FT(Fourier transform), STFT (Short Time Fourier transform)에 대해 알아보자

데이터 통신 강의 시간에 푸리에 변환에 대해 들어본 적이 있다.
한... 3강 즈음이었던 것 같음.
[ Ch3 Introduction of Physical Layer ]
해당 챕터에서는 Data와 Signal, Periodic과 Non-periodic을 중점적으로 배웠다.
Periodic signal은 측정 가능한 시간인 frame 내에서 패턴을 완성하고 동일한 기간동안 해당 패턴을 반복한다는 특징이 있고, 대표적으로 sin wave가 periodic signal에 해당한다.
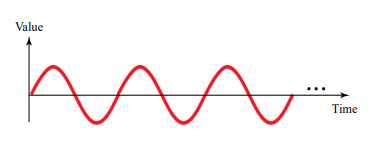
사인파는 단순 주기적 아날로그 신호 ( simple periodic analog signal )로, 더이상 분해할 수 없는 가장 작은 ( 기본적인? ) 단위이다. 이러한 특징을 바탕으로, 모든 복합 주기적 아날로그 신호 ( composite periodic analog signal )는 여러개의 sin wave를 통해서 표현 가능하다.
공부하다보니 개인적인 복습용으로관련 용어 정리
peak amplitute: 최대 진폭
amplitute: 진폭
Period(주기) : 신호가 하나의 주기를 완료하는 데 필요한 시간
