1. 정의
1) 더미 데이터
-
유용한 데이터가 포함되지는 않지만, 공간을 예비해두어 실제 데이터가 명목상 존재하는 것처럼 다루는 정보
-
언제 사용하나?
여러 건의 물리적 데이터를 이용하여 테스트 할 때 사용
(paging test 에서 게시글을 많이 만들어두기 등...)
2) 프로시저
- RDBMS 에서 다수의 쿼리를 하나의 함수처럼 실행하기 위한 쿼리의 집합
2. 더미 데이터 생성 방법
1) MySQL 프로시저를 이용한 더미데이터 삽입
-
세팅하기
1) application.properties# H2 세팅 spring.h2.console.enabled=true spring.h2.console.path=/h2-console spring.datasource.driverClassName=org.h2.Driver spring.datasource.username=sa spring.datasource.password= # 더미데이터 테이블 생성 : 서버 기동 시 실행할 schema.sql 파일의 경로 spring.datasource.schema: classpath:h2/schema.sql # 더미데이터 생성 : 서버 기동 시 실행할 data.sql 파일의 경로 spring.datasource.data: classpath:h2/data.sql # 더미 데이터 생성 설정 always : 서버 재기동 마다 schema, data 새로 생성 spring.datasource.initialization-mode=alwaysSpring boot H2 DB 를 사용할 경우이다.
application.properties 대신, application.yml 로 추가해 줄 수도 있다.
spring: datasource: initialization-mode: always platform: h22) 테이블 생성
schema.sqlDROP TABLE IF EXISTS Products; # PRODUCTS 테이블 CREATE TABLE Products ( prod_id IDENTITY PRIMARY KEY, prod_name VARCHAR(255) NOT NULL, prod_price INT NOT NULL ); -- 회원 DROP TABLE IF EXISTS MB_MBR; # MB_MBR 테이블 -- 회원 CREATE TABLE "MB_MBR" ( "MBR_ID" IDENTITY PRIMARY KEY, -- 회원식별번호 "MBR_NM" VARCHAR(50) NOT NULL, -- 회원이름 "MBR_CP_NO" VARCHAR(30) NOT NULL, -- 회원연락처 "REG_DT" DATETIME NOT NULL, -- 등록일시 "MOD_DT" DATETIME NULL -- 수정일시 );data.sql
INSERT INTO Products (prod_name, prod_price) values ('롤휴지', 2700); INSERT INTO Products (prod_name, prod_price) values ('슬리퍼', 3500); INSERT INTO Products (prod_name, prod_price) values ('양말', 3000); INSERT INTO Products (prod_name, prod_price) values ('우산', 8500); INSERT INTO MB_MBR (MBR_NM, MBR_CP_NO, REG_DT) VALUES ('이서진', '010-6666-6555', now()) , ('이수린', '010-3232-3444', now()) , ('박한민', '010-3232-3444', now()) , ('박진환', '010-3232-3444', now()) , ('강서준', '010-3232-3444', now()) , ('이세진', '010-3232-3444', now());application.properties 에서 설정해준대로, 각 sql 파일 경로에 따른 테이블을 만든다.
-
테이블 구조 확인해보기
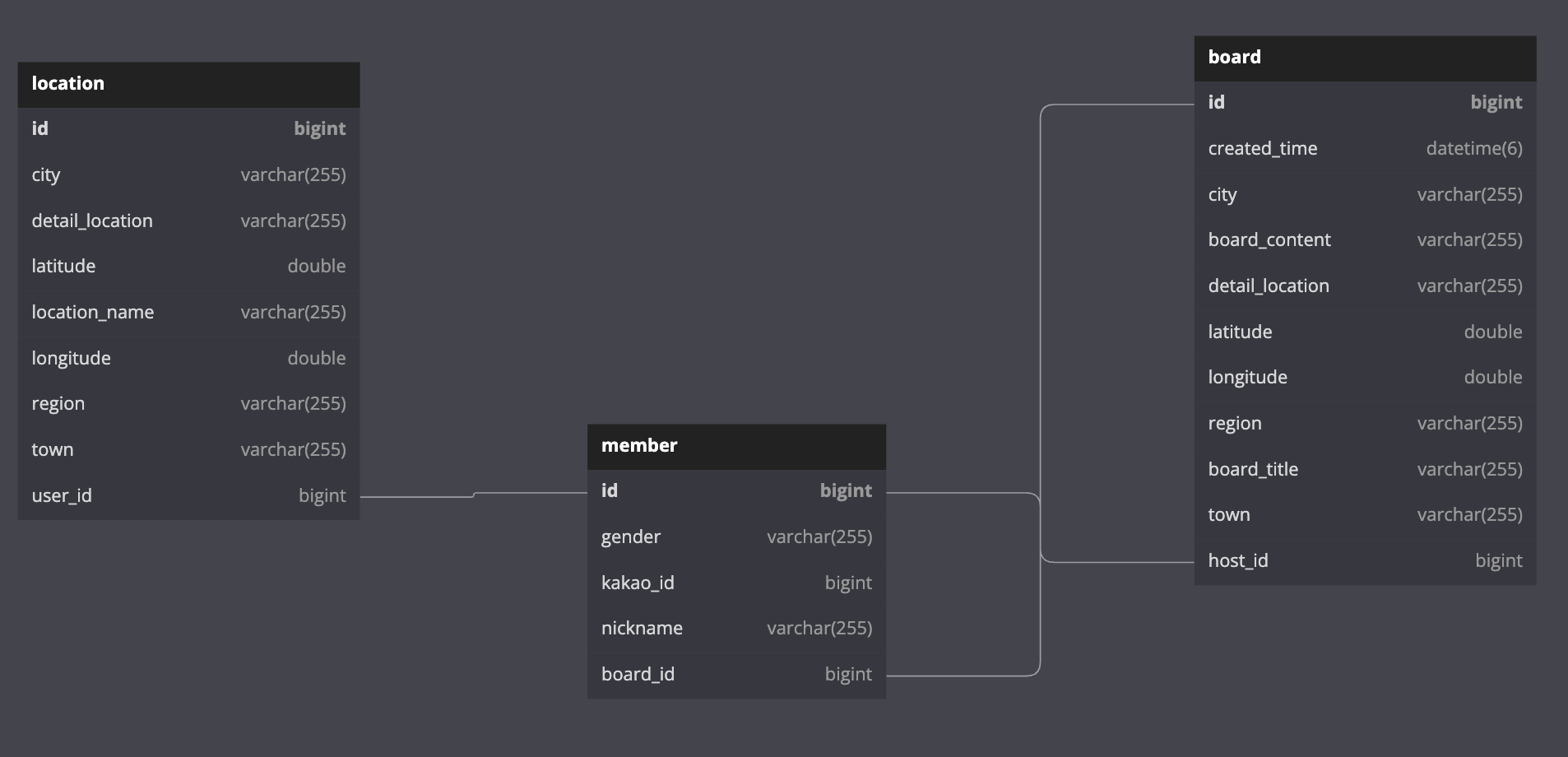

-
프로시저를 이용해서 현재 테이블에 더미 데이터를 넣고자 하는데,
먼저 테이블 구조가 어떤지, 어떤 더미데이터가 필요한지 살펴봐야한다. -
(예시) member 와 board 는 1 : N 관계를 이루고 있다.
