6주차 배운 내용
배열, 노드, 그리고 점근표기법을 배웠습니다.
1. 점근표기법 (Big-O Notation)
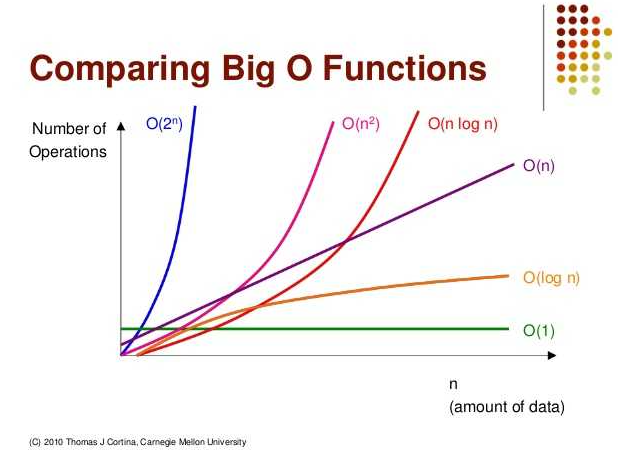
점근표기법이란 위 그림과 같이 자료의 양 대비 작업 효율성을 표현하는 방법 중 하나이다.
여기서 그래프에서 특별한 눈금이 없다는 사실을 생각해보면, 자료의 양이 무한대에 가까울 때도 가정한다고 볼 수 있다.
또한, O(n^2), O(n log n) 과 같은 식으로 상수의 연산이 없이 쓰이는 이유도 O(n^2 +1) 이나 O(n^2 * 44) 와 같은 상수의 연산은 자료양이 무한대에 가깝다고 가정하면 큰 영향이 없기 때문에 생략한다고 한다.
2. 배열 (Array)
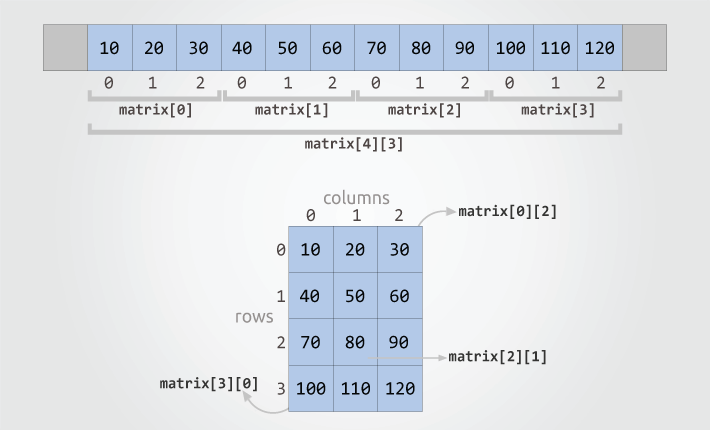
일반적으로 배열은 정적 배열을 말한다. 정적 타입의 언어인 C나 Java에서 내장하는 배열과 같은 개념이다.
처음 배열을 할당할 때 메모리에 배열의 크기만큼 먼저 할당을 받고 시작하기 때문에 크기를 변경하려면 새로운 크기의 배열을 할당해줘야 한다.
또한, 배열 내 각 데이터는 배열로 묶여있는 형태로 메모리에 있기 때문에 인덱스를 붙여 배열이름[인덱스]와 같은 형태로 탐색없이 바로 접근이 가능하다. (데이터 접근에 소모되는 비용 O(1))
그래서 배열은 읽기만 하는 자료구조일 때 효율적이며, 동적 크기의 배열을 필요로 할 때는 크기가 변경될 때마다 새로운 배열을 생성 해야하기 때문에 비효율적이다. (데이터 수정에 소모되는 비용 O(n), n은 크기)
3. 노드

노드란 연결이 가능한 최소단위이며, 연결을 할 대상의 주소의 참조와 데이터를 가진다.
