
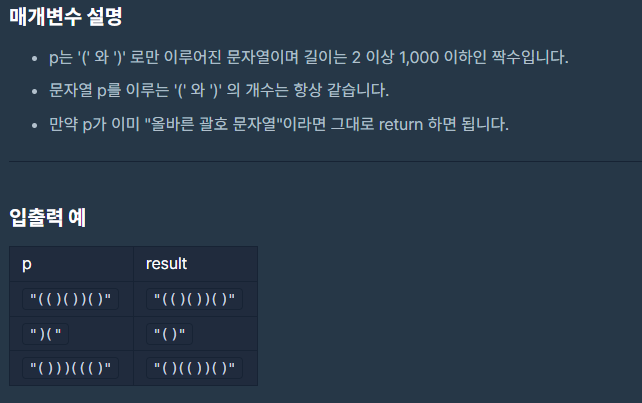
문제



풀이
주어진 알고리즘을 절차적으로 구현하면 다음과 같다.
2번과 3번은 너무 길어서 각각 divide와 correct라는 함수를 따로 만들었다.
def divide(p):
left = right = 0
for i in range(len(p)):
if p[i]=='(':
left += 1
else:
right += 1
if left == right:
return p[:i+1], p[i+1:]
def correct(u):
stack = []
for j in range(len(u)):
if u[j]=='(':
stack.append(1)
else:
if not stack:
return False
stack.pop()
return True
def solution(p):
answer = ""
# 1. 빈 문자열 반환
if not p:
answer = p
# 2. 균형 잡힌 문자열로 분리
u, v = divide(p)
print(u, v)
# 3. u가 올바른 괄호 문자열인지 검사 (True)
if correct(u):
return u + solution(v) # TypeError: cannot unpack non-iterable NoneType object
# 4. u가 올바른 괄호 문자열인지 검사 (False)
else:
# 4-1. 빈 문자열에 ( 추가
answer += '('
# 4-2. 문자열 v를 1번부터 수행하여 추가
answer += solution(v)
# 4-3. 문자열에 ) 추가
answer += ')'
# 4-4. u의 첫번째와 마지막 문자 제거, 나머지를 반전시켜 추가
for i in u[1:len(u)-1]:
if i == '(':
answer += ')'
else:
answer += '('
# 4-5. 생성된 문자열 반환
return answer코드를 좀 더 줄여보자
-
2번과 3번은 사실 합칠 수 있다
균형 잡힌 문자열은 (와 )의 개수가 같은 것이고
올바른 괄호 문자열은 (와 )가 한쌍을 이뤄 열린 괄호가 없는 상태이다.
즉 올바른 괄호 문자열이 되려면 반드시 균형 잡힌 문자열이 되어야 하고 균형 잡힌 문자열은 올바른 괄호 문자열에 포함된다.
따라서 처음부터 올바른 괄호 문자열인지를 검사하면 균형 잡힌 문자열 조건도 자동으로 충족하게 된다. -
람다 이용하기
list(map(lambda parameter: function (condition), range[slicing])위 문법을 이용해서 함수를 한 줄로 만들 수 있다.
문자열 p의 첫 문자와 마지막 문자를 제거하고, (이면 )으로, )이면 (으로 뒤집는 함수는 다음과 같다.
list(map(lambda x:'(' if x==')' else ')',p[1:i]))filter, reduce 같은 주옥같은 기능이 많은데 이를 활용해서 코드 길이를 크게 줄일 수 있다.
- ''.join 리스트 이용해서 한줄로 완성하기
def solution(p):
# 1. 빈 문자열 출력
if p=='':
return p
res = True
cnt = 0
for i in range(len(p)):
# 균형 잡힌 문자열은 올바른 괄호 문자열에 포함 관계이므로 올바른 괄호 문자열 여부만 검사
if p[i]=='(':
cnt += 1
else:
cnt -= 1
if cnt < 0:
res = False
if cnt == 0:
# 3. 문자열 u가 올바른 괄호 문자열 일 때
if res:
# 2. 문자열을 u, v로 분리하고
# 3-1. 문자열 u과 1단계부터 시행한 v의 결과를 출력
return p[:i+1]+solution(p[i+1:])
# 4. 문자열 u가 올바른 괄호 문자열이 아닐 때
else:
return '('+solution(p[i+1:])+')'+''.join(list(map(lambda x:'(' if x==')' else ')',p[1:i])))


홀로서기 기록장