→ 이 2개의 테이블은 대용량 데이터일 것이다.
-
-
프로시저 생성
1) 프로시저 목록 확인show procedure status;
해당 명령어를 입력하면, 아래의 여러 프로시저들이 나온다.
2) 프로시저 생성(정의)
더미데이터가 多 필요한 경우(페이징 테스트 같이), 프로시저를 생성해서 더미데이터 삽입 가능// 문법 예시 DELIMITER $$ CREATE PROCEDURE <생성할 프로시저 이름>( IN <파라미터명> <타입>, IN <파라미터명> <타입>, OUT <파라미터명> <반환 타입> ) BEGIN DECLARE <변수명> <타입> <기타 옵션>; # 중략... 다른 쿼리 명령문 END $$ DELIMITER ;DELIMITER $$
- 프로시저 내부에 존재하는 쿼리 명령문은 " ; "로 끝난다.
→ 이로 인해서 쿼리가 실행되버리면 안되기 때문에, 해당 DELIMETER 속에 존재하는 내용은 실행되지 않도록 막기 위한 명령어
→ 즉, 가장 처음과 끝에 사용해줌
- 프로시저나 트리거에서 사용BEGIN&END
BEGIN 과 END 사이에는 수행할 쿼리를 나열IN
프로시저를 호출 시 파라미터가 필요할 때 사용OUT
프로시저의 결과값이 필요한 경우 사용DECLARE
변수의 선언이 필요한 경우에 사용그 외의 프로시저를 생성하는 명령어는 찾아서 사용하기!
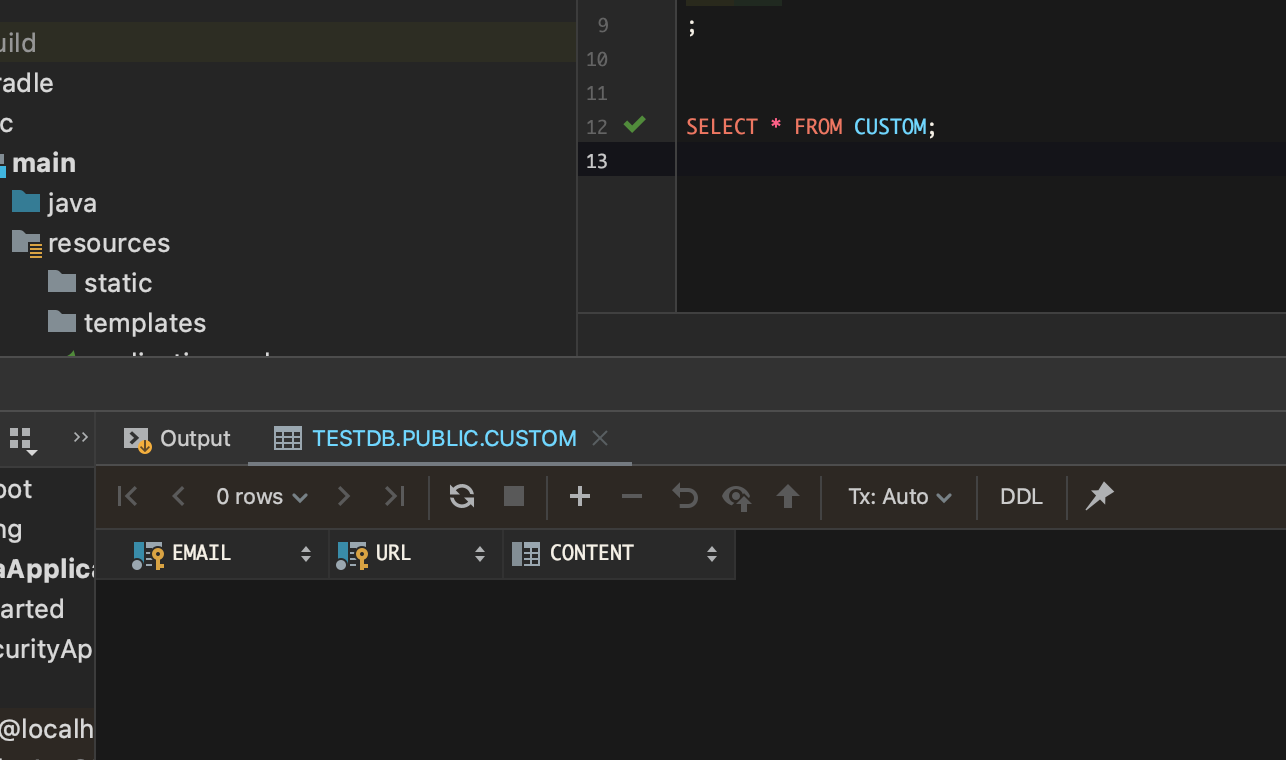
// 실제 적용 예시 DELIMITER $$ DROP PROCEDURE IF EXISTS insertDummyData$$ // 만약 insertDummyData 이름의 프로시저가 있다면, 명령을 사용하여 기존 프로시저를 삭제 CREATE PROCEDURE insertDummyData() // insertDummyData 를 만든다 BEGIN // 시작 