getter 쓰지 말라고만 하고 가버리면 어떡해요

참고한 자료:
-
블로그
public 대신 getter와 setter를 사용하는 이유는 무엇일까
getter메소드 사용을 지양하자
getter를 사용하는 대신 객체에 메시지를 보내자
얕은복사 VS 깊은복사 -
서적
리팩터링 2판
이펙티브 자바
좋은 코드, 나쁜 코드
클린 코드
소프트웨어 악취를 제거하는 리팩토링
서문
부트캠프를 거쳐
스타트업에 갓 입사해 한 프로젝트를 맡게 된 엄준식씨.
todo 리스트를 관리하는 프로그램을 담당하게 되었다.
setter를 올바르게 작성하는 방법을 익힌 후
객체지향적 코드는 나름 잘 알게 되었다고 자신하며
위풍당당하게 프로젝트 코드를 작성하는 엄준식.
"전체 Todo 리스트 중에서 특정한 회원의 Todo 리스트를 가져오려면, filter를 사용해서 회원 이름과 일치하는 값을 가져오면 돼!
값을 걸러낼 코드로 todo.getUsername().equals(username) .. 윽 !"
그의 등 뒤로 칼이 꽂힌다. 엄준식은 뜨거운 피를 흘리며 쓰러졌다.
엄준식에게 칼을 던진 이는 다름아닌 '클린 코드'의 저자 로버트 C. 마틴.
겉으로 보기에는 그저 평범한 베스트셀러 작가이지만,
사실 그는
객체지향적이지 않은 코드를 쓰는 사람들을
무참하게 죽이고 다니는 연쇄살인마다.
엄준식이 쓴 코드의 어떤 부분이 그의 죽음을 유발한 것일까요?
유추해보건대, 자바빈 규약에서 사용하는 getXXX 메소드가 문제인 것 같아요.
우리의 주인공이 사망하기 직전에 쓴 코드도
todo.getUsername() 이라는,
todo 리스트 객체에 있는 사람 이름 값을 getter 메소드로 가져오는 함수가 들어가 있었네요.
하지만 이 메소드가 뭐가 문제죠?
getXxx 메소드는 실제로 다양한 프로젝트 코드에서 흔히 볼 수 있는 형태의 메소드이고,
getter 메소드를 써서 프로그램을 만들어도 지금까지 잘만 돌아갔는걸요.
얼핏 듣기로는 getter 메소드를 지양하라는 말을 듣기는 했는데,
정확히 뭐가 문제길래 그러는 걸까요?
getter 메소드를 사용하면 어떤 문제가 생기는 지,
그리고 그게 왜 문제가 되는 지 잘 이해하고 있나요?
또는 잘 설명해주는 블로그를 알고 있나요?
사실 저는 잘 이해하지 못하고 있었고, 그 이유를 한 번에 납득할 수 있게 설명해주는 블로그를 찾기도 어려웠습니다.
그래서, 습 ,, 조금 돌아가지만, 저는 조금 더 근본적인 질문을 해보고 싶습니다.
이런 getter 메소드를 왜 쓰는거죠?
애초에 필드 자체의 접근자를 public으로 하면 되는 거잖아요.
왜 쓸데없이 getXxx같은 메소드를 통해서만 필드의 값을 가져오도록 설계를 하는 걸까요?
참고: 이 글에서 칭하는 getter 메소드는 필드의 참조값을 그대로 넘기는, getXxx 형태의 public 메소드를 뜻합니다.
public class TodoList { private final List<TodoItem> todos = new LinkedList<>(); public List<TodoItem> getTodos() { return todos; } }
참고: 인용한 책은 번역본의 문장들이 너무 복잡한 단어들을 사용하고 내용을 알아듣기가 어려워서, 맥락을 해치지 않는 선에서 일부 단어를 읽기 쉽게 살짝씩 바꿨습니다. 원문은 책을 참고하시면 좋겠습니다. ;)
public 필드 이야기
저는 지금 맥북 에어로 블로그를 쓰고 있지만 노트북의 작동 원리는 전혀 알지 못해요.
하지만 '전원 버튼을 누르면 전원이 켜지고,
터치패드를 누르면 터치가 되고,
키보드를 누르면 글자를 입력할 수 있다' 등,
노트북에 있는 다양한 장치,
다른 말로는 '인터페이스'를 통해
노트북의 구체적인 동작 원리를 모르고도 노트북과 정상적으로 상호작용 할 수 있죠!
코드로 이루어진 객체도 이와 비슷하게 설계한다면,
어떠한 객체를 외부의 개발자 또는 또다른 객체가 사용할 때
객체 안에 있는 구성 요소들이 어떤 구조인지, 어떻게 동작하는 지 알지 못하더라도
객체가 외부에 제공하는 인터페이스를 통해
필요한 작업을 수행할 수 있도록 만드는 것이 캡슐화의 정의에요.
자동차를 예로 들어 보자. 자동차를 운전하는 데 자동차 엔진의 정확한 동작 방식을 알 필요가 있을까? 정말로 자동차에 탑재된 ABS의 동작 방식을 알아야 할까? ••• 이런 세부 사항은 자동차를 운전하는 데 필요하지 않다.
이것은 캡슐화 원칙이 추구하는 바와 정확히 일치한다. 캡슐화는 객체를 사용하는 사람에게 실제로 필요하지 않은 세부 사항을 감춘다.
게다가 캡슐화 원칙은 객체의 세부적인 구현 사항이 변하는 것을 사용자가 전혀 몰라도 되도록 도와준다.
예를 들어, 자동차에 가솔린 기관을 탑재하든 디젤 기관을 탑재하든 자동차 운전 방식은 바뀌지 않는다.
- 소프트웨어 악취를 제거하는 리팩토링 中
어설프게 설계된 객체와 잘 설계된 객체의 가장 큰 차이는
바로 클래스 내부의 데이터와 구현 방법을 외부로부터 얼마나 잘 숨겼느냐다.
잘 설계된 객체는 모든 내부 구현을 완벽히 숨겨, 실제로 구현한 코드와 외부의 사용자가 사용하는 코드를 깔끔하게 분리한다.
오직 외부에 공개한 메소드를 통해서만 다른 객체들과 소통하며 서로의 내부 동작방식에는 전혀 개의치 않는다.
정보 은닉, 혹은 캡슐화라고 하는 이 개념은 소프트웨어 설계의 근간이 되는 원리다.
- 이펙티브 자바 中
'서로의 내부 동작방식에는 전혀 개의치 않는다' 라는 것이 가능하려면
노트북의 CPU가 노트북에 노출되어있지 않는 것처럼
외부에서 객체 내부의 필드에 접근하지 못하도록 차단하는 것이
필수 조건이 되겠죠.
그럼 필드가 public 접근자를 가진 클래스는
이 캡슐화를 잘 지킬 수 있을까요?
응 어림도 없죠! (꺄르륵)
객체가 가지고 있는 필드에
todoList.todos 이렇게 바로 접근해서
값을 가져오고 조작하고, 완전히 다른 무언가로 바꿔칠 수도 있는데요!
(다음 단락에서 자세히 설명)
어떤 객체의 필드들이 public 접근자를 갖고 있다는 것은 결과적으로
객체 안에 어떤 필드가 있는지, 그 필드는 어떻게 생겼는지
아주 투명하고 무방비하게 외부에 노출하고 있는 것이고,
이는 캡슐화를 전혀 지키지 못하고 있는 모습입니다.
그렇다면 이런 형태로 캡슐화가 깨지면 구체적으로 뭐가 안 좋은 것인지,
리팩토링 서적들의 내용을 찾아보면서
같이 조금 더 자세히 알아봅시다.
부족한 캡슐화
객체가 사용자에게 구현 세부 사항을 공개하면
객체와 사용자 사이에 원하지 않는 결합력이 발생한다.
그러면 객체가 구현 세부 사항을 변경하려고 할 때마다 사용자에게 영향을 미칠 것이다.
- 소프트웨어 악취를 제거하는 리팩토링 中
출석부를 표현하는 객체가 있다고 해보아요.
import java.util.ArrayList;
import java.util.List;
public class 출석부 {
public List<Name> studentNames = new ArrayList<>();
// studentName : 학생 이름
// Index : 리스트에 등록된 순서가 학번이 돼요
}
오와 ! 학생의 이름들을 담고 있는 studentNames 필드가 public으로 열려있는 전역 변수에요.