Frequency(주파수) : 진동수 -> 1초에 몇번의 주기를 완수하는가? (단위 Hz)
frequency = 1/Period이다.
phase: 각도 (즉 시작 지점이 다른 것)
...
암튼 이러한 내용들을 배웠는데, 다시 보니 새롭네..
본론으로 돌아와서 Fourier Transform 푸리에 변환이란 진짜 무엇일까 ? 그때도 이해 못하고 넘어갔는데, 여전히 이해가 잘 되진 않는다.
FT (Fourier Transform)
요약을 통해 먼저 쉽게 이해해보자면, "시간에 대한 함수(or 신호)를 주파수에 대한 함수로 변환하는 것"
네?
시간에 대한 함수를 주파수에 대한 함수로 변환하는 것.... -> 처음 읽으면 무슨 말인지 와닿지가 않는게 정상이다.
[ 해석 ]
: 시간에 따른 신호의 변화를, 주파수의 관점으로 변환한 것.
( 그래프에서, x축을 시간에서 -> 주파수로 바꿨다고 생각하면 됨 )
예를 들어보자, 어떤 복잡한 신호가 있다.
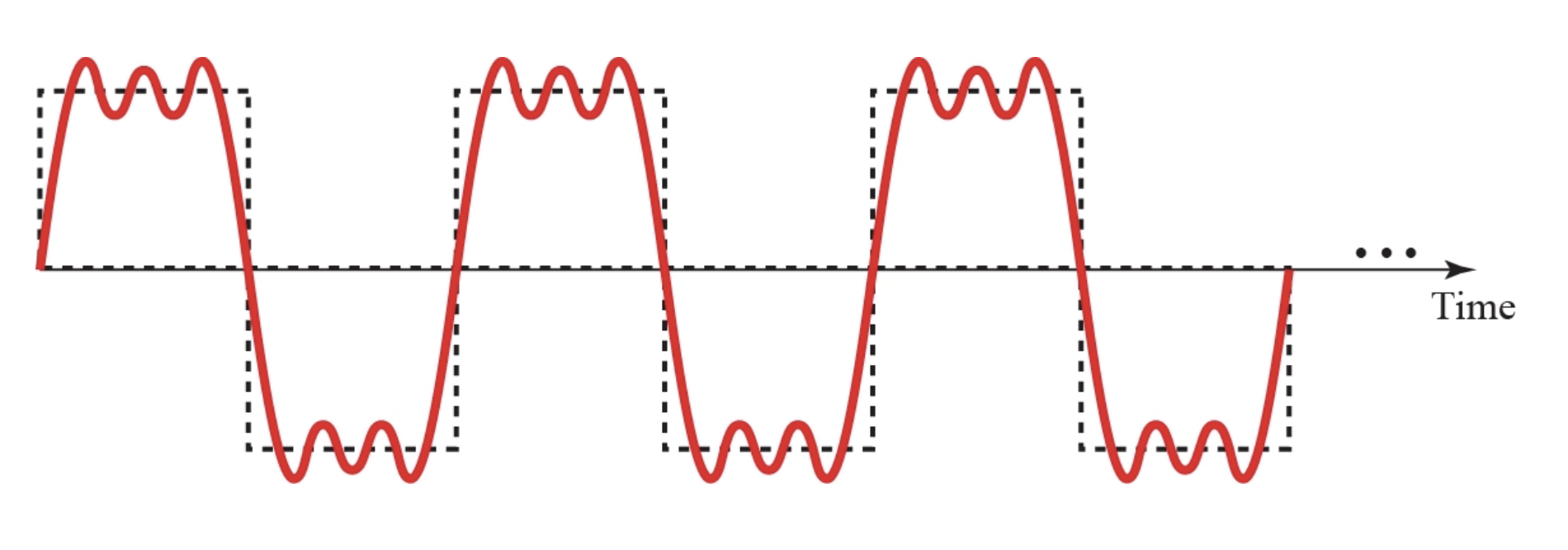
이 복잡한 신호는 어떤 단순한 신호들로 구성되어있을까? 푸리에 변환을 통하면 어떤 신호들로 구성되어있는지 알 수 있다.
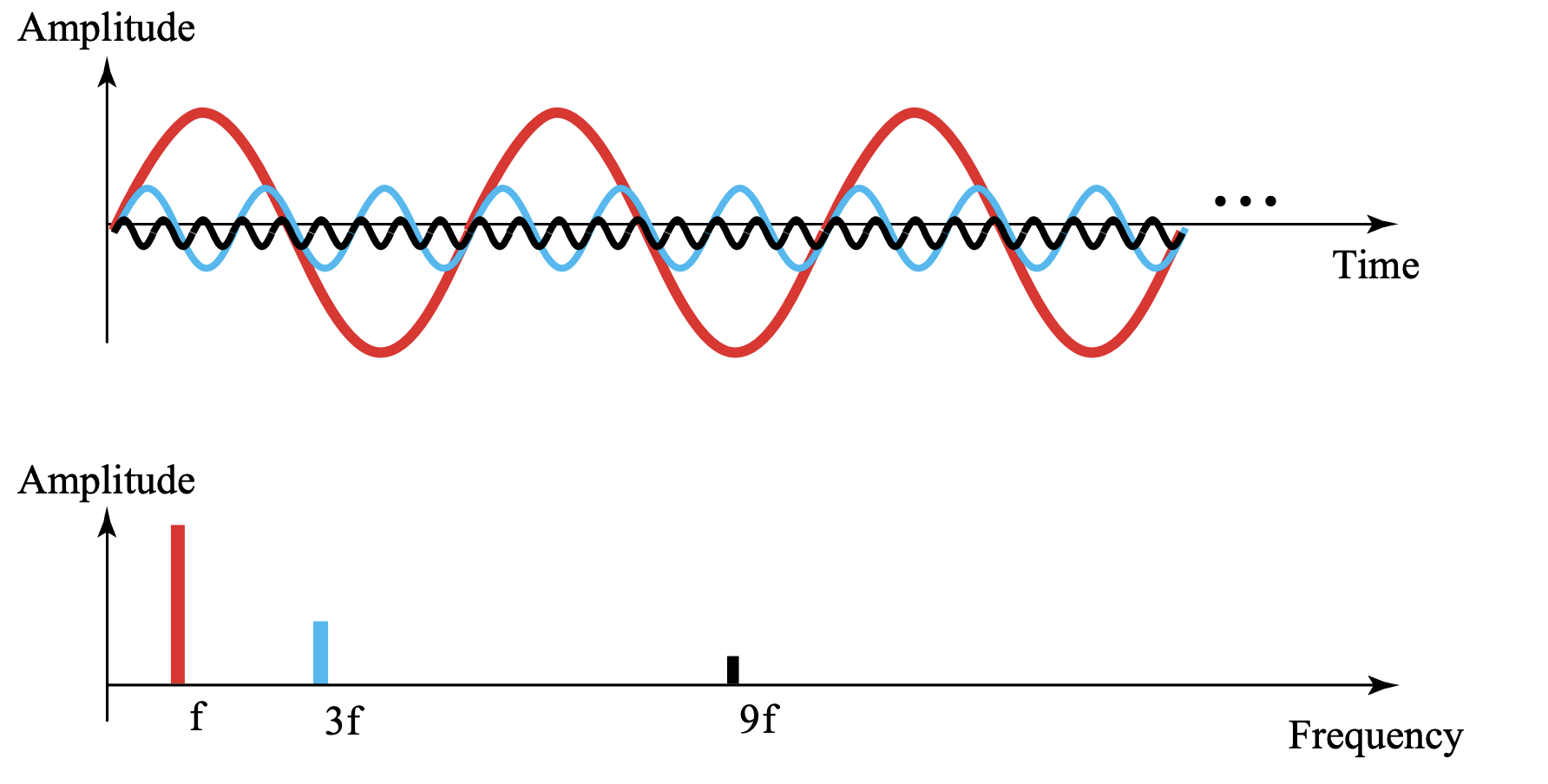
푸리에 변환을 통해 복잡한 시그널을 분해해보면 다음과 같은 결과를 얻을 수 있다고 한다.
