
재귀(Recursion)와 스택(Stack)
큰 목표 작업 하나를 동일하면서 간단한 작업 여러 개로 나눌 수 있을 때 유용한 프로그래밍 패턴이다.
문제 해결을 하다 보면 함수에서 다른 함수를 호출해야 할 때가 있습니다. 이때 함수가 자기 자신을 호출할 수도 있는데, 이를 재귀 라고 부른다.
특정 자료구조를 다뤄야 할 때도 재귀가 사용된다.
두 가지 사고방식
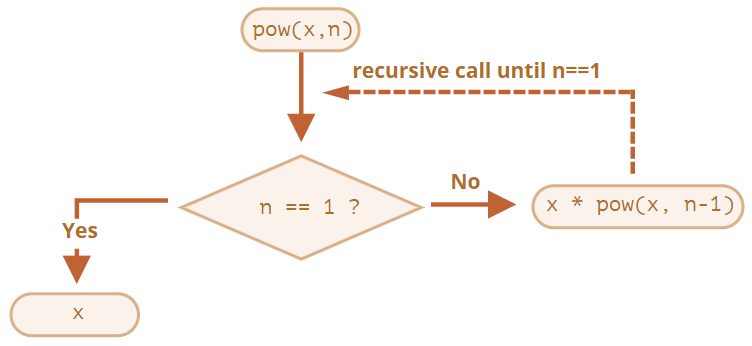
x를 n 제곱해 주는 함수 pow(x, n)를 만들어보자.
- 반복적인 사고를 통한 방법: for 루프
function pow(x, n) {
let result = 1;
// 반복문을 돌면서 x를 n번 곱함
for (let i = 0; i < n; i++) {
result *= x;
}
return result;
}
alert( pow(2, 3) ); // 8- 재귀적인 사고를 통한 방법: 작업을 단순화하고 자기 자신(함수)을 호출함
function pow(x, n) {
if (n == 1) {
return x;
} else {
return x * pow(x, n - 1);
}
}
alert( pow(2, 3) ); // 8재귀를 이용한 예시에서 pow (x, n)을 호출하면 아래와 같이 두 갈래로 나뉘어 코드가 실행된다.
if n==1 = x
/
pow(x, n) =
\
else = x * pow(x, n - 1)-
n == 1일 때
명확한 결괏값을 즉시 도출하므로 이를 재귀의 베이스(base)라고 한다. -
n == 1이 아닐 때
- pow(x, n)은 x * pow(x, n - 1)으로 표현할 수 있다. 수학식으론 xn = x * xn-1로 표현할 수 있겠다. 이를 재귀 단계(recursive step) 라고 부른다.
- 목표 작업 pow(x, n)을 간단한 동작(x를 곱하기)과 목표 작업을 변형한 작업(pow(x, n - 1))으로 분할하였다.
- 재귀 단계는 n이 1이 될 때까지 계속 이어진다.
pow (2, 4)를 계산하려면 아래와 같은 재귀 단계가 차례대로 이어진다.
- pow(2, 4) = 2 * pow(2, 3)
- pow(2, 3) = 2 * pow(2, 2)
- pow(2, 2) = 2 * pow(2, 1)
- pow(2, 1) = 2
반복을 사용한 코드보다 재귀를 사용한 코드가 짧다.
if 대신 조건부 연산자 ?를 사용하면 pow (x, n)를 더 > 간결하고 읽기 >쉽게 만들 수도 있다.function pow(x, n) { return (n == 1) ? x : (x * pow(x, n - 1)); }
재귀에서 중첩되는 호출의 개수를 재귀 깊이(recursion depth) 라고 한다. pow(x, n)의 재귀 깊이는 n이다.
자바스크립트 엔진에 따라 최대 재귀 깊이를 제한한다(10,000 ~ 100,000 정도). 이런 제한을 완화하려고 엔진 내부에서 자동으로 'tail calls optimization’라는 최적화를 수행하긴 하지만, 모든 곳에 적용되는 것은 아니고 간단한 경우에만 적용한다.
