주의!
여기서 말하는 '스트림' 은 Java 8 에서부터 추가된 스트림 API 를 뜻한다.
'입출력 스트림'과는 전혀 다른 개념이다.
1. 정의
-
자바 8 이전에는 배열 또는 Collection 인스턴스를 for 또는 foreach 문을 돌면서 요소 하나씩을 꺼내서 다루는 방법을 사용
- 로직이 복잡해질수록, 코드 多
- 메소드를 나눌 경우, 루프를 여러 번 돌게 되어버림
-
자바 8부터 Stream API와 람다식, 함수형 인터페이스 등...을 지원하면서, Java를 이용해 함수형으로 프로그래밍할 수 있는 API 들을 제공해주고 있다.
(원래 Java는 객체지향 언어이기 때문에, 기본적으로 함수형 프로그래밍이 불가능) -
람다를 활용할 수 있는 기술 中 하나
- 컬렉션의 저장 요소를 하나씩 참조해서, 람다식으로 처리할 수 있도록 해주는 반복자
-
Stream 연산들은 매개변수로 함수형 인터페이스를 받고,
람다식은 반환값으로 함수형 인터페이스를 반환한다. -
스트림은 한 요소씩 수직적으로(vertically) 실행된다.
참고: 자바 컬렉션 (Java Collection)
참고: 람다식(람다 표현식, Lambda Expression)
2. 특징
1) 원본의 데이터를 변경 X
List<String> sortedList = nameStream.sorted()
.collect(Collections.toList());Stream API는 원본의 데이터를 조회하여, 원본의 데이터가 아닌 별도의 요소들로 Stream을 생성
→ 원본의 데이터로부터 읽기만 할 뿐
→ 정렬이나 필터링 등...의 작업은 별도의 Stream 요소들에서 처리
2) 일회용
userStream.sorted().forEach(System.out::print);
// 스트림이 이미 사용되어 닫혔으므로 에러 발생
int count = userStream.count();
// IllegalStateException 발생
java.lang.IllegalStateException: stream has already been operated upon or closed
at java.util.stream.AbstractPipeline.evaluate(AbstractPipeline.java:229)
at java.util.stream.ReferencePipeline.noneMatch(ReferencePipeline.java:459)- Stream API는 일회용이기 때문에, 한번 사용이 끝나면 재사용이 불가능
→ Stream 이 또 필요한 경우, Stream을 다시 생성해주어야 한다.
→ 닫힌 Stream을 다시 사용한다면, IllegalStateException 이 발생
3) 내부 반복으로 작업을 처리
// 반복문이 forEach라는 함수 내부에 숨겨져 있다.
nameStream.forEach(System.out::println);- 내부 반복으로 인해, Stream 을 사용하면 코드가 간결해진다.
- 기존 : 반복문을 위해 for, while 등... 을 사용
- stream : 반복 문법을 메소드 내부에 숨기고 있다.
4) 병렬 처리
병렬처리(multi-threading)가 가능하다
참고: 운영체제 (OS) - 3) 멀티 스레드 (Multi Thread)
3. 비교
1) Iterator 과 Stream
Iterator 를 사용할 경우
ArrayList<Integer> list = new ArrayList<Integer>(Arrays.asList(1,2,3));
Iterator<Integer> iter = list.iterator();
while(iter.hasNext()) {
int num = iter.next();
System.out.println("값 : "+num);
}-
자바 6이전까지는 ArrayList에서 요소를 순차적으로 처리하기 위해, Iterator라는 반복자를 사용했다.
Stream 을 사용할 경우
ArrayList<Integer> list = new ArrayList<Integer>(Arrays.asList(1,2,3));
Stream<Integer> stream = list.stream(); // 1. stream()메소드로 스트림 객체를 얻은 후
stream.forEach(num -> System.out.println("값 : "+num)); // 2. ArrayList에 있는 요소들을 하나씩 출력-
람다식으로 기술 된 부분에는 Stream 이 들어가는 부분이 많다.
-
장점
- 람다식으로 요소 처리 코드를 제공하여, 코드가 좀 더 간결하게 할 수 있다.
- 내부 반복자를 사용하므로, 병렬 처리가 쉽다.
2) 직접 정렬 과 Stream
데이터를 직접 정렬할 경우
String[] nameArr = {"IronMan", "Captain", "Hulk", "Thor"}
List<String> nameList = Arrays.asList(nameArr);
// 원본의 데이터가 직접 정렬됨
Arrays.sort(nameArr);
Collections.sort(nameList);
for (String str: nameArr) {
System.out.println(str);
}
for (String str : nameList) {
System.out.println(str);
}Stream 을 사용한 코드
String[] nameArr = {"IronMan", "Captain", "Hulk", "Thor"}
List<String> nameList = Arrays.asList(nameArr);
// 원본의 데이터가 아닌 별도의 Stream을 생성함
Stream<String> nameStream = nameList.stream();
Stream<String> arrayStream = Arrays.stream(nameArr);
// 복사된 데이터를 정렬하여 출력함
nameStream.sorted().forEach(System.out::println);
arrayStream.sorted().forEach(System.out::println);4. 동작 순서
list.stream()
.filter(el -> {
System.out.println("filter() was called.");
return el.contains("a");
})
.map(el -> {
System.out.println("map() was called.");
return el.toUpperCase();
})
.findFirst();filter() was called.
filter() was called.
map() was called.-
요소는 3개 : filter 두 번, map 이 한 번 출력된다.
