
DB를 하나만 사용할 경우 모든 쿼리를 해당 db에서 감당해야하니 부하가 크고
만일 DB가 문제가 생겨 다운될 경우 모든 동작이 다운되는 상황이 벌어진다.
이러한 문제를 막고자 백업본의 db를 만드는데 그것이 "데이터베이스 Replication"이다.
구성
- Master
데이터를 실질적으로 저장하는 소스 서버 - Slave
소스서버의 데이터를 복제해서 저장하는 레플리카 서버
Replication 장점
- 스케일 아웃
레플리카서버를 자유롭게 늘려 규모를 늘림으로써 트래픽 감당량이 증가함. - 데이터 백업
레플리카 서버에서 백업을 진행하여 실제 서버의 부담을 줄인다. - 용도별 서버 구축
특정 용도별로 서버를 구축할 수 있다.
Replication 종류
-
싱글 레플리카 복제
하나의 소스 서버에 하나의 레플리카 서버를 두어 소스 서버에 문제가 생길여우 레플리카 서버가 데이터를 백업하고 서버역할을 대체한다.
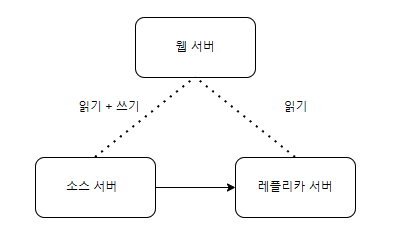
-
멀티 레플리카 복제
하나의 소스 서버에 두개의 레플리카 서버를 두고 하나는 백업용 하나는 읽기 요청 분산용이다.
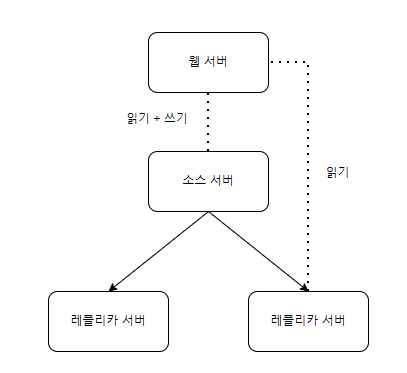
-
듀얼 소스 복제
두개의 서버가 존재하고 이는 소스이자 레플리카이다.
각 서버에서 변경한 데이터는 각 서버에 전달되어서 동일한 데이터를 유지하게 된다.
이는 Active-Active와 Active-Standby 형태로 동작이 가능하다.
이는 그냥 레플리케이션 방식과 달리 한 서버에서 문제가 생기면 바로 전환이 가능하다.
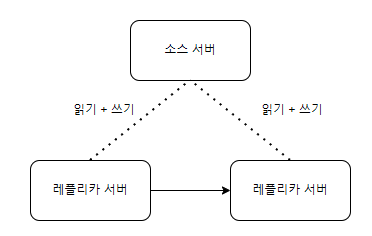
Active-Active
클러스터를 구성하는 컴포넌트들이 동시에 가동되는 방식.
하나의 저장소를 공유한다.
Active-Standby
클러스터를 구성하는 컴포넌트 중 Active만 사용하다가 장애가 생기면 Standby가 작동하는 구성
MySQL Replication
- Single Master & Single Slave
Master과 Slave 서버가 1대씩 구성되어있다.
