프로세스 vs 쓰레드 는 개발자 면접에서 자주 나오는 질문 중의 하나!
1. 정의
1) Program vs Process
실행 안 하느냐 / 하느냐 의 차이!
(1) Program
-
컴퓨터에서 실행 할 수 있는 파일을 통칭
- 윈도우의
*.exe 파일이나 Mac의*.dmg 파일
- 윈도우의
-
단, 아직 파일을 실행하지 않은 상태이기 때문에 정적 프로그램(Static Program) 줄여서 프로그램(Program)이라고 부른 것
-
Program 을 개발하기 위해서는 Java 같은 코드를 작성해서 완성
- 즉, Program 은 코드 덩어리인 것.
(2) Process
-
Program 을 실행시켜, 정적인 프로그램이 동적(動的)으로 변하여 프로그램이 돌아가고 있는 상태
- 즉, 컴퓨터에서 실행 중인 프로그램을 의미
-
OS 로부터 시스템 자원을 할당받는 작업의 단위
(할당받는 시스템 자원? CPU 시간, Code, Data, Stack, Heap의 구조로 되어 있는 독립된 메모리 영역, Code, Data, Stack, Heap의 구조로 되어 있는 독립된 메모리 영역 등...) -
메모리에 올라와 실행되고 있는 프로그램의 인스턴스(독립적인 개체)
