ORM 사용으로 쿼리가 복잡해질 경우의 해결법에 대한 것은 개발자 면접에서 자주 나오는 질문 중의 하나!
ORM 기술 중에 JPA 가 있음.
1. Native Query
JPA 는 SQL 이 지원하는 대부분의 문법과 SQL 함수들을 지원한다.
그러나 정해진 문법을 사용하다보면 쿼리가 복잡해질 수도 있다.
이 경우에, Native Query 를 사용할 수가 있다.
1) 정의
JPA 에서 직접 SQL 을 작성한 쿼리
2) 예시
데이터 마이그레이션(어떤 DB 에 있던 데이터 모두를 다른 DB 로 옮기는 것)
-
어떤 DB 에서 모든 데이터를 삭제할 경우, delete 쿼리로 한번에 삭제가 가능하다.
그러나, update 의 경우, 데이터를 일일이 조회한 후 save 를 거쳐야 한다. -
이때, Native Query 를 사용해서, 한번에 update 가 되도록 할 수 있다.
@Transactional @Query(value = "update book set category = 'IT문서'", nativeQuery = true) int updateCategories();
2. Stored Procedure (저장 프로시저) = 캐싱
Stored Procedure 는
첫 번째 실행으로 메모리에 실행 결과를 등록하고 이후 실행부터는 메모리에서 결과를 가져오기 때문에, 성능면에서 유리하고
여러 개의 쿼리를 한번에 실행 할 수 있기 때문에, 쿼리를 복잡하게 만들지 않을 수 있다.
1) 정의
SQL 명령문들을 하나의 함수로 묶어서 일괄적으로 실행시키기 위한 쿼리의 집합
2) 동작 과정
일반 쿼리문
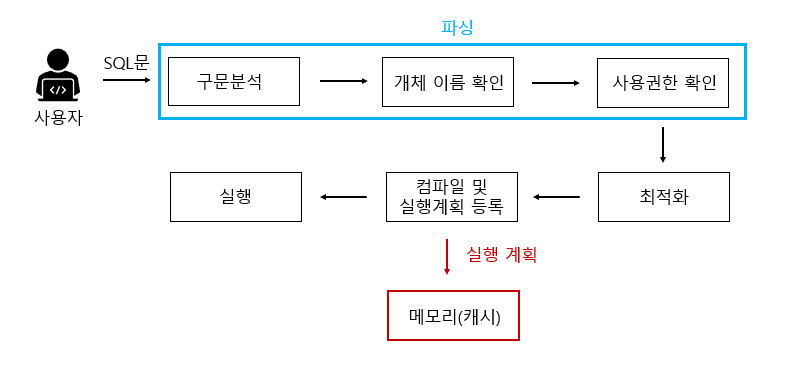
파싱→최적화→컴파일 및 실행계획 등록(실행계획 결과를 메모리(캐시)에 등록)→실행하는 과정을 거친다.
Stored Procedure
- 저장 프로시저 정의 단계
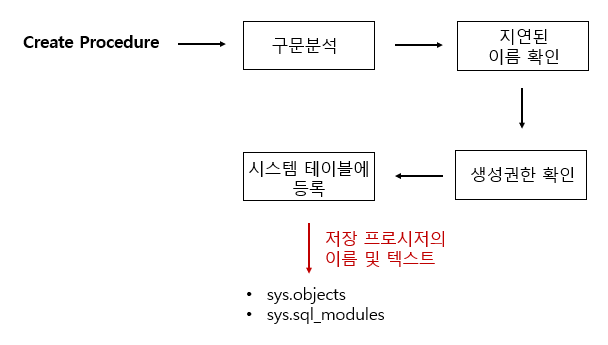
- 프로시저 실행 당시, 테이블의 존재 여부를 확인해서 저장 프로시저의 이름 및 코드를 시스템 테이블에 등록
-
처음으로 저장 프로시저를 실행
('일반 쿼리문'과 달리, 구문분석 단계가 생략됨)
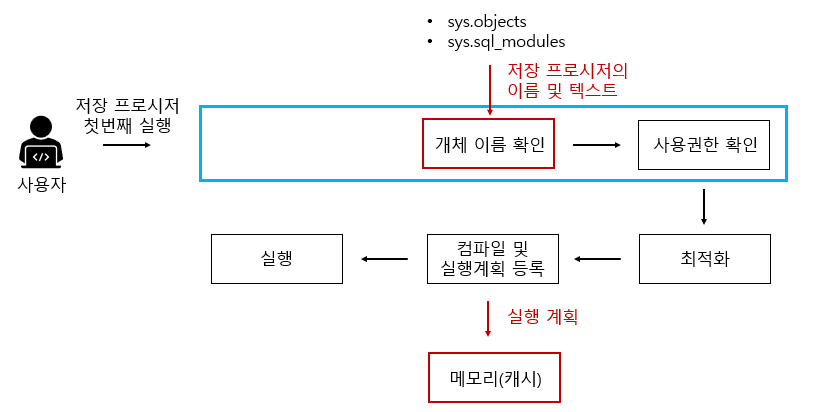
-
이후의 저장 프로시저 실행
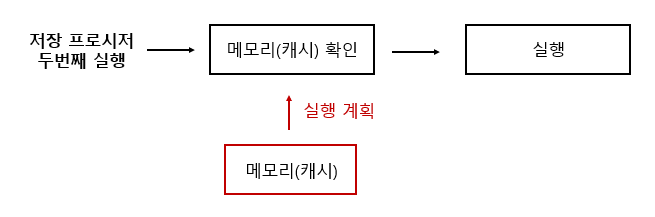
- 두 번째 실행부터는 메모리(캐시)에 있는 것을 그대로 가져와서 재사용
3. 쿼리 분리
-
하나의 쿼리는 하나의 목적만을 가지게 하자.
학생 A의 학번을 구하는 쿼리 & 학생 A가 수강중인 강의 목록을 구하는 쿼리는 서로 분리하는 게 좋다.
물론 한 번에 하나의 쿼리로 모두 구할 수는 있지만, 쿼리가 복잡해질 수 있다. -
서브쿼리를 사용하자.
괄호() 로 쿼리를 분리해서, 복잡한 쿼리를 간단하게 만들어 줄 수 있다.
4. 쿼리 최적화
ORM 이 생성한 쿼리가 비효율적인 경우, 인덱스를 추가하자.
테이블의 데이터는 순서 없이 쌓이므로, 특정 데이터를 찾기 위해서는 모든 데이터에 접근을 해야 하지만
인덱스가 있을 경우 search-key가 정렬되어 있기 때문에, 특정 데이터 검색 시 속도가 빠르다.
(이 외에도 조인 방식 변경, 쿼리 실행 계획 최적화 등... 이 있음)
5. QueryDSL
QueryDSL 라이브러리를 사용하면, 복잡한 쿼리를 직관적으로 작성할 수 있다.
6. 프로파일링과 모니터링
-
MySQL 에서 쿼리 프로파일링을 제공하여, 쿼리가 처리되는 동안 각 단계별 작업에 시간이 얼마나 걸렸는지 확인 할 수 있다.
mysql> set profiling=1;위의 코드로 프로파일링을 수행할 수 있다.
-
MySQL Workbench (모니터링 도구)를 이용하여, 모니터링을 할 수 있다.
참고: Native Query
참고: 저장 프로시저 (Stored Procedure)
참고: 복잡한 쿼리를 피하는 방법
참고: SQL 서브쿼리 사용 방법 (테이블 연결)
참고: MySQL workbench로 mysql 실시간 모니터링하기
