Neighborhoods Aggregation
GNN은 입력으로 그래프 구조와 각 노드별 feature 정보를 받습니다. 입력으로 받은 feature 정보와 그래프 내에서 나타나는 이웃 정보를 바탕으로 각 노드 별 vector embedding을 출력 결과로 얻어냅니다. GNN의 하나의 레이어에서 각 노드들은 그래프 상의 이웃들의 정보와 자기 자신의 정보를 이용해 embedding을 만듭니다. 예를 들어, 이웃으로 노드 B, C, D를 갖는 노드 A가 있고, GNN이 layer 하나로 이루어져 있는 경우를 생각해봅시다. 이러한 경우에 A의 embedding은 A의 feature와 함께 B, C, D의 feature에 의해서 결정됩니다. CNN에서 인접한 셀의 정보를 함께 사용하는 필터가 있는 것처럼, GNN에서는 인접한 노드들의 정보를 함께 사용하는 구조가 있다고 생각할 수 있습니다.
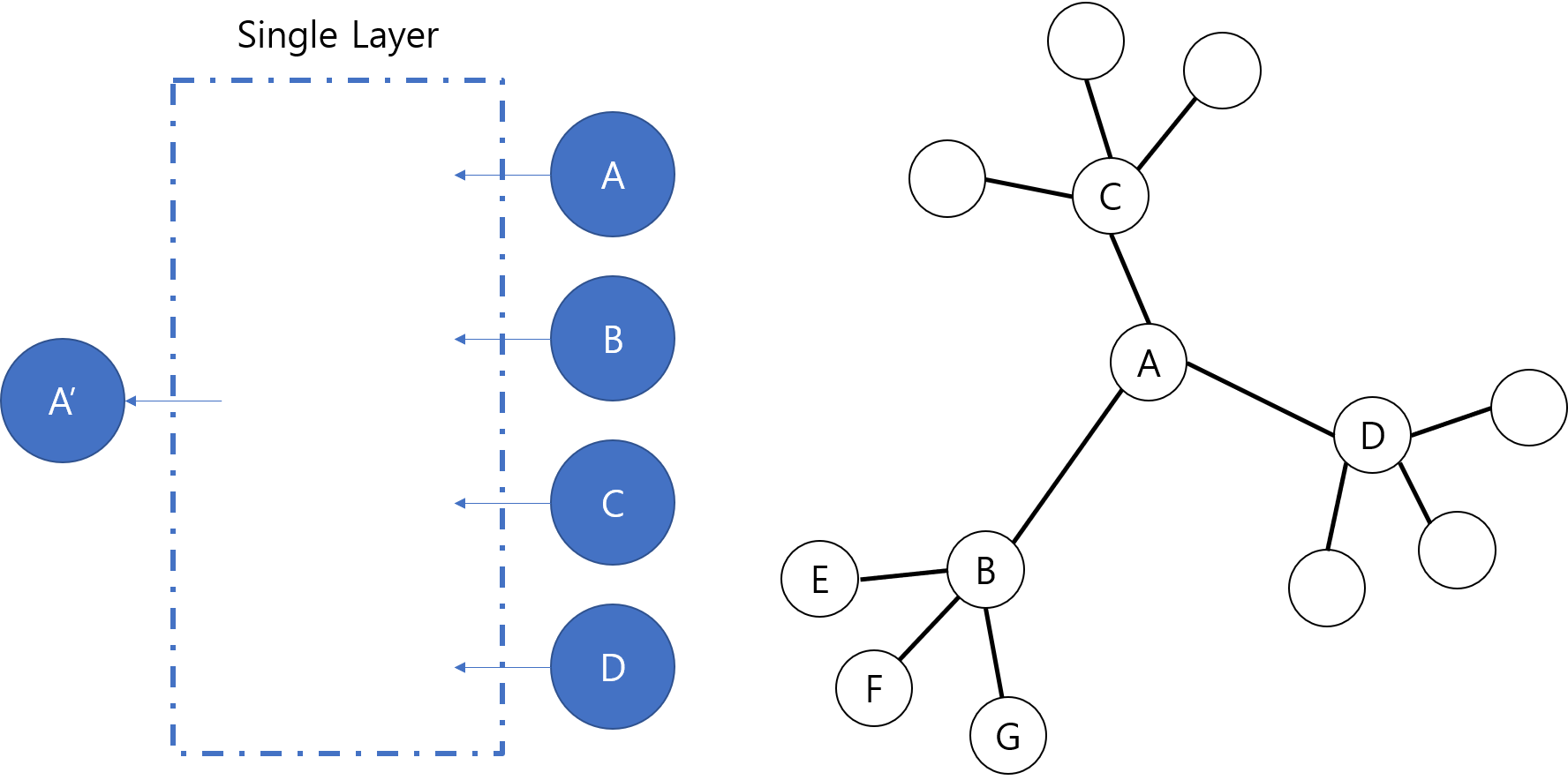
대부분의 GNN은 먼저 이웃들의 정보를 모으고, 모은 정보를 통해 얻은 새로운 값과 이전 상태의 자기 자신의 값을 이용하여 새로운 embedding을 얻어냅니다.