- 각 Process 는 독립된 메모리 공간을 사용하기 때문에, 병렬 실행이 가능 -> 이것이 멀티 프로세스
2) Program & Process

-
Program 은 OS 가 실행되기 위한 메모리 공간을 할당해 줘야 실행될 수 있다
-
Program 을 실행하는 순간 파일은 컴퓨터 메모리에 올라가게 되고
-
OS 로부터 실행에 필요한 시스템 자원(CPU, 메모리)을 할당받고
-
프로그램 코드를 실행시켜, 사용자가 서비스를 이용할 수 있게 되는 것이다.
-
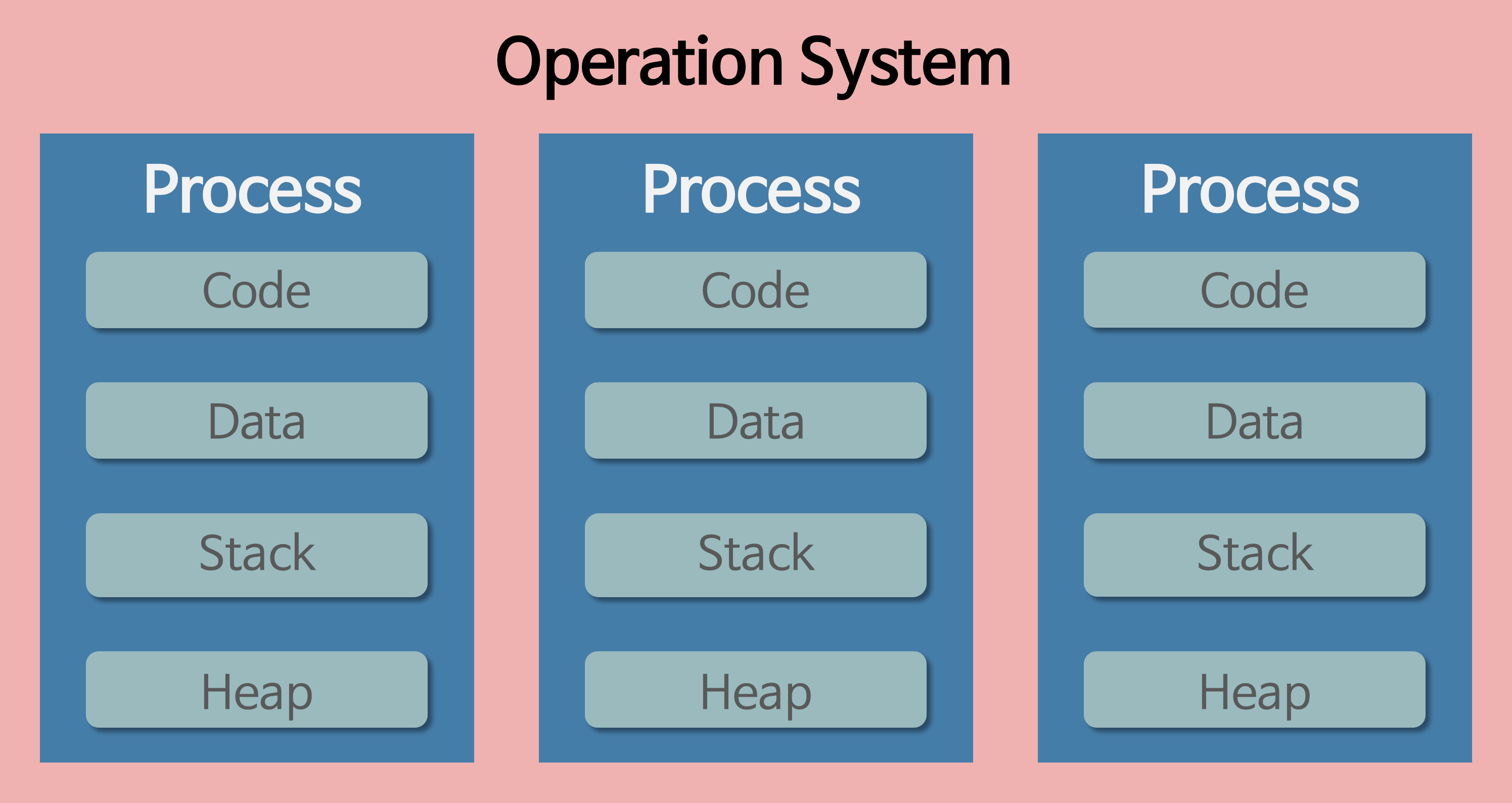
2. 자원 구조 (메모리 구조)
Program이 실행되어 Process가 만들어지면, 다음 4가지의 메모리 영역으로 구성되어 할당받게 된다.
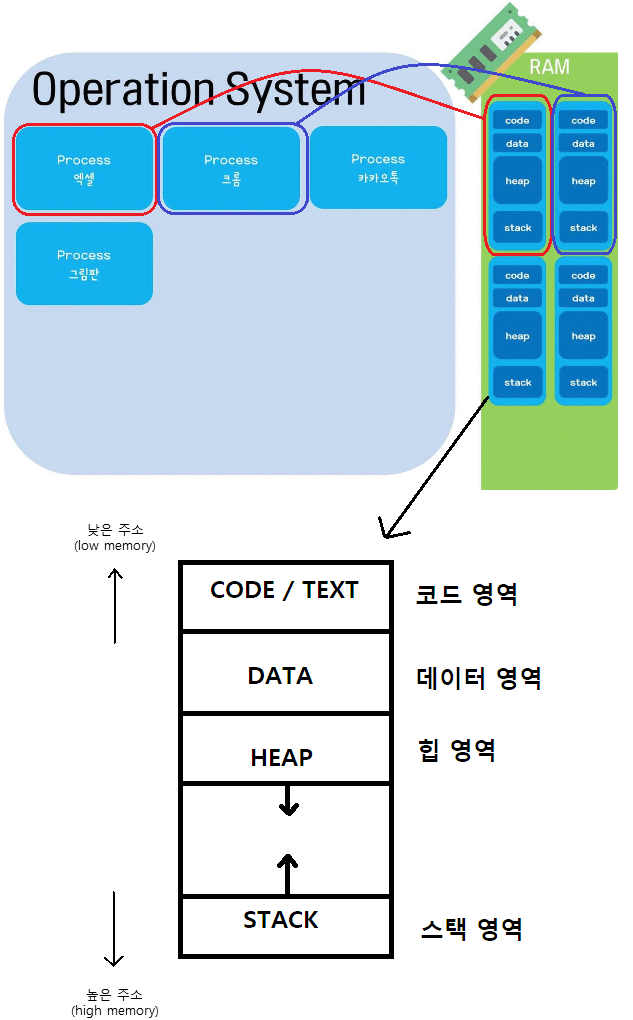
-
CODE 영역과DATA 영역은 선언할 때 그 크기가 결정되는 정적 영역
Stack 영역과Heap 영역은 Process 가 실행되는 동안 크기가 늘어났다 줄어들기도 하는 동적 영역 (이를 그림에선 화살표로 나타냄) -
프로그램이 여러 개 실행된다면, 메모리에 프로세스들이 담길 주소 공간이 생성되고
그 안에 Code, Data, Stack, Heap 공간이 만들어지게 된다.