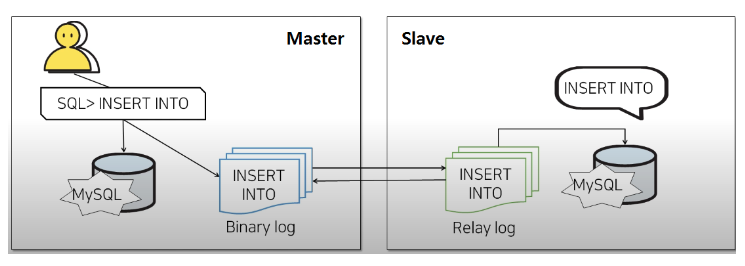
Insert, Delete, update 등의 데이터 변경을 일으키는 쿼리를 Binary log과 Relay log에 기록이 남는다.- Binary Log : Master에 실행되는 모든 DML/DDL 기록
- Relay log : Binary log에 내용을 Slave에 기록
<동작 방식>
Master에서 Client가 Query 실행 -> 데이터 변경 쿼리의 경우 Binary log 파일에 기록 -> mysql에서 query 실행 -> slave 에서는 binary log 감시하다가, 새로운 query 들어오면 해당 정보를 slave의 relay log로 가져오고자 master에게 새로운 query 요청 -> master는 slave의 요청을 받아 binary log에 적힌 쿼리를 slave에 전달하고 응답 기다림 -> slave는 master에게 query 받았다는 응답 ACK 보냄 -> master는 slave에게 ACK받으면 client에게 OK 사인 보냄
master의 변경사항이 slave에도 적용된다.
- Single Master & Multi Slave
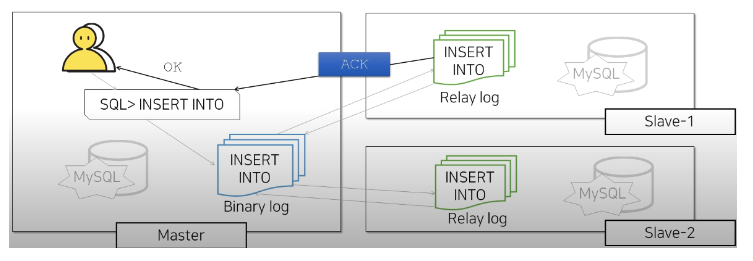
