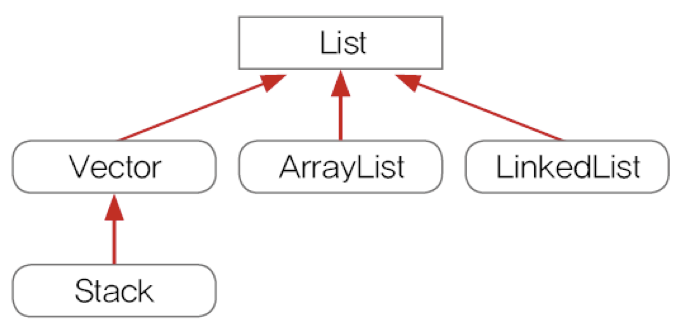
List 인터페이스
1) 정의
중복 O
저장순서 유지 O
- List 인터페이스의 구현 클래스 : LinkedList, Stack, Vector, ArrayList
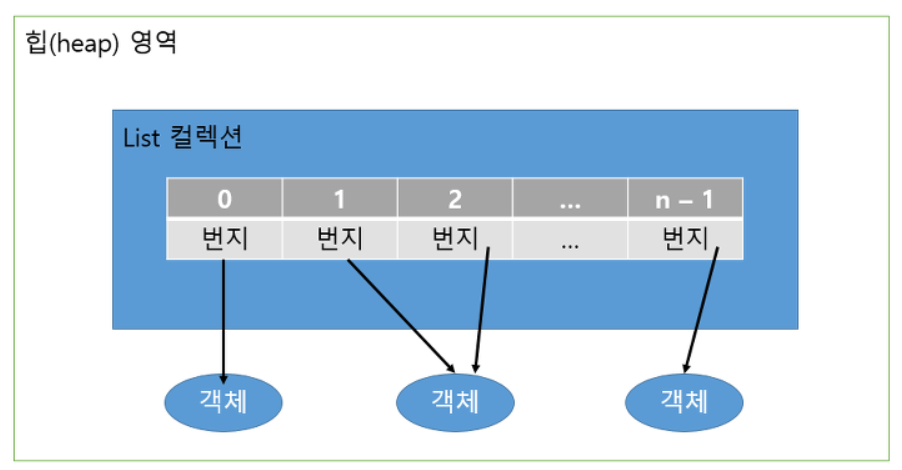
- 순서가 있는 데이터의 집합
객체 자체를 저장 (X)- 객체의 번지를 참조 (O) → 따라서, 동일한 객체를 중복 저장 가능
2) 메서드
list<String> list = ...;
list.add("홍길동"); // 맨 끝에 객체 추가
list.remove(0); // 인덱스로 객체 삭제
list.remove("신용권") // 객체 삭제
...- Collection 인터페이스의 자식이기 때문에, Collection 인터페이스에서 사용되는 메서드 또한 사용이 가능
3) ArrayList
-
기존의 Vector를 개선한 것
- Vector
- 과거에 대용량 처리를 위해 사용헀었음
- 내부에서 자동으로 동기화 처리가 일어나, 비교적 성능이 좋지 않고 무거워 현재는 잘 쓰이지 않음
- 기존에 작성된 소스와의 호환성을 위해 남겨둔 것
- 따라서,
Vector보단ArrayList를 사용할 것!
- 따라서,
Vector vs ArrayList
- 공통점
- 동적 배열을 제공
- 표준 배열보다 느리지만
- 많은 움직임이 필요한 프로그램에서 유용
- 차이점
- 동기화가 된다 (Vector 의 특징)
- 멀티 스레드가
동시에 Vector의 메소드들을 실행 X
참고: 운영체제 (OS) - (3) 동시성 문제
- 멀티 스레드가
- 동기화가 된다 (Vector 의 특징)
- Vector
4) LinkedList
(1) 정의
-
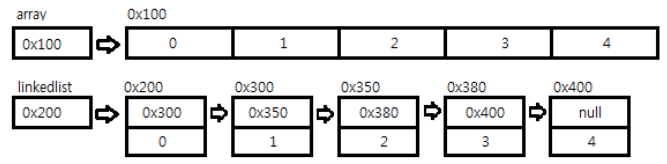
불연속적으로 존재하는 데이터를 서로 연결(Link)한 형태
-
각 요소(node)들은 자신과 연결
-
각 요소(node)들은 다음 요소에 대한 참조(주소값)와 데이터로 구성
-
-
배열의 단점을 보완한 자료구조
- 배열의 단점
- 크기 변경 X
- 비순차적 데이터의 추가/삭제에 작업시간 Long
- 배열의 단점
-
List 인터페이스와 Deque 인터페이스를 둘다 구현
- Queue 를 구현하려면, LinkedList 를 사용하여 구현할 필요가 있다.