1. 단일연결리스트 (Single Linked List)
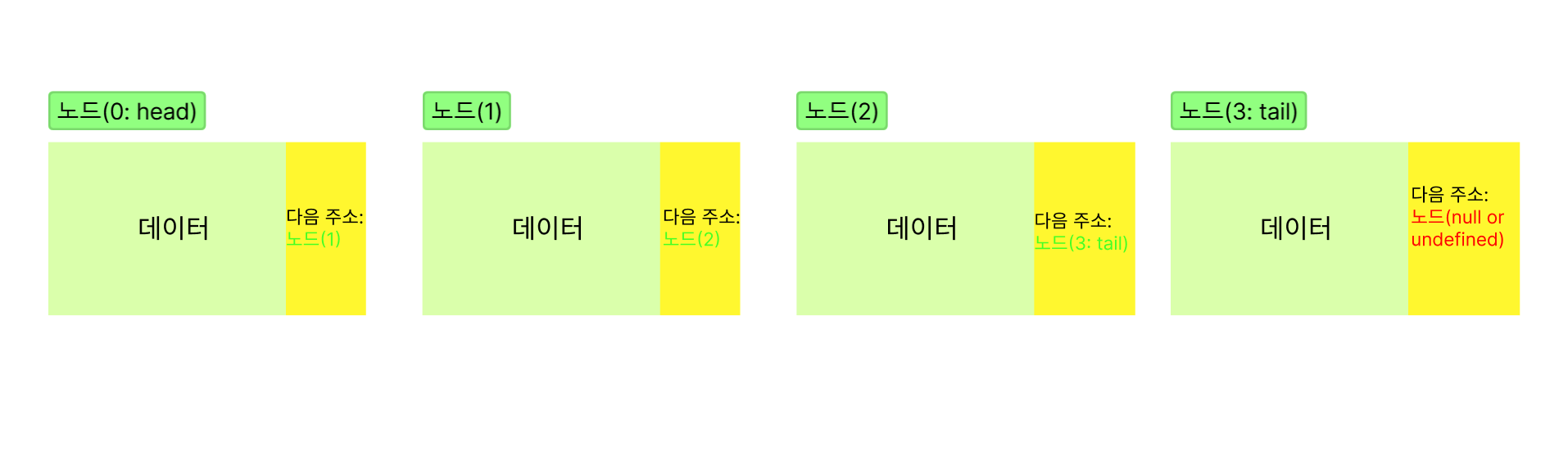
노드가 참조하는 주소값이 하나일 때, 한 방향으로 리스트가 형성되고 이를 단일연결리스트라고 부른다. 보통 첫 시작점이 되는 노드를 헤드노드라고 부르고, 가장 끝에 오는 노드를 테일노드라고 부른다.
-
첫 시작 노드인 헤드노드가 다음 주소값이 존재하지 않을 경우(null or undefined), 헤드노드는 테일노드이며 리스트의 길이는 1이다.
-
헤드노드가 가리키는 다음 노드가 존재하고 그 노드가 테일노드일 경우, 리스트의 길이는 2이다.
-
노드(n)을 삽입 할 때노드(n-1)의 다음 노드를노드(n)으로,노드(n)의 다음 노드를노드(n+1)로 연결해주면 된다.- 새로운 헤드일 경우에는 원래의 헤드노드가
노드(n+1)가 되고 새로운 노드가 헤드노드로 지정된다. - 새로운 테일은 원래 테일노드가
노드(n-1)이 되고 다음 노드는nullorundefined가 된다.
-
노드(n)을 제거할 때노드(n-1)의 다음 노드를노드(n+1)로 지정해주면노드(n)은 아무도 가리키지 않게 된다. 자바나 자바스크립트의 경우 Garbege Collector(통칭 쓰레기차)가노드(n)을 자기가 내킬 때 쓸어가준다.- 제거할 노드가 헤드일 경우에는 헤드노드의 다음노드를 헤드노드로 지정하면 된다.
- 제거할 노드가 테일일 경우에는
노드(n-1)의 다음노드를nullorundefined로 지정하면 된다.
-
자료를 접근할 때 다음 노드를 하나씩 찾아봐야 하므로 O(n)의 비용이 소모된다.