이제 다른 개발자가 new 출석부()로 인스턴스를 만들면
출석부.studentNames로 학생부에 있는 학생 이름들 필드에 바로 접근할 수 있어요.
출석부 출석부 = new 출석부();
출석부.studentNames; <<- 필드에 곧바로 접근 가능!
멋있군요 👀
이제 사람이 출석부를 가지고 여러 가지 일을 하는 비즈니스 로직을 만들어 보아요 !
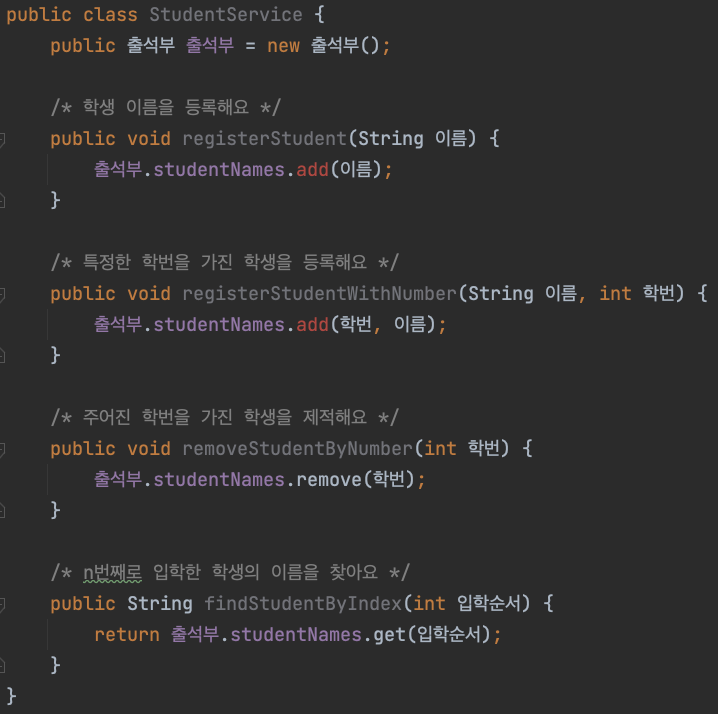
public class StudentService {
public 출석부 출석부 = new 출석부();
/* 학생 이름을 등록해요 */
public void registerStudent(Name 이름) {
출석부.studentNames.add(이름);
}
/* 특정한 학번을 가진 학생을 등록해요 */
public void registerStudentWithNumber(Name 이름, int 학번) {
출석부.studentNames.add(학번, 이름);
}
/* 주어진 학번을 가진 학생을 제적해요 */
public void removeStudentByNumber(int 학번) {
출석부.studentNames.remove(학번);
}
/* n번째로 입학한 학생의 이름을 찾아요 */
public String findStudentByIndex(int 입학순서) {
return 출석부.studentNames.get(입학순서);
}
}
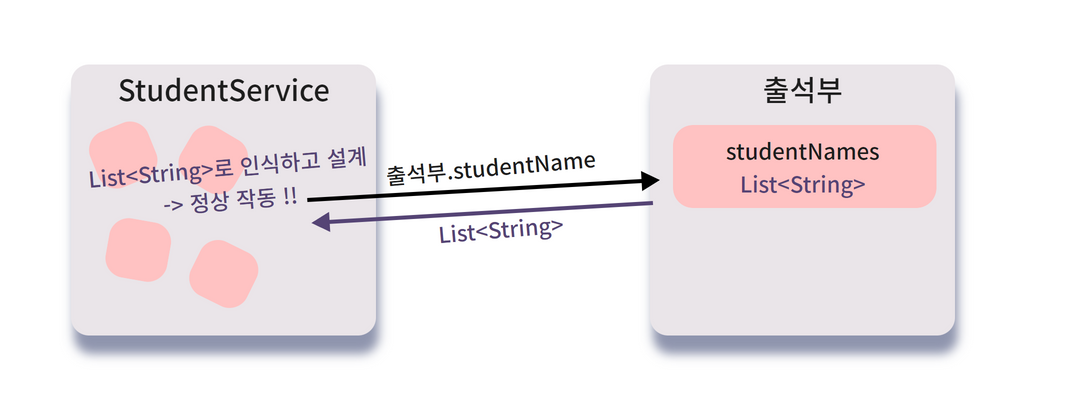
출석부.studentNames를 호출하면 필드의 자료구조인 List<Name>가 반환되므로,
비즈니스 로직에서는 List 인터페이스를 활용해 필요한 작업을 진행하도록 설계되어 있어요.
모 .. 기능도 잘 동작하고 꽤 괜찮아 보여요!
이제 해당 코드의 배포 버전을 만들어
저의 모교인 서울대학교에서 사용하게 되었습니다.(뻥임)
어느 날, 학교의 교내 규칙이 변경되어
더이상 입학 순서대로 학생의 학번을 정하지 않고
무작위로 배정된 6자리의 숫자를 학번으로 사용하기로 했다고 해보아요.
그럼 List의 인덱스로 학번을 나타낼 수 없기 때문에
학번 : 학생 이름 이렇게 짝지어진
Map 자료구조를 사용하기로 했어요.
package exam2;
import java.util.HashMap;
import java.util.Map;
public class 출석부 {
public Map<Integer, Name> studentNames = new HashMap<>();
// Integer : 학번
// Name : 학생 이름
}음 뭐 도메인 규칙이 바뀌는 건 흔한 일이죠!
그런데 출석부의 필드 하나만 바뀌었는데 무슨 일이 일어났을까요?
오 이런 ,, 출석부 객체를 사용하는 서비스레이어가 작동불능이 됐어요!
우리는 출석부.studentNames를 호출한 결과로 List<Name> 인터페이스를 가져와 사용했는데,
studentNames 필드의 자료구조가 Map<Integer, Name>으로 변한 이후엔
출석부.studentNames 를 호출한 결과로 Map<Integer, Name> 자료구조를 반환하게 되어버렸고,
Map 자료구조에는 add 같은 메소드가 없기 때문에 컴파일 오류가 난 거에요!! 😮😮
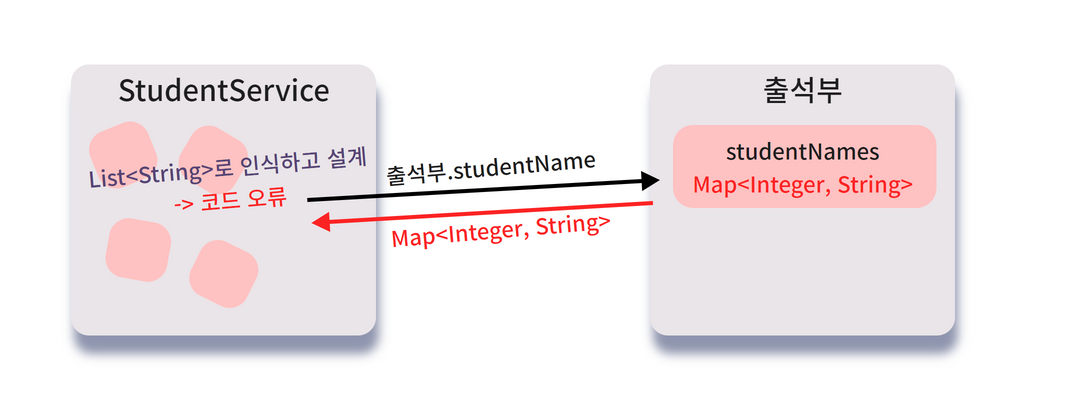
서로 다른 필드와 메소드 또는 클래스를 직접 사용하는 것을
프로그래밍의 객체지향 관련 용어로 의존한다 라고 해요.
위 예제의 경우에는 StudentService의 메소드들이
출석부 객체의 studentNames 필드를 직접 가져와서 사용하기 때문에,
즉 StudentService가 studentNames 필드에 의존하고 있기 때문에
studentNames 필드의 구조, 즉 필드의 타입이 바뀌면
StudentService가 직접적인 영향을 바로 받게 되는 거에요.
지금은 출석부 객체를 사용하는 객체가 StudentService 하나 뿐이어서 빨간 줄도 두 개만 떴지,
만약 출석부 객체의 studentNames 필드를 가져다 사용하는 객체가 100개, 1,000개라면?
