Group by
- 동일한 범주를 갖는 데이터를 하나로 묶어서, 범주별 통계를 내주는 것
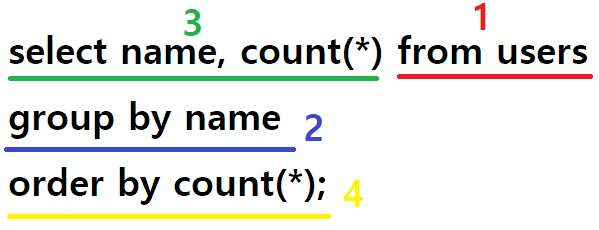
1. 실행 순서
select name, count(*) from users
group by name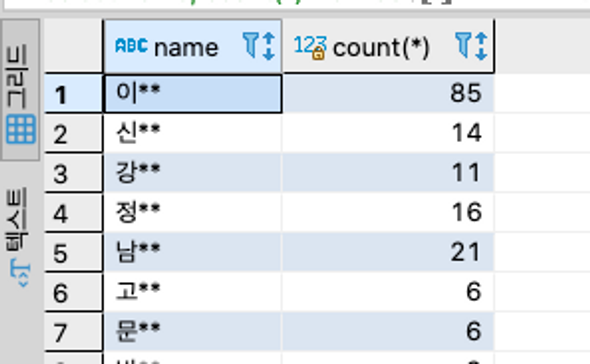
성씨별 회원수를 구하는 다음과 같은 쿼리문이 있다면
-
from users: users 테이블 데이터 전체를 가져온다. -
group by name: users 테이블 데이터에서 같은 name을 갖는 데이터를 합친다.- 이** 데이터끼리 합치기
- 김** 데이터 끼리 합치기
- ...
-
select name, count(*): name에 따라 합쳐진 데이터가 각각 몇 개가 합쳐진 것인지 세어줍니다.- 합쳐진 이** 데이터 -> 2개
- 합쳐진 김** 데이터 -> 5개
- ...
2. 사용법
예시 1 : 동일한 범주의 개수(count) 구하기
# 문법
select 범주별로 세어주고 싶은 필드명, count(*) from 테이블명
group by 범주별로 세어주고 싶은 필드명
# 예시
select week, count(*) from checkins
group by weekcount(*): 동일한 범주의 개수- week : 범주별로 세어주고 싶은 필드명
예시 2 : 동일한 범주에서의 최솟값(min) 구하기
# 문법
select 범주가 담긴 필드명, min(최솟값을 알고 싶은 필드명) from 테이블명
group by 범주가 담긴 필드명
# 예시
select week, min(likes) from checkins
group by week예시 3 : 동일한 범주에서의 최댓값(max) 구하기
# 문법
select 범주가 담긴 필드명, max(최댓값을 알고 싶은 필드명) from 테이블명
group by 범주가 담긴 필드명
# 예시
select week, max(likes) from checkins
group by week예시 4 : 동일한 범주의 평균(avg) 구하기
# 문법
select 범주가 담긴 필드명, avg(평균값을 알고 싶은 필드명) from 테이블명
group by 범주가 담긴 필드명
# 예시
select week, avg(likes) from checkins
group by week
# 예시 : 소수점을 없애고 싶다면
select week, round(avg(likes),1) from checkins
group by week- 소수점을 없애고 싶다면 round()
- round(avg(likes),0) : 반올림
- round(avg(likes),1) : 첫째자리까지
- ...
예시 5 : 동일한 범주의 합계(sum) 구하기
# 문법
select 범주가 담긴 필드명, sum(합계를 알고 싶은 필드명) from 테이블명
group by 범주가 담긴 필드명;
# 예시
select week, sum(likes) from checkins
group by week예시 6 : group by, count + where - 웹개발 종합반의 결제수단별 주문건수
select payment_method, count(*) from orders
where course_title = "웹개발 종합반"
group by payment_method예시 7 : group by, count, like - Gmail 을 사용하는 성씨별 회원수
select name, count(*) from users
where email like '%gmail.com'
group by name;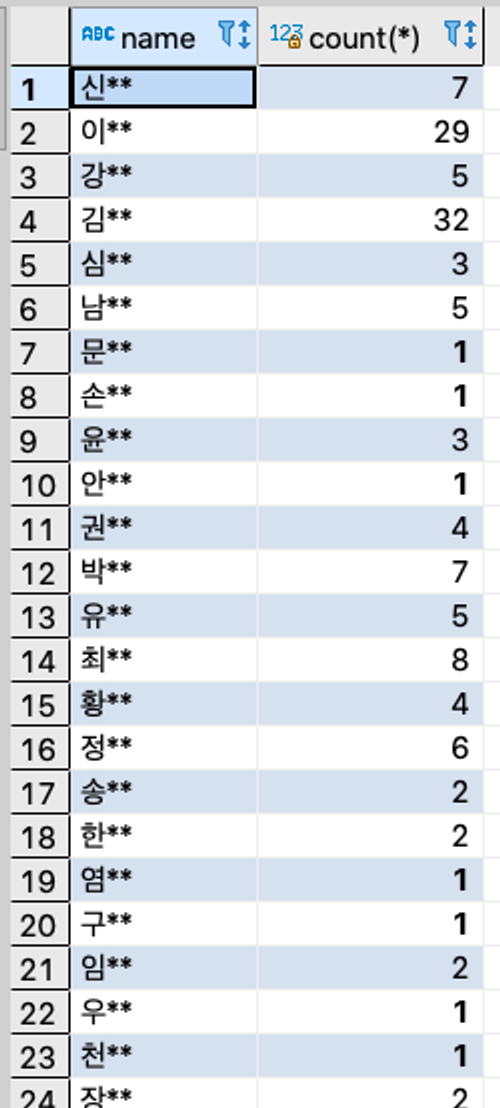
예시 8 : group by, count, where, and - 네이버 이메일을 사용하여 앱개발 종합반을 신청한 주문의 결제수단별 주문건수
select payment_method, count(*) from orders
where email like '%naver.com' and course_title = '앱개발 종합반'
group by payment_method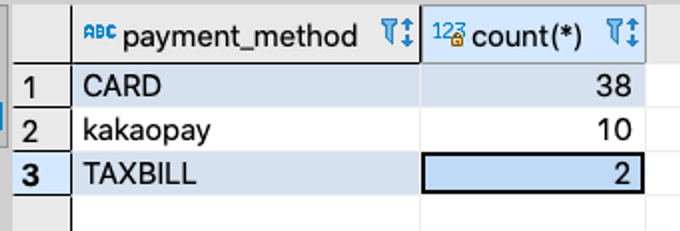
Order by
1. 실행 순서
Group by 에서의 실행순서와 동일하고, 마지막에 정렬이 이뤄진다.