-
자료를 추가할 때 다음 노드를 하나씩 찾아 위치를 확인해야 하므로 O(n)의 비용이 소모되나, 끝에 추가할 경우 헤드/테일노드의 이전/다음 노드로 연결하면 되니 O(1)이 소모된다.
-
자료를 삭제할 때 또한 하나씩 확인해야 해서 O(n)이 소모되나, 끝일 경우 O(1)이다.
2. 큐와 스택 (Queue and Stack)
1. 큐
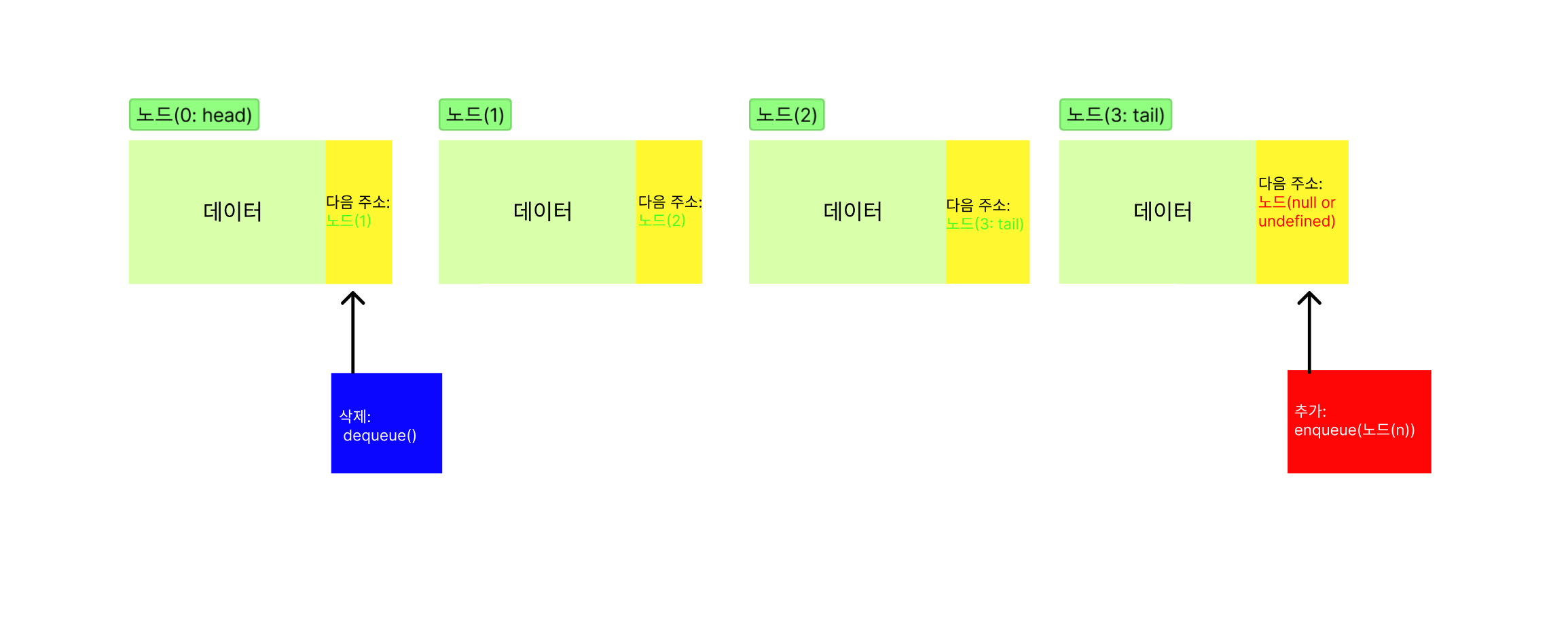
큐의 경우, 삭제(dequeue)는 항상 헤드노드에서, 추가(enqueue)는 항상 테일노드에서 일어나는 구조이다.
일반적인 줄서기나 선착순의 개념과 같다.

