Map 인터페이스
1) 정의
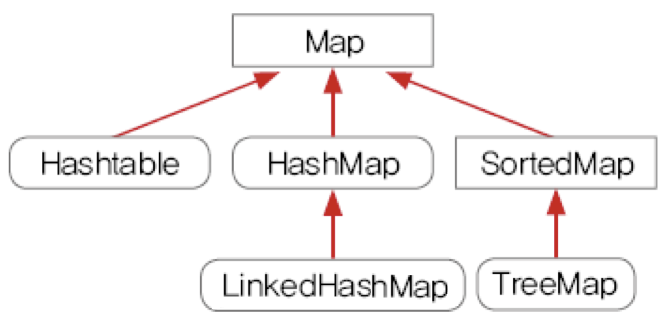
Key 중복 X
Value 중복 O
- Hashing 기술을 사용
- 인덱싱 및 검색 작업이 더 빨라지도록 key에 산술적인 연산을 적용하여,
항목이 저장되어 있는 테이블의 주소를 계산하여 항목에 접근하는 방식
- 인덱싱 및 검색 작업이 더 빨라지도록 key에 산술적인 연산을 적용하여,
2) 메서드
3) HashMap
(1) 정의
-
해싱(hashing)을 하기 때문에, 많은 데이터를 검색하는데 뛰어난 성능을 보임
-
키와 값의 저장
- Object 타입으로 저장 -> (Object, Object) 형태 (따라서, 타입에 제한 받지 않음)
- 키 : 주로 String을 대문자/소문자로 통일해서 사용
- Object 타입으로 저장 -> (Object, Object) 형태 (따라서, 타입에 제한 받지 않음)
-
Null값도 저장 가능
-
해시 함수를 통해 '키'와 '값'이 저장되는 위치를 결정
- 사용자는 그 위치를 알 수 X
- 삽입되는 순서와 들어 있는 위치와는 무관
Hashtable vs HashMap
Hashtable : HashMap보다는 느리지만, 동기화 지원Vector vs ArrayList의 관계와 같다.
Hashtable 보단,HashMap 를 사용하길 권장한다.
(2) 사용법
예시 1 : ID 와 비밀번호
import java.util.*;
class Ex [
public static void main(string[] args) [
HashMap map = new HashMap();
map.put("myId", "1234");
map.put("asdf", "1111");
map.put("asdf", "1234"); // 이미 존재하는 키를 추가하므로, 기존 값은 없어짐
Scanner s=new Scanner(System.in); // 화면으로부터 라인단위로 입력받는다.
while(true) {
System. out.println("id와 password를 입력해주세요.");
System.out.print("id :");
string 'id = s.nextLine().trim();
System.out.print("password :");
String password = s.itetine().trim();
System.out.printin();
if (!map. containskey(id)) { // HashMap에 지정된 키가 포함돼있는지 확인
system. out. printin("입력하신 id는 존재하지 않습니다. 다시 입력해주세요.");
continue;
}
if (!(map.get(id)).equals(password)) { // 지정된 키의 값을 반환
system.out. println( "비밀번호가 일치하지 않습니다. 다시 입력해주세요.");
} else {
system.out. println("id와 비밀번호가 일치합니다." );
break;
}
}
}
}-
로그인 시,
-
키 = 아이디
- 중복 X
- 동일한 아이디는 없다.
-
값 = 비밀번호
- 중복 O
- 서로 다른 아이디일지라도, 두 아이디의 비밀번호는 같을 수 있다.
-
-
기존에 저장된 키와 동일한 키로 값을 저장하면,
기존의 값은 없어지고새로운 값으로 대체된다.
예시 2 : 선언
HashMap<String,String> map1 = new HashMap<String,String>(); // HashMap생성
HashMap<String,String> map2 = new HashMap<>(); // new에서 타입 파라미터 생략가능
HashMap<String,String> map3 = new HashMap<>(map1); // map1의 모든 값을 가진 HashMap생성
HashMap<String,String> map4 = new HashMap<>(10); // 초기 용량(capacity)지정
HashMap<String,String> map5 = new HashMap<>(10, 0.7f); // 초기 capacity,load factor지정
HashMap<String,String> map6 = new HashMap<String,String>(){{ // 초기값 지정
put("a","b");
}};-
HashMap 생성 : 키 타입과 값 타입을 파라미터로 주고 기본생성자를 호출하면 된다.
-
HashMap의 저장공간
- HashMap은 저장공간보다 값이 추가로 들어오면, List처럼 저장공간을 추가로 늘린다.
- 단,
List처럼 저장공간을 한 칸씩 늘리지 않고약 두배로 늘린다.
→ 여기서 과부하가 많이 발생
→ 따라서, 초기에 저장할 데이터 개수를 알고 있다면, Map의 초기 용량을 지정해줄 것을 권장
- 단,
- HashMap은 저장공간보다 값이 추가로 들어오면, List처럼 저장공간을 추가로 늘린다.
