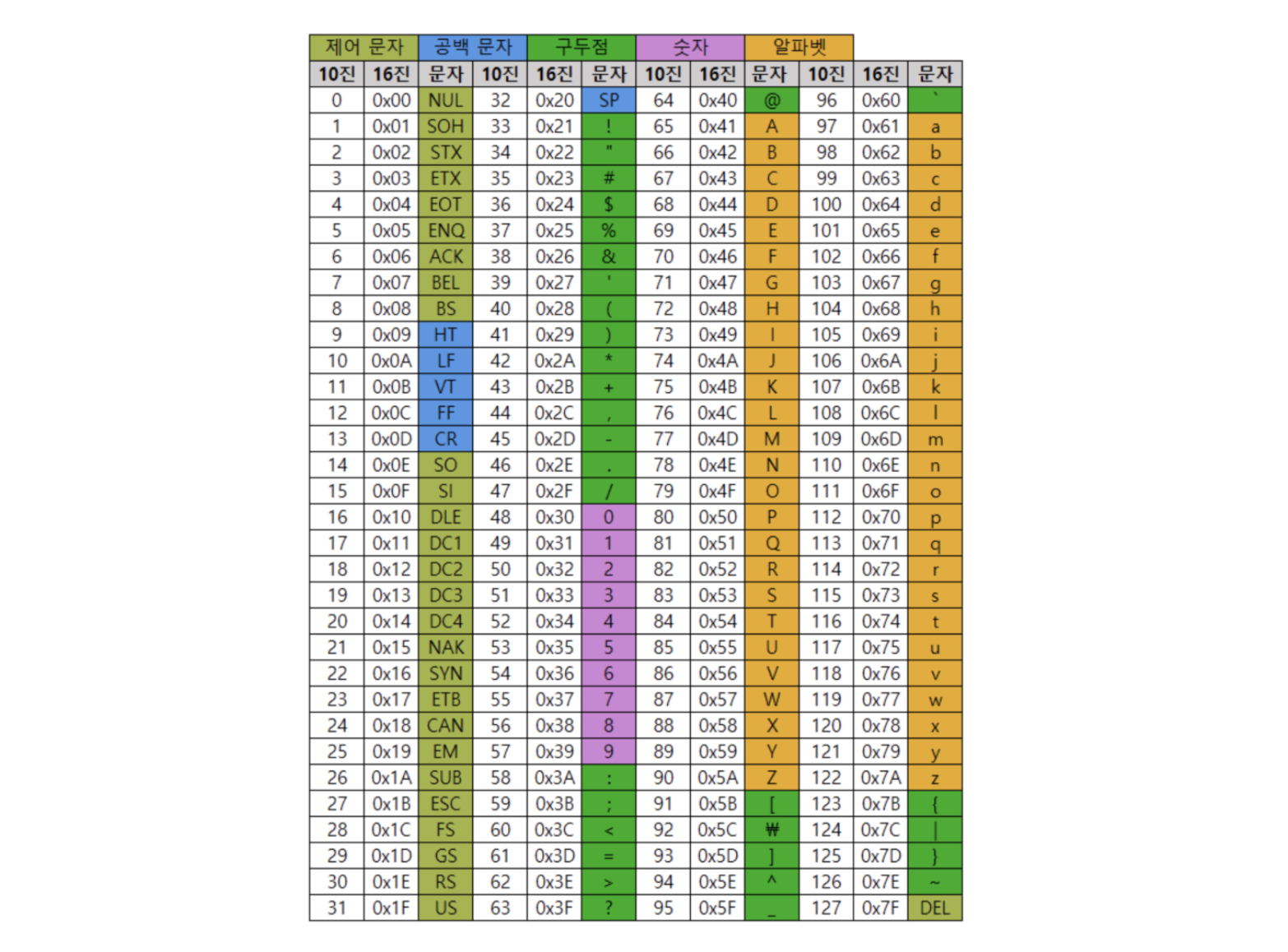
📌 아스키 코드 (SBCS, Single Byte Character Set)
: 최초의 문자열 인코딩 (ASCII, American Standard Code for Information Interchange), 미국 정보 교환 표준
: 7bit로 구성되어 있으며, 영어를 위한 문자, 숫자, 특수문자, 기호 등 128개 문자를 표현할 수 있다.
: 모든 문자를 1Byte로 간주 (0-255의 범위 내에 있다.)
1. 장점
- 알파벳(대문자, 소문자)들과 확장 문자를 포함하여 총 256개를 넘지 않는 문자로 이루어져 있다.
- 1Byte(는 256가지의 표현이 가능)를 가지고 충분히 표현할 수 있기에 1Byte의 char형을 사용해서 표현을 할 수 있다.
2. 단점
- 아스키 문자 코드만으로는 한글이나 일어 등의 다른 문자를 표시할 수 없다.
- SBCS로는 프로그램을 국제화(Internationalization(i18n))할 수 없다.
📌 유니 코드 (WBCS, Wide Byte Character Set)
: 전 세계의 모든 문자를 컴퓨터에서 일관되게 표현하고 다룰 수 있도록 설계된 산업 표준 (유니코드 협회 제정)
: 모든 문자를 2Byte로 간주 (주의 : 인코딩에 따라 가변적으로 적용됨)
: 모든 코드값이 일괄적으로 16비트로 할당
: 대표적인 인코딩 방법 : UTF-
1. 장점
- 유니코드는 지구상에서 통용되는 대부분의 문자들을 담고 있다.
