관계형 데이터베이스 모델링에 대해 알아봅니다.
▶︎ RDB 관계형 데이터베이스
- 데이터 중복을 최소화하기 위해 테이블을 분리하여 관리.
- 테이블 간의 관계를 통해 데이터를 효율적으로 저장.
- 유지보수성과 확장성이 뛰어나다.
▶︎ Data Modeling
- model: 특정 목적을 가지고 현실 세계를 모방하여 단순화한 표현.
- 데이터 모델링 4단계
- 업무 파악
- 개념적 데이터 모델링
- 논리적 데이터 모델링
- 물리적 데이터 모델링
1. 업무파악
- 해결하고자 하는 문제를 명확히 이해하고 정의할 수 있어야 한다.
- 시스템으로 구현 가능하도록 문제를 구조화할 수 있어야 한다.
2. 개념적 데이터 모델링
- 개념적 데이터 모델링: 파악한 업무에서 개념을 뽑아내는 과정.
ERDiagram
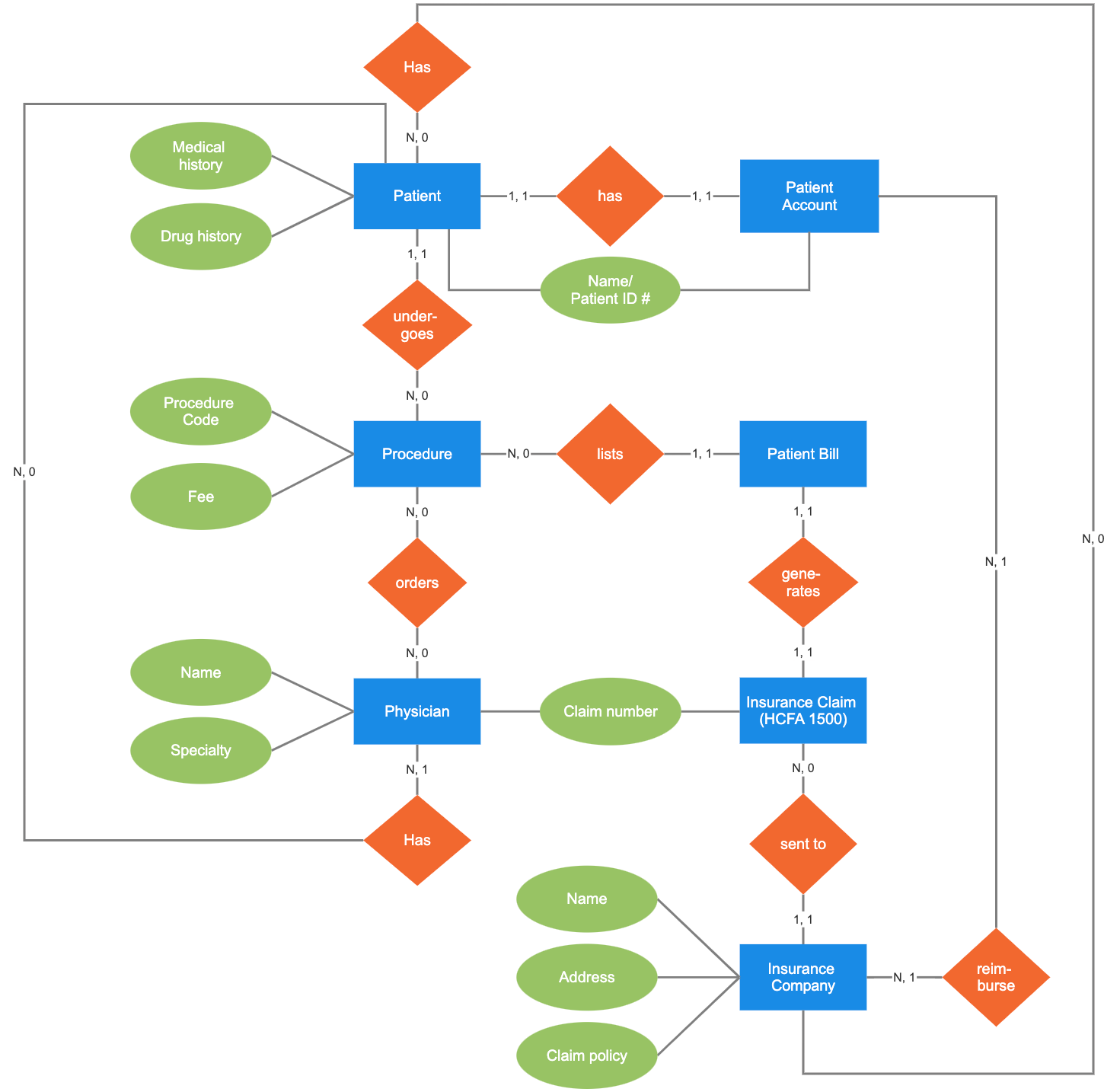
- Entity Relationship Diagram.
