MLOps 란
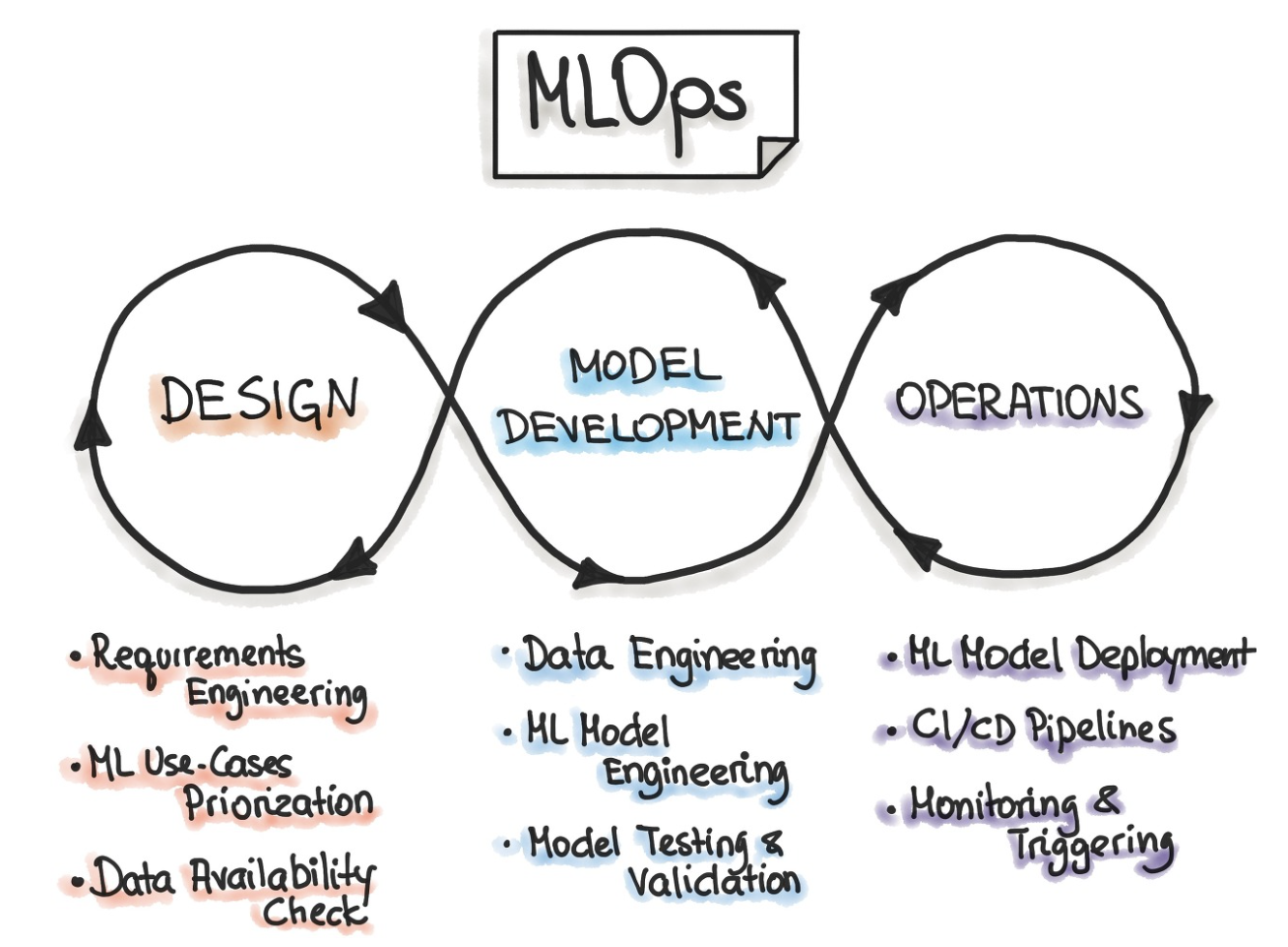
ML 프로젝트 단계
ML 기반의 프로젝트를 시작한다고 하면 크게 3단계로 나눌 수 있습니다.