필드 하나의 타입만 바뀌어도 연관된 모든 객체들에 줄줄이 빨간 줄이 뜬다면
개발자의 유지보수 생활은 정말 끔찍해질 거에요.
public 클래스에서는 멤버의 접근 수준을 package-private에서 protected 이상으로 바꾸는 순간
그 멤버에 접근할 수 있는 대상 범위가 엄청나게 넓어진다.
public 클래스에 접근할 수 있는 멤버는 공개 API이므로 그 모습 그대로 영원히 지원해야 한다.
- 이펙티브 자바 中
상상만 해도 킹받지 않나요?
하지만 문제는 여기서 끝이 아니었으니!
도메인 규칙 무시
전역 변수와 자료 구조 공개는 데이터 멤버에 대한 관대한 접근 기능을 제공하는 것보다 더 문제가 심각하다.
프로그램에 있는 어떤 다른 객체든지 전역 변수에 접근하여 변경할 수 있으며,
서로 직접 의존해서는 안 되는 두 객체 사이에 은밀한 통신 채널을 생성하기 때문이다.이렇게 전역으로 접근 가능한 변수와 자료 구조는
소프트웨어 시스템의 이해 가능성, 안정성, 테스트 가능성에
심각한 영향을 미칠 수 있다.
- 소프트웨어 악취를 제거하는 리팩토링 中
처음 상태의 출석부로 돌려볼게요!
import java.util.ArrayList;
import java.util.List;
public class 출석부 {
public List<Name> studentNames = new ArrayList<>();
// studentName : 학생 이름
// Index : 리스트에 등록된 순서가 학번이 돼요
}
public class StudentService {
public 출석부 출석부 = new 출석부();
/* 학생 이름을 등록해요 */
public void registerStudent(Name 이름) {
출석부.studentNames.add(이름);
}
/* 특정한 학번을 가진 학생을 등록해요 */
public void registerStudentWithNumber(Name 이름, int 학번) {
출석부.studentNames.add(학번, 이름);
}
/* 주어진 학번을 가진 학생을 제적해요 */
public void removeStudentByNumber(int 학번) {
출석부.studentNames.remove(학번);
}
/* n번째로 입학한 학생의 이름을 찾아요 */
public String findStudentByIndex(int 입학순서) {
return 출석부.studentNames.get(입학순서);
}
}
이제 대학교에서 프로그램을 사용하기 시작해
출석부에 학생 이름을 기록하기 시작했어요.
public class University {
public static void main(String[] args) {
StudentService service = new StudentService();
service.registerStudent(Name.of("백여우"));
service.registerStudent(Name.of("매튜"));
학생이름출력하기(service.출석부);
}
private static void 학생이름출력하기(출석부 출석부) {
for (Name name : 출석부.studentNames) {
System.out.println(name);
}
}
}
음 ! 잘 등록이 되는군요.
(Name.of 생략)
service.registerStudent("백여우");
service.registerStudent("매튜");
service.registerStudent("Boxter"); 
영어 이름도 있을 수 있죠, 잘 등록되네요 ;)
(Name.of 생략)
service.registerStudent("백여우");
service.registerStudent("매튜");
service.registerStudent("Boxter");
service.registerStudent("ぎっちゃん");
service.registerStudent("友主");
service.registerStudent("هونغجو");
service.registerStudent("#@#%@#!^^"); 
.. ???
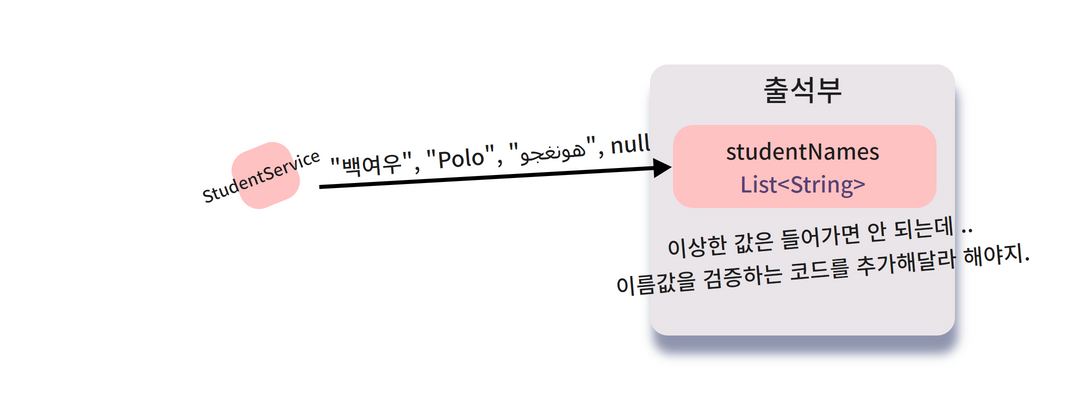
등록할 이름에 제약사항이 없다 보니
사람이름이 아닌 것도 등록해버릴 수 있는 버그가 생겨 버렸군요. !!
출석부에 이름을 등록할 때
"한글과 영어만 입력할 수 있다."
"빈 값이 들어오면 안 된다" 등의 제약사항을 추가하면 좋을 것 같아요.
import java.util.ArrayList;
import java.util.List;
public class 출석부 {
public List<String> studentNames = new ArrayList<>();
}엥 하지만 .. 필드를 선언한 코드에는 어떤 제약사항과 관련된 코드를 적어놓을 수가 없는걸요.
대신 studentNames 필드를 사용하는
registerStudent() 메소드 안에 해당 제약사항을 구현해야 겠습니다.
public class StudentService {
public 출석부 출석부 = new 출석부();
/* 학생 이름을 등록해요 */
public void registerStudent(Name 이름) {
if (빈문자열인가() || 한글또는영어가아닌가(name)) {
throw new RuntimeException();
} <<-- 제약사항 추가 !!
출석부.studentNames.add(이름);
}
/* 특정한 학번을 가진 학생을 등록해요 */
public void registerStudentWithNumber(Name 이름, int 학번) {
출석부.studentNames.add(학번, 이름);
}
/* 주어진 학번을 가진 학생을 제적해요 */
public void removeStudentByNumber(int 학번) {
출석부.studentNames.remove(학번);
}
/* n번째로 입학한 학생의 이름을 찾아요 */
public String findStudentByIndex(int 입학순서) {
return 출석부.studentNames.get(입학순서);
}
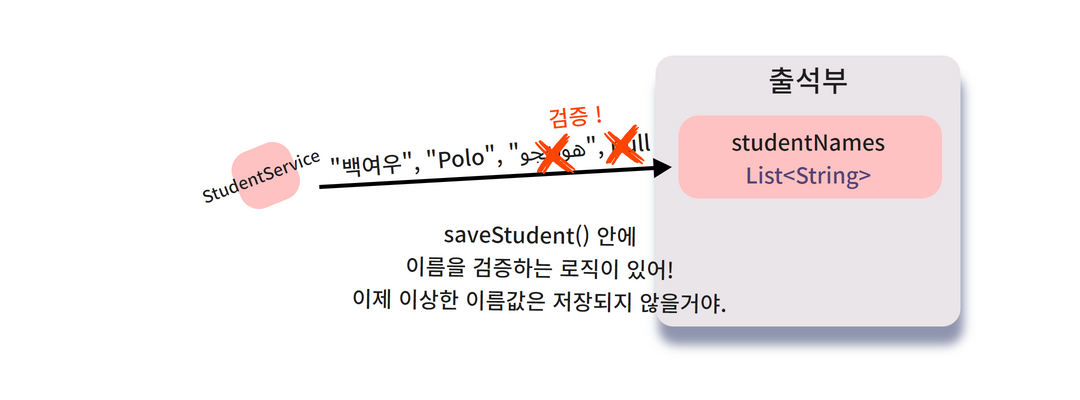
}짜잔. StudentService의 registerStudent() 메소드를 호출하면
저장할 이름이 유효한 지 검증한 후에
검증을 통과하면 출석부에 등록되도록 설계하였어요.
.. 아 하지만 StudentService의 다른 메소드들은 이 제약사항이 구현되어있지 않아요.
public으로 공개된 필드와 StudentService의 메소드들이 직접적으로 연결되어 있기 때문에
해당 메소드들을 만든 개발자에게 각각 연락해서
'studentNames 필드에 이름을 추가할 때 검증 코드를 추가해 주세요' 라고 부탁해야 해요 !
