
Airflow는 DAG를 작성하여 태스크 파이프라인을 적성할 때, BashOperator 및 PythonOperator와 같은 일반적인 오퍼레이터를 많이 사용합니다.
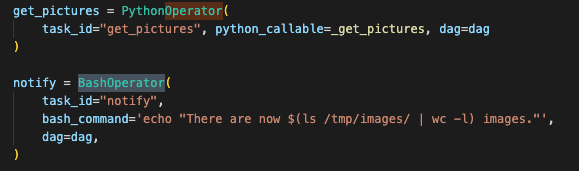
그러나 이것만으로는 충분하지 않고 더욱 구체적인 목적을 위한 오페레이터를 제공합니다.
이러한 구체적 목적을 위한 오퍼레이터는 지정된 그 목적의 기능만을 제공하며 직접 구현하여 사용가능합니다.
이러한 특수한 목적의 오퍼레이터를 사용하여 외부시스템과 airflow가 통신하는 방법을 알아봅시다.
책은 아래 2개를 들어 설명하고 있습니다.
- AWS S3 버킷 및 머신러닝 모델을 개발 및 배포하기 위한 AWS SageMaker를 사용해 머신러닝 모델을 개발하고
- Airbnb 숙소 내용의 Postgres 데이터베이스를 사용해 다양한 시스템 간의 데이터를 전달한다.
두 예시는 결국 이 2가지를 말하고자합니다. 그럼 어떻게 할 수 있다는 건지 알아보도록 합시다.
- airflow를 외부시스템과 연동하기
- 시스템 간 데이터 이동하기
이를 이해하기 위해 우선 AWS S3 버킷에 대해 간단히 알아보자.
AWS S3란
객체 스토리지 저장소로 쉽게 말해 데이터 자장소 입니다.
1. airflow를 외부시스템과 연동하기
AWS와 같은 클라우드 서비스를 사용하기 위해서는 apache-airflow 파이썬 패키지의 필수 오퍼레이터 이외의 클라우드 공급자가 제공하는 패키지를 설치해야합니다.
# AWS
pip install apache-airflow-providers-amazon
# GCP
pip install apache-airflow-providers-google
# Azure
pip install apache-airflow-providers-microsoft-azure여기서는 MNIST(http://yann.lecun.com/exdb/mnist) 데이터 세트를 훈련하여 손글씨를 분류하는 모델을 만들고자합니다.

모델의 학습 과정과 분류 과정을 보여주는 이미지입니다.
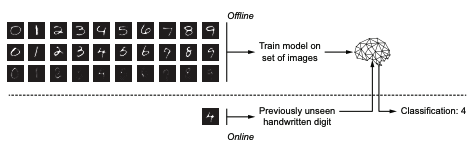
오프라인과 온라인으로 나뉘어지는데.
- 오프라인 : 모델 학습 & 학습 결과(모델 파라미터) 저장 👉 train
- 온라인 : 새로운 데이터를 가지고 모델이 숫자를 분류 👉 test
Airflow 워크플로는 오프라인(train) 부분을 담당합니다.
즉, 모델학습을 위한 전반적인 플로우를 Airflow로 생성,모니터링,학습 하는 것입니다.
또한, 새로운 데이터가 추가로 들어오거나 더 나은 모델 성능을 위해 모델 재학습 등을 할 때에도 Airflow의 배치 프로세스 기능을 사용하면 되기에 적합합니다.
↔️ 온라인 (test)는 주로 REST API 호출을 통한 웹페이지로 진행됩니다. 이러한 API 배포는 CI/CD 파이프라인으로 진행하는 경우가 많으며 매번 API를 다시 배포하는 요구사항은 없으므로 Airflow 워크플로우에는 포함되지 않습니다.
지금부터 오프라인을 train, 모델 학습이라고 부르겠습니다.
다시 본론으로 돌아와서,
Airflow을 사용하여 모델을 학습하기위한 파이프라인이 어떻게 되는지 알아보겠습니다.
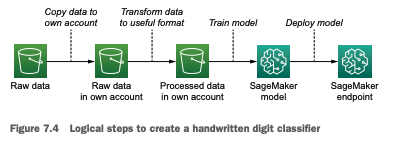
Airflow 분류기 모델 학습 과정입니다.
각 과정을 차근차근 알아봅시다.
위 그림을 보면 "->" 화살표가 각 과정이므로 총 4단계의 과정입니다.