요약하자면 ! 푸리에 변환이란, 어떤 복잡한 신호가 있는데 이 복잡한 신호가 어떠한 단순한 신호들로 구성되었는지를 알려주는 변환기라고 이해할 수 있다.
조금 더 깊은 이해를 해보자.
사람이 " 아~~~ " 라고 소리냈을 때, 다음과 같은 모양의 주파수가 생긴다고 쳐보자. 해당 소리를 하나의 음으로만 냈다면, 그 소리는 하나의 주파수로 이루어졌을까?
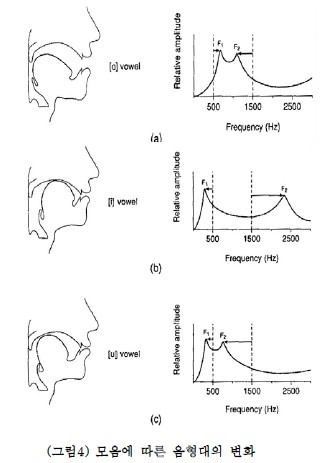
정답은 아니다.
사람이 같은 음의 높이로 소리를 내도 그 안에는 굉장히 많은 주파수 성분이 있고, 이 주파수 성분들의 합해져서 " 아~~~ " 라는 소리가 되는 것이다.
이러한 파형도 푸리에 변환을 통해 변환한다면, 여러 주파수 성분들을 얻어낼 수 있을 것이다.
이렇게 얻어낸 주파수 성분을 이용한다면, 파형만 보고는 분류하기 어려운 "아 ~" 와 "가 ~"를 분류해내는 작업이 가능할 것이다. 혹은 주파수 성분 중 일부를 수정하여 아예 다른 음성 (ex. "바~") 을 만들어 내는 작업도 가능할 것이다.
STFT를 알아보기 전에 가볍게 FT에 대해 먼저 알아봤다. 이제 STFT를 알아보자.
STFT (Short Time Fourier Trasnform)
어떤 음성신호에 대해 FFT를 적용하는데, 일정한 시간 단위로 끊어서 적용하는 것. 음성 인식에서 사용되는 기법이라고 한다.
사실 음성인식 이벤트 탐지 분류 모델 생성을 위해 STFT를 사용해야해서 공부 중인데, FT, STFT 외에도 많은 종류의 푸리에 변환이 존재함을 알아버렸고 ....... 이를 이해하기 위해서는 몇몇 추가적인 알고리즘에 대한 공부가 필요할 것 같아 이번 포스트에서는 간단하게만 알아보고 쉬운 방법을 택하여 간단한 실습만 해보기로 햇따 ..
[ Discrete Fourier Transform ]
퓨리에 변환의 결과가 이산값(Dicrete)하게 만드는 것이 특징.
우리가 실제로 컴퓨터에 활용할 신호는 양자환된 Dicrete신호이므로, DFT가 필요하다.
[ Fast Fourier Transform ]
DFT를 빠르게 계산하는 하나의 알고리즘.