1) CODE / TEXT
-
"클래스 영역", "메서드 영역" 이라고도 부름
-
프로그래머가 작성한 프로그램 함수들의 코드가 CPU가 해석 가능한 기계어 형태로 저장되어 있다.
- CPU는 코드영역에 저장된 명령어들을 하나씩 처리
-
코드에서 사용되는 class들을 Classloader(클래스 로더)로 읽어,
클래스 별로 정적 필드(static field)와 상수(constant), 메소드 코드, 생성자 코드(constructor) 등...으로 분류해서 저장 -
컴파일 타임에 결정된다.
-
JVM 이 시작할 때 생성됨
-
모든 Thread 가 공유하는 영역
-
중간에 코드를 바꿀 수 없게 Read-Only로 지정 돼 있다.
2) DATA
-
"Runtime Data Area" 라고도 부름
- 프로그램이 실행되면서 할당되고, 종료되면서 소멸한다.
-
코드가 실행되면서 사용하는 전역 변수나 각종 데이터들이 모여있다.
- 실행 중도에 전역 변수가 변경 될 수도 있으므로, 이 영역은 Read-Write 로 지정돼있다.
-
DATA 영역은 .data, .rodata, .bss 영역으로 세분화 된다.
-
.data
- 프로그램이 사용하는 데이터를 저장 (전역 변수 또는 static 변수 등...)
- 전역 변수와 정적 변수 값을 참조한 코드는 컴파일 하고 나면, Data 영역의 주소값을 가르키도록 바뀐다
-
.BSS
- 초기값 없는 전역 변수, static 변수가 저장
-
.rodata
- 상수 키워드 선언 된 변수(const 등...)나 문자열 상수가 저장
-
3) HEAP
-
"Heap" : 더미, 무더기, 쌓다
-
동적으로 할당되는 데이터들(생성자, 인스턴스 등...)을 위해 존재하는 공간
- 동적 메모리가 저장되는 영역
- 동적인 데이터 구조(연결 목록, 나무, 그래프 등...)를 만드는 데 반드시 필요
-
사용자에 의해 메모리 공간이 동적으로 할당되고 해제된다.
-
프로그램이 실행될 때 알 수 없는 가변적인 양의 데이터를 임시로 저장하기 위해, 프로그램 프로세스가 사용할 수 있도록 미리 예약된 메인 메모리 영역
- 만약 프로그램 실행 中 해당 Heap 영역이 없어지면, 메모리 부족으로 비정상 종료된다.
-
HEAP 영역에는 인스턴스(인스턴스변수)가 생성된다
- call stack(호출 스택) 에는 지역변수가 생성된다
-
객체와 배열이 생성된다.
- JVM 스택 영역의 변수 or 다른 객체의 필드에서 이들을 참조함
- 단, 참조하는 변수 or 필드가 없는 경우에는 자동 제거된다.
- JVM 은 의미 없는 객체를 쓰레기 취급해서 쓰레기 수집기(Garbage Collector)로 제거하므로, 객체 제거를 위해 따로 코드를 작성할 필요 X
-
런 타임에 크기가 결정됨
-
장점
- 메모리 크기 제한이 없다.
-
단점
- 상대적으로 느린 액세스(할당, 해제가 느리다)
- OS 마다 메모리 관리가 다르기 때문에 어렵다.
4) STACK
-
정적 메모리가 저장되는 영역
-
호출한 함수(지역 변수 등...)가 종료되면, 되돌아올 임시적인 자료를 저장하는 독립적인 공간
- Stack 은 함수의 호출과 함께 할당되며, 함수의 호출이 완료되면 소멸한다.
- 만약, Stack 영역을 초과하면 stack overflow 에러가 발생한다.