-
모든 요소가 첫 번째 중간 연산을 수행하고 남은 결과가 다음 연산으로 넘어가는 것이 아니라
한 요소가 모든 파이프라인을 거쳐서 결과를 만들어내고, 다음 요소로 넘어가는 순- 처음 요소인 “Eric” : “a” 문자열을 가지고 있지 않기 때문에, 다음 요소로 넘어간다. 이 때 “filter() was called.” 가 한 번 출력된다.
- 다음 요소인 “Elena” : "filter() was called."가 한 번 더 출력된다. "Elena"는 "a"를 가지고 있기 때문에, 다음 연산으로 넘어갈 수 있다.
- 다음 연산인 map : toUpperCase 메소드가 호출된다. 이 때 "map() was called"가 출력된다.
- 마지막 연산인 findFirst : 첫 번째 요소만을 반환한다.
→ 따라서 최종 결과는 “ELENA” 이고, 다음 연산은 수행할 필요가 없어 종료
5. Stream API의 연산 종류
List<String> myList = Arrays.asList("a1", "a2", "b1", "c2", "c1");
myList
.stream() // 생성하기
.filter(s -> s.startsWith("c")) // 가공하기 : 데이터 필터링
.map(String::toUpperCase) // 가공하기 : 데이터 변형
.sorted() // 가공하기 : 데이터 정렬
.count(); Stream은 데이터를 처리하기 위해 다양한 연산들을 지원한다.
스트림에 대한 연산은 생성하기, 가공하기, 결과 만들기 3가지 단계로 나눌 수 있다.
1) 생성하기
(1) 정의
- 배열, 컬렉션, 임의의 수, 파일 등... 거의 모든 것을 가지고 Stream 객체를 생성할 수 있다.
(단, Stream은 재사용이 불가능하므로, 닫히면 다시 생성해주어야 한다.)
(2) 종류
① Collection 에서 Stream 생성
// List로부터 스트림을 생성
List<String> list = Arrays.asList("a", "b", "c");
Stream<String> listStream = list.stream();-
Collection 인터페이스에는 stream()이 정의되어 있기 때문에,
Collection 인터페이스를 구현한 객체들(List, Set 등)은 모두 이 메소드를 이용해 Stream을 생성할 수 있다.
→ stream() : 인터페이스에 추가된 디폴트 메소드 -
stream()을 사용하면, 해당 Collection의 객체를 소스로 하는 Stream을 반환한다.
② 배열에서 Stream 생성
// 배열에서 스트림을 생성
Stream<String> stream1 = Arrays.stream(arr);
Stream<String> stream = Stream.of(new String[] {"a", "b", "c"});
Stream<String> stream = Arrays.stream(new String[] {"a", "b", "c"});
Stream<String> stream = Arrays.stream(new String[] {"a", "b", "c"}, 0, 3); // end범위 포함 x
// 배열의 특정 부분만을 이용한 스트림을 생성
Stream<String> stream2 = Arrays.stream(arr, 1, 3);- Stream의 of 메소드 또는 Arrays의 stream 메소드를 사용하면 된다.
③ 가변 매개변수
Stream<String> stream = Stream.of("a", "b", "c");④ 원시(기본 타입형) Stream 생성
// range() : 4이상 10 이하의 숫자를 갖는 IntStream
IntStream stream = IntStream.range(4, 10);
// rangeClosed()
IntStream stream2 = IntStream.rangeClosed(1, 4);
// 필요한 경우 boxed 메소드를 이용해서 박싱(boxing)할 수 있다.
Stream<Integer> boxedIntStream = IntStream.range(1, 5).boxed();-
(객체를 위한 Stream 외에도) int, long, double 같은 원시 자료형들을 사용하기 위한 특수한 종류의 Stream(IntStream, LongStream, DoubleStream) 들도 사용 가능
- Intstream 의 경우, range()함수를 사용하여 기존의 for문을 대체할 수 있다.
- range() : 명시된 시작 정수를 포함하지만, 명시된 마지막 정수는 포함하지 않는 스트림을 생성
- rangeClosed() :명시된 시작 정수뿐만 아니라 명시된 마지막 정수까지도 포함하는 스트림을 생성
- Intstream 의 경우, range()함수를 사용하여 기존의 for문을 대체할 수 있다.
-
제네릭을 사용하지 않기 때문에, 불필요한 오토박싱(auto-boxing)이 일어나지 않는다.
(단, 필요한 경우 boxed 메소드를 이용해서 박싱(boxing)할 수 있다.)
⑤ 특정 타입의 난수들
IntStream stream = new Random().ints(4);- Random 클래스에는 ints(), longs(), doubles()와 같은 메소드가 정의되어 있다.
- 이 메소드들은 매개변수로 스트림의 크기를 long 타입으로 전달받을 수 있다.