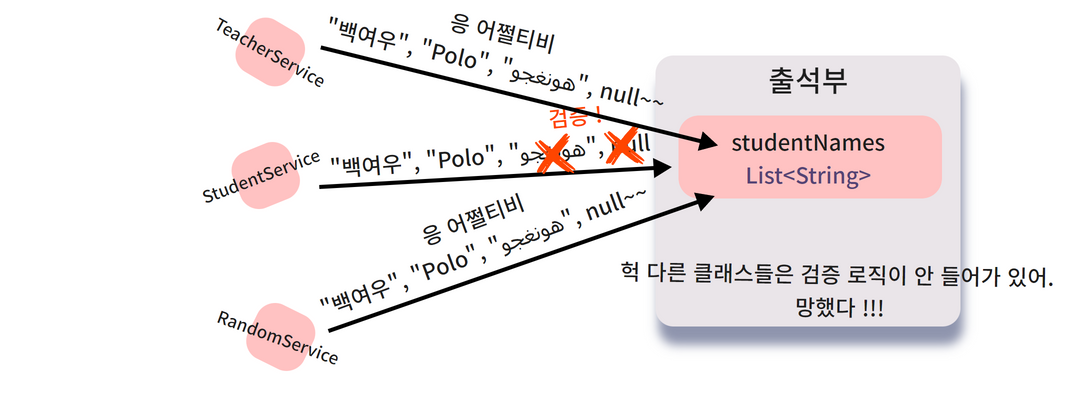
만약 studentNames 필드를 가져와
학생부에 이름을 추가하는 작업을 1,000개의 다른 객체들의 1,000개의 메소드에서 사용하고 있다면
못해도 1,000,000명의 개발자에게 전화를 돌려야 하는 .. 참사가 일어나겠죠?
그 1,000개의 클래스를 다 고쳤다고 해도
나중에 출석부를 사용하는 객체들이 새롭게 더 생겨날 때
고분고분 제약사항이 들어있는 메소드를 사용해 줄지,
아니면 또다시 필드에 직접 접근해서
"んんん" 같은 규칙에 어긋난 이름을 등록해버릴 지 알 수가 없어요.
도메인 객체를 사용할 때 지켜야 할 규칙들이 분명 있을텐데,
외부의 사용자가 객체 내부의 필드를 직접 가져다 쓸 수 있게 되면
그 규칙들을 싹 무시해버릴 수 있기 때문에
코드의 안정성이 정말 심각하게 훼손될 수 있습니다.
이런 문제가 발생하는 것은
도메인 객체의 필드를 외부의 사용자가 직접 접근할 수 있게 되어,
필드를 조작할 때 지켜야 하는 규칙이나 제약사항을
지키도록 강제하지 못하는 잘못된 구조가 원인이에요.
객체 내부의 값을 조작할 때 지켜야 하는 규칙들이
도메인 객체 내부가 아니라 외부의 객체들에 흩어져 구현되어 있기 때문에
어떤 곳에서는 지켜지고 어떤 곳에서는 안 지켜지고,
게다가 그 규칙이 한 번 수정되면 그 코드가 적혀있는 모든 클래스를 찾아다니면서 코드를 수정해야 하는
비참한 유지보수성을 가진 코드가 생겨나는 거에요 !
공개 Getter 메소드 이야기
public 필드만 아니라면 해결이 될까?
사실 어떤 분들은 이걸 읽는 내내 답답함을 호소하셨을지도 모르겠습니다.
'요새 누가 필드를 public으로 쓰노.
우리집 멈무도 코딩할 때 getter 메소드 쓴다고!'
좋아요. 그렇게 해 봅시다!
public 클래스에서는 public 필드가 아닌 접근자 메서드를 사용하라 라는 이펙티브 자바의 조언을 적용하여
필드의 접근자는 private로 바꾸고, 객체의 값을 가져오는 공개 getter 메소드를 추가했어요.
import java.util.ArrayList;
import java.util.List;
public class 출석부 {
private List<Name> studentNames = new ArrayList<>(); <<- 필드는 private로!
public List<Name> getStudentNames() {
return studentNames;
} <<- 값을 가져오는 getter 메소드!
} 이제 출석부 객체를 사용하는 서비스 클래스에서는 필드에 직접 접근할 수 없고,
getStudentNames()라는 getter 메소드를 통해서만 값을 가져와 사용할 수 있어요.
public class StudentService {
public 출석부 출석부 = new 출석부();
/* 학생 이름을 등록해요 */
public void registerStudent(Name 이름) {
if (빈문자열인가() || 한글또는영어가아닌가(name)) {
throw new RuntimeException();
}
출석부.getStudentNames().add(이름);
}
/* 특정한 학번을 가진 학생을 등록해요 */
public void registerStudentWithNumber(Name 이름, int 학번) {
출석부.getStudentNames().add(학번, 이름);
}
/* 주어진 학번을 가진 학생을 제적해요 */
public void removeStudentByNumber(int 학번) {
출석부.getStudentNames().remove(학번);
}
/* n번째로 입학한 학생의 이름을 찾아요 */
public String findStudentByIndex(int 입학순서) {
return 출석부.getStudentNames().get(입학순서);
}
}오! 우리가 흔히 작성하는 형태의 코드와 생김새가 비슷해졌네요.
뭔가 멋있군요.
다만 궁금한 것은,
getter 메소드를 사용함으로써
아까 언급했던 문제들이 하나라도 해결되었느냐는 거에요.
이게 public 필드를 그냥 가져온 것과 다를 게 있나요 ..?
전혀 개선되지 않은 문제점
변수를 private로 선언하더라도 각 값마다 조회 함수와 설정 함수를 제공한다면 구현을 외부로 노출하는 셈이다.
변수 사이에 함수라는 계층을 넣는다고 구현이 저절로 감춰지지는 않는다.
- 클린 코드 中
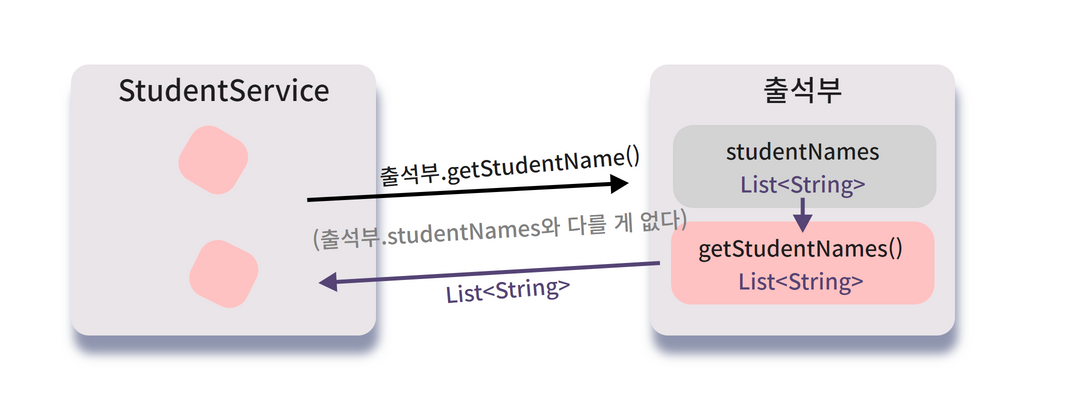
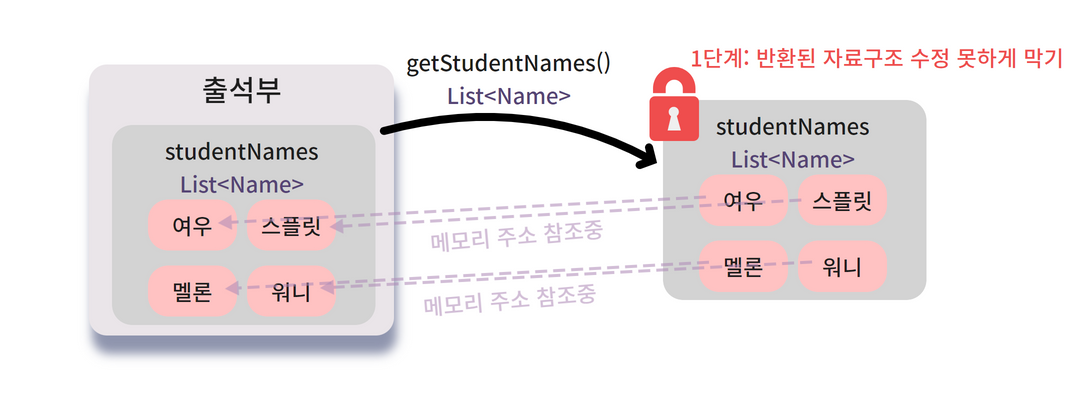
출석부.getStudentNames() 를 호출하면 무엇을 반환할까요?