예시 3 : 값 추가
HashMap<Integer,String> map = new HashMap<>(); // new에서 타입 파라미터 생략가능
map.put(1,"사과"); // 값 추가
map.put(2,"바나나");
map.put(3,"포도");- 값 추가 : put(key,value) 메소드를 사용
- 단, 선언 시 HashMap에 설정해준 타입과 같은 타입의 Key와 Value값을 넣어야 한다.
- 입력되는 키 값이 HashMap 내부에 존재한다면, 기존의 값은 새로 입력되는 값으로 대치된다.
예시 4 : 값 삭제
HashMap<Integer,String> map = new HashMap<Integer,String>(){{ // HashMap 선언 : 초기값 지정
put(1,"사과"); // 값 추가
put(2,"바나나");
put(3,"포도");
}};
map.remove(1); // key값 1 제거
map.clear(); // 모든 값 제거- 값 제거 : remove(key) 메소드를 사용
- 오직 '키값'으로만 Map의 요소를 삭제할 수 있다. (map.remove)
- 만약, 모든 값을 제거하려면 clear() 메소드를 사용
예시 5 : 값 출력
HashMap<Integer,String> map = new HashMap<Integer,String>(){{ // HashMap 선언 : 초기값 지정
put(1,"사과"); // 값 추가
put(2,"바나나");
put(3,"포도");
}};
System.out.println(map); // 전체 출력
System.out.println(map.get(1)); // key값 1의 value얻기
/* 출력 결과
{1=사과, 2=바나나, 3=포도}
사과
*/예시 6 : 값 조회
문법
// 1. 조회
intMap.get({조회할 Key값})
// 2. 전체 key 조회
intMap.keySet()
// 3. 전체 value 조회
intMap.values()예시
import java.util.Map;
public class Main {
public static void main(String[] args) {
Map<String, Integer> intMap = new HashMap<>(); // 선언 및 생성
// 키 , 값
intMap.put("일", 11);
intMap.put("이", 12);
intMap.put("삼", 13);
intMap.put("삼", 14); // 중복 Key값은 덮어쓴다
intMap.put("삼", 15); // 중복 Key값은 덮어쓴다
// key 값 전체 출력
for (String key : intMap.keySet()) {
System.out.println(key); // 일,이,삼 출력
}
// value 값 전체 출력
for (Integer key : intMap.values()) {
System.out.println(key); // 11,12,15 출력
}
// get()
System.out.println(intMap.get("삼")); // 15 출력
}
}
/* 출력 결과
이
일
삼
12
11
15
15
*/예시 7 : 크기 구하기
import java.util.HashMap;
public class HashMapDemo {
public static void main(String[] args) {
HashMap<String, String> hm = new HashMap<String, String>(); // HashMap 선언 : 초기값 지정
hm.put("1", "Hello1"); // 값 추가
hm.put("2", "World2");
hm.put("3", "Hello3");
hm.put("4", "World4");
System.out.println(hm);
System.out.println("Size : " + hm.size());
}
}
/* 출력 결과
{1=Hello1, 2=World2, 3=Hello3, 4=World4}
Size : 4 */- 크기 구하기 : size() 메서드를 사용예시 8 : 정렬
HashMap의 entrySet과 Stream을 이용한 key값 기준 정렬
Map<String, Integer> map = new HashMap<>();
map.put("A", 5);
map.put("Z", 2);
map.put("C", 11);
map.put("G", 4);
map.put("E", 9);
// key를 기준값으로 정렬
map.entrySet().stream()
.sorted(Map.Entry.comparingByKey())
.forEach(entry -> System.out.printf("Key : %s, value : %d%n", entry.getKey(), entry.getValue()));
/* 출력 결과
Key : A, value : 5
Key : C, value : 11
Key : E, value : 9
Key : G, value : 4
Key : Z, value : 2
*/HashMap의 entrySet과 Stream을 이용한 value값 기준 정렬
Map<String, Integer> map = new HashMap<>();
map.put("A", 5);
map.put("Z", 2);
map.put("C", 11);
map.put("G", 4);
map.put("E", 9);
// value를 기준값으로 정렬
map.entrySet().stream()
.sorted(Map.Entry.comparingByValue())
.forEach(entry -> {
System.out.printf("Key : %s, value : %d%n", entry.getKey(), entry.getValue());
});
/* 출력 결과
Key : Z, value : 2
Key : G, value : 4
Key : A, value : 5
Key : E, value : 9
Key : C, value : 11
*/HashMap의 entrySet과 Stream을 이용한 value값 기준 역정렬
Map<String, Integer> map = new HashMap<>();
map.put("A", 5);
map.put("Z", 2);
map.put("C", 11);
map.put("G", 4);
map.put("E", 9);
// value 기준 역정렬
map.entrySet().stream()
