
java
OOP
- 캡슐화 : 데이터 은닉
- 상속 : 코드의 재사용성, 확장용이(오버라이딩)
- 다형성(상속전제조건) :
- 메소드 다형성(오버로딩, 오버라이딩)
- 객체 다형성
참조변수 = 객체 // 공간 = 값 (공간에다가 값을 넣는것이 변수선언) 따라서 오른쪽이 더 큰 범위여야 함(묵시적 형변환, 데이터 손실X)
오른쪽이 왼쪽보다 더 작은 범위이면(명시적 형변환, 데이터 손실O)
A <- B <- C
A <- B <- C2 (B가 A를 상속, C,C2가 B를 상속하는 관계)에서
A a = new A()
A a = new B()
A a = new C()
A a = new C2()가 가능함
정적타입언어 : 자바, C 등
동적타입언어 : 자바스크립트, 파이썬
결합도 down : 결합도를 낮추기위해 인터페이스 활용설계
응집도 up : mvc
상속은 조상에대한 종속성으로 인해 결합도가 높아지기 때문에, 꼭 필요한 것만 상속받아야 함
위임상속 : 물려받는것이 아니라서 실제 상속은 아니고, 객체지향 모델링에서 영구적인 연관관계 -> 상황에 따라 바꿀 수 있음 결합도가 낮추기 위한 방법.
자바 특징
- Multi Threading
- 메모리 관리 X / GC(Garbage Collector)가 자체적 메모리 관리
포인터 개념 X => reference 개념 제공
자바 동작과정
xxx.java
-> compile (javac xxx.java)
xxx.class(Bytecode) | interpretor (JVM)
-> execute (java xxx)
자바 환경
- JRE(Java Runtime Enviroment) : JVM + core API
- JDK(Java Development toolKit) : JRE + 개발도구(컴파일러, ..)
자바 클래스
class XXX{
멤버변수
생성자
메소드
}자바 데이터타입
-
Primitive type
- 원자성의 data
- 논리형 : boolean (true, false ; 8bit) => 다른 언어와 달리 숫자 호환 X
- 문자형 : char ('a' ; single quotation ; 16bit) => 'a'(문자) != "a"(문자열 ; 객체)
- 정수형 : byte(8bit), short(16bit), int(default ; 32bit), long(L ; 64bit)
- 실수형 : float(F ; 32bit), double(default ; 64bit)
byte < short < int < long < float < double
-----------------------------------------> 묵시적 형변환
<----------------------------------------- 명시적 형변환 -
non-Primitive type
- Reference type; 참조타입- class type
- interface type
- array type
java는 2Bytes체제의 유니코드를 지원한다.
유니코드는 u0000 ~ uffff까지 표현됨
u00[**]에서 [**]의 1바이트는 ASCII코드
char ch = 'A';
char ch = 65;
char ch = '\u0041'; //A의 유니코드표기 (4*16^1+1*16^0 = 65)자바 조건분기문
- if
- switch
switch(표현식)에서 표현식에 올 수 있는 datatype : byte, short, char, int, string (long, float, double은 올 수 없다.)
자바 반복문
-
while
while(조건식){반복내용}
do{반복내용}while(조건식); -
for
for(초기화;조건식;증감식){반복내용}
for(데이터타입 변수 : 반복집합객체)
반복 가능한 집합들의 원소들을 꺼내어 처리 -> array, iterable 타입
==> 자료구조사용에 대한 추상화,
==> (반복 가능한 집합의 원소)값의 수정이 불가능(조회 목적)
자바 배열
Reference Type (객체)
장점
1) 데이터 관리 용이함
- 반복문과 결합하여 일괄처리 가능
- 리턴값, 매개변수 전달시 활용 가능
2) 처리성능 효율적
단점
1) 크기가 고정적 (하지만 고정이기 때문에 처리성능이 효율적이게 됨)
- 크기를 변경하고 싶으면 배열 새로 생성
1차원 배열 생성
데이터타입[] 참조변수 = new 데이터타입[size]
1차원 배열 사용
참조변수[index]
index는 첫번째 원소 기준 offset 개념
그렇기 때문에, 0 ~ 길이-1 까지가 유효인덱스가 됨
1차원 배열 초기화
-데이터타입[] 참조변수 = new 데이터타입[]{값1,값2,,,,}
초기화를 할 때는 들어간 초기값의 개수에 따라 자동으로 size가 결정되기 때문에 직접 size를 명시하지 않는다.