- 정보를 그룹핑하고 그룹 사이의 관계를 시각적으로 표현하는 도구.
- 테이블 구조로 쉽게 전환 가능.
- 참고)
erd 구성요소
Entity 개체
- 저장하고 관리해야 할 데이터의 집합.
- 사각형으로 표시.
- 추후 테이블(Table)로 전환된다.
- 다른 엔티티를 포함할 수 없다. (RDB는 중첩 관계를 허용하지 않는다.)
- 예) 회원, 상품, 주문, 게시글
Attribute 속성
- Entity의 구체적인 데이터 항목.
- 원으로 표시.
- 추후 테이블의 컬럼(Column)으로 전환된다.
- 예시) 회원 엔티티의 속성: 회원ID, 이름, 이메일, 전화번호
Relationship 관계
- Entity 간의 연관성.
- 마름모로 표시.
- PK(Primary Key, 기본키)와 FK(Foreign Key, 외래키)로 구현된다. JOIN을 통해 테이블 간 데이터 연결한다.
+) 칼럼의 행은 tuple이라고 한다.
개념적 데이터 모델링 프로세스
Step 1: Entity 정의
- 기획서에서 연관된 데이터를 그룹핑하며 entity를 찾는다.
Step 2: Attribute 정의
- 각 Entity에 속하는 구체적인 데이터 항목을 정의한다.
Step 3: Identifier 지정
- identifier: entity 내에서 각 인스턴스를 고유하게 구별할 수 있는 속성.
- entity의 속성에서 identifier를 정해야 한다.
- identifier 선정 기준: 값이 중복되면 안된다. null값이 들어가면 안된다. 변경 가능성이 낮아야 한다.
- identifier는 나중에 primary key가 된다.
- 주요 개념
- candidate key 후보키: 식별자가 될 수 있는 후보 속성들.
- primary key 기본키: candidate key중 선택된 대표 식별자.
- alternate key 대체키: candidate key에서 primary key가 되지 못한 것들. secondary index의 후보가 된다.
- composite key 중복키: 두 개 이상의 속성을 조합하여 만든 식별자.
Step 4: Relationship 정의
- Relationship: entity 간의 연결
- Foreign Key: 다른 테이블의 Primary Key를 참조하는 컬럼.
- 관계형 데이터의 relationship은 primary key와 forien key가 연결될 때 구현된다.
relationship의 핵심 요소
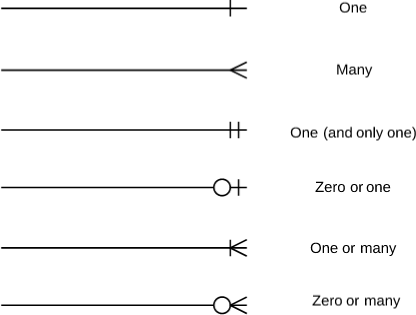
cardinality
- 관계의 수적 측면 표현.
- 1:1 관계, 1:n 관계, n:n 관계
- n:n 관계는 현실의 database에서 직접 표현 불가능으로 연결 테이블(Junction Table) 생성하여 1:n 관계 두 개로 분리한다.
optionality
- 관계의 필수 여부 표현
- 반드시 관계가 존재해야 한다면 mandatory.
- 표기: | (수직선)
- 관계가 없어도 존재 가능하다면 oprionality.
- 표기: o (원)
3. 논리적 데이터 모델링
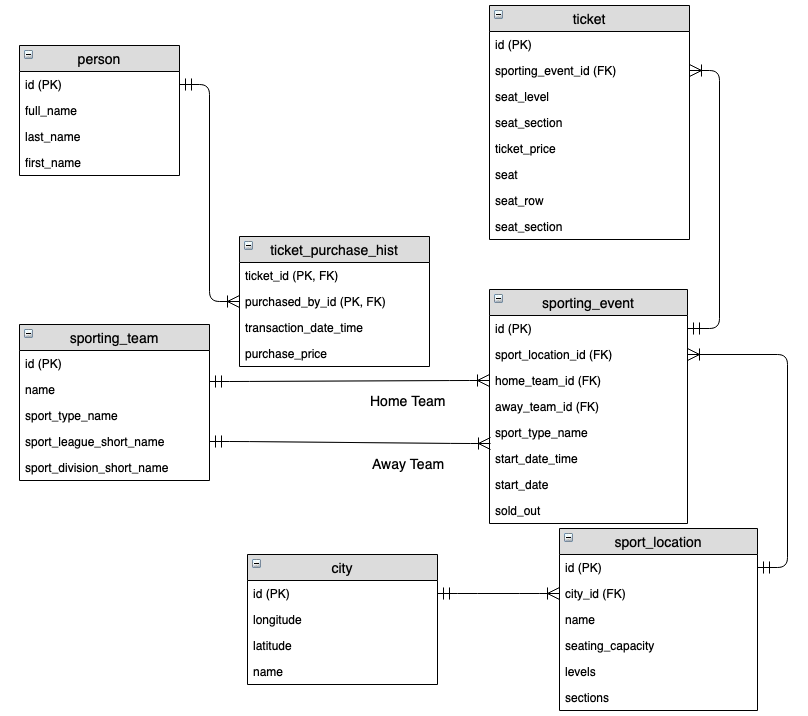
- 개념적 모델링에서 추출한 개념을 관계형 데이터베이스 패러다임에 맞게 구체화.