실행 컨텍스트와 스택
실제 재귀 호출 시 함수의 내부 동작에 대해 살펴보자.
실행 중인 함수의 실행 절차에 대한 정보는 해당 함수의 실행 컨텍스트(execution context) 에 저장된다.
실행 컨텍스트는 함수 실행에 대한 세부 정보를 담고 있는 내부 데이터 구조이다.
- 제어 흐름의 현재 위치
- 변수의 현재 값
- this의 값(여기선 다루지 않음)
등 상세 내부 정보가 실행 컨텍스트에 저장된다.
함수 호출 1회당 정확히 하나의 실행 컨텍스트가 생성된다.
함수 내부에 중첩 호출이 있을 때는 아래와 같은 절차가 수행됩니다.
- 현재 함수의 실행이 일시 중지된다.
- 중지된 함수와 연관된 실행 컨텍스트는 실행 컨텍스트 스택(execution context stack) 이라는 특별한 자료 구조에 저장된다.
- 중첩 호출이 실행된다.
- 중첩 호출 실행이 끝난 이후 실행 컨텍스트 스택에서 일시 중단한 함수의 실행 컨텍스트를 꺼내온다.
- 중단한 함수의 실행을 다시 이어간다.
실행 컨텍스트 예시:
pow(2, 3) 호출 시
실행 컨텍스트에 변수 x = 2, n = 3이 저장되고, 실행 흐름은 함수의 첫 번째 줄에 위치한다.
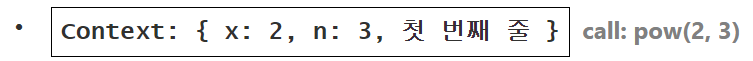
위 그림은 함수 실행이 시작되는 순간을 도식화한 것이다. n == 1을 만족하지 못하므로 실행 흐름은 if의 두 번째 분기(else)로 넘어간다.
이 때, 변수는 동일하지만 실행 흐름의 위치가 변경되면서 싱행 컨텍스트도 다음과 같이 변경된다.

x * pow (x, n - 1)을 계산하려면 새로운 인수가 들어가는 pow의 서브 호출(subcall), pow (2, 2)을 만들어야 합니다.
pow(2, 2) 서브 호출
중첩 호출을 하기 위해, 자바스크립트는 실행 컨텍스트 스택 에 현재 실행 컨텍스트를 저장한다.
재귀 함수 뿐만 아니라, 모든 함수에 대해 아래 프로세스가 똑같이 적용된다.
- 스택 최상단에 현재 컨텍스트가 '기록’된다.
- 서브 호출을 위한 새로운 컨텍스트가 만들어진다.
- 서브 호출이 완료되면, 기존 컨텍스트를 스택에서 꺼내(pop) 실행을 이어나간다.
다음은 서브 호출 pow (2, 2)이 시작될 때의 실행 컨텍스트 스택이다.

굵은 테두리로 표시한 새 실행 컨텍스트는 상단에, 기존 컨텍스트는 하단에 있다.
이전 컨텍스트에 변수 정보, 코드가 일시 중단된 줄에 대한 정보가 저장되어있기 때문에 서브 호출이 끝났을 때 이전 컨텍스트가 문제없이 다시 시작된다.
pow(2, 1) 서브 호출
동일하게 반복

실행 종료
pow (2, 1)가 실행될 땐 상황이 달라진다.
조건 n == 1을 만족시키므로 if문의 첫 번째 분기가 실행
function pow(x, n) {
if (n == 1) {
return x; // <-- 실행되는 코드
} else {
return x * pow(x, n - 1);
}
}호출해야 할 중첩이 없기 때문에 함수가 종료되고 2가 반환된다.
함수가 종료되었기 때문에 이에 상응하는 실행 컨텍스트는 쓸모가 없어졌다.
