
2024 1분기 Snowflake Parter Network base camp에 다녀왔습니다.
이후 현장에서 들은 교육 내용을 정리해보았습니다!
❄️ 1. Snow Pipe
- serverless
- 데이터를 자동으로 적재하는 object
- copy command를 매번 타이핑 하는 게 불편할 때 많이 사용
- 한 번 pipe를 구성해두면 manual 하게 적지 않아도 됨
- 히스토리 존재
- 파일의 이름이 동일하면 적재되지 않음
- 따라서, 파일 이름이 달라야 함
- 보통 날짜를 같이 적음
- 시간 관련 특징
- 5분 미만의 시간이 걸
- 다만, 리얼타임에서 5분은 조금 크기 때문에 snowpipe streaming을 만듦
❄️ 2. Snowpipe Streaming
- 카프카를 연동해 적재 메세지가 들어오면 snow flake에 리얼타임으로 저장되는 기능
- 5초 내로 해결→ 리얼타임으로 느껴지게 함
- 과금 단위 : 건수
❄️ 3. Dynamic Table
- base table을 여러개 가지는 테이블
- 쿼리로 table 만들면 됨
- base table에서 데이터가 바뀐다면 snow flake에서 sync를 맞춰줌
- 실시간은 아니고 지정한 시간에 따라서 sync를 맞추게 됨
- Data set이 자주 변한다면 Dynamic table이 resource를 더 많이 사용할 수 있음
- 여기서 resource란 virtural warehouse나 serverless warehouse를 말함
❄️ 4. Schema Detection and Evolution
4-1. Schema Detection
- 현재 있는 parquet or json 등의 데이터를 보고 테이블로 만들어주는 기능
- csv, parquet, json 지원
4-2. Schema Evolution
- 반정형 데이터는 object 내에 칼럼명이 픽스 되었다면 데이터가 추가되기 쉽지 않음
- 이를 극복하기 위해 새로 생기는 컬럼을 자동으로 감지해 칼럼을 추가하고 데이터를 추가함
- 다만, 삭제되는 칼럼에 대해서는 지원하지 않음
- kafka를 통해서 들어오는 데이터가 변했을 때 활용 가능
❄️5. Cost Optimization
- Budgets
- 내가 얼마나 가지고 있고, 얼마나 관리할 거냐에 대한 정보
- account 단위로 제공
- warehouse 단위로 제공
- 내가 얼마나 보유하고 있고 얼마나 관리할 것인지에 대한 정보를 담
❄️6. Replication
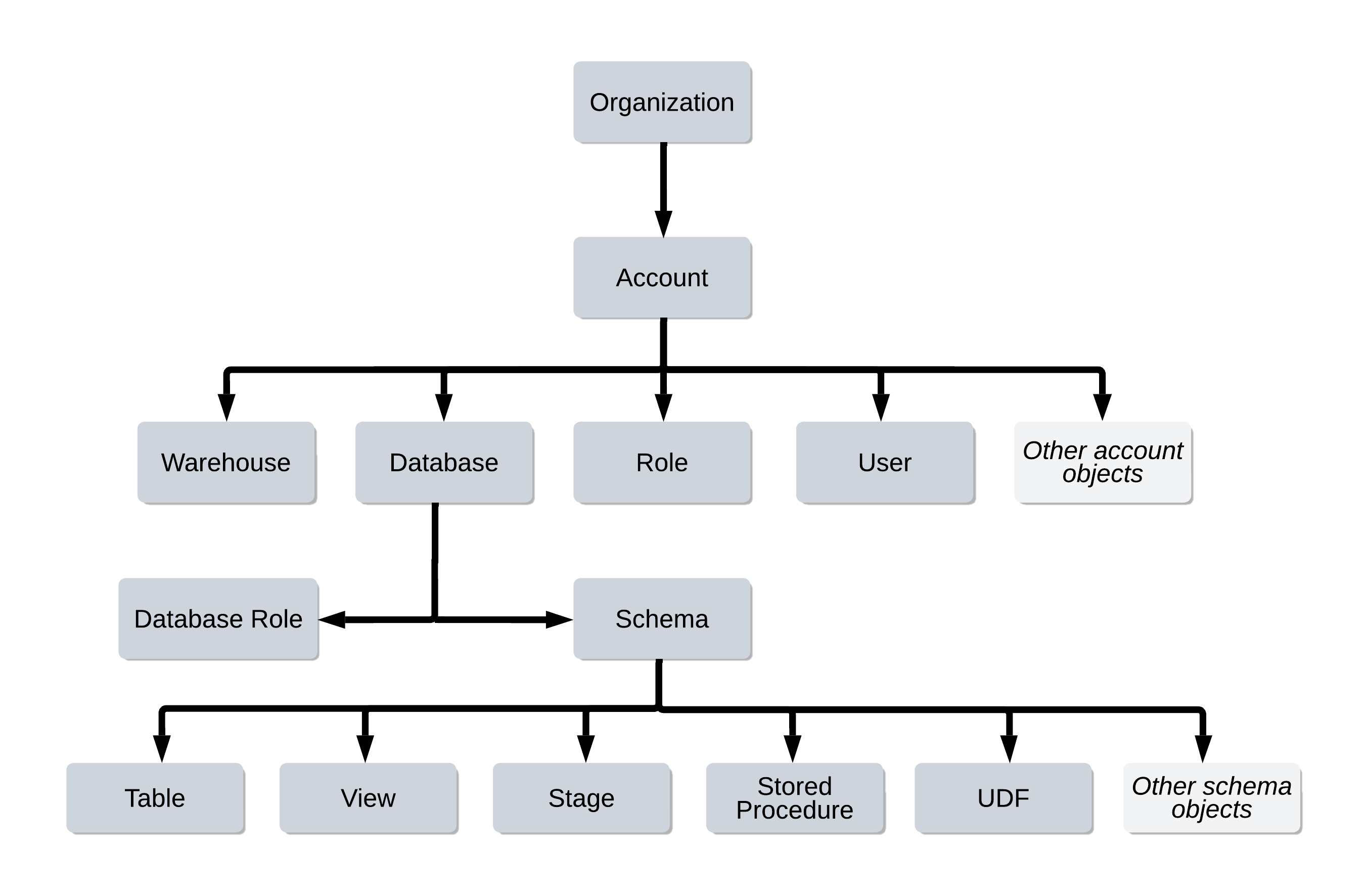
- 상기 그림과 같은 계층 구조로 snowflake가 구성되어 있음
6-1. account replication
- account 아래에 해당하는 모든 것에 대한 복제
- role 해당 o
6-2. Database replication
- database 아래(스키마, 테이블) 등등 해당하는 것에 대한 복제
- role은 해당 x
❄️ 7. Database Failover
- primary에서 region 오류가 발생하면 secondary에서 장애조치함

Data가 좋은 Web 개발자