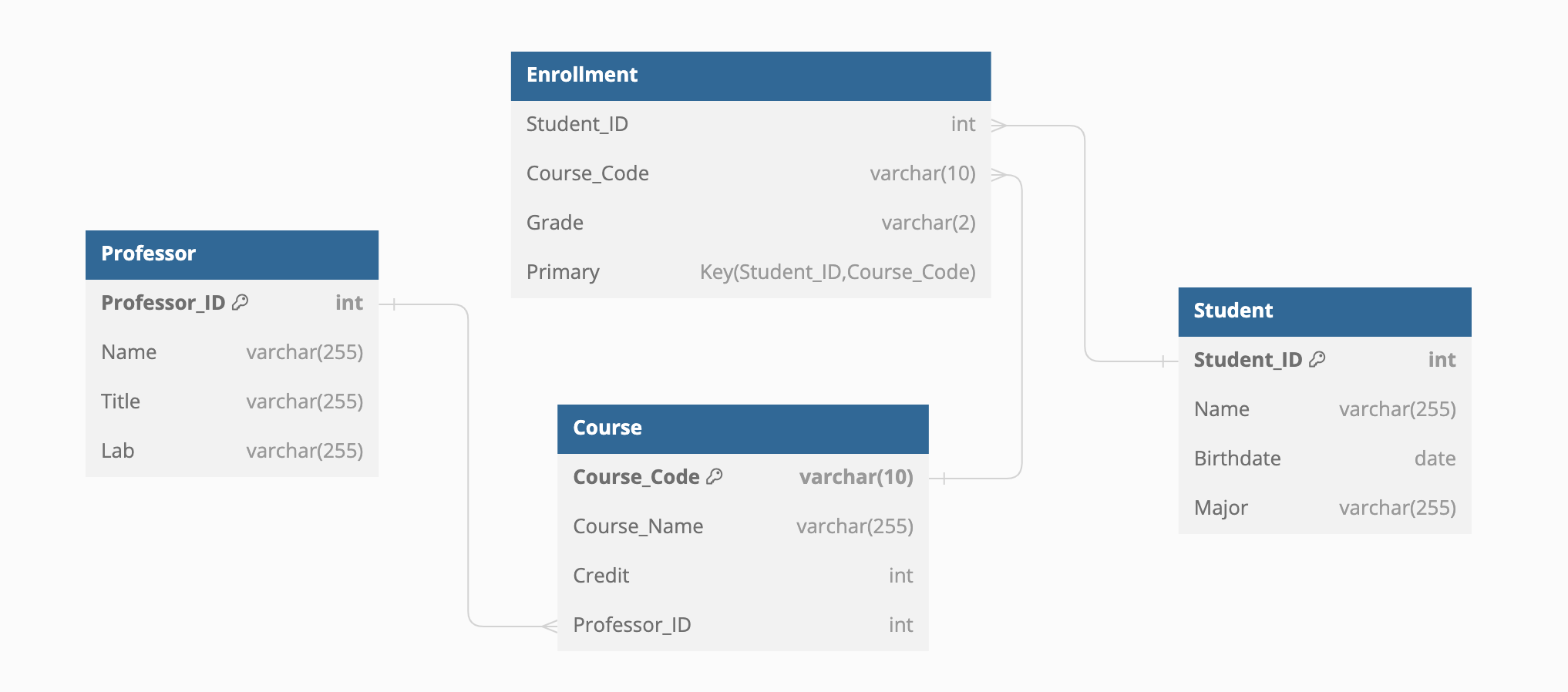
관계정리 실습을 위한 테이블 작성
-- 학생 테이블
CREATE TABLE Student (
Student_ID INT PRIMARY KEY,
Name VARCHAR(255),
Birthdate DATE,
Major VARCHAR(255)
);
-- 교수 테이블
CREATE TABLE Professor (
Professor_ID INT PRIMARY KEY,
Name VARCHAR(255),
Title VARCHAR(255),
Lab VARCHAR(255)
);
-- 강의 테이블
CREATE TABLE Course (
Course_Code VARCHAR(10) PRIMARY KEY,
Course_Name VARCHAR(255),
Credit INT,
Professor_ID INT,
FOREIGN KEY (Professor_ID) REFERENCES Professor(Professor_ID)
);
-- 수강신청 테이블
CREATE TABLE Enrollment (
Student_ID INT,
Course_Code VARCHAR(10),
Grade VARCHAR(2),
PRIMARY KEY (Student_ID, Course_Code),
FOREIGN KEY (Student_ID) REFERENCES Student(Student_ID),
FOREIGN KEY (Course_Code) REFERENCES Course(Course_Code)
);테이블 작성 후 ERD 추출
메모한 내용을 배열에 저장하던 것을 MongoDB를 사용해 저장 (CRUD 수정)
from fastapi import FastAPI , Query
from pydantic import BaseModel
from typing import List
from fastapi.staticfiles import StaticFiles
from pymongo import MongoClient
import json
class Memo(BaseModel):
id:int
title:str
content:str
createdAt:str
class Message(BaseModel):
sender:str
message:str
client = MongoClient('mongodb://127.0.0.1:27017/')
db = client['database_test']
collection = db['mycollection']
chat_log = []
app = FastAPI()
# 챗 부분
@app.post('/chat')
async def send_chat(message: Message):
chat_log.append(message)
return "message received successful"
@app.get("/chat")
async def get_chat_log():
return chat_log
# 메모 부분
# post method
@app.post("/memos")
def create_memo(memo:Memo):
data = {
'id' : memo.id,
'title' : memo.title,
'content' : memo.content,
'created_at' : memo.createdAt
}
result = collection.insert_one(data)
return 'request successful'
# get method
@app.get("/memos")
def read_memo(sort: str = Query(None, description="정렬 속성"),
order: str = Query("ASC", description="정렬 순서 (ASC 또는 DESC)")):
# MongoDB에서 메모 가져오기 및 정렬
if sort == "title":
memos = list(collection.find().sort("title", 1 if order == "ASC" else -1))
elif sort == "createdAt":
memos = list(collection.find().sort("created_at", 1 if order == "ASC" else -1))
else:
memos = list(collection.find())
serialized_memos = [{key: memo[key] for key in memo if key != '_id'} for memo in memos]
return serialized_memos
# put method
@app.put('/memos/{memo_id}')
def put_memo(memo_id:str ,req_memo:Memo):
# MongoDB에서 메모 업데이트
update_result = collection.update_one(
{'id': int(memo_id)},
{'$set': {'title': req_memo.title, 'content': req_memo.content}}