1. Design
현재 요구하는 바가 무엇인지 파악하고 문제를 정의한다.
2. Model Development
문제에 대한 여럿 시험을 수행하기 위한 개발 단계, 충분한 검증이 진행
3. Operations
최종적으로 사용자에게 서비스하는 단계
MLOps 등장배경
본래 MLOps라는 개념은 아래 논문에서 처음 출연했다고 합니다.
머신러닝 딥러닝 연구자들이 MLOps에 관심을 갖는 이유
결국 ml 혹은 ai 제품을 만든다는 것은 위에 언급한 3단계를 모두 포함합니다.
학계는 사실 세 단계를 크게 신경쓰지 않죠. 이론 개념만 잘 파악해서 좋은 논문을 내는 것이 목적이었죠. 이러한 연구들이 로컬에서도 잘 수행되면 복잡한 tool들이 필요가 없습니다. 그냥 데이터가지고 구현하고 학습하고 평가하고 끝..
근데... 산업계는 달라요.. 실제 현실에 적용이 가능한가가 중요합니다.
아무리 좋은 논문을 냈다고 한들 실제 현실에서 적용이 안되면 그건.. 딥러닝 기술이 거품이라는 이야기를 듣게되죠.
따라서 딥러닝 연구 역시 상용화를 목적에 두어야 더 환경받는 연구분야인 것입니다.
모델 성능 추적의 어려움
예측 모델 하나에 대하여 DevOps 팀에서 데이터를 받아 예측값을 전달하는 API를 만들어 주었고, 며칠간 수요 예측모델을 운영한다고 가정해봅시다. 실제 운영상황에서는 외부 여러 요인들에 따라 데이터는 변하게 됩니다.
예를 들면 코로나로 인해 생수와 같은 생필품 수요량이 많이 늘어날 수 있습니다. 이러한 데이터의 변화, 모델 성능의 변화를 인지하지 못한다면, 모델은 과거의 학습된 패턴으로 수요를 예측합니다. 모델의 성능이 떨어짐을 인지하지 못하면, 수요예측에 실패하고 상품이 품절되거나 재고가 쌓이는 상황이 발생하여 비즈니스 운영에 타격을 입히게될 수 있습니다..
모델과 데이터 관리의 어려움
모델이 이상징후가 감지되면 학습에 사용된 데이터와 서빙된 데이터들이 어떤 차이가 있는지 꼼꼼히 비교해 보아야 합니다. 하지만 데이터는 계속해서 변해가고 데이터 변형과정과 모델학습 방법은 반복해서 업데이트가 이루어집니다.
과거 모델을 분석하기 위해선 학습된 데이터, 예측했던 데이터들이 필요합니다. 반복된 데이터 정제 코드의 수정과 모델 학습 코드의 변경으로 과거의 모델을 재현하고 분석하는 건 어렵습니다.
협업의 여러움
수요 예측이라는 문제 하나를 풀기 위해 실험환경을 구축하는 것부터, 모델 endpoint, 모니터링과 같은 기능은 DevOps 팀과의 협업이 필요합니다. 하지만 문제는 DevOps 엔지니어는 머신러닝 시스템을 이해하기 어렵고, 반대로 데이터 과학자는 인프라스트럭쳐 설계부터, 서비스 운영까지의 DevOps 과정을 이해하기 어렵습니다. DevOps, 데이터 과학자, 운영자들이 서로 잘 모르는 영역을 논의하고 R&R을 논의하는 것은 어렵습니다. 이렇게 힘겨운 과정을 새로운 모델을 개발할 때, 모델을 업데이트할 때마다 발생합니다.