-
푸시(push) 동작으로 데이터를 저장하고, 팝(pop) 동작으로 데이터를 인출
- 후입 선출(LIFO, Last-In First-Out, 나중에 저장된 값을 먼저 사용)의 형식으로 입출력이 일어나는 자료구조
- LIFO 방식을 처리하므로, "푸시다운", "푸시다운 팝업 스택", "푸시다운 팝업 리스트" 등... 으로 불리기도 한다.
- 참고: 'Stack vs Queue' & 'LIFO(후입선출) vs FIFO(선입선출)'
-
초기화될 때가 Stack 영역에 변수가 생성되는 시점 (= 최초로 변수의 값이 저장될 때)
- 컴파일 타임에 크기가 결정됨
-
장점
- 매우 빠른 액세스 (할당, 해제가 빠르다)
-
단점
- 메모리 크기 제한
3. 자원 공유
1) 기본적으로
각 Process 는 메모리에 별도의 주소 공간에서 실행되기 때문에, 한 Process 는 다른 Process 의 변수나 자료구조에 접근할 수는 없다.
2) 자원 공유 방법?
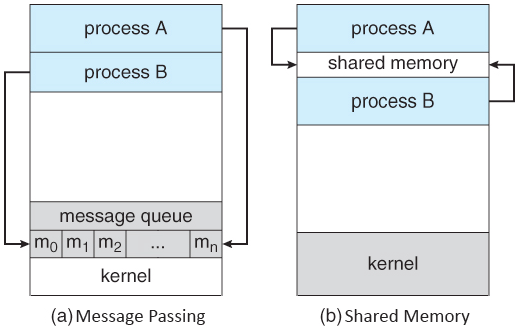
방법 1
IPC(Inter-Process Communication) 사용
방법 2
LPC(Local inter-Process Communication) 사용
방법 3
별도로 공유 메모리를 만들어서 정보를 주고받도록 설정
그러나!
Process 자원 공유는 단순히 CPU 레지스터 교체뿐만이 아니라 RAM과 CPU 사이의 캐시 메모리까지 초기화되기 때문에 자원 부담이 크다는 단점이 있다.따라서
다중 작업이 필요한 경우 Thread 를 이용하는 것이 훨씬 효율적이기 때문에,
현대 컴퓨터의 OS 에선 다중 프로세싱을 지원하고 있지만, '다중 스레딩'을 기본으로 하고 있다.
4. Process 스케줄링 (Scheduling)
1) 정의
-
프로세스 스케줄링(Process Scheduling) 이란?
- OS 에서 CPU 를 사용할 수 있는 Process 를 선택하고, CPU 를 할당하는 작업
-
Process 의 우선순위, 작업량 등... 을 고려하여 효율적으로 배치하여, 이를 통해 OS 는 CPU 를 효율적으로 사용하며 시스템 전반적인 성능을 향상시킨다.
- 따라서, 스케줄링은 멀티 태스킹 작업을 만들어내는 데에 있어서 핵심적인 부분
-
OS 의 특징과 시스템 요구사항에 따라, 스케줄링은 다양한 알고리즘 방식으로 동작된다.
(알고리즘 종류 : FCFS(First-Come, First-Served), SJF(Shortest-Job-First), Priority, RR(Round-Robin), Multilevel Queue 등...)
2) Process 상태
(1) 구성
Process 가 실행되는 동안 변경되는 고유 상태를 의미.
Process 가 생성되어 실행하기까지 Process 는 여러가지의 상태를 갖게 되고, 상태의 변화에 따라 Process 가 동작되는 것이다.