DECLARE i INT DEFAULT 1; // 변수 i 를 선언하는데, int 형이고, 기본값은 1 이다 // 10000000 DO 이하의 데이터들은 (아래의) WHILE 문의 규칙을 따른다 WHILE i <= 10000000 DO INSERT INTO member(id, gender, kakao_id, nickname) VALUES(i, 'MALE', i, concat('닉네임', i)); IF i <= 1000000 THEN INSERT INTO board(id, created_time, city, board_content, detail_location, latitude, longitude, region, board_title, town, host_id) VALUES(i, now(), '창원시 의창구', concat('내용', i), concat('상세주소', i), 1.111 + i, 2.222 + i, '경상남도', concat('제목', i), '상남동', i); ELSEIF (i<= 3000000 AND i >= 1000001) THEN INSERT INTO board(id, created_time, city, board_content, detail_location, latitude, longitude, region, board_title, town, host_id) VALUES(i, now(), '강남구', concat('내용', i), concat('상세주소', i), 1.111 + i, 2.222 + i, '서울특별시', concat('제목', i), '대치동', i); ELSEIF (i<= 5000000 AND i >= 3000001) THEN INSERT INTO board(id, created_time, city, board_content, detail_location, latitude, longitude, region, board_title, town, host_id) VALUES(i, now(), '강서구', concat('내용', i), concat('상세주소', i), 1.111, 2.222, '서울특별시', concat('제목', i), '화곡', i); ELSEIF (i <= 6000000 AND i>= 5000001) THEN INSERT INTO board(id, created_time, city, board_content, detail_location, latitude, longitude, region, board_title, town, host_id) VALUES(i, now(), '창원시 의창구', concat('내용', i), concat('상세주소', i), 1.111 + i, 2.222 + i, '경상남도', concat('제목', i), '상남동', i); ELSEIF (i<= 8000000 AND i >= 6000001) THEN INSERT INTO board(id, created_time, city, board_content, detail_location, latitude, longitude, region, board_title, town, host_id) VALUES(i, now(), '강남구', concat('내용', i), concat('상세주소', i), 1.111 + i, 2.222 + i, '서울특별시', concat('제목', i), '대치동', i); ELSE INSERT INTO board(id, created_time, city, board_content, detail_location, latitude, longitude, region, board_title, town, host_id) VALUES(i, now(), '강서구', concat('내용', i), concat('상세주소', i), 