(2) 사용법
class GFG {
public static void main(String[] args) {
// LinkedList 선언
LinkedList<Integer> ll = new LinkedList<Integer>();
// 값 입력
for (int i = 1; i <= 5; i++)
ll.add(i);
// 결과 출력
System.out.println(ll);
// 3번 데이터 삭제
ll.remove(3);
// 결과 출력
System.out.println(ll);
// 결과를 하나씩 출력
for (int i = 0; i < ll.size(); i++)
System.out.print(ll.get(i) + " ");
}
}
/* 출력 결과
[1, 2, 3, 4, 5]
[1, 2, 3, 5]
1 2 3 5 */① 삭제
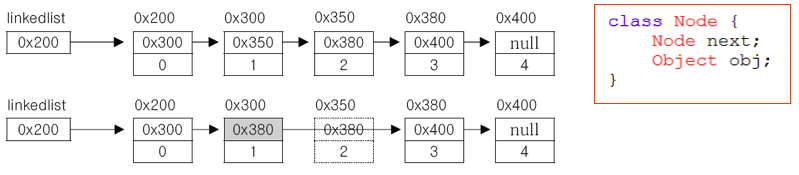
- 삭제할 요소의 이전 요소가 삭제할 요소의 다음 요소를 참조하도록 변경하면 된다
② 추가
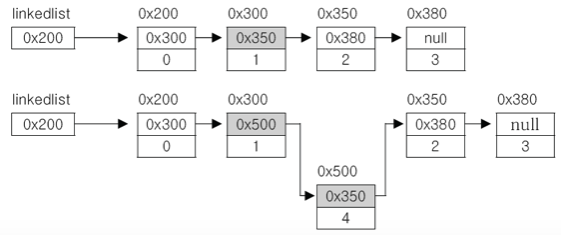
-
새로운 데이터 생성
-
추가할 위치의 이전 요소의 참조 -> 새로운 요소의 참조로 변경
-
새로운 요소가 그 다음 요소를 참조하도록 변경
(3) Array vs LinkedList
개발자 면접에서 자주 나오는 질문 중의 하나!
Array
(Array 와 ArrayList 는 고정 길이인가 아닌가의 차이)
-
읽기 (검색)
- 인덱스로 해당 원소 접근할 수 있어, 찾고자 하는 원소의 인덱스 값을 알고 있으면 O(1)에 해당 원소로 접근할 수 있다.
- RandomAccess 가 가능해, 속도가 빠르다.
-
삽입 / 삭제
- 각 원소들을 shift 해줘야 하는 비용이 생겨, 시간 복잡도는 O(n)이 된다는 단점. 즉, 느리다.
(shift : 배열에서 첫 번째 요소를 제거하고, 제거된 요소를 반환)
- 각 원소들을 shift 해줘야 하는 비용이 생겨, 시간 복잡도는 O(n)이 된다는 단점. 즉, 느리다.
LinkedList
-
읽기 (검색)
- 원하는 위치에 한 번에 접근할 수 없다.
- 원하는 위치에 삽입을 하고자 하면 원하는 위치를 Search 과정에 있어서 첫번째 원소부터 다 확인해봐야 한다.
-
삽입 / 삭제
- 각각의 원소들은 자기 자신 다음에 어떤 원소인지만을 기억하고 있다.
따라서, 이 부분만 다른 값으로 바꿔주면 삽입과 삭제를 O(1)로 해결 가능. 즉, 빠르다.
- 각각의 원소들은 자기 자신 다음에 어떤 원소인지만을 기억하고 있다.
(4) ArrayList vs LinkedList
ArrayList
다루는 데이터의 개수가 고정적일 경우에 사용!
-
읽기 (접근 시간) : Fast ↑
-
추가 / 삭제 : Slow ↓
- 단, 순차적인 데이터의 추가/삭제는 더 빠름
- 비효율적인 메모리 사용
LinkedList
다루는 데이터의 개수가 변동이 많을 경우에 사용!
-
읽기 (접근 시간) : Slow ↓
-
추가 / 삭제 : Fast ↑
-
메모리에 남는 공간을 요청해서 여기저기 나누어서 실제 값을 담아둔다. (요소가
연속된 위치에 저장되지 않고, 모든 요소가 데이터 부분과 주소 부분이 있는 별도의 객체에 저장됨)- 데이터의 추가/삭제가 빈번할 경우, 데이터의 위치 정보만 수정하면 되기에 유용
- 특정 인덱스의 객체를 추가/삭제하면, 앞뒤 링크만 변경 O. 나머지 링크는 변경 X
-
단, 데이터 多수록, 접근성 ↓
-
5) Stack
Stack에 대한 내용 + Stack과 Queue의 비교
참고: 'Stack vs Queue' & 'LIFO(후입선출) vs FIFO(선입선출)'

개발자로 거듭나기!