출석부 객체 안에 있는
studentNames 라는 이름의 List<Name>를 가져옵니다.
그것도 참조값을요 !
그래서 외부의 객체인 StudentService에서
출석부.getStudentNames() 를 호출해 값을 가져온 후
무엇을 하고있나 자세히 보면,
결국
출석부.getStudentNames().add(이름)
출석부.getStudentNames().remove(학번)
출석부.getStudentNames().get(입학순서)
이렇게 필드의 자료구조인 List<Name>에 직접 의존하는 메소드를 여전히 쓰고있는 것을 알 수 있어요.
만약 출석부 객체의 studentNames 필드의 자료구조가 Map으로 바뀌면
getter 메소드를 사용하는 외부의 객체들은 줄줄이 에러가 뜰 거에요.
public 필드가 가지고 있던 '부족한 캡슐화' 문제가 전혀 개선되지 않은 거에요 !
게다가, 앞서 언급했듯
출석부.getStudentNames()는 studentNames 필드의 참조, 즉 메모리 주소를 그대로 넘겨줘요.
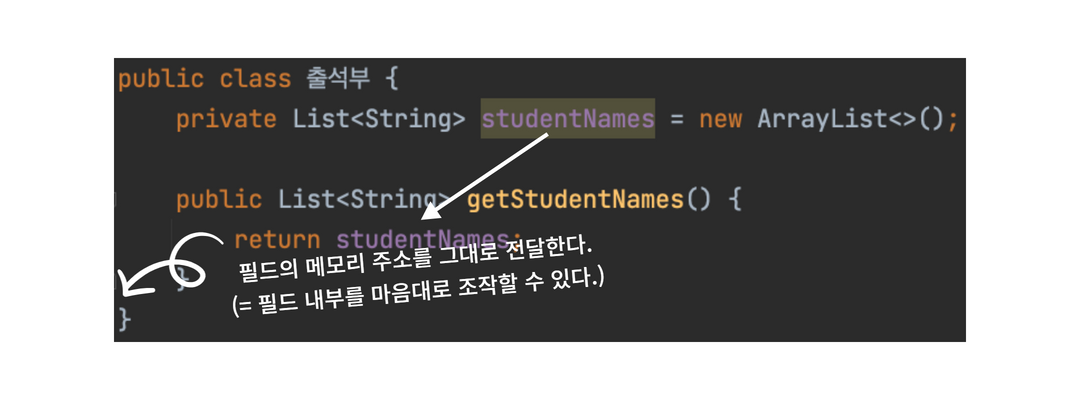
외부의 객체에서 출석부.getStudentNames().add("ぎっちゃん") 같은 코드를 통해
출석부 객체에 있는 studentNames 필드 원본을 마음대로 조작할 수 있고
이 객체를 조작할 때 필요한 제약사항을
객체 내부의 getStudentName()에 적어둘 방법이 없기 때문에
public 필드의 문제점이 가지고 있던 '도메인 규칙 무시' 문제가 똑같이 일어날 수 있습니다.
지금까지 공개 getter 메소드가 가질 수 있는 문제점에 대해 알아보았습니다.
..엥
public 필드의 문제점을 설명할 때에 비해
getter 메소드의 문제점을 설명할 때는 엄청 분량이 짧고 대충 쓴 느낌이지 않나요?
사실 .. 의도한 것입니다.
우리가 흔히 'getter 메소드를 지양해야 하는 이유' 로 구글링했을 때 검색되는 블로그에서
'getter 메소드를 쓰면 Xxx된다'. 'Xxx해서 지양해야 한다' 등의 이유들이
본질적으로는 'getXxx라는 이름의 메소드를 사용했기 때문에' 일어난 문제들이 아니기 때문이에요.
getter 메소드를 사용했을 때 객체의 캡슐화, 모듈화가 깨져서 유지보수성이 악화되는 문제는
본질적으로
객체의 필드가 public으로 공개되어 있을 때 일어나는 문제, 즉
'객체의 민감한 내부 구조를 외부에서 직접 접근' 함으로써 일어나는 것이지,
getter setter 이름을 가진 메소드를 사용했기 때문에 일어난 거다라고만 생각하면
문제에 대해 절반만 접근한 것이라고 생각합니다.

특히 우테코 과정을 처음 진행할 때 권고사항으로 제시한 객체지향 생활 체조 원칙에서
'게터/세터/프로퍼티를 쓰지 않는다' 라고만 적혀있다 보니
'세터는 뭐 알겠는데 게터는 대체 왜 ..? 값 가져오는 게 대체 왜 ??' 하면서
초반에 엄청 혼란스러워했던 기억이 나고,
주입식으로 답지를 외우듯이 getter 메소드에
stream().collect(Collectors.toUnmodifiableList()) 같은 코드를 덧붙여
'불변인 리스트를 반환했으니 괜찮겠지' 했다가
'크루님 이거 불변 아니에요' 라는 피드백을 받고 멘탈이 폭발하거나
게터 공포증에 걸려서
getter 메소드로 값을 가져와야만 하는 상황에서도
'아 게터 .. 여우님 근데 게터 쓰면 안되지 않나요 ..' 하면서
파트너와 굉장히 꺼림칙한 기분으로 코딩하는 등
마음 아픈 경험을 너무 많이 했습니다.
이제 'getter' 라는 메소드 너머에 있는
본질적인 원인을 찾아냈으니,
이것을 고치는 멋진 코드를 작성하는 방법을 알아보아요 :)
세 줄 요약
- 객체의 내부 구조를 외부에서 직접 조작하게 되면 캡슐화, 모듈화가 깨지면서 코드의 안정성이 심각하게 무너진다.
- 객체의 필드를 public으로 공개해 두면 위의 문제점이 나타난다. 필드의 접근자를 private로 하고 getXxx() 형태의 getter 메소드를 사용하더라도, 필드를 public으로 공개하는 것과 다를 바가 없는 구조라면 결국 똑같은 문제가 일어난다.
- 오해를 버려야 한다. getXxx() 형태의 메소드가 문제인 게 아니라, 객체의 구성 요소를 외부로 빼내서 외부에서 조작하게 만드는 설계 구조가 문제를 일으키는 것이다.
설계 고치기
값을 가져와 무엇을 할 건가요?
getter 메소드를 왜 쓰나요?
어떤 객체 안에 있는 필드 값이 필요해서 사용할 것입니다.
그렇다면 그 필드의 값이 왜 필요한가요?
우리가 객체 안에 있는 내부의 값을 꺼내올 때에는
그 값을 활용해 어떤 것을 하고 싶다는 목적이 있을 것입니다.
우리의 출석부 객체를 사용하는 StudentService 클래스에서는
출석부에 학생 이름을 등록하는 registerStudent() 라는 메소드가 있는데,
/* 학생 이름을 등록해요 */
public void registerStudent(Name 이름) {
if (빈문자열인가() || 한글또는영어가아닌가(name)) {
throw new RuntimeException();
}
출석부.getStudentNames().add(이름);
} 이 메소드에서는 '학생의 이름을 저장한다'는 목적을 위해
getStudentNames() 로 학생 이름들을 담고 있는 필드를 가져온 후 add() 메소드로 새로운 이름을 저장하는 거죠.
그렇다면 이 목적을 달성하기 위해
굳이 studentNames라는 List를 직접 가져와서 작업해야 할까요?
어떤 필드를 활용해 어떤 작업을 해야 한다고 해서
항상 그 필드 자체를 직접 가져와 작업하는 것은 .. 마치
의사가 환자의 허리를 스트레칭 시켜주겠다며
환자의 척추를 뽑아서 잡아 늘리는 것과도 같습니다.
척추를 뽑지 않고도 척추를 스트레칭 시켜주려면 의사는 어떻게 해야 할까요?