따라서 해당 실행 컨텍스트는 메모리에서 삭제됩니다. 스택 맨 위엔 이전의 실행 컨텍스트가 위치하게 된다.

pow (2, 2)의 실행이 다시 시작된다. 서브 호출 pow (2, 1)의 결과를 알고 있으므로, 쉽게 x * pow (x, n - 1)를 계산해 4를 반환한다.
그리고 다시 이전 컨텍스트가 스택 최상단에 위치하게 된다.

마지막 실행 컨텍스트까지 처리되면 pow (2, 3) = 8이라는 결과가 도출된다.
도식을 통해 살펴보았듯이, 재귀 깊이는 스택에 들어가는 실행 컨텍스트 수의 최댓값과 같기 때문에 이 예시의 재귀 깊이는 3이다.
실행 컨텍스트는 메모리를 차지하므로 재귀를 사용할 땐 메모리 요구사항에 유의해야 한다. n을 늘리면 n이 줄어들 때마다 만들어지는 n개의 실행 컨텍스트가 저장될 메모리 공간이 필요하기 때문이다.
한편, 반복문 기반 알고리즘을 사용하면 메모리가 절약된다.
function pow(x, n) {
let result = 1;
for (let i = 0; i < n; i++) {
result *= x;
}
return result;
}컨텍스트 하나만 사용하기 때문이다.
재귀를 이용한 코드는 반복문을 사용한 코드로 다시 작성할 수 있다. 이 경우 대개 함수 호출의 비용(메모리 사용)이 절약된다.
하지만 코드를 다시 작성해도 큰 개선이 없는 경우도 있다.
- 조건에 따라 함수가 다른 재귀 서브 호출을 하고 그 결과를 합치는 경우
- 분기문이 복잡하게 얽혀있을 경우
위 경우에는 코드 최적화가 무용지물일 수 있으며, 오히려 재귀를 사용한 코드가 짧기 때문에 유지보수에 용이할 수 있다. 또한 모든 곳에서 메모리 최적화를 신경써야 하는 것은 아니기 때문에 좋은 코드를 위한다면 재귀 사용을 고려해볼만 하다.
재귀적 순회
재귀는 재귀적 순회(recursive traversal)를 구현할 때 사용하면 좋다.
회사 객체 예시:
let company = {
sales: [{
name: 'John',
salary: 1000
}, {
name: 'Alice',
salary: 1600
}],
development: {
sites: [{
name: 'Peter',
salary: 2000
}, {
name: 'Alex',
salary: 1800
}],
internals: [{
name: 'Jack',
salary: 1300
}]
}
};회사엔 부서가 있다.
부서에는 여러 명의 직원이 있고, 이를 배열로 표현할 수 있다.
부서는 하위 부서를 가질 수 있으며, 각 하위부서에도 직원이 있다.
하위 부서가 커지면 더 작은 단위의 하위 부서(또는 팀)로 쪼개질 가능성도 있다.
.
.
.
자, 이제 모든 임직원의 급여를 더한 값을 구해야 한다고 가정한다면 어떻게 해야 할까?
가장 먼저 떠오르는 생각은 company를 대상으로 동작하는 for 반복문을 만들고 한 단계 아래의 부서에 중첩 반복문를 돌리는 방법일 것이다.
그런데 이렇게 하면 부서의 하위 부서의 하위 부서의... 하위 부서에 각각 중첩 반복문을 사용한다면 코드도 지저분해지고 모든 for문을 완료하는 데에 시간적으로 부담이 될 가능성이 크다.
재귀를 이용한 풀이법을 시도해 보자.
앞서 본 바와 같이 임직원 급여 합계를 구할 때는 두 가지 경우로 나누어 생각할 수 있다.
- 임직원 배열 을 가진 ‘단순한’ 부서 – 간단한 반복문으로 급여 합계를 구할 수 있다.