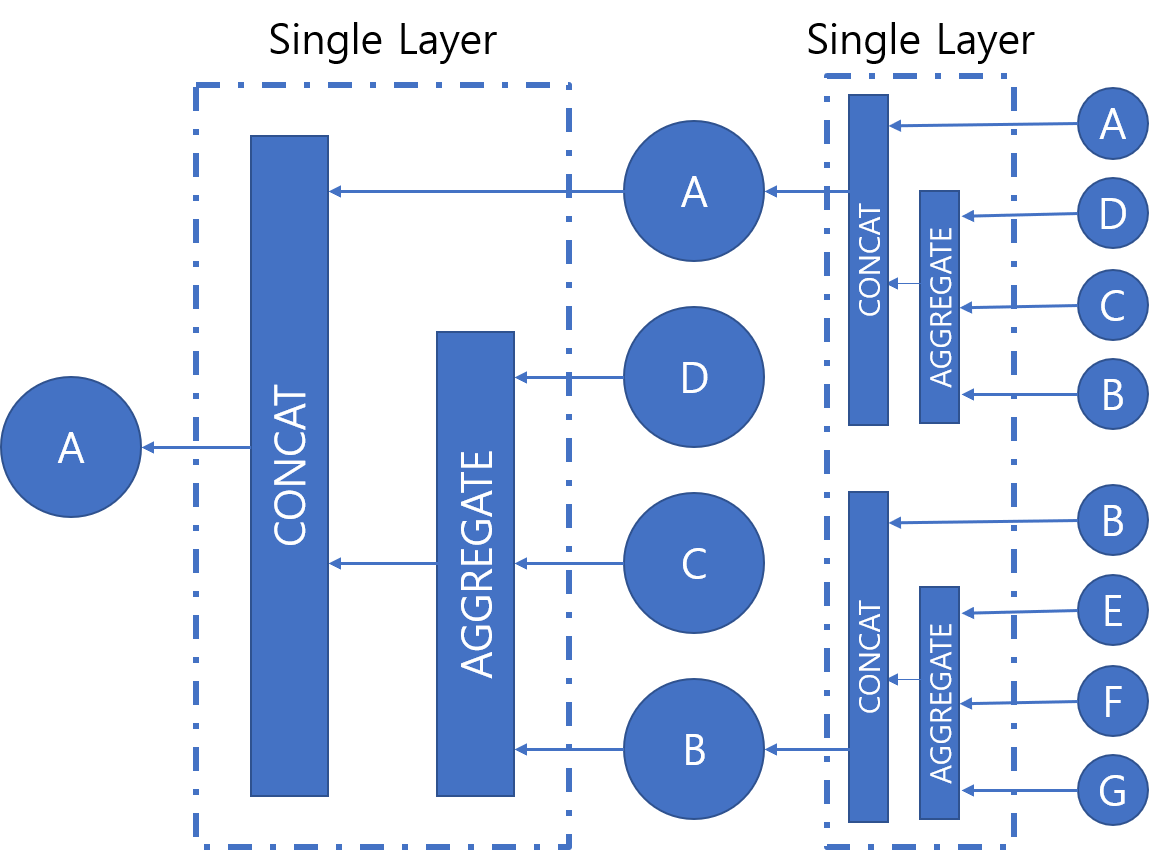

GNN Training 및 활용
앞에서는 GNN에서 중요한 개념인 Neighborhood aggregation에 대해서 다뤘습니다. 그러므로 이제 AGGREGATE와 CONCAT 함수만 알고 있다면 각 노드별로 embedding을 구할 수 있을 것입니다. 여기서는 AGGREGATE와 CONCAT 함수를 어떻게 학습하는지에 대해 알아보겠습니다.
일반적인 인공 신경망에서의 학습하는 과정은 다음과 같습니다.
학습할 인공 신경망의 구조를 정하고, input을 준비한다.
loss function을 정의하고, 어떤 optimizer를 사용할지 결정한다.
2번에서 정의한 loss function과 optimizer를 사용하여 loss가 0에 가까워지도록 신경망의 parameter를 학습한다.
GNN을 학습하는 과정도 위의 학습과정과 동일합니다.
AGGREGATE, CONCAT 함수를 정의하고, input으로 사용할 그래프를 준비한다.
loss function을 정의하고, 어떤 optimizer를 사용할지 결정한다.
loss가 0에 가까워지도록 신경망의 AGGREGATE, CONCAT 함수의 parameter를 학습한다.
optimizer는 RMSProp이나 Adam 등 일반적인 인공 신경망에서 널리 사용되는 optimizer를 그대로 사용할 수 있습니다. loss function을 정의하는 방법은 GNN을 사용하여 어떠한 문제를 풀고싶은가에 따라서 달라집니다.
첫 번째로, Node classification 문제에 GNN을 활용할 수 있습니다. supervised learning을 하는 경우에는 각 노드가 어떤 class에 속하는지에 대한 학습 데이터가 주어질 것입니다. 이러한 경우에 학습하는 방법은 일반적인 classification 문제를 푸는 것과 동일합니다. 예를 들어, loss function으로 cross entropy loss를 사용할 수 있습니다. 그래프 하나에 있는 모든 노드들을 batch로 학습한다고 생각하면 됩니다.
문자열의 각 단어의 embedding을 구하는 Word2Vec처럼 Unsupervised Learning을 사용하여 그래프 구조를 고려한 각 노드의 embedding을 구할 수 있습니다. 예를 들어서, logistic regression을 사용해서 loss function을 다음과 같이 나타낼 수 있습니다.