Wrapper Class
- Primitive Type을 Wrapper Class로 Boxing하여 객체화함
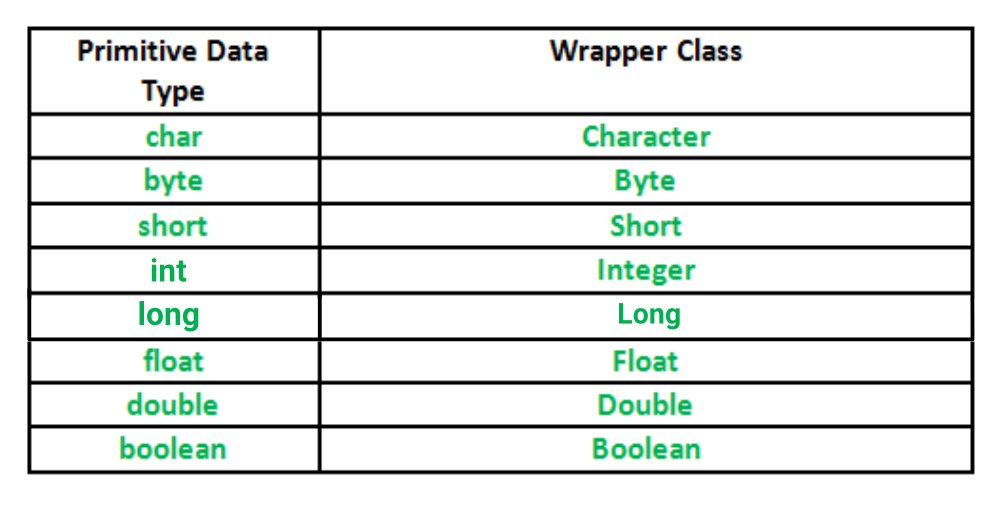 8개의 Primitive Type에 각각 대응되게 다 존재함.
8개의 Primitive Type에 각각 대응되게 다 존재함.
ex)
Integer i = new Integer(10);java 5.0 부터 사용자들이 int와 Integer가 서로 호환되는 것 처럼 느껴지게 Auto Boxing, Auto UnBoxing을 지원함.
따라서 java의 모든 데이터타입은 객체로 표현이 가능해진다.
그래서 최상위 타입인 Object Type은 다형성 때문에 존재.
Scanner
Stream : 데이터의 흐름. 통로
- InputStream
- OutputStream
System.in // 표준입력 -> InputStream 사용법 숙지
java.util.Scanner // 요리로치면 밀키트 같은 놈
System.out // 표준출력
System.err // 표준에러출력
System.setIn() // BufferedReader를 사용하면 시간을 30%까지도 절약할 수 있다.
수동기어 차량이 연비가 더 좋은느낌
Array
다차원배열 : Array of Array, 배열 여러개를 모아서 다시 배열로 관리
int[][] arr;
int[][][] arr2;ex)
영업1팀의 2020년 1/4, 2/4, 3/4, 4/4 분기 영업실적
int[] year = new int[4];
or
int year[] = new int[4]; // 이렇게 표현하는것도 나쁘지 않음2018년, 2019년, 2020년 영업1팀의 1/4, 2/4, 3/4, 4/4 분기 영업실적
int[] years[] = new int[3][4]; // 새롭게 생성할 배열크기를 가장 왼쪽에 둔다영업1팀, 영업2팀의 2018년, 2019년, 2020년 1/4, 2/4, 3/4, 4/4 분기 영업실적
int[][] teams[] = new int[2][3][4]; 서울, 부산, 대전, 광주의 각 영업1팀, 영업2팀의 2018년, 2019년, 2020년 1/4, 2/4, 3/4, 4/4 분기 영업실적
int[][][] region[] = new int[4][2][3][4]; 여기 region의 배열 객체수는 1 + (1 * 4) + (1 * 4 * 2) + (1 * 4 * 2 * 3) = 37개이다.