- N개의 하위 부서가 있는 객체 – 각 하위 부서에 속한 임직원의 급여 합계를 얻기 위해 N번의 재귀 호출을 하고, 최종적으로 모든 하위부서 임직원의 급여를 더한다.
배열을 사용하는 첫 번째 경우는 간단한 경우로, 재귀의 베이스가 된다.
객체를 사용하는 두 번째 경우는 재귀 단계가 된다. 복잡한 작업은 작은 작업(하위 부서에 대한 반복문)으로 쪼갤 수 있다. 부서의 깊이에 따라 더 작은 작업으로 쪼갤 수 있는데, 결국 마지막엔 첫 번째 경우가 된다.
코드를 직접 읽어보면서 재귀 알고리즘을 이해해봅시다.
let company = { // 동일한 객체(간결성을 위해 약간 압축함)
sales: [{name: 'John', salary: 1000}, {name: 'Alice', salary: 1600 }],
development: {
sites: [{name: 'Peter', salary: 2000}, {name: 'Alex', salary: 1800 }],
internals: [{name: 'Jack', salary: 1300}]
}
};
// 급여 합계를 구해주는 함수
function sumSalaries(department) {
if (Array.isArray(department)) { // 첫 번째 경우
return department.reduce((prev, current) => prev + current.salary, 0); // 배열의 요소를 합함
} else { // 두 번째 경우
let sum = 0;
for (let subdep of Object.values(department)) {
sum += sumSalaries(subdep); // 재귀 호출로 각 하위 부서 임직원의 급여 총합을 구함
}
return sum;
}
}
alert(sumSalaries(company)); // 7700짧고 이해하기 쉬운 코드로 원하는 기능을 구현할 수 있다.
재귀의 강력함은 여기에 있다. 하위 부서의 깊이와 상관없이 원하는 값을 구할 수 있게 되었다.
아래는 호출이 어떻게 일어나는지를 나타낸 그림이다.

객체 {...}를 만나면 서브 호출이 만들어지는 반면, 배열 [...]을 만나면 더 이상의 서브 호출이 만들어지지 않고 결과가 바로 계산된다.
재귀적 구조
재귀적으로 정의된 자료구조인 '재귀적 자료 구조'는 자기 자신의 일부를 복제하는 형태의 자료 구조이다.
재귀적 구조의 예시
위에서 살펴본 회사 구조
회사의 부서 객체는 두 가지 종류로 나뉜다.
- 사람들로 구성된 배열
- 하위 부서로 이루어진 객체
HTML, XML
HTML 문서에서 HTML 태그는 아래와 같은 항목으로 구성된다.
- 일반 텍스트
- HTML-주석
- 이 외의 HTML 태그 (이 아래에 일반 텍스트, HTML-주석, 다른 HTML 태그가 올 수 있다.)
이렇게 다양한 곳에서 재귀적으로 정의된 자료구조가 쓰인다.
'연결 리스트’라는 재귀적 자료 구조를 살펴보면서 재귀적 구조에 대해 더 알아보자.
연결 리스트
객체를 정렬하여 어딘가에 저장하려고 할 때, 주로 배열을 먼저 떠올릴 것이다.
하지만 배열은 요소 '삽입'과 '삭제'에 비용이 많이 든다.
arr.unshift(obj)연산을 수행하려면 새로운 obj를 위한 공간을 만들기 위해 모든 요소의 번호를 다시 매겨야 한다. arr.shift()도 마찬가지이다.
요소 전체의 번호를 다시 매기지 않아도 되는 조작은 배열 끝에 하는 연산인 arr.push/pop 뿐이다. 앞쪽 요소에 무언가를 할 때 배열은 이처럼 꽤 느리다.
빠르게 삽입 혹은 삭제를 해야 할 때는 배열 대신 연결 리스트(linked list)라 불리는 자료 구조를 사용할 수 있다.