- 이 메소드들은 만약 매개변수를 전달받지 않으면 크기가 정해지지 않은 무한 스트림(infinite stream)을 반환
→ 이 경우, limit() 메소드를 사용하여 따로 스트림의 크기를 제한해야 한다.
⑥ 람다 표현식
// iterate() 메소드 예시 1
IntStream stream = Stream.iterate(2, n -> n + 2); // 2, 4, 6, 8, 10, ...
// iterate() 메소드 예시 2
Stream<Integer> iteratedStream = Stream.iterate(30, n -> n + 2).limit(5); // [30, 32, 34, 36, 38]
// 30이 초기값이고 값이 2씩 증가하는 값
// generate() 메소드
Stream<String> generatedStream = Stream.generate(() -> "gen").limit(5); // [el, el, el, el, el]
// 5개의 “gen” 이 들어간 스트림이 생성됨 -
iterate()
- 시드(seed)로 명시된 값을 람다 표현식에 사용하여 반환된 값을 다시 시드로 사용하는 방식으로 무한 스트림을 생성
→ 크기가 정해져있지 않고 무한하기 때문에, 특정 사이즈로 최대 크기를 제한해야 한다. - 초기값과 해당 값을 다루는 람다를 이용해서 스트림에 들어갈 요소를 만든다.
- 시드(seed)로 명시된 값을 람다 표현식에 사용하여 반환된 값을 다시 시드로 사용하는 방식으로 무한 스트림을 생성
-
generate()
- 매개변수가 없는 람다 표현식을 사용하여 반환된 값으로 무한 스트림을 생성
→ 크기가 정해져있지 않고 무한하기 때문에, 특정 사이즈로 최대 크기를 제한해야 한다. - Supplier< T > 에 해당하는 람다로 값을 넣을 수 있다.
(Supplier< T > : 인자는 없고 리턴값만 있는 함수형 인터페이스)
- 매개변수가 없는 람다 표현식을 사용하여 반환된 값으로 무한 스트림을 생성
⑦ 파일 스트림
String<String> stream = Files.lines(Path path);- 파일의 한 행(line)을 요소로 하는 스트림을 생성
- lines() 메소드를 사용하면 파일뿐만 아니라 다른 입력으로부터도 데이터를 행(line) 단위로 읽어 올 수 있습니다.
⑧ 빈 스트림
// 예시 1
Stream<Object> stream = Stream.empty();
// 예시 2
public Stream<String> streamOf(List<String> list) {
return list == null || list.isEmpty()
? Stream.empty()
: list.stream();
}- 아무 요소도 가지지 않는 빈 스트림은 Stream 클래스의 empty() 메소드를 사용하여 생성
- 요소가 없을 때 null 대신 사용할 수 있다.
⑨ 빌더(Builder)
Stream<String> builderStream =
Stream.<String>builder()
.add("Eric").add("Elena").add("Java")
.build(); // [Eric, Elena, Java]- 빌더(Builder)를 사용해서, 스트림에 직접적으로 원하는 값을 넣는다.
⑩ 문자열 스트림
// 스트링의 각 문자(char)를 IntStream 으로 변환
IntStream charsStream = "Stream".chars(); // [83, 116, 114, 101, 97, 109]
// 정규표현식(RegEx)을 이용해서 문자열을 자르고, 각 요소들로 스트림을 만듦
Stream<String> stringStream = Pattern.compile(", ").splitAsStream("Eric, Elena, Java"); // [Eric, Elena, Java]- char 는 문자이지만 본질적으로는 숫자이기 때문에 가능
⑪ 병렬 스트림
// 병렬 스트림 생성
Stream<Product> parallelStream = productList.parallelStream();
// 병렬 여부 확인
boolean isParallel = parallelStream.isParallel();boolean isMany = parallelStream
.map(product -> product.getAmount() * 10)
.anyMatch(amount -> amount > 200);- stream(스트림 생성 시 사용)대신 parallelStream 메소드를 사용해서 병렬 스트림을 쉽게 생성할 수 있다.
- 쓰레드를 처리하기 위해 자바 7부터 도입된 Fork/Join framework 를 사용
- 각 코드를 쓰레드를 이용해 병렬 처리
Arrays.stream(arr).parallel();- 배열을 이용해서 병렬 스트림을 생성하는 경우
IntStream intStream = IntStream.range(1, 150).parallel();
boolean isParallel = intStream.isParallel();
// 시퀀셜(sequential) 모드로 돌리고 싶다면, sequential 메소드를 사용
IntStream intStream = intStream.sequential();
boolean isParallel = intStream.isParallel();컬렉션과배열이 아닌 경우, parallel 메소드를 이용해서 처리
⑫ 스트림 연결
Stream<String> stream1 = Stream.of("Java", "Scala", "Groovy");
Stream<String> stream2 = Stream.of("Python", "Go", "Swift");
Stream<String> concat = Stream.concat(stream1, stream2);
// [Java, Scala, Groovy, Python, Go, Swift]- Stream.concat 메소드를 이용해 두 개의 스트림을 연결해서 새로운 스트림을 만들어낼 수 있습니다.