.sorted(Collections.reverseOrder(Map.Entry.comparingByValue()))
.forEach(entry -> {
System.out.printf("Key : %s, value : %d%n", entry.getKey(), entry.getValue());
});
/* 출력 결과
Key : C, value : 11
Key : E, value : 9
Key : A, value : 5
Key : G, value : 4
Key : Z, value : 2
*/예시 9 : getOrDefault(Object key, V DefaultValue) 메소드**
import java.util.HashMap;
public class MapGetOrDefaultEx {
public static void main(String arg[]) {
String [] alphabet = { "A", "B", "C" ,"A"};
HashMap<String, Integer> hm = new HashMap<>();
for(String key : alphabet) hm.put(key, hm.getOrDefault(key, 0) + 1);
System.out.println("결과 : " + hm);
}
}
/* 출력 결과
결과 : {A=2, B=1, C=1}
*/-
map.getOrDefault(Object key, V DefaultValue)
- key : 값을 가져와야 하는 요소의 키 (map 요소의 키)
- defaultValue : 지정된 키로 매핑된 값이 없거나 null이면 반환하는 기본 값
-
찾는 key가 존재하면, key에 매핑되어있는 value를 반환
찾는 key가 없거나 null 이면, 디폴트 값을 반환
4) TreeMap
public void treeMapTest() {
Map<String, String> HashMap = new TreeMap<>();
hashMap.put("사과", "apple");
hashMap.put("포도", "grape");
hashMap.put("수박", "watermelon");
hashMap.put("배", "pear");
System.out.println(hashMap);
}
/* 출력 결과
{배=peqr, 사과=apple, 수박=watermelon, 포도=grape} */-
정렬된 순서대로 키(Key)와 값(Value)을 저장하여, 검색이 빠름
-
이진트리를 기반으로 한다
-
부모 키값을 비교하여
낮은 것은 왼쪽에, 높은 것은 오른쪽에 Map.Entity 를 저장
→ 따라서, (다른 자료구조에 비해) 저장 시간이 오래 걸림
5) MAP 에서 entrySet() 사용
for (Entry<Integer, String> entry : map.entrySet()) {
System.out.println("[Key]:" + entry.getKey() + " [Value]:" + entry.getValue());
}
/* 출력 결과
[Key]:1 [Value]:사과
[Key]:2 [Value]:바나나
[Key]:3 [Value]:포도
*/-
전체 출력
-
key와 value 모두가 필요할 경우 사용
-
장점 : (KeySet()에 비해) key와 value를 찾는 시간 小 → 따라서, 많은 양의 데이터를 가져와야 할 경우 권장
-
단점 : 약 20 ~ 200% 성능 저하
-
6) MAP 에서 KeySet() 사용
for (Integer i : map.keySet()){ // 저장된 key값 확인
System.out.println("[Key]:" + i + " [Value]:" + map.get(i));
}
/* 출력 결과
[Key]:1 [Value]:사과
[Key]:2 [Value]:바나나
[Key]:3 [Value]:포도
*/-
전체 출력
-
key 값만 필요할 경우 사용
-
장점 : (entrySet()에 비해) 코드가 간단함
-
단점 : key값을 이용해서 value를 찾는 과정에서 시간 소모 多
-
7) MAP 에서 Iterator() 사용
문법
Map map = new HashMap();
...
Iterator it = map.entrySet().iterator();
/* 위의 코드는 사실은 아래 두 문장을 합친 것
Set eset = map.entrySet();
Iterator it = eSet.iterator();
*/- Map 인터페이스는 키와 값을 쌍으로 저장하고 있으므로, iterator()를
직접 호출 X- 대안 : 다음 메서드로 키와 값을 따로 Set 형태로 얻은 후(keySet(), entrySet() 메서드 사용), 다시 iterator()를 호출
예시 1 : entrySet().iterator()
HashMap<Integer,String> map = new HashMap<Integer,String>(){{ // HashMap 선언 : 초기값 지정
put(1,"사과"); // 값 추가
put(2,"바나나");
put(3,"포도");
}};
Iterator<Entry<Integer, String>> entries = map.entrySet().iterator();
while(entries.hasNext()){
Map.Entry<Integer, String> entry = entries.next();
System.out.println("[Key]:" + entry.getKey() + " [Value]:" + entry.getValue());
}
/* 출력 결과
[Key]:1 [Value]:사과
[Key]:2 [Value]:바나나
[Key]:3 [Value]:포도
*/예시 2 : keySet().iterator()
HashMap<Integer,String> map = new HashMap<Integer,String>(){{ // HashMap 선언 : 초기값 지정
put(1,"사과"); // 값 추가
put(2,"바나나");
put(3,"포도");
}};
Iterator<Integer> keys = map.keySet().iterator();
while(keys.hasNext()){
int key = keys.next();
System.out.println("[Key]:" + key + " [Value]:" + map.get(key));
}
/* 출력 결과
[Key]:1 [Value]:사과
[Key]:2 [Value]:바나나
[Key]:3 [Value]:포도
*/- HashMap의 전체를 출력할 경우,
반복문 대신Iterator 를 사용해도 무방