내츄럴한 DFT는 계산량이 많다. (DFT의 복잡도는 O(N*N)이다.)
더 간단히 할 수 있는 방법이 FFT이고, FFT의 복잡도는 (N/2)logN 으로 줄어들 수 있다.
가장 일반적으로 사용되는 알고리즘은 쿨리-튜키 알고리즘이다.
(단, N=2의 지수승일 때만 가능- 2, 4, 32 등..)
[ STFT (Short Time Fourier Transform) ]
어떤 (음성) 신호에 대해 FFT를 적용하는데, 일정한 시간 단위로 끊어서 적용하는 것.
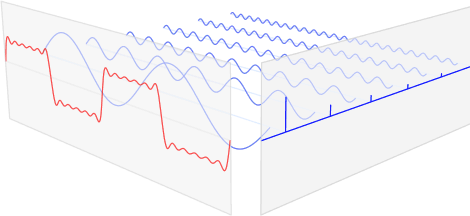
즉, FFT를 쓰지만 시간의 개념이 추가된다. (아래 그림 참고)
[ Spectrogram ] - YAMNet을 사용 해봤다면 익숙할 "그" 단어..
STFT는 FFT에서 가지고 있는 변수인 '주파수', '크기(진폭)'에 '시간'을 더한 것이라고 하였다.
이 STFT의 3차원 변수를 2차원으로 표현한 시각화 도구가 Spectrogram이다.
x축, y축은 주파수와 시간을 나타내고, 크기(진폭)은 색깔로써 표현한다.
STFT 실습 참고 블로그 -> 해당 블로그를 통해 STFT를 실제 어떻게 활용하는지 공부하였다.
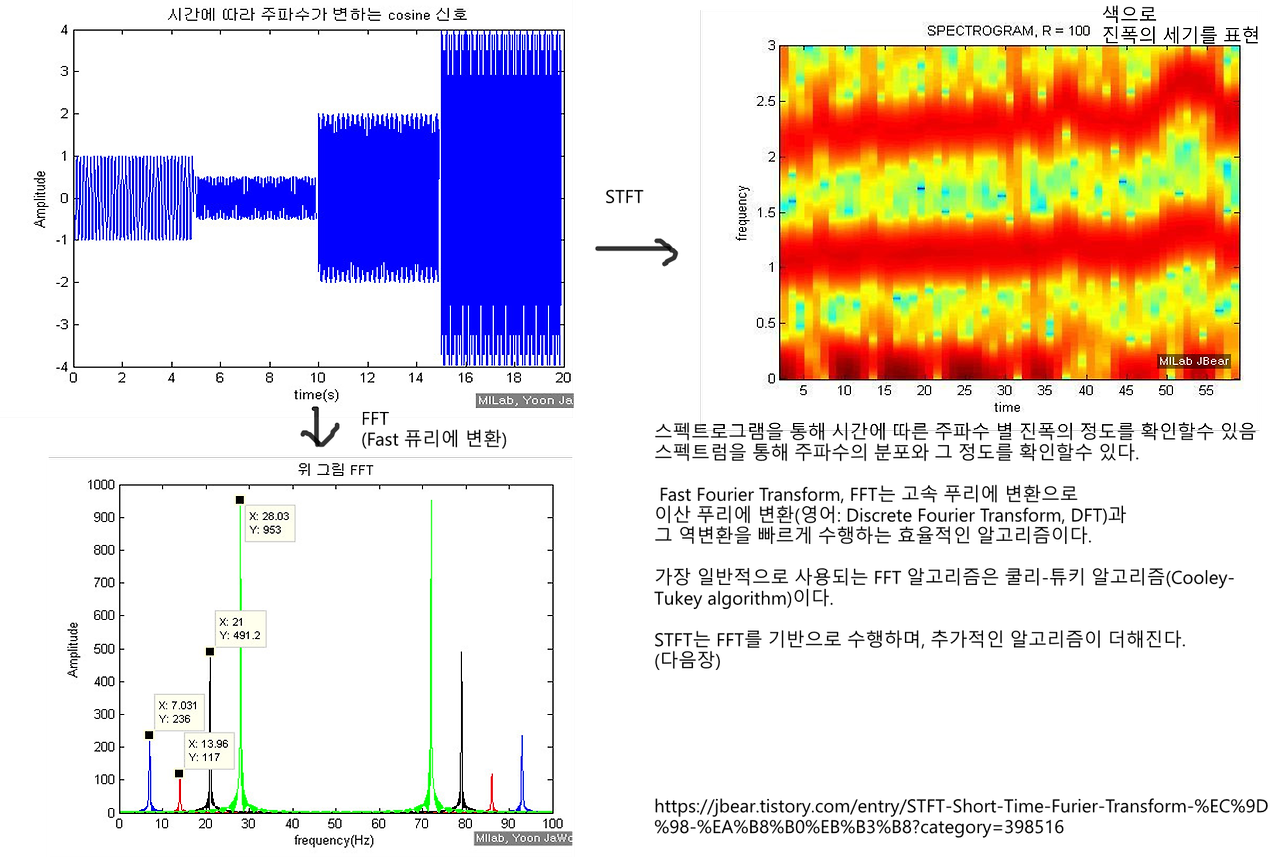
위 사진은 코사인 신호를 고속 푸리에 변환한 뒤, STFT 를 통해 스펙트로그램을 추출한 모습.