⑬ Null-safe 스트림 생성
public <T> Stream<T> collectionToStream(Collection<T> collection) {
return Optional
.ofNullable(collection) // 인자로 받은 컬렉션 객체를 이용해 옵셔널 객체를 만들고
.map(Collection::stream) // 스트림을 생성후 리턴
.orElseGet(Stream::empty); // 만약 컬렉션이 비어있는 경우라면, 빈 스트림을 리턴
}
// 예시
List<Integer> intList = Arrays.asList(1, 2, 3);
List<String> strList = Arrays.asList("a", "b", "c");
Stream<Integer> intStream =
collectionToStream(intList); // [1, 2, 3]
Stream<String> strStream =
collectionToStream(strList); // [a, b, c] -
NullPointerException 예외가 발생한다면?
→ Optional 을 이용해서 null에 안전한(Null-safe) 스트림을 생성할 수 있다. -
제네릭을 이요하므로, 어떤 타입이든 받을 수 있다.
2) 가공하기
(1) 정의
- 원본의 데이터를 별도의 데이터로 가공하기 위한 중간 연산의 단계
- 어떤 객체의 Stream을 원하는 형태로 처리 가능
- 중간 연산의 반환값은 Stream 으로써, 필요한 만큼 중간 연산을 연결해서 사용 가능 (연산 파이프라인 : Stream 연산이 연결된 것)
→ 세미콘론(;) 없이 연결 가능하다.
(2) 종류
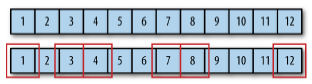
① Filtering
// 예시 1
Stream<String> stream =
list.stream()
.filter(name -> name.contains("a")); // String의 stream에서 a가 들어간 문자열만을 포함하도록 필터링
// 예시 2
Stream<String> stream =
names.stream()
.filter(name -> name.contains("a")); // [Elena, Java]-
스트림 내 요소들을 하나씩 평가해서 걸러내는 작업
-
Stream에서 조건에 맞는 데이터만을 정제하여 더 작은 컬렉션을 만들어내는 연산
-
Java에서는 filter 함수의 인자로 함수형 인터페이스 Predicate를 받고 있기 때문에, boolean을 반환하는 람다식을 작성하여 filter 함수를 구현할 수 있다.
② Mapping
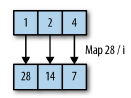
- map
// 예시 1 : 스트림 내 String 의 toUpperCase 메소드를 실행해서 대문자로 변환한 값들이 담긴 스트림을 리턴
Stream<String> stream =
names.stream()
.map(s -> s.toUpperCase()); // [ERIC, ELENA, JAVA]
// 예시 2 : 요소 내 들어있는 Product 개체의 수량을 꺼내올 수도 있다. 각 ‘상품’을 ‘상품의 수량’으로 맵핑
Stream<Integer> stream =
productList.stream()
.map(Product::getAmount); // [23, 14, 13, 23, 13]-
기존의 Stream 요소들을 변환하여, 새로운 Stream을 형성하는 연산
-
스트림 내 요소들을 하나씩 특정 값으로 변환
→ 값을 변환하기 위한 람다를 인자로 받는다. -
Java에서는 map 함수의 인자로 함수형 인터페이스 function을 받고 있다.
- 예시 : String을 요소들로 갖는 Stream을 모두 대문자 String의 요소들로 변환하고자 할 때 map을 이용할 수 있다.
Stream<File> fileStream = Stream.of(new File("Test1.java"), new File("Test2.java"), new File("Test3.java"));
// 파일의 Stream 을 파일 이름의 Stream 으로 변경
// Stream<File> --> Stream<String> 변환
Stream<String> fileNameStream = fileStream.map(File::getName); - map 함수의 람다식은 메소드 참조를 이용해 변경이 가능
- flatMap
// 중첩된 리스트가 있다.
List<List<String>> list =
Arrays.asList(Arrays.asList("a"),
Arrays.asList("b")); // [[a], [b]]
// 이를 flatMap을 사용해서 중첩 구조를 제거한 후 작업
List<String> flatList =
list.stream()
.flatMap(Collection::stream)
.collect(Collectors.toList()); // [a, b]
// 만약, flatMap을 객체에 적용할 경우 : 학생 객체를 가진 스트림에서 학생의 국영수 점수를 뽑아 새로운 스트림을 만들어 평균을 구한다
students.stream()
.flatMapToInt(student ->
IntStream.of(student.getKor(),
student.getEng(),
student.getMath()))
.average().ifPresent(avg ->
System.out.println(Math.round(avg * 10)/10.0));- flatMap 는 플래트닝(flattening) 작업을 한다.
→ 플래트닝(flattening) : 중첩 구조를 한 단계 제거하고 단일 컬렉션으로 만들어주는 역할
→ map 메소드 자체만으로는 한번에 할 수 없는 기능
③ 정렬 - Sorted
// 인자 없이 그냥 호출할 경우 : 오름차순으로 정렬
IntStream.of(14, 11, 20, 39, 23)
.sorted()
.boxed()
.collect(Collectors.toList()); // [11, 14, 20, 23, 39]
List<String> list = Arrays.asList("Java", "Scala", "Groovy", "Python", "Go", "Swift");
// 스트링 리스트에서 알파벳 순으로 정렬한 코드
Stream<String> stream = list.stream()
.sorted() // [Go, Groovy, Java, Python, Scala, Swift]
// Comparator 를 넘겨서 역순으로 정렬한 코드
Stream<String> stream = list.stream()
.sorted(Comparator.reverseOrder()) // [Swift, Scala, Python, Java, Groovy, Go]-
Stream의 요소들을 정렬하기 위해서는 sorted 를 사용
-
파라미터로 Comparator 를 넘길 수도 있다.