머신러닝은 문제를 해결하는 정말 좋은 도구입니다. 하지만 머신러닝을 운영한다는 것은 위와 같이 실험만큼이나 혹은 그 이상으로 큰 노력이 필요합니다. 운영을 위한 시스템이 마련되지 않으면, 머신러닝은 더 좋은 서비스를 만드는 도구가 아니라 병목이 됩니다. 그렇기 때문에 많은 IT 회사들이 POC 단계에서 모델의 가치는 검증하지만, 실제 머신러닝을 운영까지 발전하지 못합니다.
DevOps가 주목받은 이유가 서비스를 빠르게 전달하여, 고객을 더 잘 지원하고 경쟁력을 갖춘다는 것이었습니다.
마찬가지로 MLOps는 머신러닝 시스템을 사용자에게 빠르게 전달하는 것을 목표로 합니다.
이제부터 MLOps 에 대해 자세히 알아봅시다.
MLOps 의 상세 개념
MLOps의 목표는 DevOps의 목표와 마찬가지로 사용자에게 서비스를 빠르게 전달하는 개발 문화입니다. DevOps에서는 “코드 통합, 테스트, 배포, 테스트, 모니터링” 의 파이프라인을 자동화하여 이 목표를 달성합니다. 하지만 MLOps의 파이프라인은 DevOps의 파이프라인과 의미가 상당히 다릅니다.
코드 통합
머신러닝은 기본적으로 실험이 개발입니다. 머신러닝 개발은 데이터 더미에서 유의미한 학습 데이터 만들기, 알고리즘 구현, 하이퍼 파라미터 최적화와 같은 일입니다. 이 과정에서는 원활한 실험을 위해 샘플링된 데이터를 사용하기도 하며, 최적화를 위한 다양한 시도들이 코드로 작성됩니다. 말 그대로 실험과 검증을 위한 코드가 개발됩니다. DevOps 와 달리 실험용 코드는 운영 가능한 형태가 아닙니다. 운영을 위해선 프로덕션 데이터의 ETL, 분산처리, 불필요한 로직 제거, 예측 추론 시간을 서비스 수준에 맞게 학습 단계 단순화와 같이 운영 수준의 변형과정이 필요합니다.
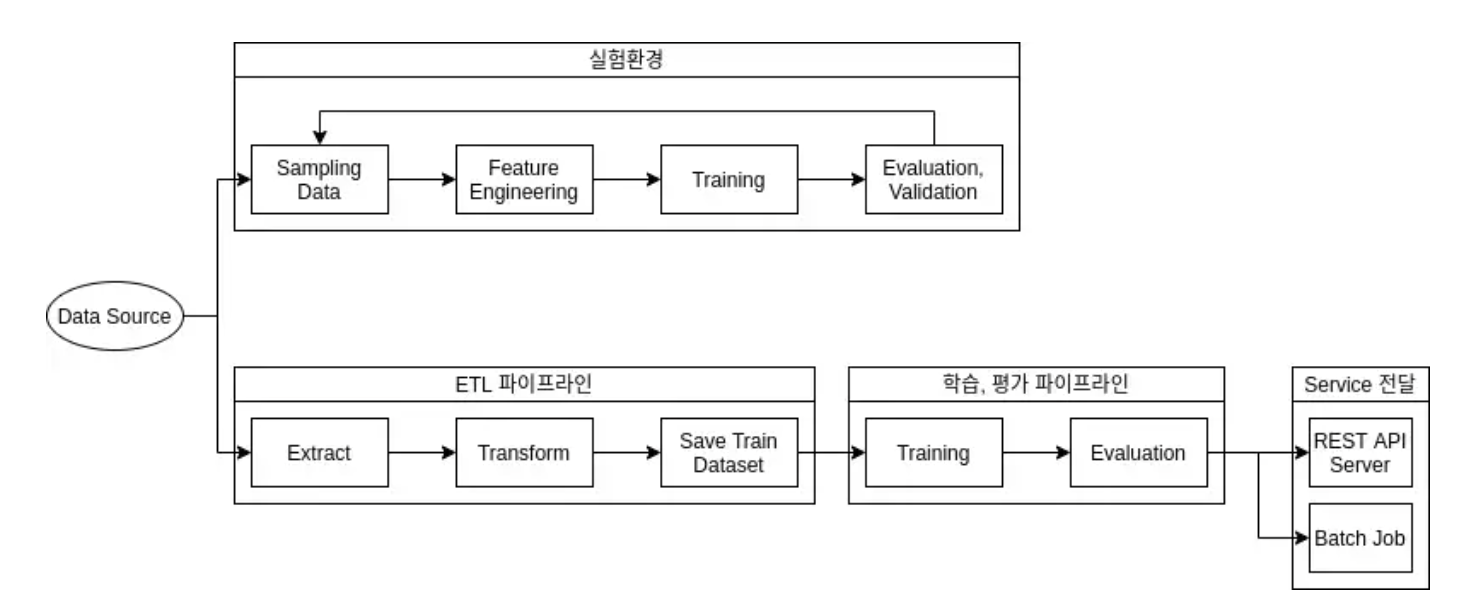
MLOps 의 통합은 실험환경에서 결정된 데이터 변형, 학습, 평가, 재학습 주기, 모니터링 지표 설정 등 실제 서비스 운영환경으로 통합되는 것을 의미합니다.
