LLM 총정리
1.LLM OverView

텍스트 다음에 올 단어의 확률을 계산하여 가장 높은 확률의 단어를 선택하는 대규모 언어 모델.In-context Learning: zero shot · few shot learningReasoning(Chain of thought)Representation Learni
2.LLM 용어 정리1
1. Word Embedding 단어의 의미를 숫자 형식으로 표현하여 AI모델에 입력하고 처리할 수 있도록 하는 알고리즘 고차원 공간에서 유사한 의미를 가진 단어를 가깝게 위치시켜서 단어를 맵핑 기존에는 One-hot Encoding을 단어 표현 방
3.LLM 용어 정리2
텍스트 분류, 질문 답변, 문서 요약 및 텍스트 생성과 같은 공통 언어문제 해결을 위해 모델 학습사전훈련된 LLM을 상대적으로 작은 양의 산업현장 dataset을 사용하여 훈련시킴.이를 통해 특정 작업 또는 도메인에 맞도록 미세조정하도록 하는 프로세스 ex) Bloom
4.LLM Tuning
1. 사전학습 LLM의 자연어 이해, 일반 상식 사전학습을 통해 사람과 LLM이 대화가 가능할 수 있도록 학습 ex) Bloomberg Dataset에서 C4 Dataset Self-Supervised Learning 일반적인 기계학습은 X
5.LLM Colab 실습
LLM 코랩 실습 코드: LLM colab 실습
6.Preprocessor
1. Preprocessor란? Neural Search를 위한 Chunk 생성 서비스 2. Chunk 문장을 작은 조각으로 분할하는 작업 텍스트나 문서에서 정보를 추출하거나 검색하는 작은 단위 Preprocessor로 문장을 의미적으로 유사한
7.HDFS
1. Hadoop이란? 1) 하나의 고사양 컴퓨터가 아닌, 범용 컴퓨터 여러 대를 클러스터화하여 대규모 데이터를 처리 2) 데이터를 병렬로 처리하여 속도가 향상됨 2. HDFS(Hadoop File System) Hadoop이 실행하는 파일들을 관리해주
8.LangChain
1. LangChain의 구조 LLM: 생성 모델의 핵심 구성 요소 -ex) GPT-3.5, LLAMA, StableVicuna 등등 Prompts: LLM에 지시하는 명령문 Index: LLM이 문서를 쉽게 탐색할 수 있도록 구조화하는
9.LLM & LangChain
1. Transformer 아키텍처 현재 NLP 모델의 거의 대부분은 Transformer 아키텍처를 기반으로 함 모델의 용도에 따라 Transformer의 Encoder, Decoder를 개별 또는 통합하여 사용 즉, Transformer의 발전 양상
10.NIFI
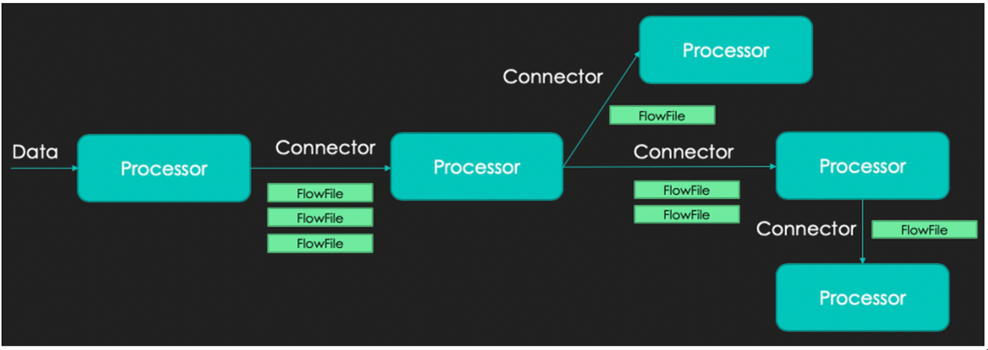
1. NIFI란? 데이터를 가져오고 처리한 후, 적재하기 위한 ETL(Extract-Transform-Load) Tools의 일종 FBP(Flow Based Programming)을 구현한 분산환경에서 대량의 데이터를 수집 처리하는 오픈소스 실시간