1. 정의
-
객체(Object)와 DB의 테이블을 Mapping 시켜, RDB 테이블을 객체지향적으로 사용하게 해주는 기술
-
RDB 테이블은 객체지향적 특성(상속, 다형성 등...)을 가지지 않는다.
그러나, 객체지향적 언어인 Java 는 ORM 을 사용하면 보다 객체지향적으로 RDB를 사용할 수 있게 된다.
2. 장단점
장점
-
직관적인 코드 (가독성) + 비지니스 로직 집중 가능 (생산성)
ORM 을 이용하면SQL문이 아닌클래스의 메서드를 통해 DB를 조작할 수 있어,
개발자가 객체 모델만 이용해서 프로그래밍을 하는 데 집중할 수 있게한다.결과적으로,
1) SQL 문을 사용하면서 같이 필요한 선언문, 할당, 종료 같은 부수적인 코드가 사라지거나 감소
2) 각종 객체에 대한 코드를 별도로 작성하여, 코드의 가독성 ↑
3) 오직 객체지향적 접근만 고려하면 되므로, 생산성 ↑ (객체지향적 접근과 SQL의 절차적/순차적 접근이 혼재되어있던 기존 방식과 달리) -
재사용, 유지보수, 리팩토링 용이성
1) ORM 은 기존 객체와 독립적으로 작성되어있고, 객체로 작성되었기 때문에 재활용 가능
2) 매핑하는 정보가 명확하기 때문에, ERD를 보는 의존도 ↓ -
DBMS(DataBase Management System) 종속성 하락
1) 객체 간의 관계를 바탕으로, SQL문 자동 생성과 객체의 자료형 타입까지 사용할 수 있기 때문에, RDBMS의 데이터 구조와 객체지향 모델 사이의 간격을 좁힐 수 있다.
2) 객체에만 집중할 수 있기 때문에, DBMS 를 교체하는 큰 작업에도 리스크 小 드는 시간 小
(예시 : 자바에서 가공할 경우 equals, hashCode의 오버라이드 같은 자바의 기능을 이용 가능, 간결하고 빠르게 가공 가능)
단점
-
프로젝트가 복잡해질수록, ORM 사용의 난이도↑
-
미흡한 설계로 인해 잘못 구현될 경우, 속도↓ 일관성X
-
(일부의) 자주 사용되는 대형 SQL문은 속도를 위해 별도의 튜닝이 필요하므로, 결국 SQL문을 써야할 수도 있다.
-
이미 프로시저가 많은 시스템에서는 다시 객체로 바꿔야하며, 그 과정에서 생산성 저하나 리스크가 많이 발생할 수 있다.
3. 객체-관계 간의 불일치
객체 지향 프로그래밍은 클래스를 사용하고, 관계형 데이터베이스는 테이블을 사용한다.
따라서, 다음과 같은 경우에 객체 모델과 관계형 모델 간의 불일치가 생기게 된다.
1) 세분성(Granularity)
-
경우에 따라서, DB 에 있는 테이블 수보다 더 많은 클래스를 가진 모델이 생길 수 있다.
-
예시
사용자의 세부 사항에 대해 데이터를 저장할 경우,객체지향 프로그래밍 : 코드 재사용과 유지보수를 위해, Person과 Address라는 2개의 클래스로 나눠서 관리
DB : person 테이블 1개에 사용자의 세부사항을 모두 저장→ Object는 2개, Table는 1개가 되어 개수가 달라지는 것
2) 상속성(Inheritance)
RDBMS 는 객체지향 프로그래밍 언어의 특징인 상속 개념이 없다.
3) 일치(Identity)
-
RDBMS : 기본키(PK, primary key)를 이용하여, 동일성(sameness)의 개념을 정의
→ 기본키(PK, primary key)가 같으면 서로 동일한 record로 정의 -
Java : 객체 식별(a==b), 객체 동일성(a.equals(b))을 모두를 정의
→ 주소값이 같거나 내용이 같은 경우를 구분해서 정의
4) 연관성(Associations)
-
객체지향 언어 : 방향성이 있는 객체의 참조(reference)를 사용하여 연관성을 나타낸다.
public class Employee { private int id; private String first_name; … private Department department; // Employee -> Department … }Java 에서의 객체 참조는 아래처럼 방향성이 있기 때문에(Employee -> Department),
양방향 관계가 필요한 경우 연관을 두 번 정의해야 한다.