테스트
예측 모델을 단순하게 생각하면 output = model.predict(inputData) 입니다.
일반적인 소프트웨어 개발이라면 predict() 의 내부 동작을 알기 때문에, 다양한 시나리오를 만들어 테스트할 수 있습니다. 하지만 모델의 경우 내부 동작 방식을 이해할 수 없는 경우가 대부분입니다. 그렇기 때문에 output 에 대한 검증을 하기 어렵습니다. 그렇기 때문에 일반적인 소프트웨어의 유닛테스트와 같이 assert output == 0.5 와 같이 나온다고 모델이 정상이라고 판단할 수 없습니다.
따라서 모델을 테스트하기 위해선 Accuracy, Precision/Recall curve, Confusion matrix 와 같은 다양한 지표들을 활용해야 합니다.
모니터링
일반적인 소프트웨어의 경우 서버의 리소스 상태, 응답시간과 같이 명확하게 정상과 비정상을 구분할 수 있는 지표들이 있습니다. 하지만 테스트 단계와 마찬가지로 모델의 성능을 판단하는 방법은 다양하고 복잡합니다. 예를 들면 모델 endpoint 에 요청된 데이터와 예측했던 값들을 수집하고, 이것들이 학습된 데이터와 Statistical distance 를 계산하는 것입니다. 프로젝트의 목적, 알고리즘, 데이터의 특성에 따라 판단 방법은 달라질 수 있기 때문에, 어떤 방법을 사용할지 결정하는 것도 중요합니다.
배포
모델을 배포하는 건 단순히 예측 모델을 API에서 제공하는 것이 아닙니다.
MLOps 의 배포는 코드 통합, 새로운 데이터의 학습, 서비스로 모델 전달, 모니터링 방식 적용까지의 파이프라인의 배포입니다.
이 파이프라인이 배포되면 Raw data에서 모델이 서비스 전달되고 모니터링되는 과정이 동작하게 됩니다. 중요한 점은 MLOps 의 파이프라인은 일회용 아니라는 것입니다. 배포 이후 다시 모델 개발 단계로 신속하게 전환이 되어야 합니다. 이전 모델과 운영된 데이터의 분석 후 다시 통합, 학습, 전달, 모니터링이 이루어져야 합니다.