1.111, 2.222, '서울특별시', concat('제목', i), '화곡', i); END IF; SET i = i + 1; // 반복을 마친다 END WHILE; END$$ // 끝 DELIMITER $$ CALL insertDummyData; // insertDummyData 를 실행한다 → 프로시저 실행데이터는 1000만 건을 삽입.
파티셔닝(Partitioning) 할 계획이 있는 region 은 중복처리.
데이터는 다음과 같이 준비.
- 200만 건 : "경상남도 창원시 의창구 상남동"
- 400만 건 : "서울특별시 강남구 대치동"
- 400만 건 : "서울특별시 강서구 화곡"
-
더미데이터 삽입상태 확인
1) 게시 글 개수 조회select count(*), city from board group by city;
2) 게시 글 100개 조회
select * from board limit 100;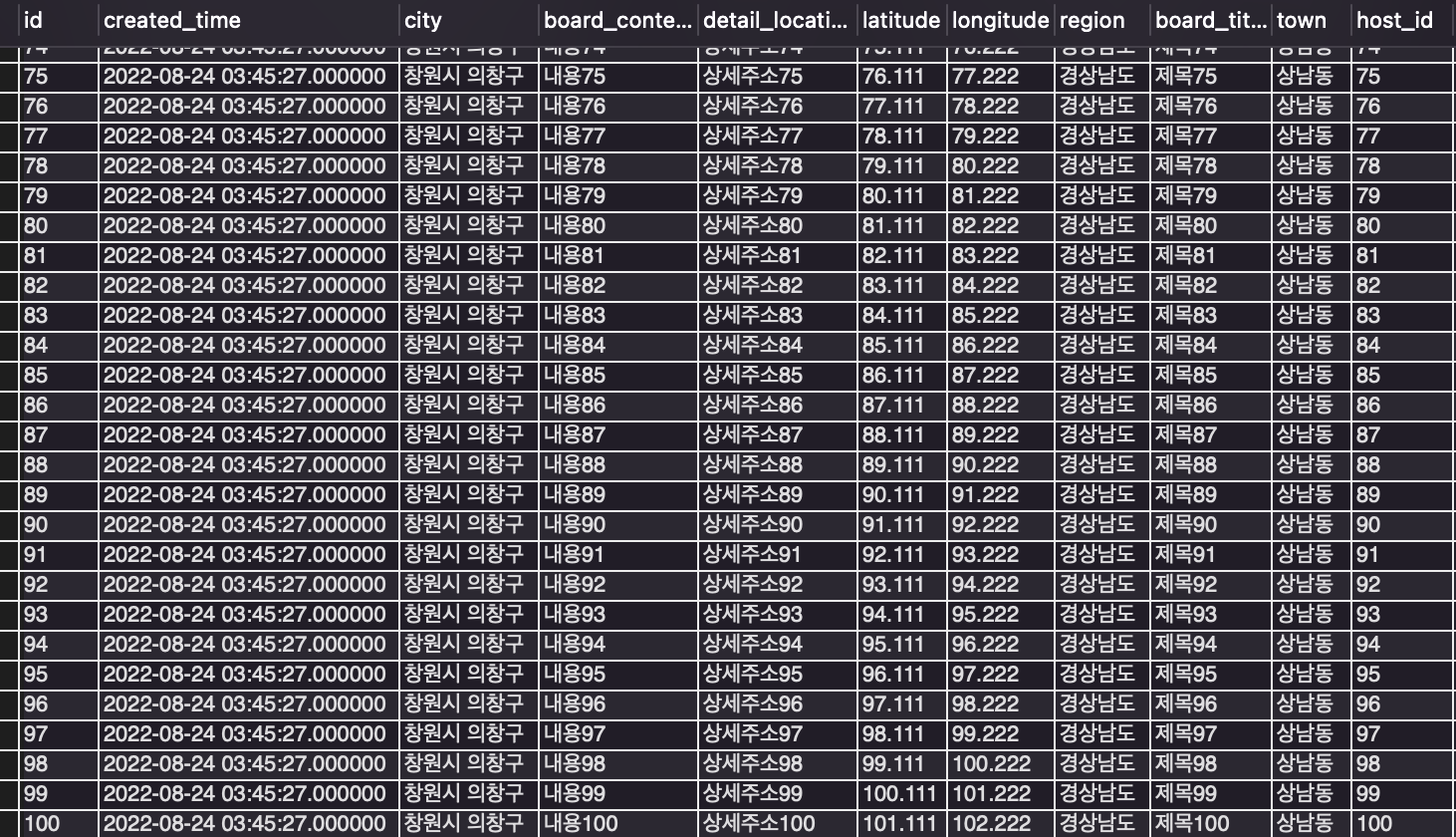
3) 회원 수 조회
select count(*) from member;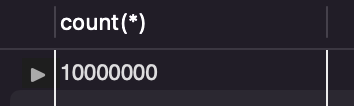
4) 회원 100명 조회
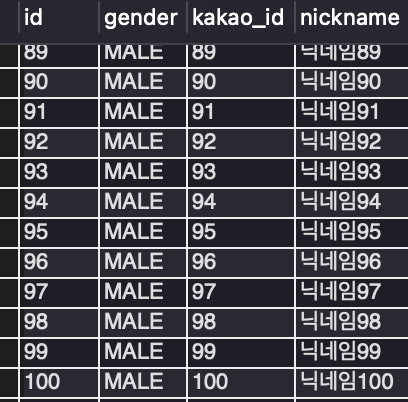
2) 기존 데이터의 복붙
-
기존에 저장돼있던 데이터 준비
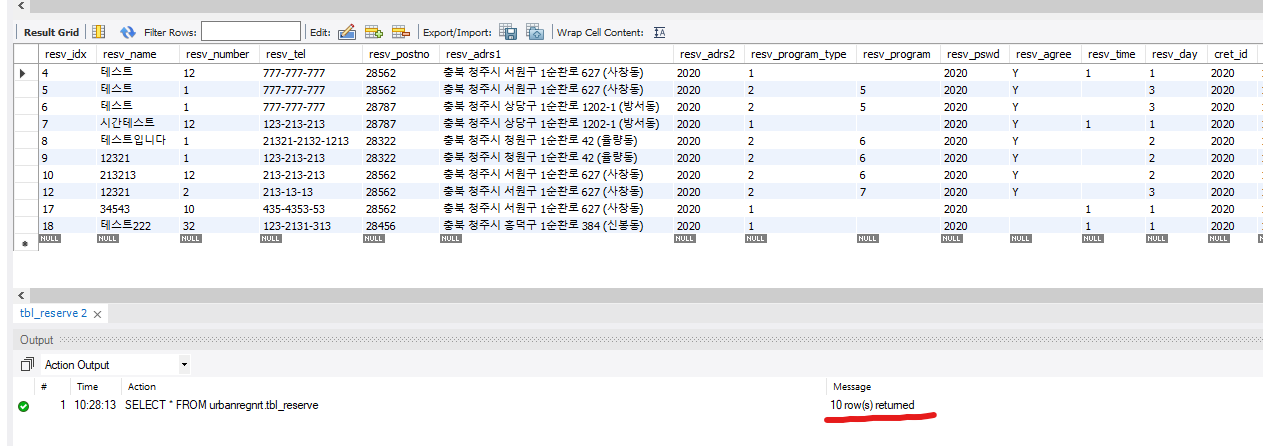
-
insert 와 select 를 통해서, 데이터를 그대로 복사해서 저장
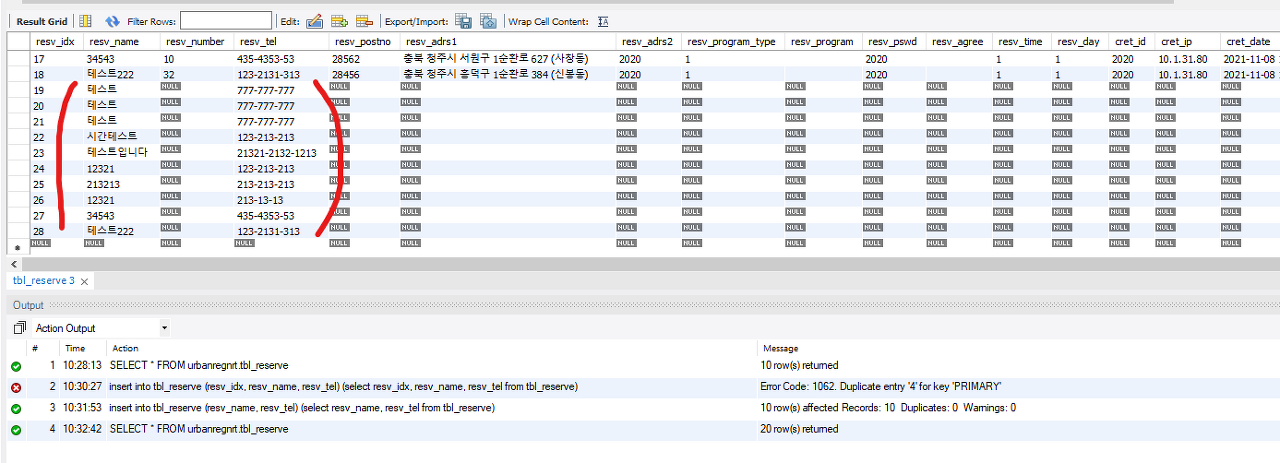