연결 리스트의 요소 는 객체와 아래 프로퍼티들을 조합해 정의할 수 있다.
- value
- next : 다음 연결 리스트 요소를 참조하는 프로퍼티. 다음 요소가 없을 땐 null이 된다.
예시:
let list = {
value: 1,
next: {
value: 2,
next: {
value: 3,
next: {
value: 4,
next: null
}
}
}
};위 연결 리스트를 그림으로 표현하면 다음과 같다.

아래처럼 코드를 작성해도 동일한 연결 리스트가 된다.
let list = { value: 1 };
list.next = { value: 2 };
list.next.next = { value: 3 };
list.next.next.next = { value: 4 };
list.next.next.next.next = null;이렇게 연결 리스트를 만드니 객체가 여러개 있고, 각 객체엔 value와 이웃 객체를 가리키는 프로퍼티인 next가 있는 게 명확히 보인다. 체인의 시작 객체는 변수 list에 저장되어 있다. 우리는 list의 next 프로퍼티를 이용해 이어지는 객체 어디든 도달할 수 있다.
연결 리스트를 사용하면 전체 리스트를 여러 부분으로 쉽게 나눌 수 있고, 다시 합치는 것도 가능하다.
let secondList = list.next.next; //나누기
list.next.next = null;
list.next.next = secondList; // 합치기그리고 쉽게 요소를 추가하거나 삭제할 수 있다.
리스트의 처음 객체를 바꾸면 리스트 맨 앞에 새로운 값을 변경하는 것이다.
let list = { value: 1 };
list.next = { value: 2 };
list.next.next = { value: 3 };
list.next.next.next = { value: 4 };
// list에 새로운 value를 추가합니다.
list = { value: "new item", next: list };
중간 요소를 제거하려면 이전 요소의 next를 변경해주면 된다.
list.next = list.next.next; //이제 value 1은 체인에서 제외되므로 메모리에서 제거됨 지금까지 살펴본 바와 같이 연결 리스트는 배열과는 달리 대량으로 요소 번호를 재할당하지 않으면서 요소를 쉽게 재배열할 수 있다는 장점이 있다.
하지만 연결 리스트의 가장 큰 단점은 배열과 달리 번호(인덱스)로 요소에 접근할 수 없다는 점이다.
배열과 연결 리스트처럼 중간 요소에 접근하는 경우가 반드시 필요한 것은 아니다. 이럴 땐 순서가 있는 자료형 중에 큐(queue)나 데크(deque)를 사용할 수 있다. 데크를 사용하면 양 끝에서 삽입과 삭제를 빠르게 수행할 수 있습니다.
위에서 구현한 연결 리스트는 아래와 같은 기능을 더해 개선할 수 있다.
- 이전 요소를 참조하는 프로퍼티 prev를 추가해 이전 요소로 쉽게 이동하게 할 수 있다.
- 리스트의 마지막 요소를 참조하는 변수 tail를 추가할 수 있다. 다만 이때 주의할 점은 리스트 마지막에 요소를 추가하거나 삭제할 때 tail도 갱신해 줘야 한다.
- 이 외에도 요구사항에 따라 구조를 변경할 수 있습니다.
✍️ 정리
재귀(recursion)
함수 내부에서 자기 자신을 호출하는 것을 나타내는 프로그래밍 용어이다.
재귀 단계(recursion step)
함수가 자신을 호출하는 단계이다.
재귀의 베이스(base)
작업을 아주 간단하게 만들어서 함수가 더 이상은 서브 호출을 만들지 않게 해주는 인수이다. basis라고도 불린다.
재귀적으로 정의된 자료 구조
자기 자신의 일부를 복제하는 형태의 자료 구조이다.
연결 리스트
'재귀적으로 정의된 자료구조'에 속하는 연결 리스트는 리스트 혹은 null을 참조하는 객체로 이루어진 데이터 구조를 사용해 정의된다.
list = {value, next -> list}