2. 스택
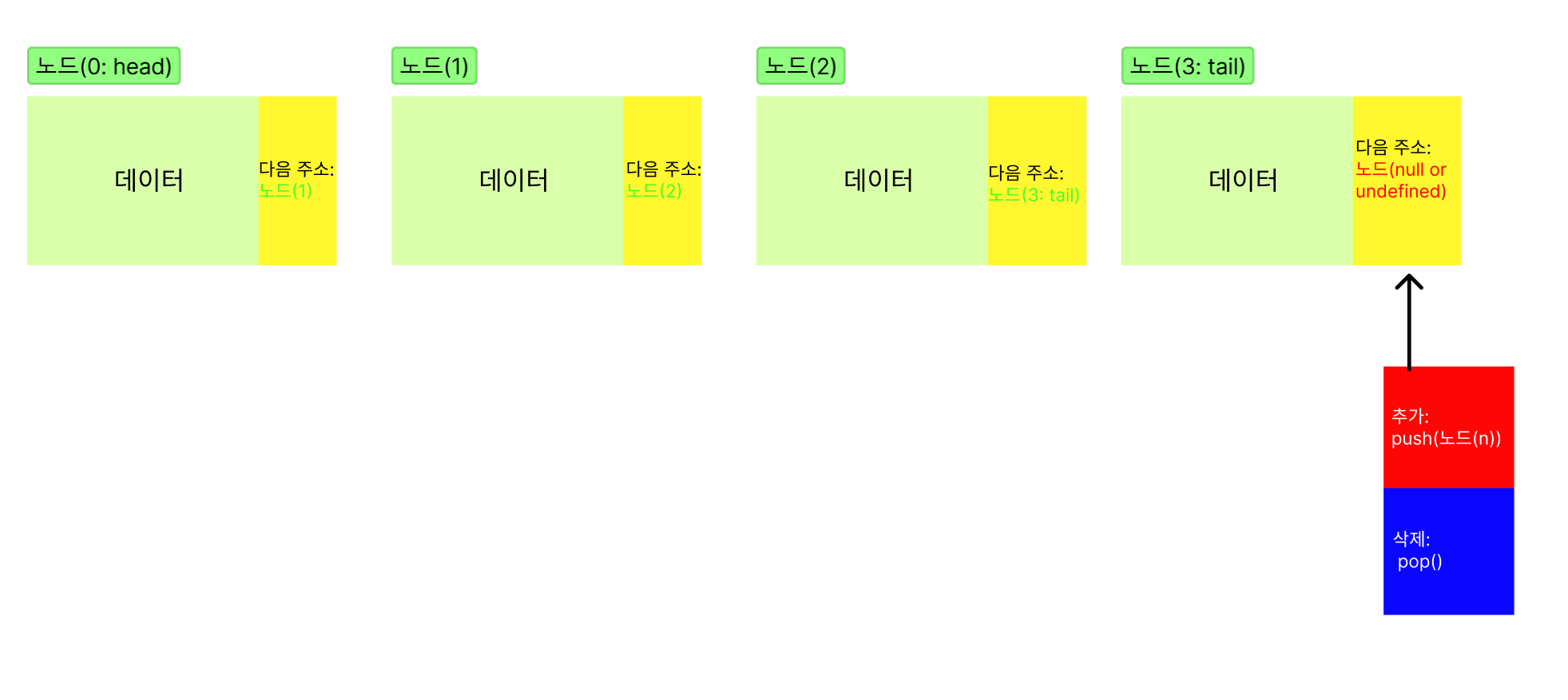
스택의 경우, 추가와 삭제하는 위치가 항상 테일노드이다.
대표적인 예로 뽑아쓰는 휴지가 있다.

마치며
자료구조를 코드로 표현하려고 연습하다 보니, 이해는 잘 되었는데 지금 진행중인 프로젝트나 포트폴리오에 사용하기엔 내 수준이 아직 미숙해서 딱히 쓸 곳이 없어서 아쉽다. 아마 자료정렬을 해야할 정도로 크기가 커져야 유의미한 사용을 할 수 있지 않을까 싶다.