// 문법 insert into 테이블명 (컬럼1, 컬럼2) (select 컬럼1, 컬럼2 from 테이블명); // 예시 insert into tbl_reserve (resv_name, resv_tel) (select resv_name, resv_tel from tbl_reserve);즉, 10개 였던 데이터 → 20개 로
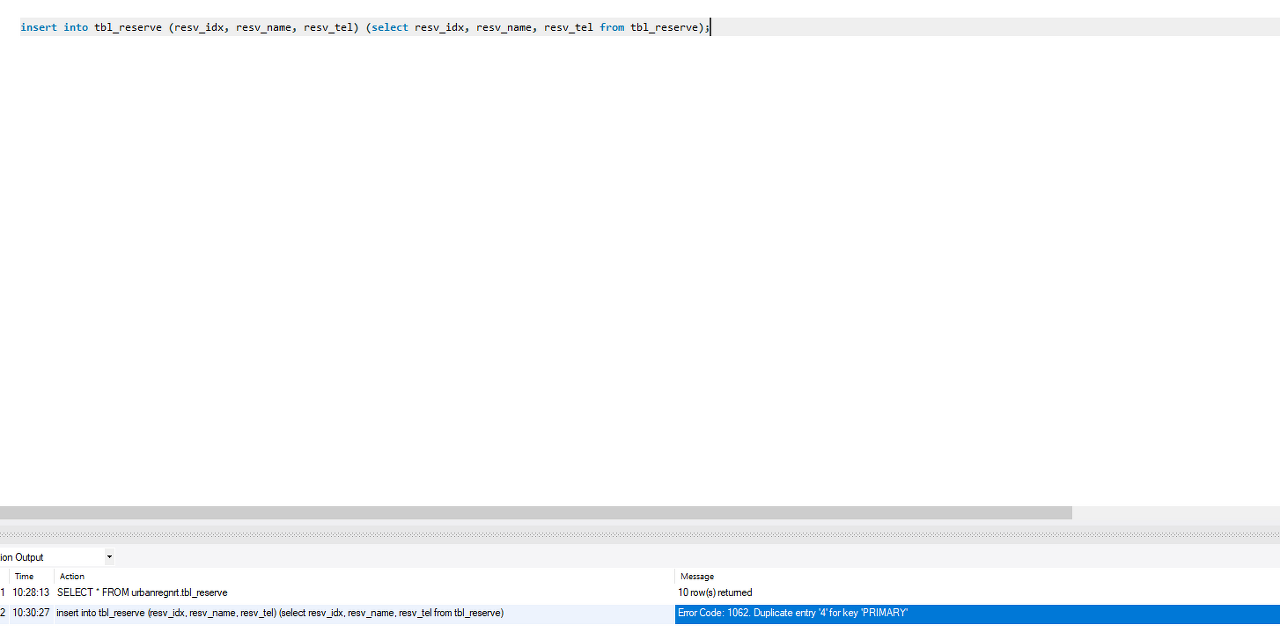
주의! 인덱스를 넣으면 고유키가 중복이 되므로, 에러가 발생한다
-
20개의 데이터가 저장돼있는지 확인하기
3) 더미 데이터 자동 생성 사이트
-
사이트 접속
mockaroo 는 랜덤으로 데이터를 생성해주는 사이트다 -
메인 화면
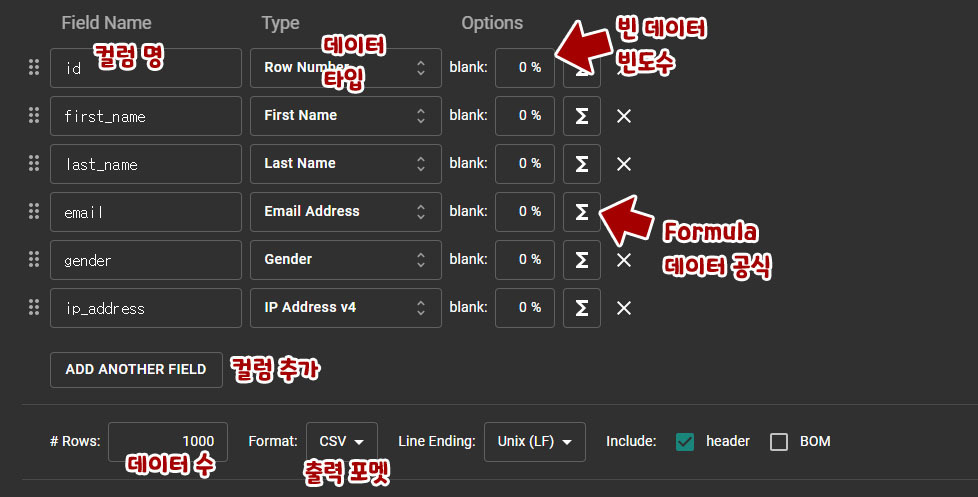
컬럼명: 출력될 컬럼의 이름 추가데이터 타입: 랜덤으로 출력될 데이터의 타입 정하기blank: 빈 데이터의 빈도율 (70% 로 설정한다면, null 이나 빈 값이 나올 확률이 70% 가 된다)Formula: 랜덤으로 나올 데이터에 직접 공식 넣을 수 있다. (컬럼 명: 이름, Formula: '이름 : ' + this → 이름 : [랜덤으로 나온 이름])ADD ANOTHER FIELD: 새 컬럼 추가ROWS: 자동 생성할 데이터 ROW 수FORMAT: 자동으로 출력할 데이터 형식 (포맷) -
데이터 타입 선택
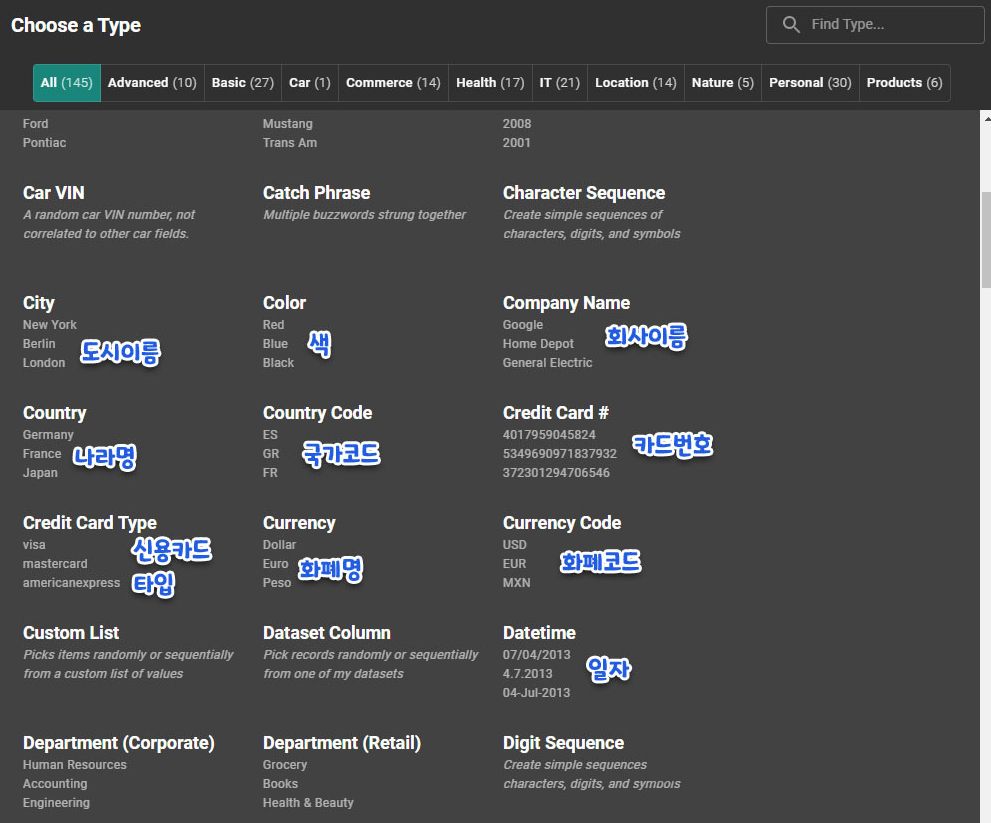
이 외에도 많은 타입이 있음
-
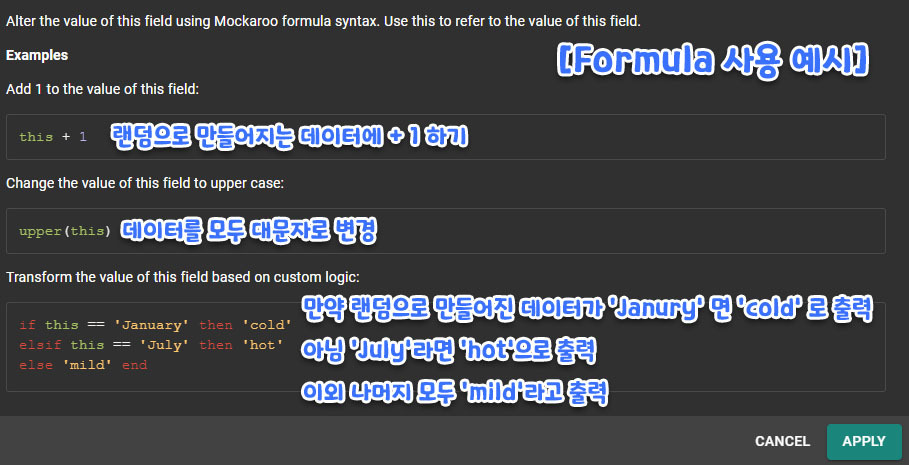
FORMULA
-
데이터 출력

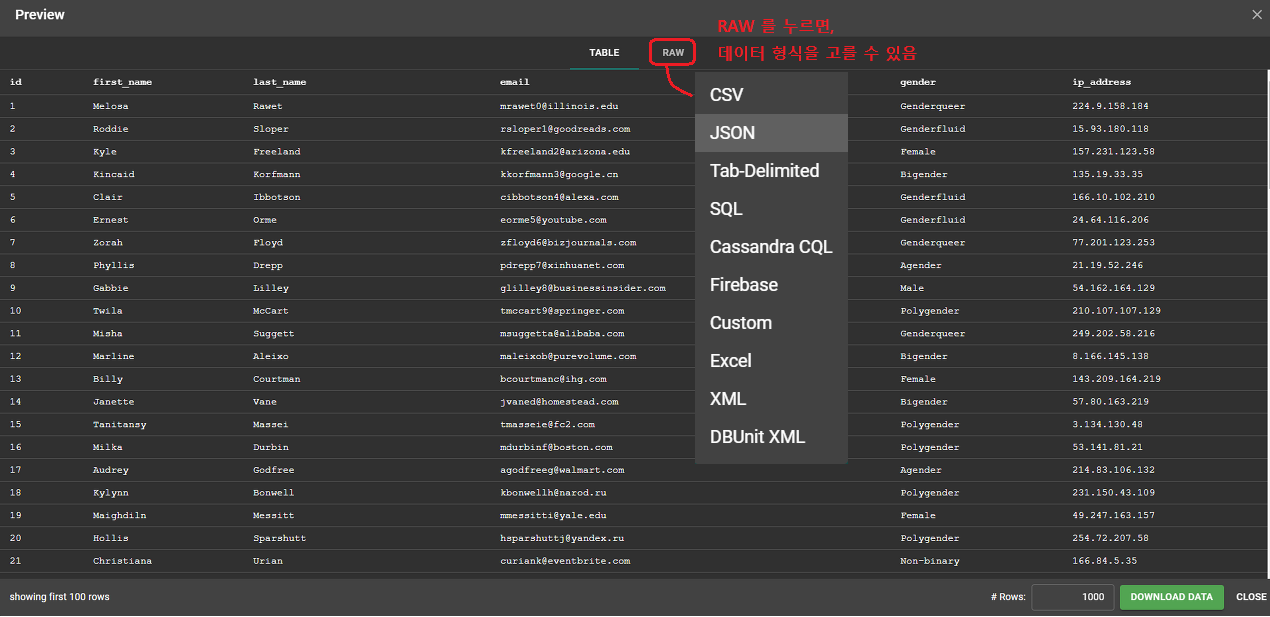
Preview 로 데이터가 잘 나오는지 확인 → 미리보기 (최대 100개 까지만 나옴)
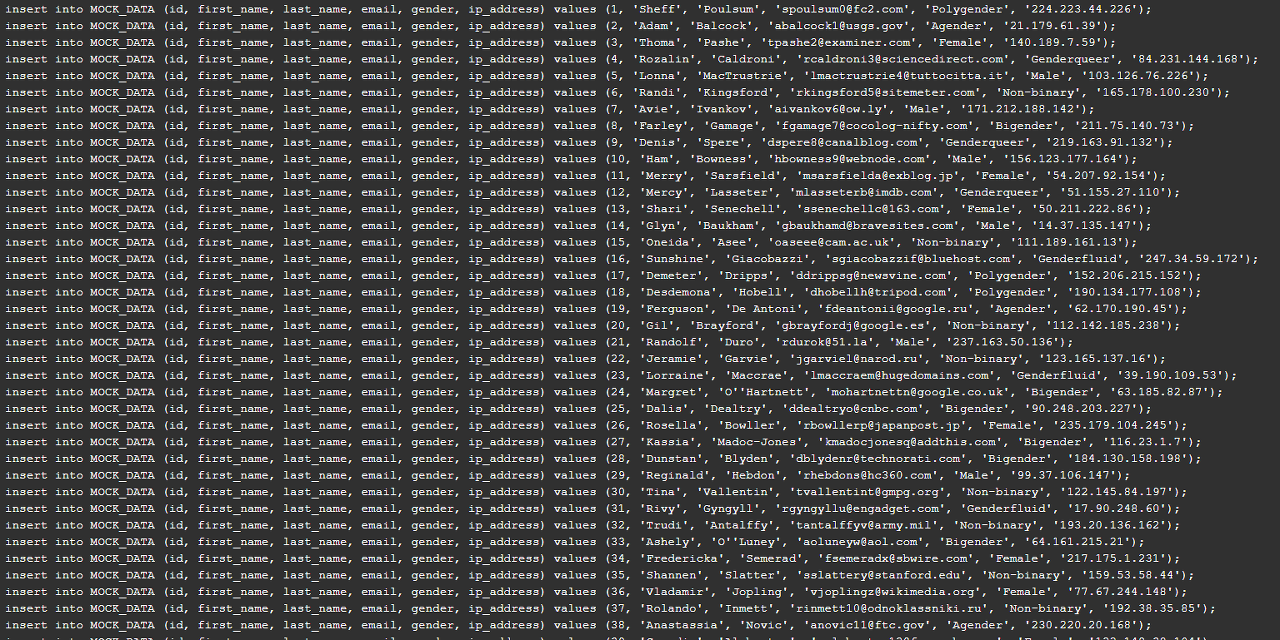