- ERD를 실제 테이블 구조로 변환.
- 데이터 타입, 제약조건 등 세부 사항 정의.
Mapping Rule
- erdiagrm를 관계형 데이터베이스 테이블로 전환하는 체계적인 방법론.
step1. 테이블과 컬럼 생성
- entity별로 테이블 생성.
- entity의 attribute으로 컬럼 생성.
- Identifier(식별자)는 Primary Key로 지정
- 컬럼에 대한 도메인 설정: 데이터 타입, null 허용 여부, 기본값 등.
step2. 관계 처리
- Relationship을 Primary Key(PK)와 Foreign Key(FK)로 구현.
1:1 관계 처리
- 부모 테이블: 혼자 잘 지낼 수 있는 테이블. PK 보유.
- 자식 테이블: 부모 테이블에 의존하고 있는 테이블. FK 보유.
- 자식 테이블에 부모 테이블의 PK를 FK로 추가.
1:n 관계 처리
- 1 쪽: PK 보유.
- n 쪽:이 FK 보유.
n:m 관계 처리
- mapping table 연결 테이블 필요.
- 연결 테이블은 양쪽 테이블의 PK를 FK로 보유.
Normalization 정규화
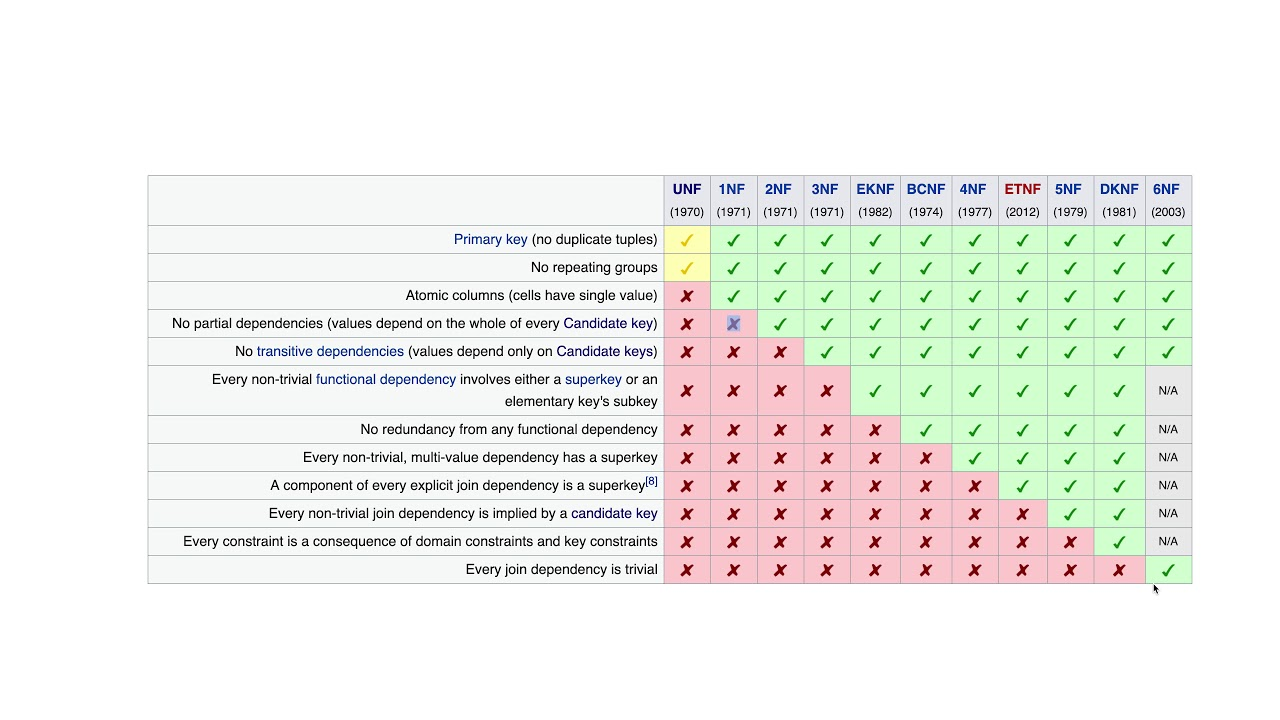
- 정제되지 않은 데이터(표)를 관계형 데이터베이스에 적합한 표로 만들어주는 레시피.