환자에게 '깍지를 끼고 허리를 쭉 펴세요' 하고 시키면
환자가 스스로 허리를 펴면서 척추가 쭉 늘어나겠죠?
객체로 이루어진 코드의 세계에 이것을 적용하면
객체지향적인 코드를 쓰기 위한 중요 개념인 행동, 메시지라는 용어가 등장합니다.
객체는 자율적인 존재라는 점을 명심하라. 객체지향의 세계에서 객체는 다른 객체의 상태에 직접적으로 접근할 수도, 상태를 변경할 수도 없다. 자율적인 객체는 스스로 자신의 상태를 책임져야 한다. 외부의 객체가 직접적으로 객체의 상태를 주무를 수 없다면 간접적으로 객체의 상태를 변경하거나 조회할 수 있는 방법이 필요하다.
이 시점에 행동이 무대 위로 등장한다. 행동은 다른 객체로 하여금 간접적으로 객체의 상태를 변경하는 것을 가능하게 한다. 객체는 스스로의 행동에 의해서만 상태가 변경되는 것을 보함으로써 객체의 자율성을 보장한다.
- 객체지향의 사실과 오해 中
이를 적용하여
학생의 이름들을 관리하는 출석부 객체에
'학생 이름을 등록한다' 라는 행동을 요청하는 메시지를 보내면
출석부 객체에서 메시지를 받고
이름을 등록하는 행동을 알아서 실행하도록 설계하면 되지 않을까요? ㅇ.ㅇ
/* 학생 이름을 등록해요 */
public void registerStudent(Name 이름) {
출석부.saveStudent(이름); <<- 객체에 메시지를 보낸다.
}import java.util.ArrayList;
import java.util.List;
public class 출석부 {
private List<String> studentNames = new ArrayList<>();
public void saveStudent(Name 이름) {
if (빈문자열인가() || 한글또는영어가아닌가(name)) {
throw new RuntimeException();
}
studentNames.add(이름);
} <<- 수신한 메시지를 처리하는 구체적인 방법은 객체 안에서만 다룬다.
} 동작 결과는 이전과 똑같으나,
출석부 객체를 사용하는 StudentService의 입장에서는
'XXX라는 이름의 학생을 등록해 주세요' 라는 메시지만 던져주고,
메시지를 받은 출석부는 출석부 안의 구성요소들을 활용해
학생 이름을 알아서 등록해 주기 때문에
출석부 객체 안에서 학생이름을 어떻게 관리하는지, 어떤 자료구조에 담고 있는지 알 필요가 없습니다!
실제로 출석부 객체 내부의 studentNames 자료구조가
List에서 Map으로 변경되었을 때
객체들 사이에 어떤 일이 일어나는 지 살펴봅시다.
import java.util.HashMap;
import java.util.Map;
public class 출석부 {
private Map<Name, Integer> studentNames = new HashMap<>();
public void saveStudent(Name 이름) {
if (빈문자열인가() || 한글또는영어가아닌가(name)) {
throw new RuntimeException();
}
studentNames.put(이름, [랜덤하게 생성된 학번]);
}
} 헉 ! studentNames의 자료구조가 바뀌어서, saveStudent()의 구현부가 약간 바뀌었어요. 하지만?
/* 학생 이름을 등록해요 */
public void registerStudent(Name 이름) {
출석부.saveStudent(이름); <<- 객체에 메시지를 보낸다.
} 메시지를 던지기만 하는 StudentService 객체는 그 사실을 전혀 모르기 때문에
코드에 아무런 변화도 없습니다.
객체의 내부 필드를 가지고 이런저런 작업하는 코드를
객체의 내부로 이동시키기만 했는데도
객체 내부의 필드와 외부 객체 사이의 의존성이 자연스럽게 떨어지고,
getXxx 같은 getter 메소드는 그 과정에서 자연스럽게 사라지는 것이에요.
게터를 무조건 쓰지 말라는 게 아닙니다.
비즈니스 로직을 만들기 위해서
게터로부터 값을 가져와서
비즈니스 로직을 구현하는 데에 쓰지 말라는 거에요.
- 네오(우아한테크코스 5기 코치, 물음표살인자)
getter 메소드를 호출해 값을 가져와서 어떤 작업을 수행하는 코드를 작성해야 한다면
한 걸음 멀리서 이 코드를 보면서
'그래서 내가 이 필드로 무슨 작업을 하는 거지?' 를 생각해본 후,
구체적인 작업은 객체 내부에서만 진행하게 만들고
이 작업을 '지시'하는 메소드만을 외부에 공개할 수는 없을 지 고민해보세요.
객체의 필드와 관련된 행동이 객체 내부에서만 이루어지도록 리팩토링하는 것만으로도
객체의 내부 구조와의 의존성이 떨어지고
불필요한 getter 메소드는 자연스럽게 사라질 거에요. 👀
조회를 위해 필드 값을 꼭 가져와야 겠다면
0단계 - 어떤 형태로 값을 가져와야 하나요?
하지만 이런 경우가 있을 수 있어요.
Q. 근데 나는 정말로 조회가 목적이에요.
학생부에 있는 이름들을 전부 가져와서 UI에 사용하던가 해야 한다구요!
import java.util.ArrayList;
import java.util.List;
import java.util.stream.Collectors;
public class 출석부 {
private List<Name> studentNames = new ArrayList<>();
public List<Name> getStudentNames() {
return studentNames;
} <<- 난 진짜 필요해서 쓰는 거라고 !!
}
A. 헉 정말요? 그렇게 가져와서 어디에 쓰실 건가요?
Q. 이름들을 형태에 맞게 전부 출력할 거에요 !
/* 학생들 이름을 형식에 맞게 출력해요. */
public void printStudentNames() {
List<Name> studentNames = 출석부.getStudentNames();
for (Name studentName : studentNames) {
System.out.printf("%s입니다.", studentName);
}
}A. 그럼 꼭 List<Name>이어야 하나요?
Q. ..어 ..
개발자는 객체가 포함하는 자료를 표현할 가장 좋은 방법을 심각하게 고민해야 한다.
아무 생각 없이 조회/설정 함수를 추가하는 방법이 가장 나쁘다.
- 클린 코드 中
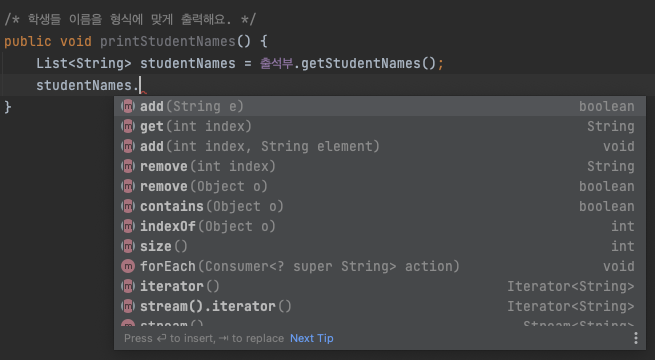
List 인터페이스의 API를 조회해보면 이렇게 많은 메소드들이 나오는데,
이 중에는 리스트 내부의 값을 조작하는 add, remove 등의 메소드들도 있습니다.
'학생 이름을 하나씩 가져와 출력한다'라는 목적을 달성하기 위해
필드의 값들을 List 인터페이스 형태로 가져오는 건 너무 투머치하지 않을까요?
어쩌면 목적에 부합하는 더 나은 타입이 있을지도 모릅니다.
예를 들면, Iterator 같은 거요!
[구현 객체]
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
public class 출석부 {
private List<Name> studentNames = new ArrayList<>();
public Iterator<Name> getStudentNames() {
return studentNames.iterator();
}
}[사용 객체]
/* 학생들 이름을 형식에 맞게 출력해요. */
public void printStudentNames() {
Iterator<Name> studentNames = 출석부.getStudentNames();
while (studentNames.hasNext()) {
System.out.printf("%s입니다.", studentNames.next());
}
}Iterator는
다음 값이 있는 지 여부를 반환하는 hasNext(),
다음 값을 가져오는 next() 딱 두개 뿐이기 때문에
List 인터페이스에 비해 API가 훨씬 간단하고
조회 목적에 딱 알맞은 인터페이스입니다 !