- 2Bytes를 사용하므로 65536개의 표현 범위 덕분에 아스키 코드가 가지는 한계 극복
2. 단점
- 아스키코드의 Char은 1바이트, 유니코드의 Char은 2바이트이기 때문에 printf , scanf 등의 함수는 유니코드와 맞지 않는다.
(함수 사용을 위해서는 wprint등 새로 정의된 다른 함수를 사용해야 한다.)
📌 멀티 바이트 코드 (MBCS, Multi Byte Character Set)
: 1Byte만으로는 표현되지 않는 언어들을 표현하기 위해 만들어진 개념 (MicroSoft에서 만든 표준)
: 영어 1Byte, 한글 2Byte로 간주
: 유니코드가 생기기 이전 다국어를 표현하기 위해 사용했던 방식
: MBCS는 SBCS와 DBCS를 묶어놓은 Character Set이다.
✔️ DBCS
: 하나의 문자세트에 부여된 글자값이 두 바이트 (0-65535의 범위 내에 있다.)
: 8비트로 처리할 수 없을 정도로 문자의 종류가 많은 중국, 한국, 일본 그리고 대만 등에서 주로 사용한다.
- ANSI, UTF-8 포함
1. 장점
- 특정 문자 집합마다의 코드페이지가 존재하여 영어 이외의 나라 문자 표현이 가능하다.
✔️ ANSI(American National Standard Institute)
: 8bit로 구성되어 있으며 256개의 문자를 표현할 수 있다.
: ASCII의 확장판으로 ASCII에서 1bit를 더 사용한다.
(앞 7bit는 ASCII와 동일하고, 뒤에 1bit를 이용하여 다른 언어의 문자를 표현한다.)
: 새로 추가 된 128개 문자로는 모든 언어의 문자를 표현할 수 없어서 코드페이지가 생겼다.
(각 언어별로 Code 값을 주고, Code마다 다른 문자열 표를 의미하도록 약속)
- ANSI = ASCII(7bit) + CodePage(1bit)
✔️ 코드페이지(Code Page)
: 마이크로소프트 테크넷에 게재된 각종 컴퓨터용 코드
: 특정 문자 인코딩 테이블을 위해 쓰이는 전통적인 IBM 용어
- 문자 인코딩 테이블 : 0부터 255까지의 정수를 표현하는 단일 옥텟(Octet, 바이트)이라고 불리는 일련의 비트들이 특정한 문자와 결합하여 도표화(Mapping)한 것
2. 단점
- ASCII를 제외하고는 각 DBCS들이 모두 다르다.
📌 T 매크로
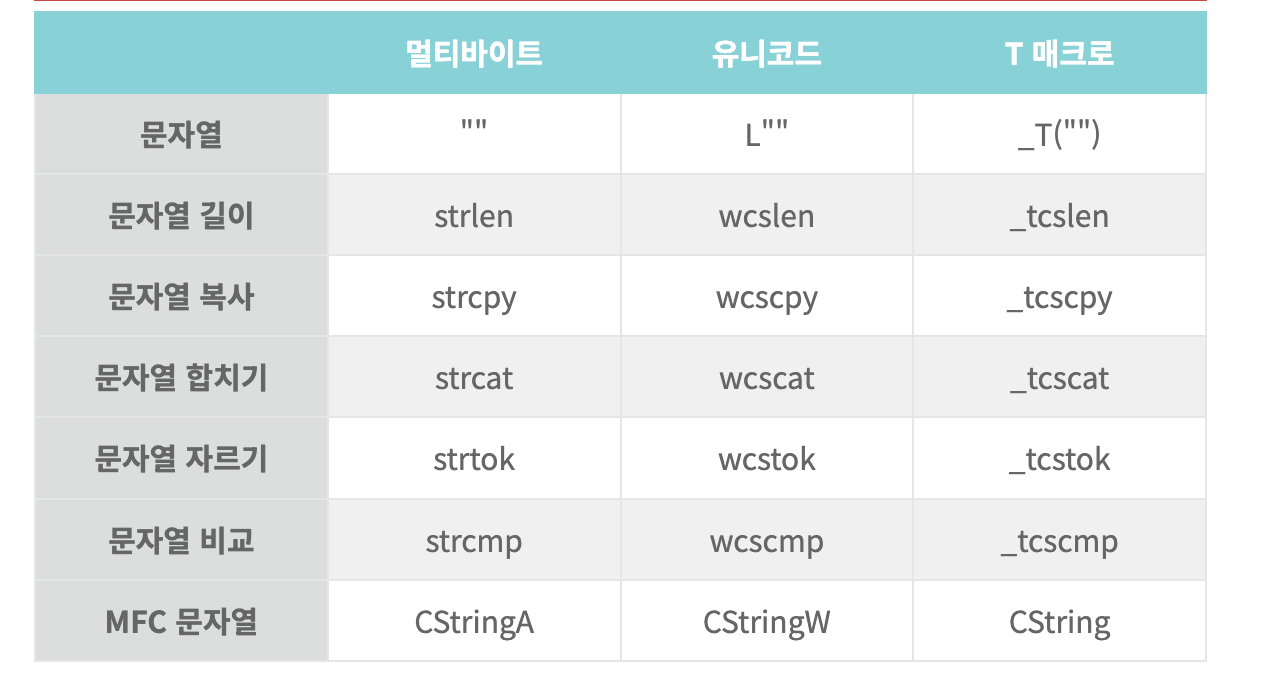
❗️ 문자를 처리할 때
- 멀티 바이트 : 기본적으로
Char사용- 유니 코드 :
wchar_t사용
참고: 이쿠의 슬기로운 개발생활:티스토리 | https://ikcoo.tistory.com/227