→ 즉, 서로 Reference를 가지고 있어야 한다. -
RDBMS : 방향성이 없는 외래키(foreign key)를 이용해서 연관성을 나타낸다.
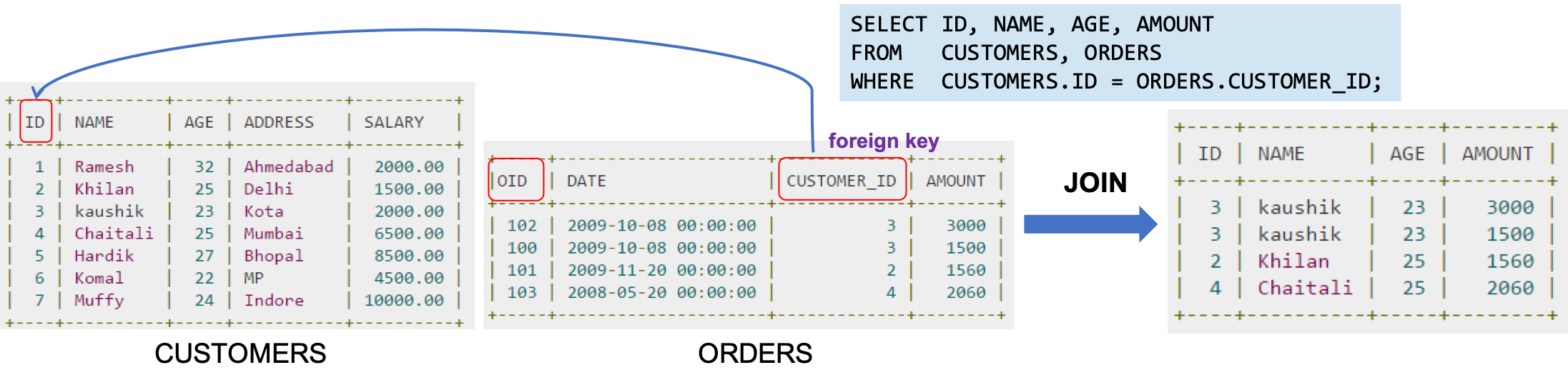
INSERT INTO EMPLOYEE(id, first_name, … ,department_id) // FK VALUES …→ foreign key 와 Join 으로 자연스럽게 방향성이 없는 연결이 이루어진다.
5) 탐색(Navigation)
Java 와 RDBMS 에서 객체를 접근하는 방법이 근본적으로 다르다.
-
Java : 그래프형태로 하나의 연결에서 다른 연결로 이동하며 탐색
user.getBillingDetails().getAccountNumber() -
RDBMS : 일반적으로 SQL문을 최소화하고 JOIN 을 통해 여러 엔티티를 로드하고 원하는 대상 엔티티를 선택하는 방식으로 탐색
예시
쿼리 수를 최소화하고,
JOIN을 통해 여러 엔티티를 로드하고,
원하는 대상 엔티티를 선택(select)하는 방식으로 탐색한다.
4. Object Mapping vs ORM
1) Object Mapping 기술
MyBatis
-
JPA가 등장하기 이전에 주로 사용되던 기술
-
Java 클래스 코드와 직접 작성한 SQL 코드를 Mapping 시켜주어야 한다.
2) ORM 기술
JPA (Java Persistent API)
Hiberante (JPA 의 구현체)
-
객체가 DB 에 연결되기 때문에, SQL 을 직접 작성하지 않고 표준 인터페이스 기반으로 처리
-
Java 에서 사용하는 대표적인 ORM
5. 사용법
1) JDBC
ORM 을 사용하지 않은 코드 예시
// 사용자 데이터 추가
public void insertUser(User user){
String query = " INSERT INTO user (email, name, pw) VALUES (?, ?, ?)";
// 각각의 쿼리 파라미터에 사용자 데이터를 직접 Set해서 DB에 저장
PreparedStatement preparedStmt = conn.prepareStatement(query);
preparedStmt.setString (1, user.getEmail());
preparedStmt.setString (2, user.getName());
preparedStmt.setString (3, user.getPW());
// execute the preparedstatement
preparedStmt.execute();
}- Java Object 와 RDB가 Mapping 되지 않기 때문에, 각각의 쿼리 파라미터에 사용자 데이터를 직접 Set 해서 DB 에 저장
- 가독성이 떨어지며 작업이 불편하다.