1단계) 본인 계정으로 데이터 복사
2단계) 모델 입력형식으로 데이터 변환
3단계) 모델 학습
4단계) 학습된 모델 배포
이 4단계를 4개의 테스크로 구분해 DAG py파일을 보면 다음처럼 파이프라인을 구성한 것을 볼 수 있습니다.
download_mnist_data >> extract_mnist_data >> sagemaker_train_model >> sagemaker_deploy_model
1단계) 본인 계정으로 데이터 복사 (download_mnist_data)
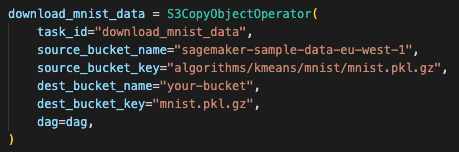
- S3CopyObjectOperator()
👉 특정버킷의 오브젝트를 다른곳으로 복사하기위한 오퍼레이터 - source_bucket_name="sagemaker-sample-data-eu-west-1"
👉 "sagemaker-sample-data-eu-west-1" 버킷을 복사하겠다. - source_bucket_key="algorithms/kmeans/mnist/mnist.pkl.gz"
👉 "algorithms/kmeans/mnist/mnist.pkl.gz" 오브젝트(데이터 파일)를 복사하겠다. - dest_bucket_name="your-bucket"
👉 "your-bucket" 버킷에 복사할거야. - dest_bucket_key="mnist.pkl.gz"
👉 "mnist.pkl.gz" 오브젝트로 복사할거야.
2단계) 모델 입력형식으로 데이터 변환 (extract_mnist_data)
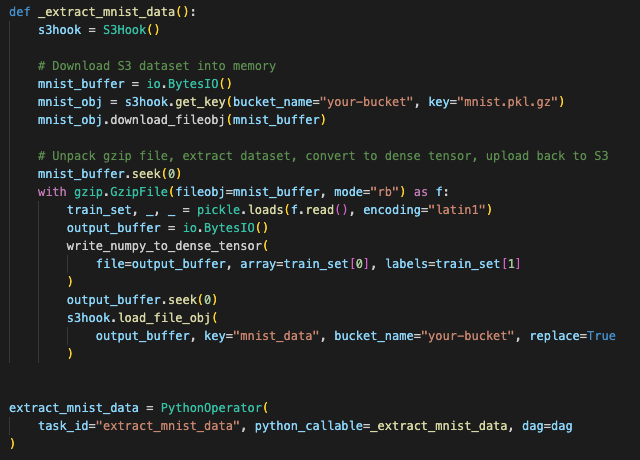
airflow에 데이터 변환 기능의 오퍼레이터는 없으므로 원하는 기능을 직접 구현함.
👉 PythonOperator로 파이썬 함수 '_extract_mnist_data'를 호출합니다.
- s3hook = S3Hook()
👉 S3상 운영을 위해 S3Hook을 사용. - mnist_obj = s3hook.get_key(bucket_name="your-bucket", key="mnist.pkl.gz")
👉 S3 오브젝트 다운 - s3hook.load_file_obj(output_buffer, key="mnist_data", bucket_name="your-bucket", replace=True)
👉 추출된 데이터를 S3로 다시 업로드합니다. "your-bucket"이라는 버킷에 "mnist_data" 오브젝트를 올려줘
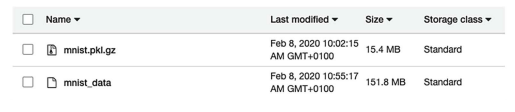
3단계) 모델 학습 (sagemaker_train_model)
-
SageMakerTrainingOperator()
👉 sagemaker의 학습 작업을 생성합니다.
sagemaker는 특징적인 설정이 필요하고 이를 설정인수로 입력합니다. -
config.TrainingJobName
👉 TrainingJobName은 AWS 계정 & 리전 내에서 교유해야합니다.
그래서, 동일한 TrainingJobName으로 오퍼레이터를 두 번 실행하면 오류가 납니다.

따라서, 이러한 오류를 피하고자TrainingJobName에 execution_date를 이용해 기존 학습 테스크와 이름이 충돌하지 않게합니다.
또한 execution_date를 사용하면 한번 생성한 모델 학습 방식(소스, 설정인수)를 계속해서 사용하게되는데 (템플릿) 이 때 자동으로 날짜를 채번해서 생성하므로 소스를 수정해야하는 번거로움도 없습니다. -
wait_for_completion
👉 False : 단순히 명령만 실행 (태스크 완료 여부 체크 x)
True : 명령 실행 & 태스크 완료 여부 확인다운스트림 작업이 있거나 파이프라인 정상 동작과 순서에 맞게 실행이 필요한 경우 SageMaker의 작업이 완료된 후 다음 작업이 실행될 수 있도록 wait_for_completion=True를 통해 주어진 작업의 완료될 때까지 기다리게해야합니다.