- Comparator 인자 없이 호출할 경우 : 오름차순으로 정렬
- Comparator의 reverseOrder를 이용할 경우 : 내림차순으로 정렬
lang.stream()
.sorted(Comparator.comparingInt(String::length))
.collect(Collectors.toList()); // [Go, Java, Scala, Swift, Groovy, Python]
lang.stream()
.sorted((s1, s2) -> s2.length() - s1.length())
.collect(Collectors.toList()); // [Groovy, Python, Scala, Swift, Java, Go]- 문자열 길이를 기준으로 정렬할 수도 있다.
④ 중복 제거 - Distinct
-
클래스가 하나 존재한다.
public class Employee { private String name; public Employee(String name) { this.name = name; } public String getName() { return name; } // equals() 오버라이드 @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Employee employee = (Employee) o; return Objects.equals(name, employee.name); } // hashCode() 오버라이드 @Override public int hashCode() { return Objects.hash(name); } }
-
주의!
생성한 클래스를 Stream으로 사용할 경우, equals와 hashCode를 오버라이드 해야만 distinct()를 제대로 적용할 수 있다.
-
중복을 제거하기 위해 distinct를 사용
public class Main { public static void main(String[] args) { Employee e1 = new Employee("MangKyu"); Employee e2 = new Employee("MangKyu"); List<Employee> employees = new ArrayList<>(); employees.add(e1); employees.add(e2); int size = employees.stream().distinct().collect(Collectors.toList()).size(); System.out.println(size); } }
⑤ 특정 연산 수행 - Peek
int sum = IntStream.of(1, 3, 5, 7, 9)
.peek(System.out::println)
.sum();-
"peek" = "확인해본다"
-
Stream의 요소들을 대상으로 Stream에 영향을 주지 않고, 특정 연산을 수행하기 위한 함수
→ Stream의 각각의 요소들에 대해 특정 작업을 수행할 뿐
→ 결과에 영향을 주지 않는다. -
peek 함수는 파라미터로 함수형 인터페이스 Consumer를 인자로 받는다.
-
예시 : 작업을 처리하는 중간에 결과를 확인해볼 때 사용
⑥ 원시 Stream <-> Stream
// IntStream -> Stream<Integer>
IntStream.range(1, 4)
.mapToObj(i -> "a" + i)
// Stream<Double> -> IntStream -> Stream<String>
Stream.of(1.0, 2.0, 3.0)
.mapToInt(Double::intValue)
.mapToObj(i -> "a" + i)- 일반적인 Stream 객체를 원시 Stream 로 바꾸거나 그 반대로 하는 작업
- 일반적인 Stream 객체 : mapToInt(), mapToLong(), mapToDouble()이라는 특수한 Mapping 연산을 지원하여 원시 Stream 객체로 바꿈
- 원시 Stream 객체 : mapToObject 를 통해, 일반적인 Stream 객체로 바꿈
3) 결과 만들기
(1) 정의
- 가공된 데이터로부터 원하는 결과를 만들기 위한 최종 연산
→ Stream의 요소들을 소모하면서 연산이 수행되기 때문에, 1번만 처리 가능
(2) 종류
① Calculating (최댓값 Max / 최솟값 Min / 총합 Sum / 평균 Average / 갯수 Count)
OptionalInt min = IntStream.of(1, 3, 5, 7, 9).min();
int max = IntStream.of().max().orElse(0);
IntStream.of(1, 3, 5, 7, 9).average().ifPresent(System.out::println);- min, max, average : Stream 이 비어있는 경우, 값을 특정할 수 없다.
→ 따라서, Optional로 값이 반환된다.
→ Optional 는 스트림에서 ifPresent 메소드를 이용하여 처리
long count = IntStream.of(1, 3, 5, 7, 9).count();
long sum = LongStream.of(1, 3, 5, 7, 9).sum();- Sum, Count : 값이 비어있는 경우, 0 으로 값을 특정할 수 있다.
→ 따라서, Stream API는 sum 메소드와 count 메소드에 대해Optional이 아닌원시 값을 반환하도록 구현해두었다.
(단, Stream이 비어있을 경우에는 0 을 반환)
② Collecting (데이터 수집 collect)
collect() : 스트림의 최종연산, 매개변수로 Collector를 필요로 한다.
Collector : 인터페이스, collect의 파라미터는 이 인터페이스를 구현해야한다.
Collectors : 클래스, static메소드로 미리 작성된 컬렉터를 제공한다.
// collect의 파라미터로 Collector의 구현체가 와야 한다.
Object collect(Collector collector)-
Stream의 요소들을 List나 Set, Map, 등... 다른 종류의 결과로 수집하고 싶은 경우에는 collect 함수를 이용할 수 있다.