객체 내부의 필드 값을 직접 가져와 사용해야 하더라도,
필드의 타입 또는 자료구조를 그대로 가져오지 말고
'내가 이 값을 가져와서 어디에 쓰려고 하는 거지?' 를 고민하신 후
그 목적을 달성하는 데에 최적화된 타입 또는 자료구조의 형태로 값을 가져오는 전략을 사용해 보세요.
하지만 순차적으로 값을 조회하는 Iterator 만으로는 해결할 수 없는 작업이 정말 많아서
결국 List나 Map 등의 자료구조에 필드 값들을 담아서 가져올 때가 많습니다.
필드의 값을 자료구조에 담아 가져올 때에는
대표적으로 두 가지의 큰 문제가 생길 수 있는데,
-
필드의 값을 갖고 있는 자료구조가 add, remove, set 등의 메소드를 지원한다면
조회를 위해 가져온 값들이 사용 과정에서 변질되면서
실제 원본 값들의 상태와 달라질 수 있다는 것, -
가져온 값이 객체의 필드 원본을 가리키는 참조값을 가리키고 있기 때문에
이 값을 조작하면 객체의 원본 값도 함께 조작된다는 문제를 안고 있습니다.조회용으로 가져온 값과
객체에 저장된 원본 필드 사이의 관계가 완전히 끊어져 있어야
진정으로 캡슐화가 이루어지는 것이에요!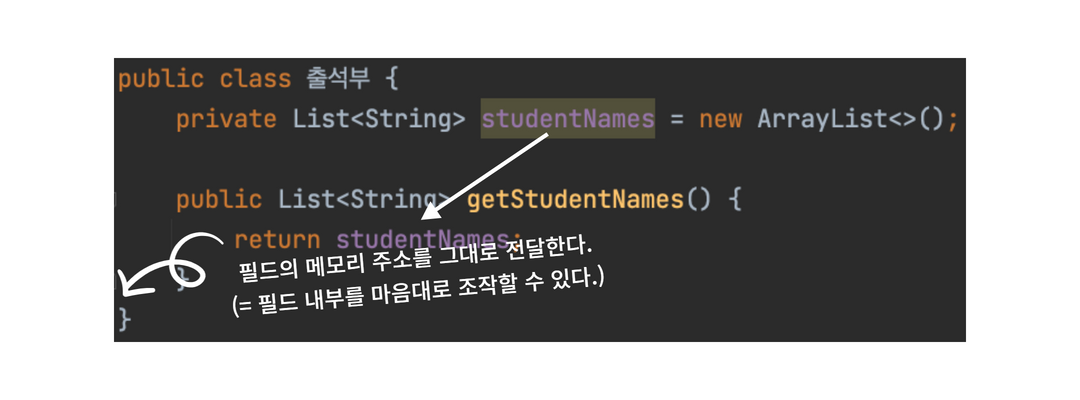

1단계 : 자료구조 수정 못하게 막기
getStudentNames() 메소드로 List<String> 자료구조의 값을 가져왔습니다.

studentNames 뒤에 온점을 찍어서, 이 변수로 어떤 작업을 할 수 있나 보았더니
add, remove, set 등
가져온 List의 구조를 변경할 수 있는 여러 메소드들이 보이네요 !
객체 안의 값을 조회하기 위한 목적으로 가져온 자료구조를 조작해서 자료구조 안에 있는 내용이 훼손된다면
값을 올바르게 조회하는 데에 큰 방해가 될 거에요.
출석부 객체이니 출석부로 예를 든다면
오늘 학교에 출석한 학생들이 적힌 출석부를 교장실에 전달하라고 제가 출석부를 전달받았는데,
교장실로 가는 길에 출석부를 슬쩍 열고 학생들 이름에 줄을 슥슥 그어
실제로 출석한 학생들이 결석한 것처럼 조작해버리는 것과 같죠. (경험담 아님)
전달할 값이 전달 과정에서 훼손되지 않게 하려면
값을 더하고 빼거나 수정하는 등의 메소드가 없거나 작동하지 않도록 만드는 게 중요한데,
이와 관련해 자바에서 멋진 것을 제공해주고 있으니
그것이 바로 ImmutableCollections(불변 컬렉션) !
ImmutableCollections에서 제공하는
ImmutableList(불변 리스트),
ImmutableSet(불변 셋),
ImmutableMap(불변 맵)의 내부 구조를 보면 엄청난 특징이 숨어있는데,
static abstract class AbstractImmutableList<E> extends AbstractImmutableCollection<E>
implements List<E>, RandomAccess {
// all mutating methods throw UnsupportedOperationException
@Override public void add(int index, E element) { throw uoe(); }
@Override public boolean addAll(int index, Collection<? extends E> c) { throw uoe(); }
@Override public E remove(int index) { throw uoe(); }
@Override public void replaceAll(UnaryOperator<E> operator) { throw uoe(); }
@Override public E set(int index, E element) { throw uoe(); }
@Override public void sort(Comparator<? super E> c) { throw uoe(); }
...자료구조의 내부를 수정하는 어떤 메소드를 호출하면
수정 작업을 하지 않고 무조건 예외가 발생하도록 구현이 되어있다는 거에요 ! 😮😮😮
또다시 출석부로 예를 들면
제가 출석부를 들고 가다가 훼손하는 것을 방지하기 위해
출석부 위에 나노코팅을(···) 발라놓는 것과 같죠.
출석부 위에 새로 이름을 쓰거나 줄을 긋지를 못하니까
원본이 안전하게 보장되는 것입니다 !
자료구조를 ImmutableCollections에서 제공하는 불변 컬렉션으로 변환하는 방법으로는 대표적으로 세 가지가 있는데,
public void exam() {
List<Name> studentNames = 출석부.getStudentNames();
List<Name> immutableStudentNames0 = List.copyOf(studentNames);
List<Name> immutableStudentNames1 = Collections.unmodifiableList(studentNames);
List<Name> immutableStudentNames2 = studentNames.stream().collect(Collectors.toUnmodifiableList());
}- List.copyOf(리스트) 를 통해
- Collections.unmodifiableList(리스트) 를 통해
- List immutableStudentNames2 = 리스트.stream().collect(Collectors.toUnmodifiableList()); 를 통해
이 중 어떤 방법을 쓰더라도
ImmutableCollections에서 제공하는 불변 자료구조를 반환해 줍니다 !
하지만 자료구조를 잠궜다고 해도 여전히 중요한 문제가 남아있는데,
위에서 한 번 적었듯
어떤 값들을 자료구조에 복사해서 왔다고 하더라도
자료구조 안에 있는 값들이 원본의 메모리 주소를 향하고 있으면
복사한 값에 변경이 일어났을 때 원본의 값도 변경된다는 거에요.
어째서 이런 일이 일어나는가를 알기 위해서는
자바 언어를 사용할 때 생기는 메모리 구조에 대한 이해가 필요한데,
이 현상을 잘 설명해준 블로그가 있으니 참고하시면 좋을 것 같아요 !
2단계 : 원본과의 연결 끊기
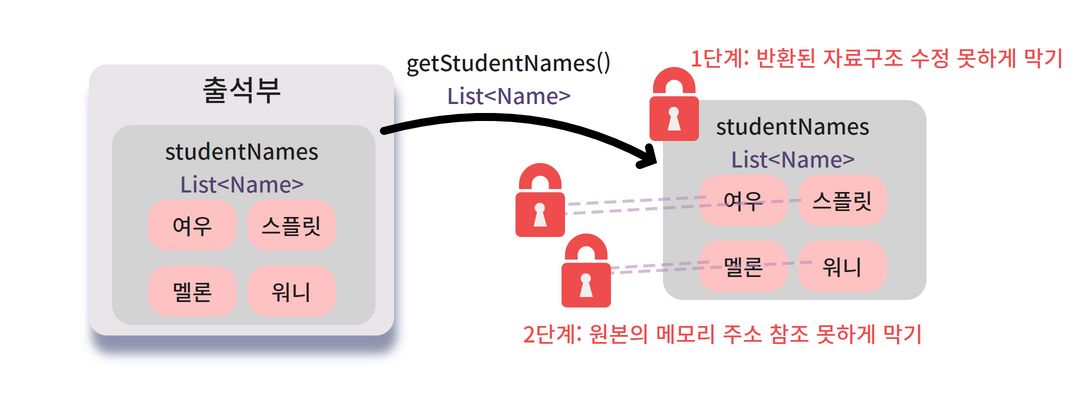
객체에 들어있는 필드의 원본 값과
getter 메소드로 가져온 조회용 값이 연결되어 있다는 것을 어떻게 확인할 수 있을까요?