- 보통 실무에서는 제3정규화(3NF)까지 수행.
제1 정규화: Atomic columns
- 각 행과, 각 칼럼의 값은 원자값(Atomic Value)만 가져야 한다. 하나의 셀에 여러 값 저장 안됨.
- 방법) 행 추가, 칼럼 추가(비추천), 테이블 분리(권장)
제2 정규화: No partial dependencies
- 부분 종속성 제거.
- 부분 종속성: 복합 기본키 중 일부 컬럼에만 종속되는 속성.
- 복합키일때 확인. (복합키가 아니라면 제3 정규화로.)
- 복합키의 일부에만 종속되는 컬럼이 있으면 안 된다. => Key가 아닌 값들은 모두 key(복합키)에 종속 되어야한다.
- 방법) 테이블 분리
제3 정규화: No transitive dependencies
- 이행적 종속성 제거.
- 이행적 종속성: 기본키가 아닌 컬럼이 다른 일반 컬럼을 결정하는 관계.
- A → B → C 관계에서 A → C 직접 종속 제거.
- 방법) 테이블 분리
4. 물리적 데이터 모델링
- 논리적 모델링에서 설계한 이상적인 구조를 제품에 맞는 현실적인 표로 만들기.
- 실제 운영 환경에 배포 가능한 형태로 변환.
- 성능 최적화 고려.
성능 최적화
find slow queru : 어디에서 병목이 발생하는지 찾은 후 성능 최적화 시도!
- index
- 행에 대한 읽기 성능을 비약적으로 향상시키지만,
- 쓰기 성능을 비관적으로 희생시킨다.
- 쓰기가 이루어질 때마다 그 행이 인덱스가 걸려있다면 입력된 정보를 정리정돈 하기 위한 복잡한 전산 과정이 필요한데 시간도 걸리고 저장공간도 차지.
- Cache
- 데이터베이스를 이용하고 있는 application 영역에서 캐시와 같은 방법을 시도.
- 입력에 따른 실행결과를 저장해 뒀다가 동일한 입력이 들어왔을 때 저장해둔 결과를 사용하는 걸 통해 db의 부하를 줄이기.
- 역정규화: 위 방법을 쓰고도 성능 향상에 어려움이 있다면 표의 구조를 바꾸는 역정규화를 시도한다.
역정규화 denormalization 반정규화
- 정규화를 통해 만든 이상적인 표를 성능이나 개발의 편의성을 위해 구조를 바꾸는 것.
- 정규화를 하면 표가 여러개로 쪼개지는데, 이 표를 다시 사용할 때는 join을 사용하는데, join은 비싼 작업이다.
- 읽기 빈도가 쓰기 빈도보다 압도적으로 높을 때, 복잡한 JOIN으로 성능 문제 발생 시, 실시간 집계/계산이 빈번할 때 역정규화를 할 수 있다.
컬럼의 역정규화
- 중복 칼럼을 추가 -> join 줄이기
- 데이터 일관성 유지 부담
- 파생 컬럼의 형성 -> 계산작업을 줄이기
- 예) total_amount라는 파생(계산) 컬럼 추가하여 주문 상품 추가 시마다 총액 업데이트.
테이블의 역정규화
- 컬럼을 기준으로 테이블을 분리 (수직분할)
- 용량이 큰 컬럼을 테이블로 분리 -> 샷 잉
- 행을 기준으로 테이블 분리 (수평분할)
- 데이터를 특정 기준으로 분할하여 각 테이블 크기 축소
- 예) created_at의 년도를 기준으로 테이블 분리
관계의 역정규화
- FK 칼럼을 추가 -> join을 줄이기.
- 정규화된 데이터베이스에서는 A → B → C 테이블로 연결되어 있다면, A에서 C의 데이터를 가져오기 위해서는 B를 거쳐서 두 번의 JOIN이 필요.
- 역정규화를 통해 A 테이블에 C 테이블의 외래 키를 직접 추가하면, A에서 바로 C로 연결되는 지름길이 생기므로 JOIN을 한 번만 수행하면 된다.

난 🥬