)
if update_result.modified_count:
return '수정 성공'
else:
return '메모를 찾을 수 없습니다'
# delete method
@app.delete('/memos/{memo_id}')
def delete_memo(memo_id:str):
# MongoDB에서 메모 삭제
delete_result = collection.delete_one({'id': int(memo_id)})
if delete_result.deleted_count:
return '삭제 성공'
else:
return '메모를 찾을 수 없습니다'
app.mount("/", StaticFiles(directory='static' , html= True), name='static')친구 추가 & 목록 조회 & 삭제 & 친구 이름을 통해 검색 할 수 있는 api 작성
from fastapi import FastAPI , Query , HTTPException
from pydantic import BaseModel
from pymongo import MongoClient
from bson import ObjectId
# friend
# post method
@app.post('/friend')
async def add_friend(friend : Friend):
data = {
"name" : friend.name,
"phone_number" : friend.phoneNumber
}
result = collection.insert_one(data)
return {"message": "친구가 추가되었습니다.", "friend_id": str(result.inserted_id)}
# get method
@app.get("/friend")
async def get_friends():
# MongoDB에서 모든 친구 조회
friends = list(collection.find())
# ObjectId 제거
for friend in friends:
friend['_id'] = str(friend['_id']) # ObjectId를 문자열로 변환
return friends
# get method (search by name)
@app.get("/friend/search")
async def search_friends_by_name(name: str = Query(..., description="검색할 친구의 이름")):
# MongoDB에서 이름으로 친구 검색
friends = list(collection.find({"name": name}))
# ObjectId 제거
for friend in friends:
friend['_id'] = str(friend['_id']) # ObjectId를 문자열로 변환
if not friends:
raise HTTPException(status_code=404, detail="해당 이름의 친구를 찾을 수 없습니다.")
return friends
# delete method
@app.delete("/friend/{friend_id}")
async def delete_friend(friend_id: str):
# MongoDB에서 친구 삭제
result = collection.delete_one({"_id": ObjectId(friend_id)})
# ObjectId 개념이 부족해 import 하지않으면 사용불가하다라는 것을 에러를 보고 발견
if result.deleted_count == 0:
raise HTTPException(status_code=404, detail="해당 ID의 친구를 찾을 수 없습니다.")
return {"message": "친구가 삭제되었습니다."}
# MongoDB를 선택한 이유(NoSQL)
# 빠르게 구현되어야 하고 성능보다 앞으로의 확장성을 고려해야하는 상황, 추가로 다른 요구사항이 추가될 예정이라는 것을 감안했을 때
# 유연성과 확장성 : MongoDB는 수평적 확장이 용이하며, 클러스터링을 통해 데이터베이스의 성능과 가용성을 향상시킬 수 있습니다.
# 간편한 쿼리 : MongoDB는 JSON과 유사한 BSON 형식을 사용하며, 쿼리 언어로는 간단하고 직관적인 문법을 제공합니다.
# 빠른 개발속도 : MongoDB는 스키마가 없으므로 데이터 모델링에 소요되는 시간이 상대적으로 적습니다.해결 내용 : 필요한 라이브러리들을 제대로 이해하고 사용
알게된 점 : 에러를 발견하면 제일 처음 한번 읽어보고 구글링을 해보는것을 추천 (자주 보는 에러는 한 줄만 봐도 뭔지 알게되는 신기한 현상...)
헷갈리거나 실수한 점 : 라이브러리에 대한 이해
회고 : 2주차의 2일차를 들어서서 개인적인 사정이나 문제들로 같이 공부하던 동기들이
접게되는 것을 보며 혼란스러운 마음을 다잡고 더욱 열심히 해야겠다라는 생각이 들었다.
다들 좋은 일만 있기를 바라는 마음입니다.