동작방식은 1. Single Master & Single Slave 과 같다.
모든 데이터 변경 쿼리는 slave로 복제해주고 응답을 기다림
한 곳의 slave에서라도 응답오면 client에게 ok 넘김 (즉, 하나의 slave를 보장해준다.)
MySQL Replication 이중화
Multi Master Replication Manager (MMM)
- Perl 기반의 Auto Failover Open Source
- MMM Monitor에서 DB서버 health check와 FAILOVER 수행
- Monitor <-> Agent 통신 방식
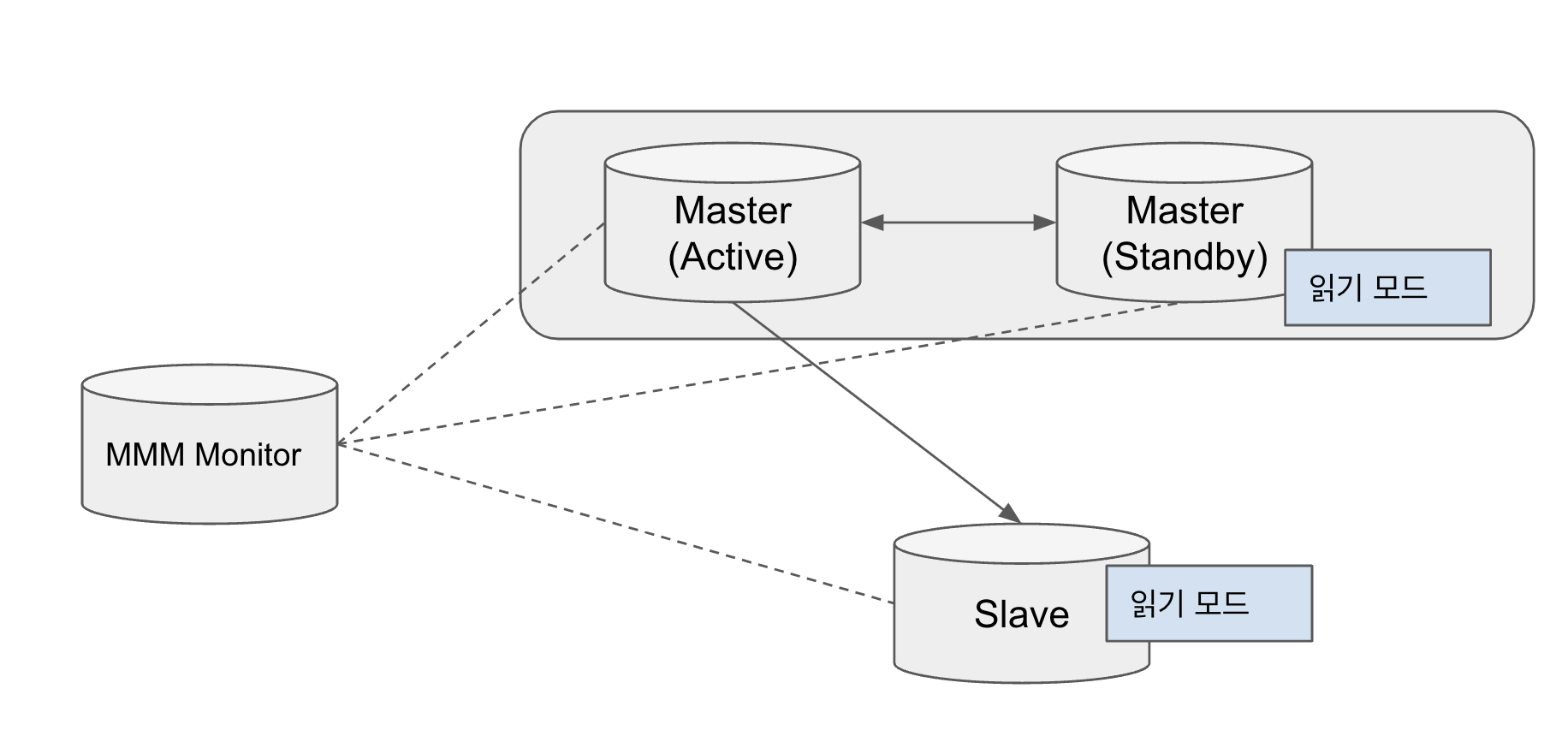
Master(Active)와 Mater(Standby)는 양방향으로 서로 복제가 가능하지만
MMM Monitor에 의해 Mater(Standby)는 읽기모드로 제어된다.
Master(Active)에서 Slave로 단뱡향 복제로 Slave를 n개 설치
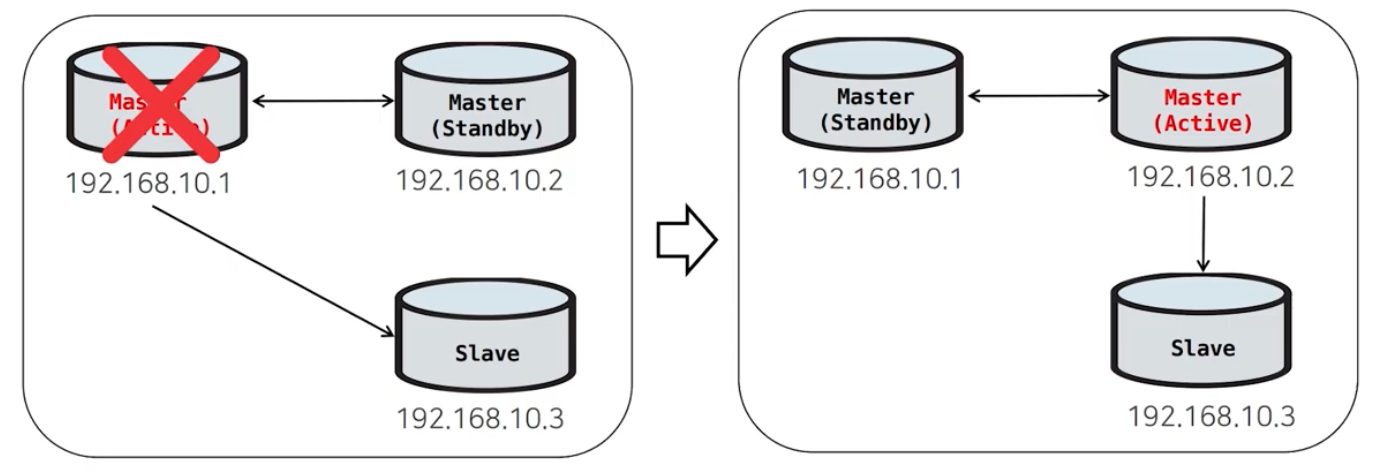
MMM Failover 과정
- MMM Monitor가 Master 서버의 Health checking
- Mastrer(Active)가 접속이 되지않으면 Failover 시작
① Master(Active)에서 master의 역할을 뺏음.