2) MyBatis
Database 처리를 위한 Mapper 인터페이스
@Mapper
@Repository
public interface UserMapper {
insertUser(User user); // Repository에서 메소드의 이름
}Mapper.xml 파일
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="mang.blog.user.userMapper">
<insert id="insertUser" parameterType = "user">
INSERT USER(
email, name, pw,
)VALUES(
#{email}, #{name}, #{pw}
)
</insert>
</mapper>-
mybatis 는 자주 사용되는 라이브러리들을 편리하게 이용할 수 있도록 돕는 spring-data-mybatis 프로젝트가 존재한다.
-
Repository에서 메소드의 이름은 queryId에 매핑되며, xml 파일에서 해당 쿼리의 id를 기준으로 쿼리를 실행
3) JPA
- Spring 은 JPA 를 위해 spring-data-jpa 프로젝트를 제공
Entity
@Entity
@Table(name = "user")
@Getter
@Builder
@NoArgsConstructor(force = true)
@AllArgsConstructor
public class User extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String email;
private String name;
private String pw;
}- Java 클래스에 매핑 정보를 넣어줘야 한다
- Java 객체와 테이블을 매핑시키는 ORM 기술이기 때문
Repository
public interface UserRepository extends JpaRepository <User, Long> {
}- DB에 데이터를 저장하기 위한 Repository 구현
Service
@Service
@RequiredArgsConstructor
@Transactional(readonly = true)
public class UserService {
private final UserRepository userRepository;
@Transactional
public User findUserAndUpdateName(Long id) {
User user = userRepository.findById(id);
user.setName("변경된 이름");
}
}-
저장 : UserRepository 의 save 호출
-
조회 : UserRepositor y의 findById 호출
6. JPA 를 사용하자
MyBatis 보다는 JPA 의 사용을 권장하는 이유에 대해 알아보자.
1) 엔티티에 맞는 테이블 생성 + DB 생성을 편리
-
JPA 는 설정에 따라 매핑된 객체를 바탕으로 테이블을 자동 생성해준다.
-
직접 모든 DDL을 작성하는 것보다는 편리하다.
2) 객체 지향 중심의 개발
- 객체를 이용하면 테이블에 매핑되는 클래스를 더욱 객체 지향적으로 개발할 수 있다.
3) 테스트 작성이 용이
@JpaTestConfig
class UserRepositoryTest {
@Autowired
private UserRepository userRepository;
@Test
public void selectUserByEmail() {
// given
final String email = "test@mangkyu.com"
// when
final User result userRepository.findByEmail(email);
// then
assertThat(result.getEmail()).isEqualTo(email);
}
}-
JPA 는 테이블을 자동 생성해주므로, 테스트를 작성하기에 매우 좋다.
- 단, Repository 는 DB 와 데이터를 주고 받는 계층이기 때문에,
단위 테스트로 작성하기보다DB 와 연결하여 실제 쿼리를 날리는 '통합 테스트'로 진행하는 것이 좋다.
- 단, Repository 는 DB 와 데이터를 주고 받는 계층이기 때문에,
-
Spring 은 Repository 테스트를 위한 @DataJpaTest 를 제공
- @DataJpaTest 를 이용하면, 기본적으로 인메모리 데이터베이스(h2)로 연결이 된다.
4) 기본적인 CRUD 자동화
- JPA 는 테이블과 객체를 매핑시키는 기술이므로, 기본적인 CRUD 가 제공된다.
(간단한 CRUD 쿼리들도 모두 작성해주어야 하는 MyBatis 에 비해 생산성이 높다)
참고: [DB] ORM (Object Relational Mapping) 사용 이유, 장단점
참고: ORM(Object Relational Mapping)이 뭘까?
참고: [DB] ORM이란
참고: [Java] ORM이란? MyBatis와 JPA의 차이, MyBatis보다 JPA를 사용해야 하는 이유