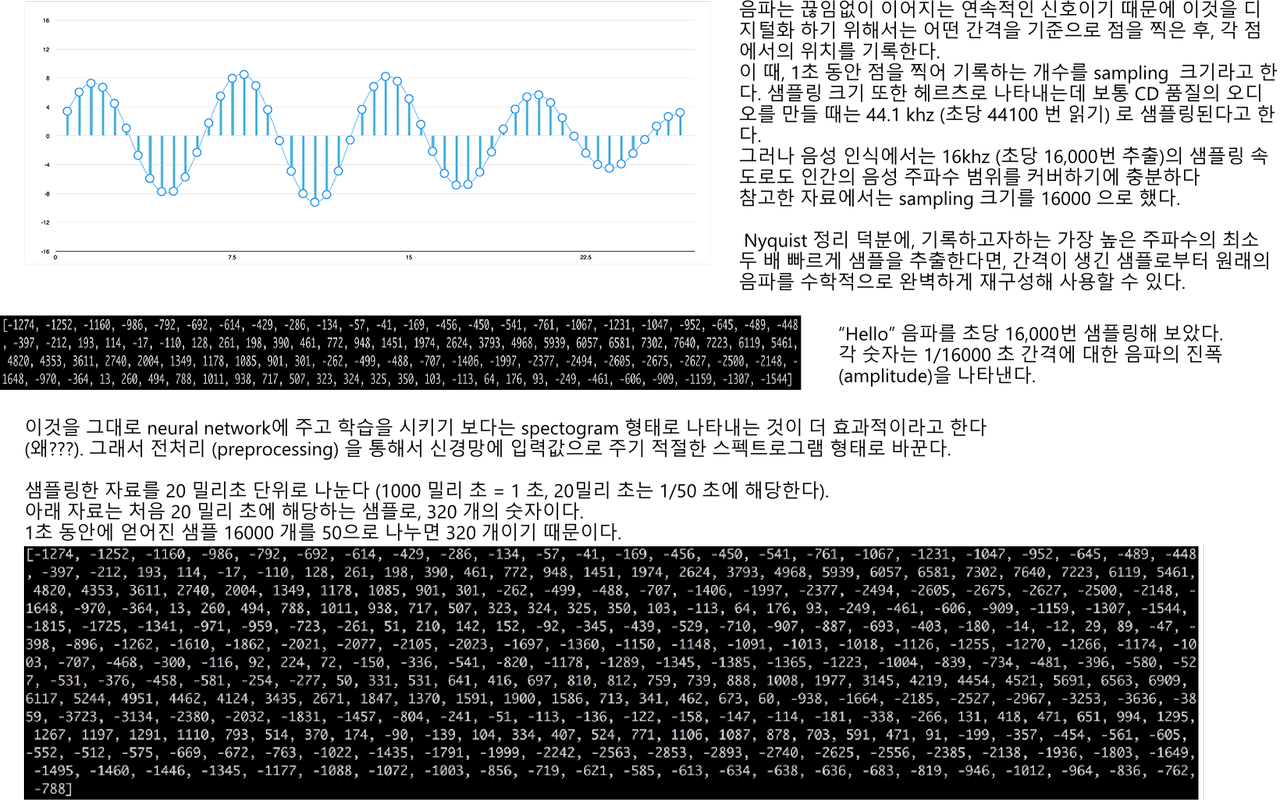
분석하고자 하는 음파를 스펙트로그램 형태로 나타내 신경망에 입력값으로 줌.. (과정 매우 생략) 그럼 다음과같이 "hello"라는 샘플 데이터에 대한 전체 음향 스펙트로그램을 얻을 수 있다.
