
01-1. 시간 복잡도 표기법 알아보기
- 시간 복잡도 : 주어진 문제를 해결하기 위한 연산 횟수
📌시간 복잡도 정의하기
📏시간 복잡도 유형
| 이름(표기) | 의미 | 시간 복잡도 |
|---|---|---|
| 빅-오메가 ((n)) | 최선일 때(best case)의 연산 횟수를 나타낸 표기법 | 1번 |
| 빅-세타 ((n)) | 보통일 때(average case)의 연산 횟수를 나타낸 표기법 | N/2번 |
| 빅-오 (O(n)) | 최악일 때(worst case)의 연산 횟수를 나타낸 표기법 | N번 |
❗코딩테스트에서는 빅-오 표기법(O(n)) 기준으로 수행 시간을 계산하는 것이 좋다.
→ WHY? 최악일 때(worst case)를 염두에 둬야 하기 때문!
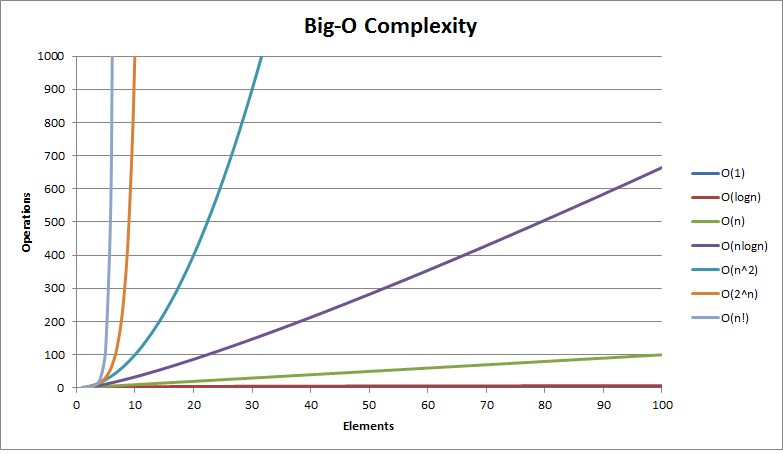
📌빅-오 표기법(O(n))의 시간 복잡도
- 시간 복잡도가 데이터 크기(N)의 증가에 따라 성능(수행 시간)이 다르다.
✖️IT 5분 잡학사전 #24 - 알고리즘의 속도는 어떻게 표현할까?
- N : 알고리즘으로 작업을 완료할 때까지 걸리는 절차 수
- 예) O(N), O(log N)
"선형 검색 알고리즘은 배열의 길이가 N일 때 총 N번 검색하는 과정이 필요하다." 라고 말하는 것보다 "선형 검색 알고리즘의 시간 복잡도는 O(N)이다." 라고 말하는 게 더 간단하다.
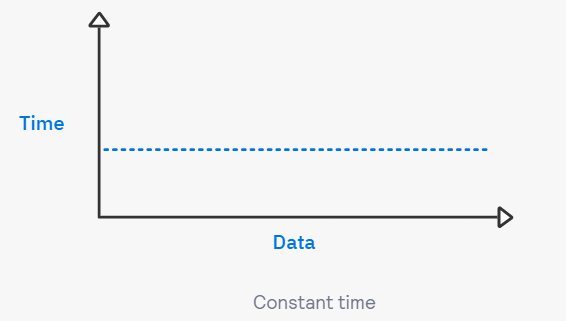
예시 #1 상수 시간(Constant time)
- 배열 arr의 첫번째 데이터를 출력하는 코드
def print_first(arr):
print(arr[0])→ 배열의 길이와 상관없이 딱 1번 실행하고 끝난다. 시간 복잡도 O(1)
= '상수 시간(constant time) 내에 실행된다'
⭐상수 시간(constant time) : 이미 실행 횟수가 고정으로 정해진 것
- 배열 arr의 첫번째 데이터를 2번 출력하는 코드
def print_first(arr):
print(arr[0])
print(arr[0])→ 위의 경우와 마찬가지로 O(1)이라고 표현
WHY? Big-O는 실행 단계에 영향을 주는 요소만 보기 때문이다!
⭐배열의 길이가 길어져도 시간은 항상 같다. 그래서 같다는 의미로 "1"을 사용한다.