-
check_interval
👉 태스크 완료 여부를 체크하는 주기입니다.
내부적으로는 check_interval 정의된 초마다 태스크가 실행중인지 확인하여 작업 완료여부를 확인합니다.
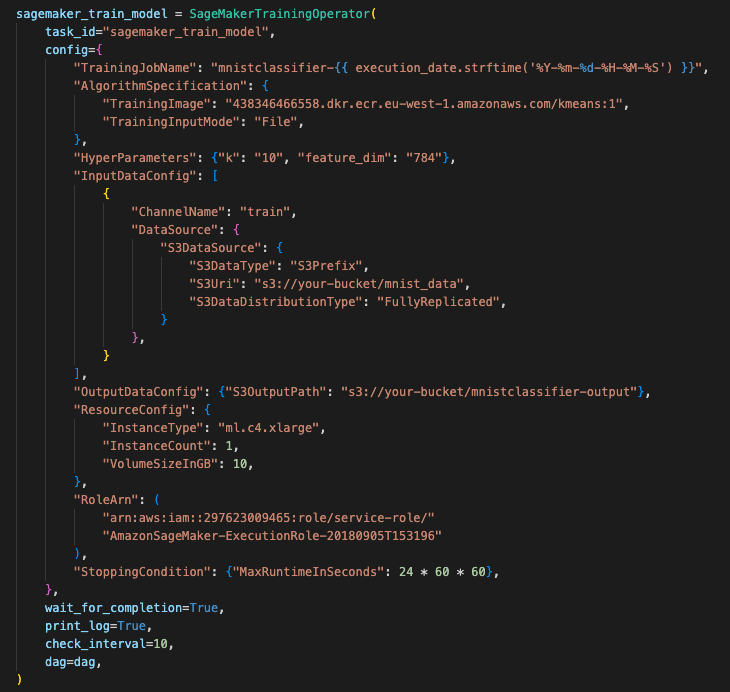
4단계) 학습된 모델 배포 (sagemaker_deploy_model)
학습된 모델을 Endpoint로 배포합니다.
모든 단계가 마무리되고

전체 파이프라인이 완료되면 SageMaker 모델과 엔드포인트가 성공적으로 배포된 것을 볼 수 있습니다.
이렇게 모델 학습을 위한 전처리부터 모델 배포까지의 과정을 Airflow로 진행하는 방법 train(오프라인)을 알아보았습니다.
이제 이렇게 학습된 모델을 사용해 예측(test,온라인)하는 방법은 어떻게 진행될까요? 🧐
학습된 모델을 사용해 예측(test,온라인)
SageMaker의 엔드포인트는 AWS API 등을 사용해 접근할 수 있지만, 외부에서는 접근이 불가합니다. 따라서 외부에서 접근할 수 있는 인터페이스나 API를 만들기 위해서는 SageMaker 엔드포인트를 트리거하는 AWS Lambda를 개발 및 배포하고 API를 생성 및 연결해 외부에서 접속할 수 있는 HTTP 엔드포인트를 만듭니다.
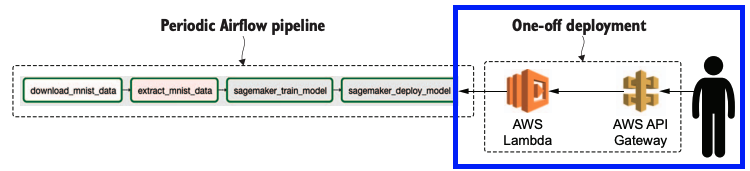
한번에 인프라 배포도 코드로 구성해서 배포하면 되지 않을까요? 🧐
Lambda 및 API Gateway는 한번만 배포하면 되기 때문에 굳이 주기적으로 재실행되는 파이프라인에 넣을 필요가 없는 겁니다.
이러한 API 작업은 완성도를 높이기위해 Chalice로 구현됩니다.
Chalice란?
Python 기반의 Serverless Microframework 입니다.