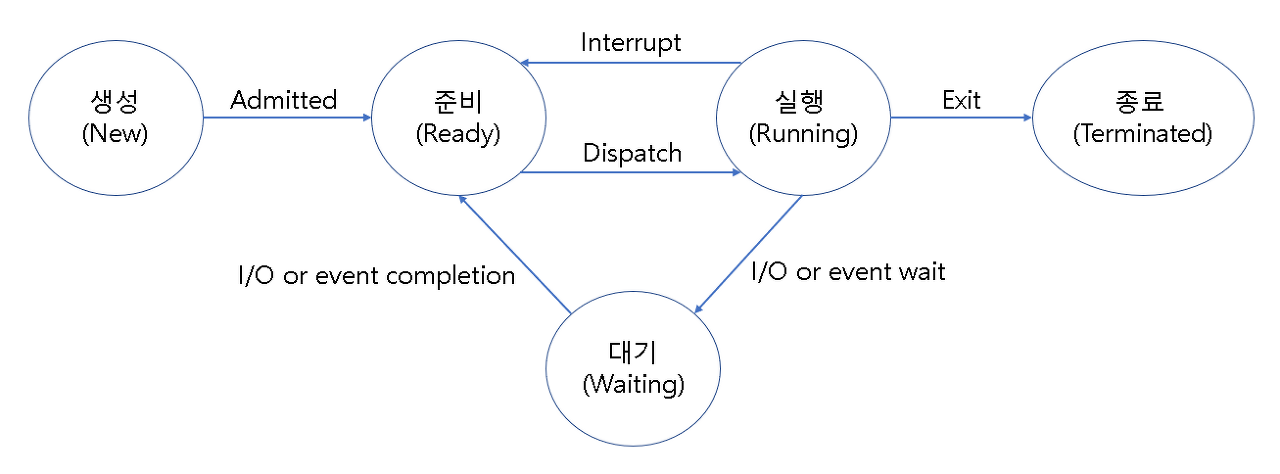
생성 (new)
- 프로세스가 생성되고 아직 준비가 되지 않은 상태
준비 (ready)
- 프로세스가 실행을 위해 기다리는 상태
- CPU를 할당받을 수 있는 상태이며, 언제든지 실행될 준비가 되어있다.
실행 (running)
- 프로세스가 CPU를 할당받아 실행되는 상태
대기 (waiting)
- 프로세스가 특정 이벤트(입출력 요청 등)가 발생하여 대기하는 상태
- CPU를 할당받지 못하며, 이벤트가 발생하여 다시 READY 상태로 전환될 때까지 대기
종료 (terminated)
- 프로세스가 실행을 완료하고 종료된 상태
- 더 이상 실행될 수 없으며, 메모리에서 제거되게 된다.
(2) Process 상태 전이
Process 가 실행되는 동안 상태가 OS 에 의해 변경되는 것.
OS 는 Process 의 상태를 감시하고, Process 상태를 기반으로 Process 스케쥴링을 통해 Process를 관리하고 제어한다.
-
Admitted (new → ready): 프로세스 생성을 승인 받음 -
Dispatch (ready→ running): 준비 상태에 있는 여러 프로세스들 중 하나가 스케줄러에 의해 실행됨 -
Interrupt (running → ready): Timeout, 예기치 않은 이벤트가 발생하여 현재 실행 중인 프로세스를 준비 상태로 전환하고, 해당 작업을 먼저 처리 -
I/O or event wait (running → wainting): 실행 중인 프로세스가 입출력이나 이벤트를 처리해야 하는 경우, 입출력이나 이벤트가 끝날 때까지 대기 상태로 전환 -
I/O or event completion (waiting → ready): 입출력이나 이벤트가 모두 끝난 프로세스를 다시 준비 상태로 만들어 스케줄러에 의해 선택될 수 있는 상태로 전환
예시
READY 상태에 있는 여러 프로세스 中
어떤 Process 를 RUNNING 상태로 바꿀지, TERMINATED 상태에 있는 Process 를 제거하고 READY 상태에 있는 다른 Process 를 선택할지
스케쥴링 알고리즘에 의해 동작된다.
3) Process Context Switching
(1) 정의
- CPU 가 한 Process 에서 다른 Process 로 전환할 때 발생하는 일련의 과정
- CPU 는 한 번에 하나의 Process 만 실행할 수 있으므로, 여러 개의 Process를 번갈아가며 실행하여 CPU 활용률을 높이기 위해 컨텍스트 스위칭이 필요한 것이다.
(Process & Thread 동시 실행 원리 中 동시성과 관련)
- CPU 는 한 번에 하나의 Process 만 실행할 수 있으므로, 여러 개의 Process를 번갈아가며 실행하여 CPU 활용률을 높이기 위해 컨텍스트 스위칭이 필요한 것이다.