출석부 객체를 이용한 테스트 코드로 확인해 봅시다.
[출석부 객체]
import java.util.ArrayList;
import java.util.List;
public class 출석부 {
private final List<Name> studentNames;
public 출석부(List<Name> studentNames) {
this.studentNames = studentNames;
}
public List<Name> getStudentNames() {
return Collections.unmodifiableList(studentNames);
} <<- 필드 값들을 구조를 수정할 수 없는 불변 리스트에 담아요
}[출석부 리스트에 들어있는 Name 객체]
public class Name {
private String name;
public Name(String name) {
this.name = name;
}
public void setName(String name) {
this.name = name;
}
public String getName() {
return name;
}
}[테스트 코드]
import org.junit.jupiter.api.DisplayName;
import org.junit.jupiter.api.Test;
import java.util.Arrays;
import java.util.List;
public class 출석부Test {
@Test
@DisplayName("원본 이름과, getter 메소드를 통해 가져온 조회용 이름은 '동일(identical)' 하다.")
void given출석부_ComparingIdentity() {
Name fox = new Name("여우");
Name maco = new Name("마코");
System.out.println("원본 여우 이름의 메모리 주소 : " + fox);
System.out.println("원본 마코 이름의 메모리 주소 : " + maco);
List<Name> names = Arrays.asList(fox, maco);
출석부 출석부 = new 출석부(names);
List<Name> 조회용Names = 출석부.getStudentNames();
System.out.println("조회용으로 가져온 여우 이름의 메모리 주소 : " + 조회용Names.get(0));
System.out.println("조회용으로 가져온 마코 이름의 메모리 주소 : " + 조회용Names.get(1));
}
}짜잔 무엇을 나타내는 테스트 코드일까요?
위 코드에서는
1. '여우', '마코'라는 이름을 담은 출석부 객체를 생성하고,
2. 출석부 객체에서 getter 메소드를 통해 이름들 값을 복사해 가져온 후
3. 원본과 복사본이 '동일'한 지 확인하기 위해 작성했어요.
(자바에서 '동일성'과 '동등성'은 큰 차이가 있습니다 !)

위 테스트를 실행하면
원본 값과 복사본 각각이 가지고 있는 메모리 주소를 출력해서 확인해볼 수 있습니다.
(정확히는 해시 코드인데, hashCode() 메소드를 재정의하지 않으면 객체의 메모리 주소를 이용해 고유한 해시 값을 만들어요)

확인해보니
원본의 메모리 주소와, getter 메소드로 가져온 복사본의 메모리 주소가
완전히 같은 것을 확인할 수 있어요!
가져온 Name 객체에는 setName() 처럼 내부 필드의 값을 수정할 수 있는 메소드가 있어서,
복사본의 setName() 을 호출해 이름을 바꾸면
나는 분명 복사본의 이름을 바꾸었는데 원본 출석부의 이름이 바뀌어 있는 기상천외한 광경을 볼 수 있을 것입니다.
이것을 막기 위해서는
getter 메소드를 호출하여 복사한 조회용 값이 원본의 메모리 주소를 향하지 않게,
즉 원본과 똑같지만 완전히 새로운 복사체를 만들어 가져와야 합니다.
어떻게 할 수 있을까요?
내부 값까지 전부 복사하기 (깊은 복사)
public List<Name> getStudentNames() {
return Collections.unmodifiableList(studentNames);
}getter 메소드를 잘 보면,
값들을 담는 자료구조는 변경이 불가능한 불변 구조를 사용하지만
그 안에 담을 값들로는 필드 값을 사실상 그대로 가져와 담고 있습니다.
이를 개선하려면
원본 값인 Name 하나하나까지도 새로운 객체로 만들어준 후 리스트에 담는다면
원본과는 상관없는 완전히 새로운 조회용 값을 받을 수 있을 거에요!
한 번 시도해보고 테스트해 보겠습니다.
public List<Name> getStudentNames() {
List<Name> clonedStudentsNames = new ArrayList<>();
for (Name studentName : studentNames) {
clonedStudentsNames.add(new Name(studentName.getName())); < 1. 같은 이름을 가진 새로운 Name 객체를 만들어 리스트에 담아요
}
return Collections.unmodifiableList(clonedStudentsNames); < 2. 새롭게 만든 Name 값들을 수정 불가능한 리스트에 담아 보내요
}필드의 값을 그대로 리스트에 담는 원래 구조에서
Name 값 하나하나에 대해 new Name()을 사용해
새로운 Name 객체로 바꾼 후 리스트에 담아 오도록 변경되었어요.
stream 사용법이 익숙하다면 이케 바꿀 수 있음 ㅎ-ㅎ
public List<Name> getStudentNames() { return studentNames.stream() .map(name -> new Name(name.getName())) .collect(Collectors.toUnmodifiableList()); }
이제 위에서 실행했던 테스트 코드를 똑같이 다시 실행하면 !

new Name()으로 새로 만든 객체이기 때문에
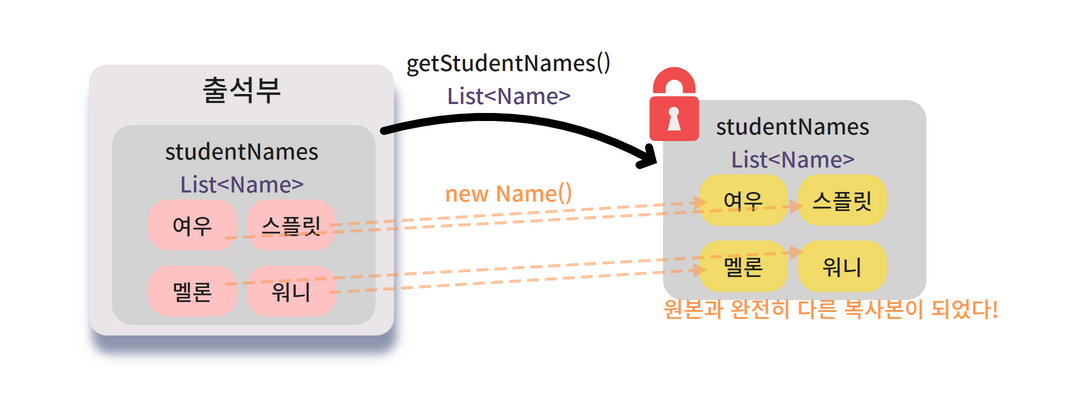
이제 복사본의 값들이 원본과 다른 메모리 주소를 갖게 되었네요!
복사본에서 setName() 등으로 이름을 바꾼다고 해도
원본에는 전혀 영향이 가지 않으니
getter 메소드 호출로 인해서 캡슐화가 망가질 일이 더이상 생기지 않게 되었습니다.
우와 박수 ~~
new 생성자를 쓰는 것이 번거롭다면
복사하려는 객체가 Cloneable 인터페이스를 구현하게 만들어,
객체.clone() 메서드를 호출해 간단하게 깊은 복사를 하는 방법도 있어요.
하지만 Cloneable 인터페이스와 관련해 주의해야 할 점이 몇가지 있어,
이와 관련한 내용은 구글에 'Cloneable' 키워드로 검색하신 후
관련 블로그 글 또는 서적을 참고해주시면 될 것 같아요!
지금까지 getter 메서드가 가지고 있는 본질적인 문제점과
문제점을 해결하는 방향으로 코드를 작성하는 방법에 대해 이야기해 보았습니다.
2월 17일에 쓰기 시작했으니, 다 쓰는데에 1달 10일 걸렸네요!
(6일간의 작성과 35일의 딴짓)
더 보충할 내용이 있거나 틀린 내용이 있다면 피드백 남겨주세요!
읽어주셔서 고마워요 •́︿•̀

15개의 댓글













정말 많은 도움이 되었습니다! 한 가지 바라는 점이 있다면, 다름이 아니오라 코드부분들에 ```java 해주시면 가독성이 더 좋을 것 같습니다!
//```java
public class TodoList {
private final List<TodoItem> todos = new LinkedList<>();
public List<TodoItem> getTodos() {
return todos;
}
}
///```(java맞죠? 제가 java를 안 써봐서...)
잘읽었습니다~~~ box's'ter입니다