클래스 디자인
객체 : 실세계(Real World)에 존재하는 유/무형의 모든 것
- 속성(명사형)과 행위(동사형)를 갖는다.
ex) 자동차 (유형)
- 속성 : 주행거리, 차종, 색상, 마력,,,
- 행위 : 시동켜기, 시동끄기, 주행하기,,,
ex) 계좌 (무형)
- 속성 : 계좌번호, 예금주, 잔액, 이체한도,,,
- 행위 : 잔액조회, 입금, 출금, 송금,,,
클래스 : 객체에 대한 정의이자, 객체를 찍어내는 틀
| 클래스 | 객체 |
|---|---|
| 붕어빵틀 | 붕어빵 |
| 공장 생산라인 | 제품 |
| 건물설계도 | 건물 |
같은 클래스로부터 생성된 객체는 모두 같은 속성과 행위를 가지는데,
객체마다 고유한 속성값을 가질 수 있다.
-> 같은 클래스에서 생성된 객체라도 모두 다르다!
String s1 = "hello";
String s2 = new String("hello");s1 == s2 ? false
String s3 = "hello";자바에서 String s1 = "hello"는 값이 불변하는 리터럴
값이 변하지 않는 객체는 재사용을 위해 문자열상수 pool에 hello가 등록됨
new로 생성한 객체는 heap에 올라감 -> 같은 내용이라도 계속 새로 생성
s3는 생성될 때 문자열상수 pool에 등록된 "hello"를 참조함
따라서, s1 == s3 ? true
| 객체 | 클래스 |
|---|---|
| 속성 | 변수 (클래스변수(static), 인스턴스변수(non-static)) |
| 행위 | 메소드 |
- 사람
- 속성 : 이름, 나이
- 행위 : 나이먹기, 잠자기,,,
class Person{
//member
String name;
int age;
//method
increaseAge(){}
Sleep(){}
}
//객체생성
클래스이름 참조변수 = new 생성자호출; -> 객체생성시 초기화를 담당하는 특별한 메소드
Person p1 = new Person("배문규", 29);
Person p2 = new Person("정다운", 29);Class Area에
Person 바이트코드가 올라감
Heap에
인스턴스변수가 올라감
Stack에
p1, p2 레퍼런스변수가 올라감
class Person{
//class member
static char gender;
//instance member
String name;
int age;
//method
increaseAge(){}
Sleep(){}
}
Person p1 = new Person("배문규", 29);
Person p2 = new Person("정다운", 29);
p1.gender = 'm';
-> p2.gender is 'm'Class Area에
Person 클래스 바이트코드와 클래스변수인 gender도 올라감
클래스 구성요소
-
멤버변수
-
클래스멤버(static) 변수 :
클래스의 상태
클래스 메모리 로드시 1번만 할당 -
인스턴스멤버 변수 :
객체의 상태
객체 생성시마다 할당
-
-
메소드
-
클래스(static) 메소드 :
클래스 관점에서의 행위
객체 식별을 해야만하는 작업X
객체를 생성하지 않고도 실행할 수 있는 작업 -
객체 메소드 :
객체 관점에서의 행위
객체 식별을 해야만 하는 작업 O
객체 관련 작업
-
-
생성자
- 객체 초기화의 다양성 제공
-
중첩 클래스(Nested Class, Inner Class)
- 클래스 속 클래스
-
Initializer
- Static Initializer
static{ 실행문장 } : 클래스 메모리 로드시 자동실행 - Instance Initializer
{ 실행문장 } : 객체 생성시 마다 자동실행 --> 생성자 때문에 잘 사용 안함
- Static Initializer
클래스 멤버 사용 접근
-
클래스멤버 : 클래스이름.멤버변수, 클래스이름.메소드()
-
인스턴스멤버 : 객체 생성 후 객체참조값.멤버변수, 객체참조값.메소드()
-
this : non-static 영역에서만 사용가능
1) 지역변수와 멤버변수 구분 : this.XXX
2) 생성자안에서 자신의 또 다른 생성자를 호출하는 경우 : this( )
클래스 작성
- 패키지 선언문 (0 or 1)
package top.sub....;
//물리적 : 폴더
//보통 domain name(Unique!) 역순사용- import문 (0 ~ 多)
import top.sub...클래스이름;// 소스 클래스명 바로사용
import top.sub...*;// all classes, interfaces
(not package) : import단위는 패키지 아님!