2. 사용법
예시 1 : 오름차순으로 정렬
# 원본
select name, count(*) from users
group by name
# 수정본
select name, count(*) from users
group by name
order by count(*)
# 문법
select * from 테이블명
order by 정렬의 기준이 될 필드명- 갯수 (count(*) 값)을 기준으로 정렬
예시 2 : 내림차순으로 정렬
# 원본
select name, count(*) from users
group by name;
# 수정본
select name, count(*) from users
group by name
order by count(*) desc
# 문법
select * from 테이블명
order by 정렬의 기준이 될 필드명 desc- 즉, order by 에
- desc 가 없으면 -> 오름차순
- desc 가 있으면 -> 내림차순
예시 3 : 정렬의 오해
select name, count(*) from users
order by count(*) desc- group by name 가 반드시 와야하는 것은 아니다.
예시 4 : group by 中 count + Where + order by - 웹개발 종합반의 결제수단별 주문건수
select payment_method, count(*) from orders
where course_title = "웹개발 종합반"
group by payment_method
order by count(*) desc예시 5 : 문자열(알파벳) 정렬
select * from users
order by email;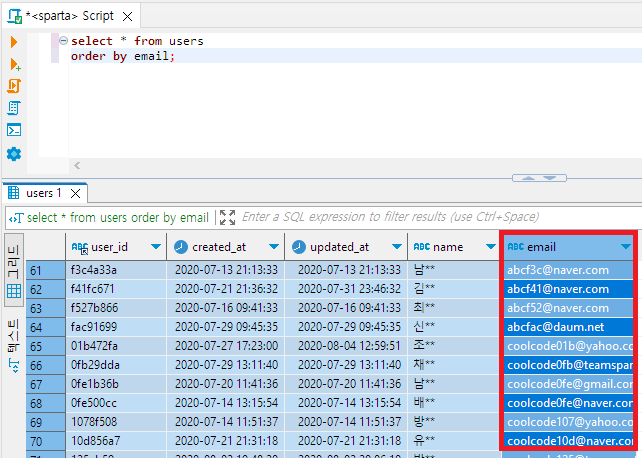
예시 6 : 문자열(한글) 정렬
select * from users
order by name;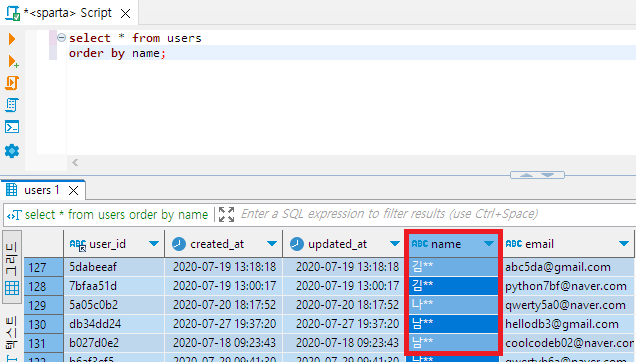
예시 7 : 시간 정렬
select * from users
order by created_at desc;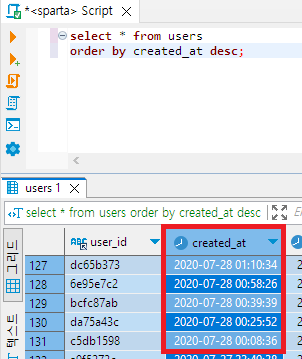
- 최근 데이터부터 볼 때 유용하다.
예시 8 : 필드별로 정렬
SELECT 필드이름1, 필드이름2, ...
FROM 테이블이름
ORDER BY 필드이름1 ASC|DESC, 필드이름2 ASC|DESC, ...;- 여러 개의 필드를 기준으로 정렬 가능
- 각각의 필드에 옵션을 별개로 적용 가능

개발자로 거듭나기!