(2) PCB (Process Control Block)
① 정의
-
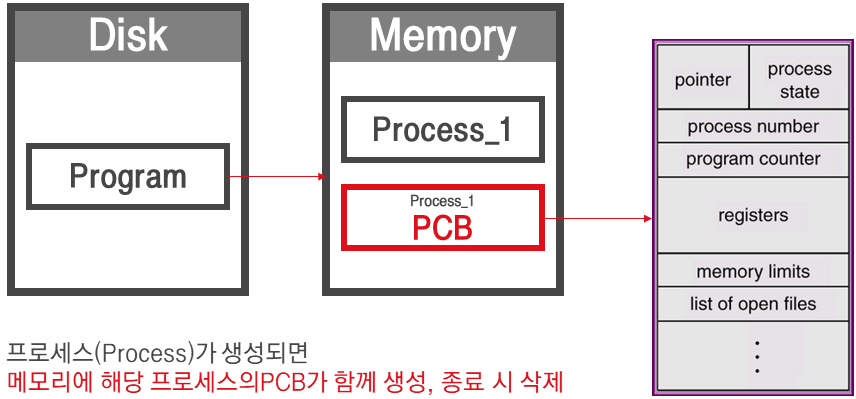
PCB(프로세스 제어 블록)는 OS 에서 Process 를 관리하기 위해 해당 Process 의 상태 정보를 담고 있는 자료구조
- Process Scheduling 을 위해 Process 에 관한 모든 정보 저장하는 임시 저장소
- Process 를 Context Switching 할 때, 기존 Process의 상태를 어딘가에 저장해 둬야 다음에 똑같은 작업을 이어서 할 수 있을 것이고, 새로 해야 할 작업의 상태 또한 알아야 어디서부터 다시 작업을 시작할지 결정할 수 있을 것이다.
- Process Scheduling 을 위해 Process 에 관한 모든 정보 저장하는 임시 저장소
-
OS 는 PCB 에 담긴 Process 고유 정보를 통해,
- Process 를 관리
- Process 의 실행 상태를 파악
- 우선순위를 조정
- 스케줄링을 수행
- 다른 Process 와의 동기화를 제어
② 구성
PCB 메모리
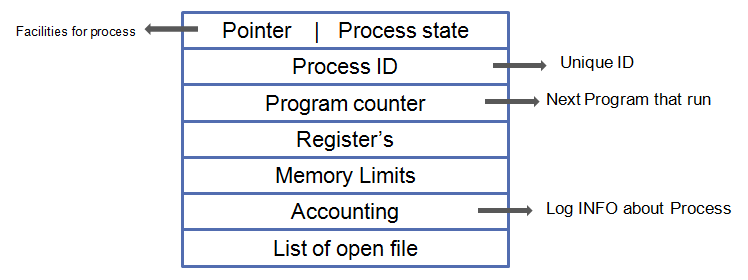
포인터 (Pointer) : 프로세스의 현재 위치를 저장하는 포인터 정보
프로세스 상태 (Process state) : 프로세스의 각 상태 - 생성(New), 준비(Ready), 실행(Running), 대기(Waiting), 종료(Terminated) 를 저장
프로세스 아이디 (Process ID, PID) : 프로세스 식별자를 지정하는 고유한 ID
프로그램 카운터 (Program counter) : 프로세스를 위해 실행될 다음 명령어의 주소를 포함하는 카운터를 저장
레지스터 (Register) : 누산기, 베이스, 레지스터 및 범용 레지스터를 포함하는 CPU 레지스터에 있는 정보
메모리 제한 (Memory Limits) : 운영 체제에서 사용하는 메모리 관리 시스템에 대한 정보
열린 파일 목록 (List of open file) : 프로세스를 위해 열린 파일 목록
(3) 과정
간단히 말하면
동작 중인 Process의 상태를 보관하고,
대기 중이던 다음 순서의 Process가 동작하면서 이전에 보관해둔 Process의 상태를 복구하는 작업이다.