현 클래스안에서 참조, 사용하는 클래스가 자신과 같은 패키지가 아닌 경우 명시
단, java.lang은 자동으로 불러옴- class 정의 (1 ~ 多)
** []는 상황에 따라 생략가능함
* 클래스정의
[접근지정자] [활용지정자] class 클래스명 [extends 부모클래스명] [implements 부모인터페이스명,,,] { }
//접근지정자
(default),public
//활용지정자
final : 상속금지
abstract : 추상클래스 (미완성클래스)
//클래스명
명사형, 첫글자 대문자, 카멜표기법
//extends
클래스 단일상속
//implements
인터페이스 다중상속
* 멤버정의
[접근지정자] [활용지정자] DataType 변수명 [=초기값];
//접근지정자
public,protected,(default),private
//활용지정자
static : 클래스멤버
final : 상수화, 생성자에서 초기화 필수
static final : 어차피 상수이기 때문에 static으로 사용
transient : 객체직렬화 대상제외
//변수명
명사형, 첫글자 소문자, 카멜표기법
//초기값
생략시 default값으로 초기화 (0, null, false)
* 메소드정의
[접근지정자] [활용지정자] ReturnType 메소드명 ([매개변수선언,,,]) [throws Exception명,,,]
{
실행문장
[return 리턴값]
}
//접근지정자
public,protected,(default),private
//활용지정자
static
final : 재정의 X
synchronized : 객체 동기화를 위한 잠금
abstract
//return 리턴값
void : 없음 -> return문 생략가능
not void : return값 명시
* 생성자
[접근지정자] 클래스명 ([매개변수선언,,,]) [throws Exception명,,,] {}
//접근지정자
public,protected,(default),private
상속
기존 클래스를 확장하여 새로운 내용을 덧붙이거나 내용의 일부를 바꿔 재정의하여 사용하는 것.
장점 : 코드의 재사용 (有 -> 또 다른 有 창조), 확장용이
단점 : 높은 결합도
-
클래스상속 (구현상속)
-
Concrete클래스 상속 : 온전한 클래스 -> 재정의 옵션
-
Abstract클래스 상속 : 미완성 클래스
- 추상메소드 구현부 없이 선언으로만 이루어진 메소드
설계상 의도적으로 추상클래스로 만드는 경우
- 추상메소드 有 : XXX(); -> 재정의 필수
- 추상메소드 無 : XXX(){}; -> 재정의 옵션
1) 추상클래스는 직접 new로 객체 생성을 못한다.
2) 반드시 하위 클래스 요구!
- 추상메소드 구현부 없이 선언으로만 이루어진 메소드
extends XXX (단일상속)
"일반화"
-
-
인터페이스상속 (표준, 약속, spe, 방법)
- 사용자 관점 : 사용방법, 약속
- 제공자 관점 : 구현의 책임
implements XXX,YYY (다중상속)
"실현"
추상메소드와 상수로 이루어진 특별한 타입 -> 재정의 필수
관계성
1. is a : 상속관계 (일반화)
2. has a : 소유 (연관관계 - 영구적)
3. use a : 사용 (의존관계 - 일시적)
메소드 재정의
논리적 재정의
전제조건 : 상속
- 전부다 뒤갈아 엎는 재정의
- 살짝 덧붙이는 구형의 재정의
1. 메소드 이름
2. 매개변수 목록
3. 리턴타입
1 ~ 3까지는 같아야 함
4. 접근지정자 같거나 넓게 (넓어짐)
5. throws 구문 예외 같거나 하위타입으로 or 안던지거나 (좁아짐)
this
- non-static 영역(instance 메소드, 생성자, instance initializer)에서 사용함.