- 읽기모드로 변경, 붙어있던 Session kill, 신규 세션 붇지않도록 VIP 회수
② Master(Standby)로 복제 재구성.
- 복제지연 있는지 확인, Master(Standby) 기준으로 복제 재구성
- Master(Standby)를 신규 마스터로 승격
- Master(Standby) 읽기모드 해제, VIP 할당
③ Failover 완료.MMM Failover의 대상은 Slave가 몇대 있던간에 Master(Standby)가 되도록 지정되어있다.
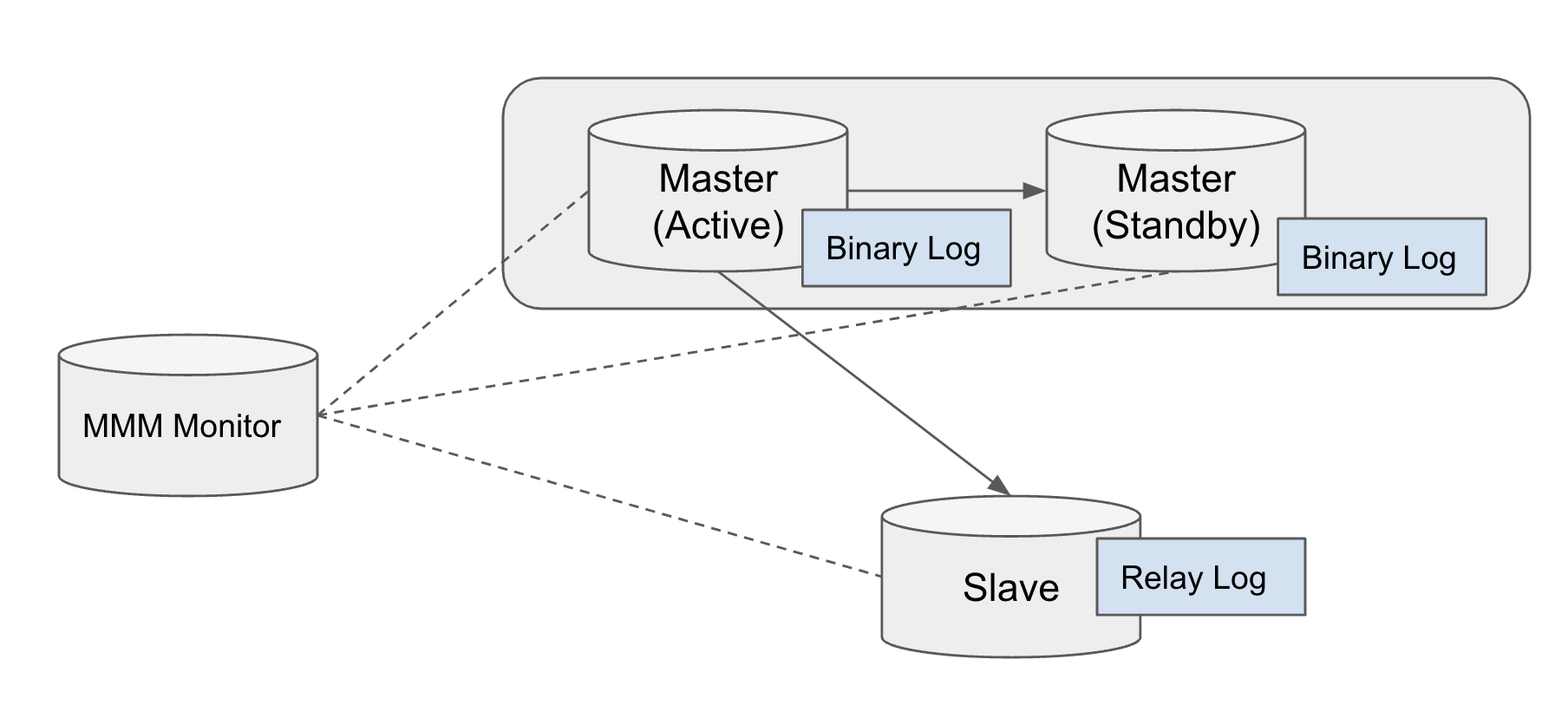
MMM Failover 후속처리
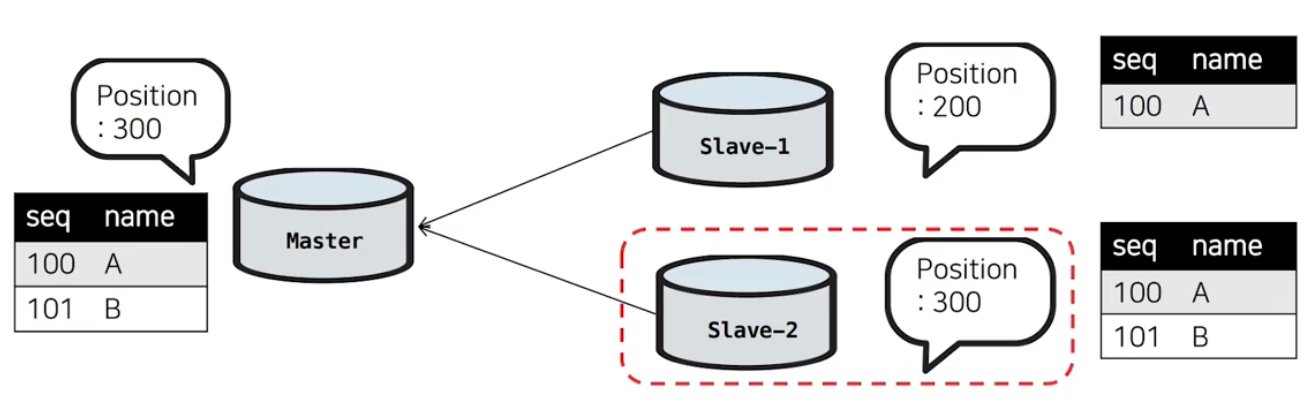
MMM Multi Slave는 데이터 유실
① Master(Active)에서 Master(Standby)와 Slave로 쿼리를 전달.
② Master(Standby)에서는 예상치 못한 오류로 쿼리 실행 X, Slave에서는 쿼리 실행 O.
③ Slave에서 쿼리가 실행되었으므로, ACK 전달
④ ACK를 받은 Master(Active)는 client에게 ACK 시그널 전달.
⑤ 갑작스레 Master(Active) 서버 종료.
⑥ Master(Standby)가 신규 마스터로 승격.
- MMM은 Master(Standby)가 복제 재구성 대상으로 고정되어있는데
ACK 전달 확인을 Slave이든 Master(Standby)든 한 곳에서라도 받으면 OK사인을 내고 이후 과정을 진행하므로 복제 재구성인 Master(Standby)가 복제되지 않았음에도 불구하고 진행되면셔 Master(Standby)에 복제되지 못한 정보는 유실되는 것입니다.
⑦ 데이터 유실 발생!!