AWS Lambda 및 Amazon API Gateway를 통해 개발자들이 확장성에 대한 걱정 없이 손쉽게 API 애플리케이션을 만들어 낼 수 있습니다.response = runtime.invoke_endpoint( # SageMaker 엔드포인트 호출 EndpointName="mnistclassifier", ContentType="application/x-recordio-protobuf", Body=numpy_to_record_serializer()(img_arr.flatten()), ) # SageMaker 응답을 반환합니다. result = json.loads(response["Body"].read().decode("utf-8")) return Response( result, status_code=200, headers={“Content-Type”: “application/json”},# 손글씨 이미지를 분류하기 위해 API에 이미지를 전달하빈다. curl --request POST \ --url http:/ /localhost:8000/ \ --header 'content-type: image/jpeg' \ --data-binary @'/path/to/image.jpeg'
이렇게 모델을 학습하는 과정을 Airflow 파이프라인으로 진행하는 게 좋은 이유가 무엇일까요? 🧐
Airflow 파이프라인로 모델 학습하는 이유
- 파이프라인을 스케줄링하기 편하다.
- 원하는 경우 새 데이터나 모델 변경시 파이프라인을 재실행할 수 있다.
- 로우 데이터가 지속적으로 업데이터되는 경우 Airflow의 파이프라인은 주기적으로 로우 데이터를 다시 로드하고 새로운 데이터로 모델을 훈련하고 재배포할 수 있다.
- 원하는 대로 모델을 조정할 수 있다.
- 모델을 자동으로 재배포 가능
즉, 전반적 스케줄링 & 모델 학습과 배포 자동화 & 자동화를 통한 지속적인 업데이트 가 가능하다.
Airflow는 기능을 극대화하기 위해 여러 외부 플랫폼과 협업하여 사용이 가능하다.
대표적으로 클라우드의 강자 AWS 플랫폼과도 연동이 가능합니다.
# AWS 오퍼레이터
pip install apache-airflow-providers-amazonAWS 외부 시스템을 사용할 때
로컬에서 Airflow 태스크를 실행해도 AWS 클라우드의 리소스를 액세스할 수 있으려면 AWS 액세스 키를 통해 인증을 미리 해두어야합니다.
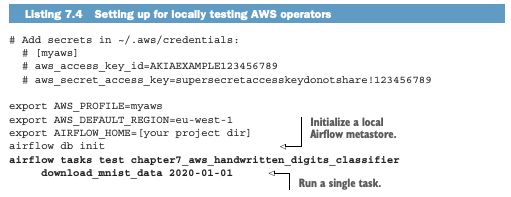
본인의 AWS 액세스 키를 로컬 pc에 기입해야함.
기본 설정이 선행되어야합니다.
이제 여기까지 예시의 1. AWS S3 버킷 및 머신러닝 모델을 개발 및 배포하기 위한 AWS SageMaker를 사용해 머신러닝 모델을 개발 하는 방법에 대하여 알아보았습니다.
이제 예시 2. Airbnb 숙소 내용의 Postgres 데이터베이스를 사용해 다양한 시스템 간의 데이터를 전달한다. 를 알아보겠습니다.
2. 시스템 간 데이터 이동하기
Airflow는 정기적인 ETL을 위한 툴이며 ETL을 위한 강력한 기능을 제공합니다.
ETL 과정에서 생긴 데이터를 다른곳에 보내고 나중에 처리할 수 있도록 저장하는 작업 또한 진행합니다.
이렇게 주기적으로 데이터를 내보내고 저장해 나중에 처리할 수 있도록 하는 Airflow로 오케스트레이션하는 방법에 대해 알아봅시다.
다음 예제는
Airbnb 데이터를 추출 -> S3 버킷 저장 -> 도커 컨테이너에서 Pandas를 사용해 데이터 처리
하는 과정을 통해 airflow 오케스트레이션을 알아보고자합니다.