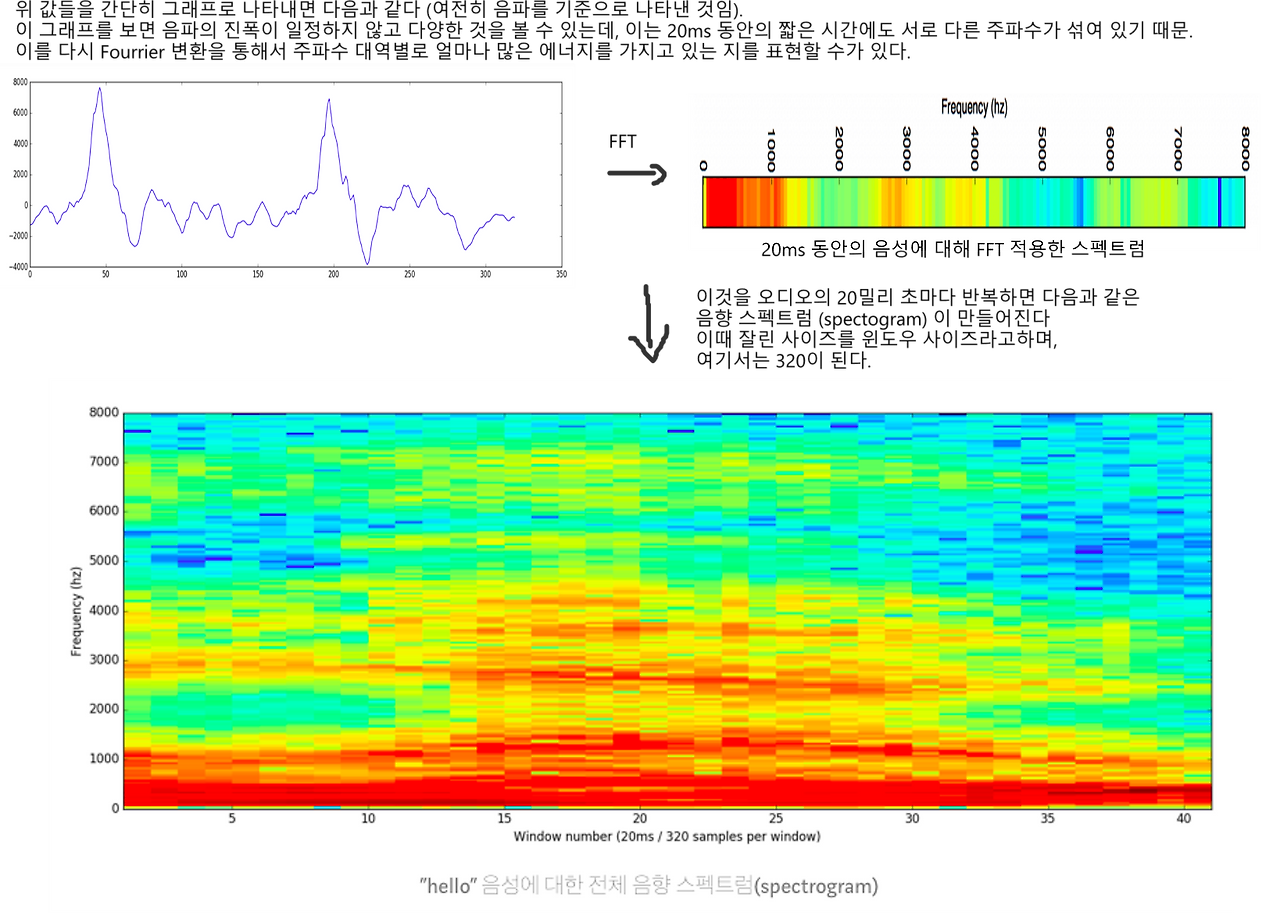
사실 이런 복잡한 알고리즘 사용 없이 간단히 스펙트로그램을 얻을 수 있는 방법이 존재한다.