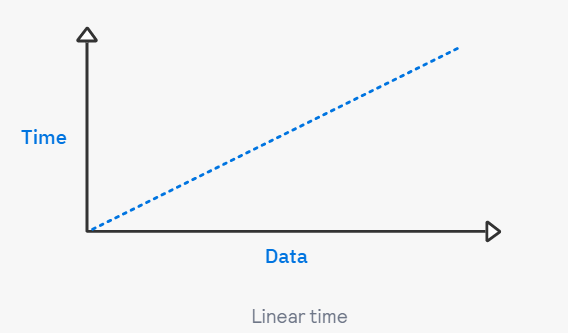
예시 #2 선형 시간(Linear time)
- 배열 arr의 모든 데이터를 출력하는 코드
def print_first(arr):
for n in arr:
print(n)→ 배열의 길이에 따라 실행 시간이 달라진다. 시간 복잡도 O(N)
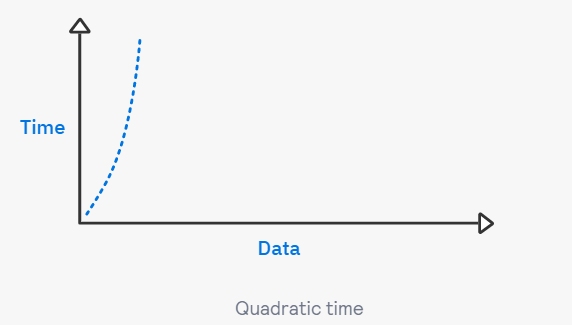
예시 #3 이차 시간(Quadratic time)
- 배열 arr의 모든 데이터를 중첩 반복문으로 출력하는 코드
def print_first(arr):
for n in arr:
for x in arr:
print(x, n)→ (1,1)부터 (100,100)까지 총 10,000번 출력한다. 시간 복잡도 O(N)
01-2. 시간 복잡도 활용하기
📌알고리즘 선택의 기준으로 사용하기
✏️연산 횟수 계산 방법
연산 횟수 = 알고리즘 시간 복잡도 N값에 데이터의 최대 크기를 대입하여 도출
- 연산 횟수는 1초에 2,000만 번 연산하는 것을 기준으로 생각한다.
- 시간 복잡도는 항상 최악일 때, 즉 데이터의 크기가 가장 클 때를 기준으로 한다.
조건 : 시간 제한 = 2초
⇒ 조건을 만족하려면 2 * 2,000만 번 = 4,000만 번 이하의 연산 횟수로 문제를 해결해야 한다.
✏️알고리즘 적합성 평가
버블 정렬(O(N)) = (1,000,000) = 1,000,000,000,000 > 40,000,000 ⇒ 부적합
병합 정렬(O(NlonN)) = 1,000,000log(1,000,000 = 약 20,000,000 < 40,000,000 ⇒ 적합
- 문제에 주어진 시간 제한이 2초이므로 연산 횟수 4,000만 번 안에 원하는 답을 구해야 한다.
- 병합 정렬이 문제를 풀기에 적합한 알고리즘이라고 판단할 수 있다.
❗시간 복잡도 분석으로 문제에서 사용할 수 있는 알고리즘을 선택할 수 있고, 데이터의 크기(N)로 사용해야 하는 알고리즘을 추측해볼 수 있다.
📌시간 복잡도를 바탕으로 코드 로직 개선하기
- 시간 복잡도는 작성한 코드의 비효율적인 로직(logic)을 개선하는 바탕으로도 사용 가능하다.
⇒ 이 부분을 활용하려면 가장 먼저 코드의 시간 복잡도를 도출할 수 있어야 한다.
✏️시간 복잡도 도출 기준
① 상수는 시간 복잡도 계산에서 제외한다.
② 가장 많이 중첩된 반복문의 수행 횟수가 시간 복잡도의 기준이 된다.
예제1 : 연산 횟수 = N
N = 100000
cnt = 1
for i in range(N):
print("연산 횟수 " + str(cnt))
cnt += 1예제2 : 연산 횟수 = 3N
N = 100000
cnt = 1
for i in range(N):
print("연산 횟수 " + str(cnt))
cnt += 1
for i in range(N):
print("연산 횟수 " + str(cnt))
cnt += 1
for i in range(N):
print("연산 횟수 " + str(cnt))
cnt += 1
⇒ 두 예제 코드의 연산 횟수는 "3배"
❗코딩 테스트에서는 일반적으로 상수를 무시하기 때문에 두 코드의 시간 복잡도는 O(N)으로 같다!
예제3 : 연산 횟수 = N
N = 100000
cnt = 1
for i in range(N):
for j in range(N):
print("연산 횟수 " + str(cnt))
cnt += 1⭐시간 복잡도는 가장 많이 중첩된 반복문을 기준으로 도출
⇒ 예제3에서는 "이중 for문"이 전체 코드의 시간 복잡도 기준이 된다.
❗일반 for문이 10개 더 있다고 해도 기준 ②에 따라 시간 복잡도는 N으로 유지된다.