- 일반적으로 List로 Stream의 요소들을 수집하는 경우 多
→ 자주 사용하는 작업은 Collectors 객체에서 static 메소드로 제공하고 있다.
→ 원하는 것이 없는 경우에는 Collector 인터페이스를 직접 구현하여 사용할 수도 있다.
- 일반적으로 List로 Stream의 요소들을 수집하는 경우 多
-
collect 함수는 어떻게 Stream의 요소들을 수집할 것인가를 정의한 Collector 타입을 인자로 받아서 처리
- Collectors.toList()
// Stream의 요소들을 Product의 이름으로 변환하여, 그 결과를 List로 반환받고 있다. List<String> nameList = productList.stream() .map(Product::getName) .collect(Collectors.toList());
- Stream에서 작업한 결과를 List로 반환받을 수 있다.
- 만약 해당 결과를 set으로 반환받기를 원한다면 Collectors.toSet()을 사용할 수 있다.
-
Collectors.joining()
String listToString = productList.stream() .map(Product::getName) .collect(Collectors.joining()); // potatoesorangelemonbreadsugar String listToString = productList.stream() .map(Product::getName) .collect(Collectors.joining(" ")); // potatoes orange lemon bread sugar String listToString = productList.stream() .map(Product::getName) .collect(Collectors.joining(", ", "<", ">")); // <potatoes, orange, lemon, bread, sugar>
- Stream에서 작업한 결과를 1개의 String으로 이어 붙이기를 원하는 경우에 사용
- Collectors.joining()은 총 3개의 인자를 받을 수 있는데, 이를 이용하면 간단하게 String을 조합할 수 있다.
- delimiter : 각 요소 중간에 들어가 요소를 구분시켜주는 구분자
- prefix : 결과 맨 앞에 붙는 문자
- suffix : 결과 맨 뒤에 붙는 문자
-
Collectors.averagingInt(), Collectors.summingInt()
Double averageAmount = productList.stream() .collect(Collectors.averagingInt(Product::getAmount)); // collect 사용 Integer summingAmount = productList.stream() .collect(Collectors.summingInt(Product::getAmount)); // 86 // mapToInt 사용 : collect 보다 더 간단하게 표현 가능 Integer summingAmount = productList.stream() .mapToInt(Product::getAmount) .sum(); // 86
- Stream에서 작업한 결과의 평균값이나 총합 등...을 구할 경우에 사용
-
Collectors.summarizingInt()
// IntSummaryStatistics 객체가 반환되며, 필요한 값에 대해 get 메소드를 이용하여 원하는 값을 꺼내면 된다 IntSummaryStatistics statistics = productList.stream() .collect(Collectors.summarizingInt(Product::getAmount)); //IntSummaryStatistics {count=5, sum=86, min=13, average=17.200000, max=23}
-
3과 같이 작업한 결과의 평균값이나 총합 등...을 구할 경우
& 1개의 Stream으로부터 갯수, 합계, 평균, 최댓값, 최솟값을 한번에 얻고 싶은 경우에 사용 -
IntSummaryStatistics 객체에는 다음과 같은 정보가 담겨 있다.
개수: getCount()
합계: getSum()
평균: getAverage()
최소: getMin()
최대: getMax()
-
Collectors.groupingBy()
Map<Integer, List<Product>> collectorMapOfLists = productList.stream() .collect(Collectors.groupingBy(Product::getAmount)); /* 결과는 Map 타입으로 나온다 {23=[Product{amount=23, name='potatoes'}, Product{amount=23, name='bread'}], 13=[Product{amount=13, name='lemon'}, Product{amount=13, name='sugar'}], 14=[Product{amount=14, name='orange'}]} */
- Stream에서 작업한 결과를 특정 그룹으로 묶기
- 결과는 Map으로 반환받게 된다.
- 매개변수로 함수형 인터페이스 Function을 필요로 한다.
- 예시 : 수량을 기준으로 grouping을 원하는 경우에 다음과 같이 작성할 수 있으며, 같은 수량일 경우에는 List로 묶어서 값을 반환받게 된다.
-
Collectors.partitioningBy()
Map<Boolean, List<Product>> mapPartitioned = productList.stream() .collect(Collectors.partitioningBy(p -> p.getAmount() > 15)); /* 평가를 하는 함수 boolean 를 통해서, 스트림 내 요소들을 true 와 false 두 가지로 나눌 수 있다. {false=[Product{amount=14, name='orange'}, Product{amount=13, name='lemon'}, Product{amount=13, name='sugar'}], true=[Product{amount=23, name='potatoes'}, Product{amount=23, name='bread'}]} */
- 함수형 인터페이스 Predicate를 받아, Boolean을 Key값으로 partitioning한다.
(5 에서의 Collectors.groupingBy() 과 반대) - 예시 : 제품의 갯수가 15보드 큰 경우와 그렇지 않은 경우를 나누고자 한다면 다음과 같이 코드를 작성할 수 있다.