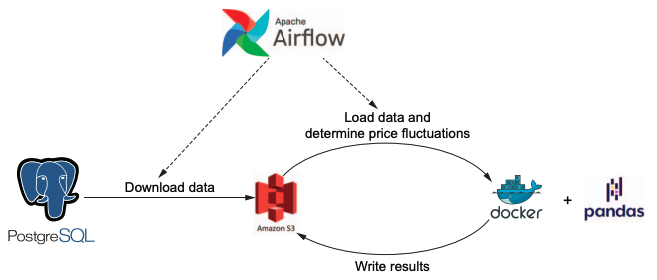
Airbnb 데이터를 추출 -> S3 버킷 저장
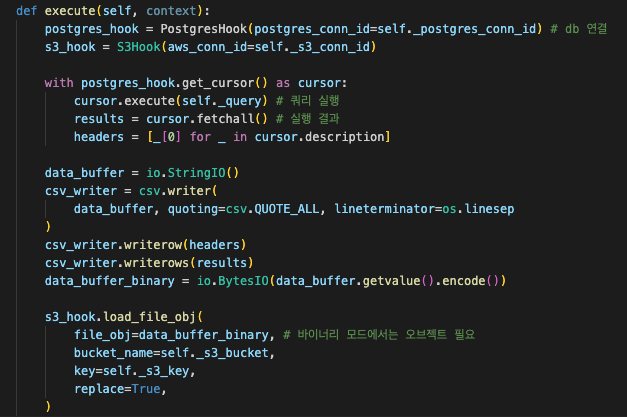
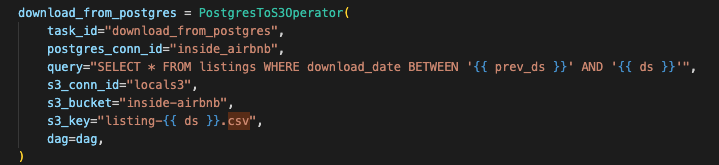
Postgres 데이터베이스에 쿼리를 실행하고 그 결과를 AWS S3 버킷에 저장합니다.
-
cursor.execute(self._query)
👉 인자로 넘어온 쿼리를 postgres 데이터 베이스에 실행한다. -
csv_writer.writerows(results)
👉 실행결과를 csv에 작성한다. -
s3_hook.load_file_obj(
file_obj=data_buffer_binary, # 바이너리 모드에서는 오브젝트 필요
bucket_name=self._s3_bucket,
key=self._s3_key,
replace=True,
)
👉 작성한 csv 파일을 s3에 업로드이렇게 생성한 커스텀 오퍼레이터는 다음처럼 사용가능합니다.

도커 컨테이너에서 Pandas를 사용해 데이터 처리
변환하여 저장한 데이터를 Pandas를 사용하여 데이터 처리하겠습니다.
이러한 데이터 처리 작업은 리소스를 많이 요할 수도 있습니다.
따라서, 리소스 사용이 큰 작업은 Airflow와 분리하여 Apache Spark와 같은 데이터 처리 프레임워크에서 작업하는 것이 좋습니다.
즉, 작업이 큰 태스크는 Airflow에 의해 태스크 실행되도록 하나 태스크 수행은 Airflow가 아닌 외부에서 수행되는 것입니다.여기에서는 도커 컨테이너를 사용하여 데이터 처리를 진행하였습니다.
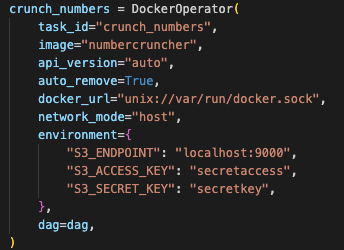
-
DockerOperator()
👉 파이썬 도커 클라이언트를 래핑하여 인수 리스트를 입력해 도커 컨테이너 실행을 시작할 수 있다. -
auto_remove=True
👉 컨테이너는 완료 후 삭제합니다. -
network_mode="host",environment={"S3_ENDPOINT": "localhost:9000"
👉 호스트 컴퓨터의 다른 서비스에 연결하려면 호스트 네트워크 모드를 사용하여 호스트 네트워크 네임 스페이스를 공유해야한다. -
image="numbercruncher"
👉 numbercruncher라는 이미지는 S3에서 Airbnb 데이터를 읽고 처리하는 pandas 스크립트를 포함하고 결과를 다시 S3에 저장하는 도커 이미지입니다.이 때 Airflow는 도커 컨테이너 시작 시키기, 로그 가져오기 및 필요한 경우 삭제 만을 관리할 뿐 직접적 태스크에 관여하지 않습니다.
📌 태스크가 멱등성을 유지하고 불필요한 찌꺼기가 남지 않도록하는 것이 중요합니다.
(가령, replace=True, 컨테이너 삭제 등)
7장 요약
- Airflow는 다양한 외부툴과 협업 가능하며 오퍼레이터를 통해 가능하다.
- 제공하지 않는 오퍼레이터는 직접 구현하여(커스텀) 사용가능하다.
- sagemakerTraininOperator와 같은 AWS는 작업 완료 여부를 주기적으로 체크 가능하며 이는 태스크 순서 및 작업 보장을 가능케한다.
- 외부에서 접근이 가능하게끔 API를 생성하여 접근이 가능하다.
