
1. 검색 엔진이란?
사용자가 원하는 정보인 검색어(키워드)가 입력되면 그에 따른 결과물(정보)를 만들어내는 시스템이나 프로그램
2. 검색 엔진의 간단한 동작 원리
- 사용자가 키워드를 입력
- 알고리즘에 따라 정보의 순위나 순서를 조정
- 결과물 산출
- 검색 엔진은 이를 위해 평소에 인터넷상에서 정보를 수집
- 이를 업데이트 하는 것이 "검색 로봇"
- 검색 로봇은 흔히 생각하는 물질적인 로봇이 아닌 자동화된 정보 수집 프로그램을 뜻함
3. 검색 엔진의 원리
1. Crwaling: 정보 찾기
크롤러(또는 스파이더)란?
웹상의 문서, 이미지, 영상 등을 주기적으로 검색하고 취합하여 자동으로 데이터베이스화시키는 프로그램으로 봇(Bot)이라고도 부름
- 크롤러가 웹사이트를 옮겨 다니면서 정보를 수집
- 새로운 웹페이지나 기존의 웹페이지지만 업데이트된 정보가 있으면 방문
- 이때, 공개된 사이트의 정보만 수집하는데 이는 크롤러가 robots.txt파일을 통해 확인
- robots.txt에서 "허용한다"라고 하면 정보를 가져오고,
- "허용하지 않는다"하면 정보를 가져오지 않는다.
다음은 네이버 웹마스터도구에서 멜론의 robot.txt를 확인해 보았다.
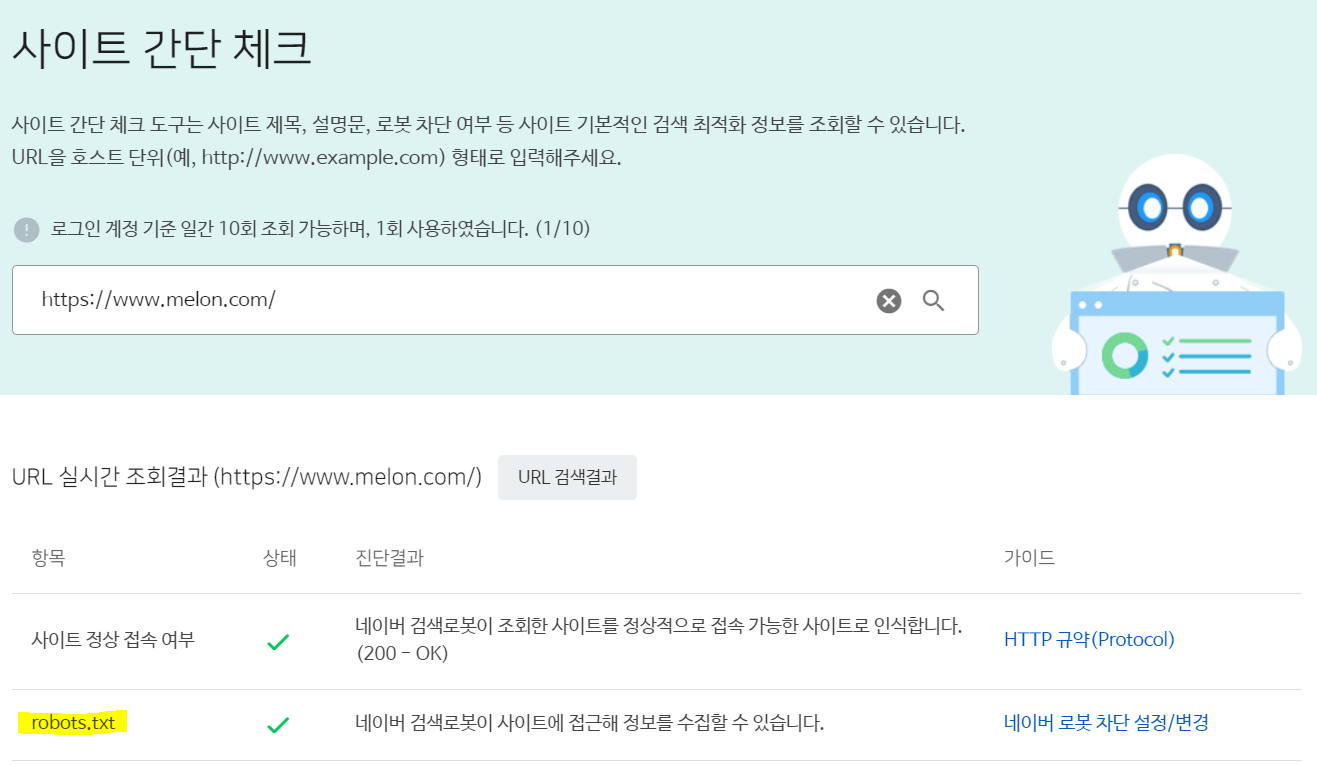
2. Indexing: 컨텐츠 색인
- 색인된 페이지는 거대한 데이터베이스에 저장
- 인덱싱의 과정
- 특정 키워드로 웹페이지를 할당
- 단어와 내용이 웹페이지를 위한 최선의 설명인지 확인
3. Process: 검색 처리
- 검색을 시작하면 검색엔진이 검색어와 데이터베이스에 색인하여 저장된 웹페이지를 비교
- 수백만개의 웹페이지들 중에서 키워드 관련성을 체크하기 위해 계산 수행
4. Calculating Relevancy: 관련도 계산
- 관련도 계산(Calculating Relevancy)을 위한 알고리즘은 굉장히 다양
- 각각의 알고리즘은 키워드, 링크, 메타태그 등 다른 관련성의 비중을 두어 체크
구글, 네이버 등 다른 검색엔진에서 검색 시 같지 않은 검색 결과를 보여주는 것이 상기 이유!
5. Retrieving: 검색결과 가져오는 과정
- 브러우저에서 검색 결과를 확인할 수 있도록 웹페이지들을 구분하고 정리
다음 장에서는 검색엔진 오픈소스의 대표주자인 Elasticsearch와 Solrsearch를 비교해보겠습니다.
참고 자료
검색 엔진 원리 / Elastic Search vs Solr Search :: DANIDANI
[키워드로 알아보는 IT] "검색 엔진(Search Engine)"이란?

Data가 좋은 Web 개발자