(이런 Context Switching이 일어날 때, 다음 Process는 스케줄러가 결정하게 된다. 즉, Context Switching을 하는 주체는 스케줄러다)
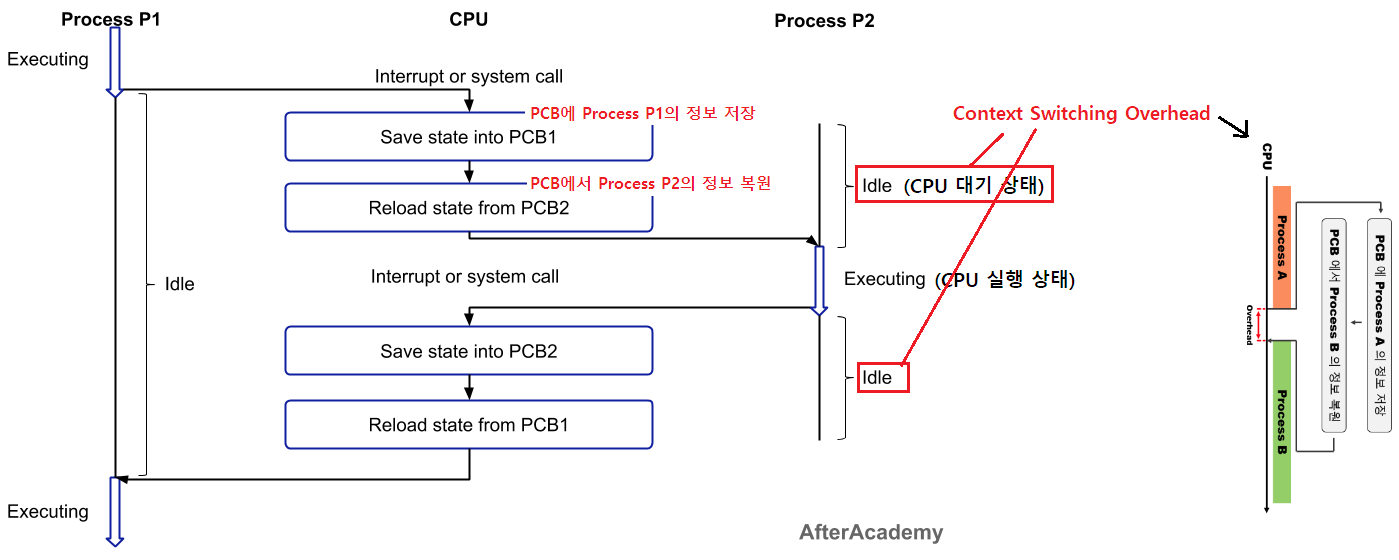
-
CPU는 Process P1을 실행 (Executing)
-
일정 시간이 지나 Interrupt 또는 system call이 발생 (CPU는 idle 상태)
-
현재 실행 중인 Process P1의 상태를 PCB1에 저장 (Save state into PCB1)
-
다음으로 실행할 Process P2를 선택 (CPU 스케줄링)
-
Process P2의 상태를 PCB2에서 불러온다. (Reload state from PCB2)
-
CPU는 Process P2를 실행 (Executing)
-
일정 시간이 지나 Interrupt 또는 system call이 발생 (CPU는 idle 상태)
-
현재 실행 중인 Process P2의 상태를 PCB2에 저장 (Save state into PCB2)
-
다시 Process P1을 실행할 차례가 된다. (CPU 스케줄링)
-
Process P1의 상태를 PCB1에서 불러온다. (Reload state from PCB1)
-
CPU는 Process P1을 중간 시점부터 실행 (Executing)
Context Switching Overhead
정의
Process P1이 Execute에서 idle이 될 때,
Process P2가바로 Execute가 되지 않고 idle을 상태에 조금 있다가 Execute가 된다.
이 간극이 컨텍스트 스위칭 오버헤드(overhead)발생 원인
- Context Switching 과정에서 PCB를 저장하고 복원하는데 비용이 발생
- Process 자체가 교체되는 것이니 CPU의 캐시 메모리에 저장된 데이터가 무효화가 된다
- CPU 스케줄링 알고리즘에 따라 Process를 선택하는 비용