- Collectors.collectingAndThen()
// 결과를 Set 으로 collect 한 후, 수정 불가한 Set 으로 변환하는 작업을 추가로 실행
Set<Product> unmodifiableSet =
productList.stream()
.collect(Collectors.collectingAndThen(Collectors.toSet(),
Collections::unmodifiableSet));- 특정 타입으로 결과를 collect 한 이후, 추가 작업이 필요한 경우에 사용
- finisher 가 추가된 모양인데, 이 피니셔는 collect 를 한 후에 실행할 작업을 의미합니다.
- Collector.of()
public static<T, R> Collector<T, R, R> of(
Supplier<R> supplier, // new collector 생성
BiConsumer<R, T> accumulator, // 두 값을 가지고 계산 → reduce 에서 살펴본 내용과 동일
BinaryOperator<R> combiner, // 계산한 결과를 수집하는 함수 → reduce 에서 살펴본 내용과 동일
Characteristics... characteristics) { ... }
// 예시
Collector<Product, ?, LinkedList<Product>> toLinkedList =
Collector.of(LinkedList::new, // collector 를 하나 생성 + 컬렉터를 생성하는 supplier 에 LinkedList 의 생성자를 넘겨준다
LinkedList::add, // accumulator 에는 리스트에 추가하는 add 메소드를 넘겨준다
(first, second) -> {
first.addAll(second); // combiner 를 이용해 결과를 조합 → 생성된 리스트들을 하나의 리스트로 합친다.
return first;
});// collect 메소드에 커스텀 컬렉터를 넘겨줄 수 있고, 결과가 담긴 LinkedList 가 반환된다.
LinkedList<Product> linkedListOfPersons =
productList.stream()
.collect(toLinkedList);③ Matching (조건 검사 Match)
// 모두 true 를 반환
List<String> names = Arrays.asList("Eric", "Elena", "Java");
boolean anyMatch = names.stream()
.anyMatch(name -> name.contains("a"));
boolean allMatch = names.stream()
.allMatch(name -> name.length() > 3);
boolean noneMatch = names.stream()
.noneMatch(name -> name.endsWith("s"));-
Stream의 요소들이 특정한 조건을 충족하는지 검사하고 싶은 경우에 사용
-
함수형 인터페이스 Predicate를 받아서 해당 조건을 만족하는지 검사
검사 결과를 boolean으로 반환 -
match 함수
- anyMatch: 1개의 요소라도 해당 조건을 만족하는가
- allMatch: 모든 요소가 해당 조건을 만족하는가
- nonMatch: 모든 요소가 해당 조건을 만족하지 않는가
④ 특정 연산 수행 - forEach
names.stream()
.forEach(System.out::println);- Stream 요소를 돌면서 실행되는 최종 작업
- 보통 System.out.println 메소드를 넘겨서 결과를 출력할 때 사용하곤 한다.
- 비교
- peek()
- 중간 연산
- 실제 요소들에 영향을 주지 않은 채로 작업을 진행
- Stream 을 반환
- forEach()
- 최종 연산
- 실제 요소들에 영향을 줄 수 있다
- 반환값이 존재하지 않는다.
- 해당 스트림의 요소를 하나씩 소모해가며 순차적으로 요소에 접근하는 메소드
- peek()
⑤ Reduction
// 인자(파라미터)가 1개인 경우 (accumulator)
Optional<T> reduce(BinaryOperator<T> accumulator);
// 예시 : 두 값을 더하는 람다를 넘긴다. 따라서 결과는 6 이다.(1 + 2 + 3 이므로)
OptionalInt reduced =
IntStream.range(1, 4) // [1, 2, 3]
.reduce((a, b) -> {
return Integer.sum(a, b);
});
// 인자(파라미터)가 2개인 경우 (identity)
T reduce(T identity, BinaryOperator<T> accumulator);
// 예시 : 10은 초기값이고, 스트림 내 값을 더해서 결과는 16 이다.(10 + 1 + 2 + 3 이므로)
int reducedTwoParams =
IntStream.range(1, 4) // [1, 2, 3]
.reduce(10, Integer::sum); // method reference : 람다는 메소드 참조(method reference)를 이용해서 넘길 수 있다.
// 인자(파라미터)가 3개인 경우 (combiner)
<U> U reduce(U identity,
BiFunction<U, ? super T, U> accumulator,
BinaryOperator<U> combiner);
// 예시
Integer reducedParams = Stream.of(1, 2, 3)
.reduce(10, // identity
Integer::sum, // accumulator
(a, b) -> { // 마지막 인자인 combiner 는 실행되지 않는다. (다음 코드 참고)
System.out.println("combiner was called");
return a + b;
});// Combiner 는 병렬 처리 시 각자 다른 쓰레드에서 실행한 결과를 마지막에 합치는 단계이므로, 병렬 스트림에서만 동작한다.
Integer reducedParallel = Arrays.asList(1, 2, 3)
.parallelStream()
.reduce(10,
Integer::sum,
(a, b) -> {
System.out.println("combiner was called");
return a + b;
});-
reduce라는 메소드를 이용해서 결과를 만들어낸다.
-
reduce 메소드는 총 세 가지의 파라미터를 받을 수 있다.