- 현재 생성중인, 실행중인 그 객체 자기자신을 일컫음.
사용법
- 지역변수와 인스턴스변수를 구분하기 위해서
ex)
void setName(String name){
this.name=name;
}- 생성자가 오버로딩된 경우, 자신의 또 다른 생성자를 호출 시 this를 부를 수 있다.
ex)
this();- 자기 자신의 객체를 메소드의 매개변수로 전달하거나 리턴하기 위해서
ex) return
XXX(){
return this;
}
ex) 매개변수 전달
YYY(){
obj.zzz(this);
}main(){
Person p1 = new Person("김재환", 25);
Person p2 = new Person("나준엽", 24);
p1.setAge(26);
p2.setAge(25);
}Super
- this와 마찬가지로 non-static 영역(instance 메소드, 생성자, instance initializer)에서 사용함.
- 현재 생성중인, 실행중인 객체의 부모를 의미하도록 사용하는 논리적인 개념
사용법
- 자신의 메소드와 부모의 메소드를 구분하기 위해 사용(메소드 재정의 상황)
this.XXX()
super.XXX()
메소드 말고 멤버는 개념적으로 구분하지 않음
부모의 멤버는 자식에게도 있기 때문- 자식의 생성자에서 부모 생성자를 명시적으로 호출하기 위해 사용
super( );this의 3번 개념은 super에 없다. (있을 필요가 없다.)
다형성
상속이 전제조건!
형태가 다양한 성질 => 다양한 형태를 가질 수 있다.
-
객체다형성 : Type다형성
-
메소드다형성 : 다중정의(오버로딩), 재정의(오버라이딩)
Type 다형성
Object <- Employee <- Engineer
big ----------------- small
Engineer e1 = new Engineer();
Employee e2 = new Engineer();
Object e3 = new Engineer();
big >= small
잔 = 내용물
커피잔 = 커피
텀블러(with빨대) = 커피
잔의 형태에 따라 커피마시는 방식이 결정된다.
즉, 객체를 어디에 담느냐에 따라 객체의 사용방법이 달라진다.
만약 Object에 a, Employee에 b, Engineer에 c가 선언되어 있다고 할 때,
e3.a
e2.a, e2.b
e1.a, e1.b, e1.c 사용가능.다형성을 사용(활용)하는 경우
- 이형 집합 배열
만약 Engineer와 Manager등 다른 직무의 직원 총 100명의 샐러리를 관리할 리스트를 생성할 때,
Employee[] list = new Employee[100];- 매개변수 다형성
Engineer와 Manager등 다양한 직무의 직원들을 매개변수로 받아야 할 때,
XXX(Employee e)
"직원들 모이세요" -> "거기서 직원들 공통적인 이야기를 해야지, 엔지니어 or 매니저 이야기 하면 안됨"- 리턴타입 다형성
경우에 따라 리턴타입을 다르게 전달해야 할 때,
Employee XXX(){
if(...) return new Engineer();
else return new Manager();
}동적바인딩
동적바인딩(Run-time) <-> 정적바인딩(Compile-time)
컴파일시에 컴파일러가 인지한 객체와 런타임시 실제 객체를 다르게 인지
Employee e = new Engineer();
e.getInfo();
ㄴ c/t : Employee
ㄴ r/t : Engineer
Employee에 정의된 getInfo()를
Engineer에서 getInfo()를 오버라이딩 했을 때,
Employee e = new Engineer();에서
e는 Engineer에 없는 메소드는 사용하지 못하지만
유일하게 Engineer가 영향을 주는것은 오버라이딩된 메소드이다.