예시로 SQL 데이터
- 다운로드
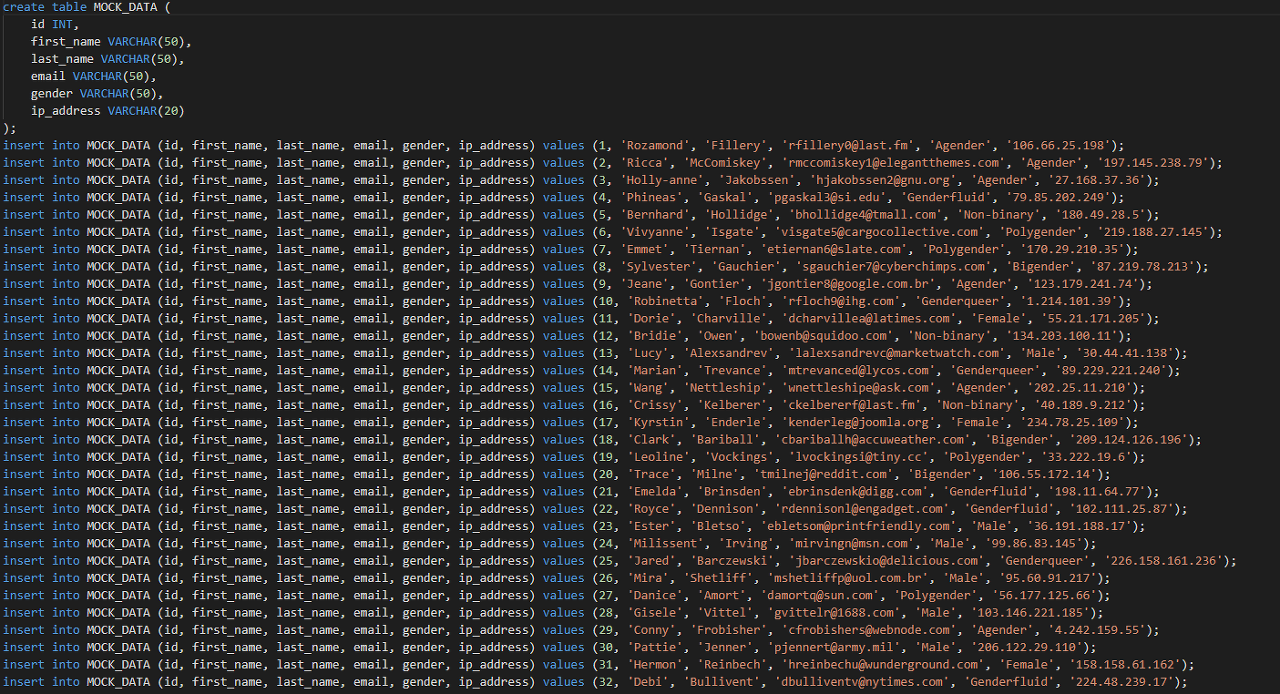
더미 데이터가 잘 나오는지 확인 후, 원하는 형식으로 다운로드
- DB 에 저장
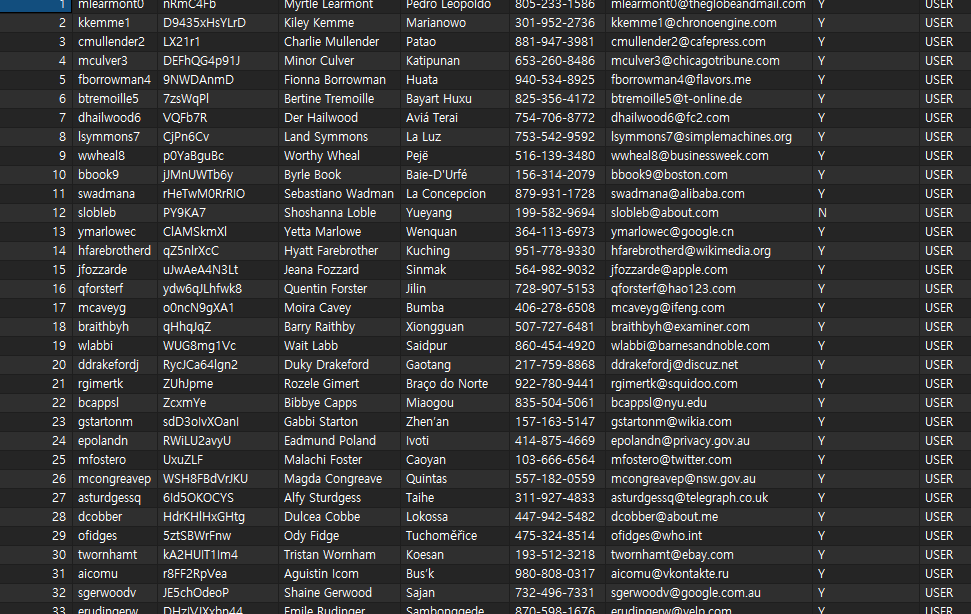
4) Entity, Repository 의 활용
게시판 댓글을 구현하기 위한 것으로 가정한다.
-
연관관계 파악하기

게시글 : 댓글 = One : Many
→One-to-Many 일대다 관계(댓글 입장에서는 Many-to-One)
-
Comment Entity 생성
1)
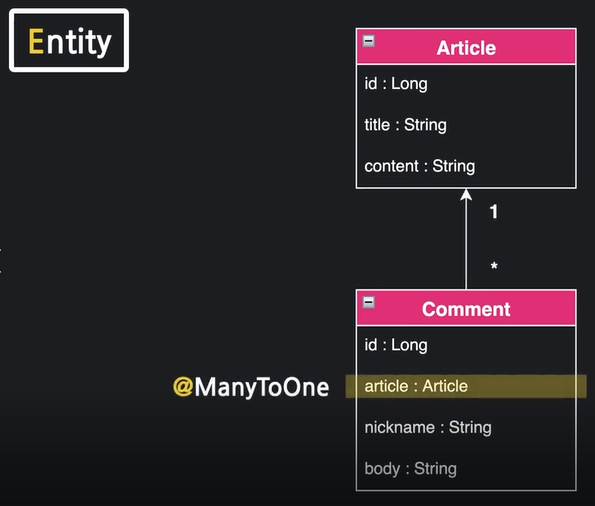
2)
@Entity @Getter @ToString @AllArgsConstructor @NoArgsConstructor public class Comment { @Id @GeneratedValue(strategy = GenerationType.IDENTITY) // DB 자동 증가 private Long id; @ManyToOne // 여러 개의 댓글이 하나의 Article 과 연관 @JoinColumn(name = "article_id") // 테이블에서 연결될 대상정보를 가져온다. private Article article; @Column private String nickname; @Column private String body; }3) 실행 콘솔 화면
create table comment ( id bigint generated by default as identity, body varchar(255), nickname varchar(255), article_id bigint, primary key (id) )이 코드가 실행되면서, comment 테이블을 형성하게 된다.