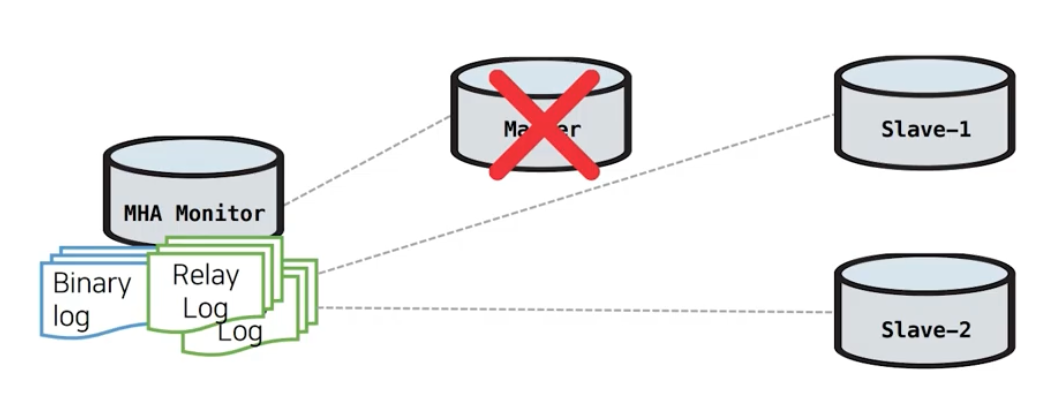
MHA(Master High Availability)
Master + Slave 구조 & 모두 단 방향 복제
MHA FAILOVER 후속처리
① Master가 재시작되거나 다시 올라와도 복제를 재구성해줘야한다.
Master가 장애가 일어나면 Master와 Slave간의 관계를 끊고 나머지 Slave를 통해 복제를 재구성해 준다.
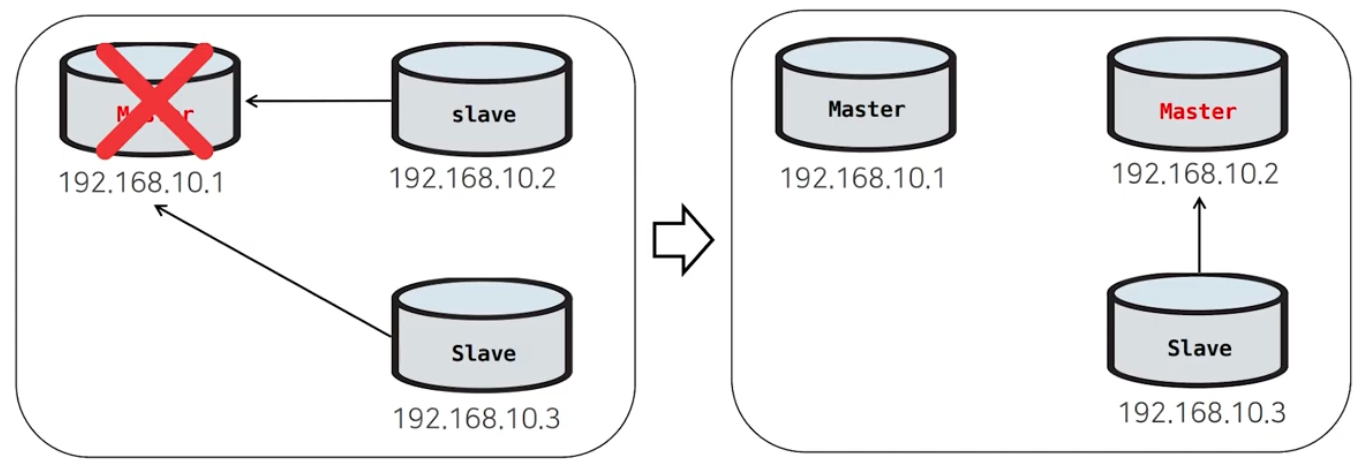
② Failover 시, 신규 Master(Standby) 고정 선택이 아닌 가장 최신의 데이터가 동기화된 Master(Standby) 또는 Slave를 선택
③ MHA Monitor가 Master의 Binary Log와 Slave들의 Relay log를 확인하여 DB간의 차이나는 쿼리를 DB 반영하여 DB간의 일관성을 보장해준다.
참조 : https://www.youtube.com/watch?v=dCVKAJ7tb70&list=RDCMUC982FhzZx87lIWCimFiry_w&start_radio=1&t=41s
진짜 완벽 강의입니다.
시간 되시면 들어보세요! 😁