Python을 사용할 예정이라면 Librosa라는 라이브러리를 사용해보자. Python에서는 Librosa라는 라이브러리를 이용하여 쉽게 STFT와 spectrogram을 계산할 수 있다.
import os
import numpy as np
import librosa
import librosa.display
import matplotlib.pyplot as plt
x = librosa.load('/Desktop/train/train_00000.wav',16000)[0]
y = librosa.stft(x, n_fft=128, hop_length=64, win_length=128)
magnitude = np.abs(y)
log_spectrogram = librosa.amplitude_to_db(magnitude)
plt.figure(figsize=(10,4))
librosa.display.specshow(log_spectrogram, sr=16000, hop_length=64)
plt.xlabel("Time")
plt.ylabel("Frequency")
plt.colorbar(format='%+2.0f dB')
plt.title("Spectrogram (dB)")stft함수의 파라미터
x: input wavfile
n_fft: fft point
hop_length: shift size
win_length: frame length
window: default: 'hann'
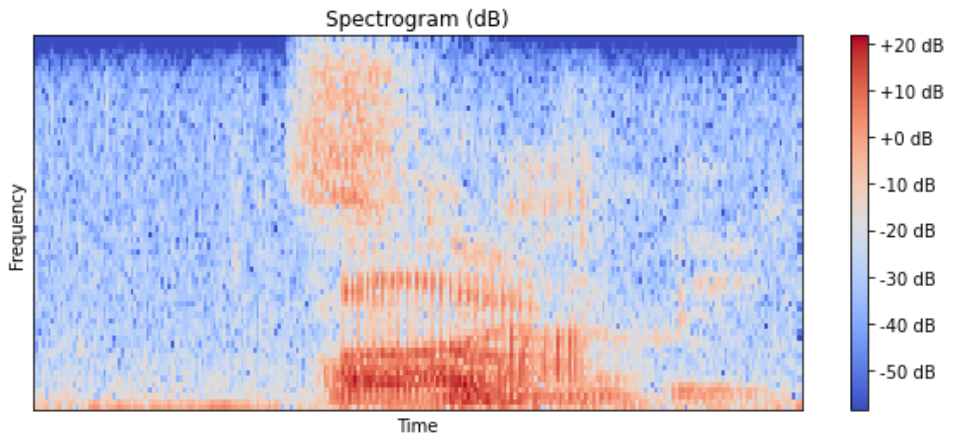
함수를 실행하면, 다음과 같은 결과창을 얻을 수 있다. 코드 출처
개념적인거 이론적인거 다 알겠는데 그래서 왜 음성인식, 음성분류의 과정에서 왜 STFT를 사용하는지 의문이 들 수 있다.
간단하게, 음성의 특성들은 시간에 따라 변하게 된다. 만약 long-term signal이 시간에 따라서 자꾸 변한다면(= non-stationary 하다면) processing을 할 수 없어진다.
그렇다고해서 long-term signal의 통계적 특성이 샘플 단위로 급격하게 변화하고 그러진 않는다. 그래서 대부분은 "speech signal의 특성이 상대적으로 느리게 변한다고 가정하고, 짧은 시간간격 안에서는 stationary하다."고 가정한다.
그렇기 때문에 ! 짧은 시간 간격으로 나누는 framing과정을 거쳐서 short-time에 대한 processing을 하게된다. 이게 왜 STTF를 사용하는지에 대한 대답이다.
오케이~?

???: 오케이 ~~
추가적으로 도움이되는 유튜브 강의 공유해드립니닷
- https://www.youtube.com/watch?v=Z7YM-HAz-IY&list=PLhA3b2k8R3t2Ng1WW_7MiXeh1pfQJQi_P
- https://www.tensorflow.org/hub/tutorials/yamnet?hl=ko
그럼 다음 포스트에서 만나뵙시다.
아녕!