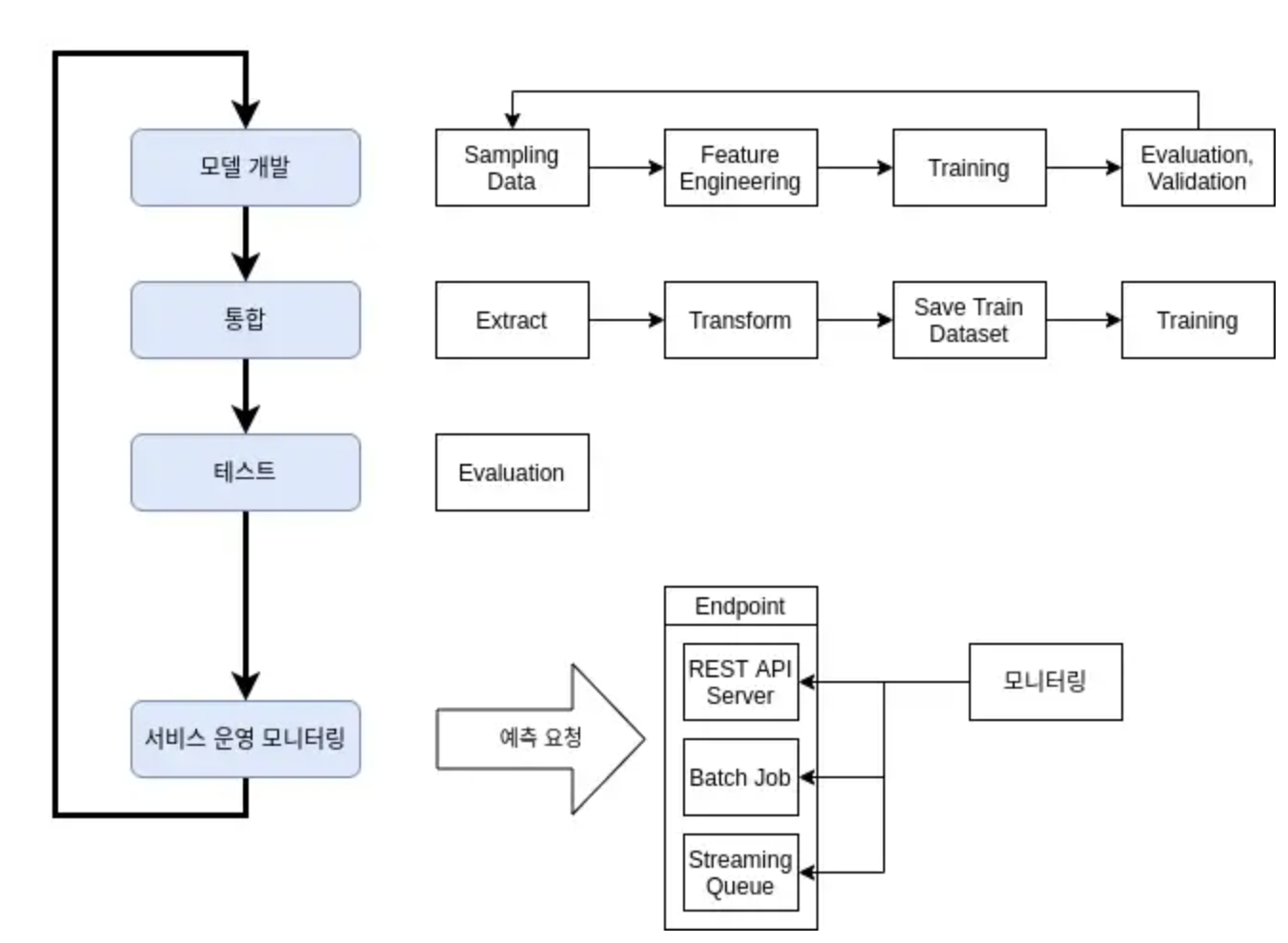
정리하자면, MLOps를 도입한다는 것을 다음과 같이 요약할 수 있습니다.
- 개발, 통합, 테스트, 운영, 모니터링 파이프라인을 운영 Infrastructure 적용
- 위 파이프라인의 Continuous Integration, Continuous Training, Continuous Delivery
- 학습 데이터와 모델, 운영 데이터의 통합적인 관리