-
commnet 테이블에 더미 데이터 추가
data.sqlINSERT INTO article(id, title, content) VALUES (1, '가가가가가', '11111'); INSERT INTO article(id, title, content) VALUES (2, '나나나나나', '22222'); INSERT INTO article(id, title, content) VALUES (3, '다다다다다', '33333'); -- article 더미 데이터 추가 INSERT INTO article(id, title, content) VALUES (4, '당신의 인생 영화는?', '댓글 ㄱ'); INSERT INTO article(id, title, content) VALUES (5, '당신의 소울 푸드는?', '댓글 ㄱㄱ'); INSERT INTO article(id, title, content) VALUES (6, '당신의 취미는?', '댓글 ㄱㄱㄱ'); -- comment 더미 데이터 추가 ---- 4번 게시글의 댓글들 INSERT INTO comment(id, article_id, nickname, body) VALUES (1, 4, 'Park', '굳 윌 헌팅'); INSERT INTO comment(id, article_id, nickname, body) VALUES (2, 4, 'Kim', '아이 엠 샘'); INSERT INTO comment(id, article_id, nickname, body) VALUES (3, 4, 'Choi', '쇼생크의 탈출'); ---- 5번 게시글의 댓글들 INSERT INTO comment(id, article_id, nickname, body) VALUES (4, 5, 'Park', '치킨'); INSERT INTO comment(id, article_id, nickname, body) VALUES (5, 5, 'Kim', '샤브샤브'); INSERT INTO comment(id, article_id, nickname, body) VALUES (6, 5, 'Choi', '초밥'); ---- 6번 게시들의 댓글들 INSERT INTO comment(id, article_id, nickname, body) VALUES (7, 6, 'Park', '조깅'); INSERT INTO comment(id, article_id, nickname, body) VALUES (8, 6, 'Kim', '유투브'); INSERT INTO comment(id, article_id, nickname, body) VALUES (9, 6, 'Choi', '독서'); -
Comment Repository 생성
public interface CommentRepository extends JpaRepository<Comment, Long> { // 특정 게시글의 모든 댓글 조회 @Query(value = "SELECT * " + "FROM comment " + "WHERE article_id = :articleId", nativeQuery = true) List<Comment> findByArticleId(Long articleId); // 특정 닉네임의 모든 댓글 조회 List<Comment> findByNickname(String nickname); } -
Test 코드 생성
@DataJpaTest // JPA와 연동한 테스트!
class CommentRepositoryTest {
@Autowired
CommentRepository commentRepository;
@Test
@DisplayName("특정 게시글의 모든 댓글 조회")
void findByArticleId() {
/* Case 1: 4번 게시글의 모든 댓글 조회 */
{
// 입력 데이터 준비
Long articleId = 4L;
// 실제 수행
List<Comment> comments = commentRepository.findByArticleId(articleId);
// 예상하기 → 예상값
Article article = new Article(4L, "당신의 인생 영화는?", "댓글 ㄱ");
Comment a = new Comment(1L, article, "Park", "굳 윌 헌팅");
Comment b = new Comment(2L, article, "Kim", "아이 엠 샘");
Comment c = new Comment(3L, article, "Choi", "쇼생크의 탈출");
List<Comment> expected = Arrays.asList(a, b, c); // List 형태로 변경
// 검증 : 실제값과 예상값을 비교
assertEquals(expected.toString(), comments.toString(), "4번 글의 모든 댓글을 출력!");
}
/* Case 2: 1번 게시글의 모든 댓글 조회 */
{
// 입력 데이터 준비
Long articleId = 1L;
// 실제 수행
List<Comment> comments = commentRepository.findByArticleId(articleId);
// 예상하기
Article article = new Article(1L, "가가가가가", "11111");
List<Comment> expected = Arrays.asList();
// 검증
assertEquals(expected.toString(), comments.toString(), "1번 글은 댓글이 없음");
}
}
@Test
@DisplayName("특정 닉네임의 모든 댓글 조회")
void findByNickname() {
/* Case 1: "Park"의 모든 댓글 조회 */
{
// 입력 데이터를 준비
String nickname = "Park";
// 실제 수행
List<Comment> comments = commentRepository.findByNickname(nickname);
// 예상하기
Comment a = new Comment(1L, new Article(4L, "당신의 인생 영화는?", "댓글 ㄱ"), nickname, "굳 윌 헌팅");
Comment b = new Comment(4L, new Article(5L, "당신의 소울 푸드는?", "댓글 ㄱㄱ"), nickname, "치킨");
Comment c = new Comment(7L, new Article(6L, "당신의 취미는?", "댓글 ㄱㄱㄱ"), nickname, "조깅");
List<Comment> expected = Arrays.asList(a, b, c);
// 검증
assertEquals(expected.toString(), comments.toString(), "Park의 모든 댓글을 출력!");
}
}
}3. 장단점
1) 프로시저
장점
-
하나의 요청으로 SQL 명령을 여러번 실행
-
보수성이 뛰어나다.
단점
-
코드 자산으로의 재사용성이 나쁘다.
-
데이터에 대한 내용 변경 시, 프로시저를 변경해야할 가능성이 존재
참고: [SQL] 더미 데이터(Dummy data)란 무엇인가? (+프로시저 추가)
참고: MySQL 프로시저를 이용한 더미데이터 삽입하기
참고: [MySql] 더미데이터 생성하기
참고: [MYSQL] 더미데이터 생성 쿼리!!
참고: 더미데이터 만들기 - mockaroo (SQL, JSON, 엑셀, XML, CSV)
참고: [Spring] Spring boot H2 Dummy Data 생성 Schema Data
참고: Spring | 더미 데이터
참고: 21. 댓글 CRUD를 위한 Entity와 Repository를 생성