- accumulator
- 각 요소를 처리하는 계산 로직
- 각 요소가 올 때마다 중간 결과를 생성하는 로직
- identity
- 계산을 위한 초기값
- 스트림이 비어서 계산할 내용이 없더라도 이 값은 리턴
- combiner
- 병렬(parallel) 스트림에서 나눠 계산한 결과를 하나로 합치는 동작하는 로직
- accumulator
-
BinaryOperator< T > : 같은 타입의 인자 두 개를 받아 같은 타입의 결과를 반환하는 함수형 인터페이스
-
예시
결과는 36이 나온다.
accumulator 는 총 세 번 동작한다. 초기값 10에 각 스트림 값을 더한 세 개의 값(10 + 1 = 11, 10 + 2 = 12, 10 + 3 = 13)을 계산
Combiner 는 identity 와 accumulator 를 가지고 여러 쓰레드에서 나눠 계산한 결과를 합치는 역할이다. 12 + 13 = 25, 25 + 11 = 36 두 번 호출 -
주의!
간단한 경우에는 부가적인 처리가 필요하기 때문에, 병렬 처리가 오히려 느릴 수도 있다.
6. 성능 향상
기존 코드
list.stream()
.map(el -> {
wasCalled();
return el.substring(0, 3);
})
.skip(2)
.collect(Collectors.toList());
System.out.println(counter); // 3첫 번째 요소인 "Eric", 다음 요소인 "Elena" : 먼저 문자열을 잘라내고, 다음 skip 메소드 때문에 스킵된다.
마지막 요소인 “Java” : 문자열을 잘라내어 “Jav” 가 된 후, 스킵되지 않고 결과에 포함된다.
→ 여기서 map 메소드는 총 3번 호출된다.
변경된 코드 : skip 메소드가 먼저 실행되도록
List<String> collect = list.stream()
.skip(2)
.map(el -> {
wasCalled();
return el.substring(0, 3);
})
.collect(Collectors.toList());
System.out.println(counter); // 1skip 을 먼저 하기 때문에, map 메소드는 한 번 밖에 호출되지 않는다.
→ 요소의 범위를 줄이는 작업을 먼저 실행하는 것이 불필요한 연산을 막을 수 있어 성능을 향상시킬 수 있다.
→ 이런 메소드로는 skip, filter, distinct 등...이 있습니다.
7. 재사용
기존 코드
Stream<String> stream =
Stream.of("Eric", "Elena", "Java")
.filter(name -> name.contains("a"));
// findFirst 메소드를 실행하면서 스트림이 닫히기 때문에, findAny 하는 순간 런타임 예외(runtime exception)이 발생
Optional<String> firstElement = stream.findFirst();
Optional<String> anyElement = stream.findAny(); // IllegalStateException: stream has already been operated upon or closed변경된 코드 : 데이터를 List 에 저장하고 필요할 때마다 스트림을 생성해 사용
List<String> names =
Stream.of("Eric", "Elena", "Java")
.filter(name -> name.contains("a"))
.collect(Collectors.toList());
Optional<String> firstElement = names.stream().findFirst();
Optional<String> anyElement = names.stream().findAny();-
종료 작업을 하지 않는 한 하나의 인스턴스로서 계속해서 사용이 가능
(단, 종료 작업을 하는 순간 스트림이 닫히기 때문에 재사용은 할 수 없다. 스트림은 저장된 데이터를 꺼내서 처리하는 용도이지 데이터를 저장하려는 목적으로 설계되지 않았기 때문) -
findFirst() : stream의 순서를 고려해, 가장 앞쪽에 있는 요소를 반환
findAny() : 멀티 쓰레드에서 가장 먼저 찾은 요소를 반환. stream의 뒤쪽에 있는 요소가 반환될 수도 있다.
8. 줄여쓰기 Simplified
(IntelliJ 를 이용함)
collection.stream().forEach()
→ collection.forEach()
collection.stream().toArray()
→ collection.toArray()
Arrays.asList().stream()
→ Arrays.stream() or Stream.of()
Collections.emptyList().stream()
→ Stream.empty()
stream.filter().findFirst().isPresent()
→ stream.anyMatch()
stream.collect(counting())
→ stream.count()
stream.collect(maxBy())
→ stream.max()
stream.collect(mapping())
→ stream.map().collect()
stream.collect(reducing())
→ stream.reduce()
stream.collect(summingInt())
→ stream.mapToInt().sum()
stream.map(x -> {...; return x;})
→ stream.peek(x -> ...)
!stream.anyMatch()
→ stream.noneMatch()
!stream.anyMatch(x -> !(...))
→ stream.allMatch()
stream.map().anyMatch(Boolean::booleanValue)
→ stream.anyMatch()
IntStream.range(expr1, expr2).mapToObj(x -> array[x])
→ Arrays.stream(array, expr1, expr2)
Collection.nCopies(count, ...)
→ Stream.generate().limit(count)
stream.sorted(comparator).findFirst()
→ Stream.min(comparator)참고: [Java] 자바 스트림(Stream) 사용법 & 예제
참고: [Java] Stream API에 대한 이해 - (1/5)
참고: [Java] Stream API의 활용 및 사용법 - 기초 (3/5)
참고: 스트림의 생성
참고: Java 스트림 Stream (1) 총정리
참고: Java 스트림 Stream (2) 고급
참고: 자바 - 스트림(Stream)
