
AWS EKS 클러스터 기반에서 Kubeflow를 설치하고 pipeline을 생성하는 방법을 알아보겠습니다.
1. AWS EKS 클러스터 구축하기
Amazon EKS는 자체 Kubernetes 제어 플레인을 설치 및 운영할 필요 없이 AWS에서 Kubernetes를 쉽게 사용할 수 있도록 해주는 관리형 서비스입니다.
사전 세팅
kubectl
CLI환경에서 Kubernetes를 관리하기 위한 프로그램입니다.
클러스터의 구성, Application의 배포 및 검사, 리소스 관리, 로그 확인 등의 기능이 있습니다.
설치 방법
- 최신 버전의 kubectl를 다운로드
curl -LO https://dl.k8s.io/release/v1.23.0/bin/linux/amd64/kubectl- kubectl 파일에 실행권한 부여
chmod +x ./kubectl- kubectl 파일을 바이너리 폴더로 이동
sudo mv ./kubectl /usr/local/bin/$ kubectl- kubectl 버전 확인
kubectl version --client
AWS CLI
AWS 계정 권한으로 AWS Application을 관리하기 위해 설치합니다.
설치
- AWS CLI2 설치
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip" unzip awscliv2.zip
- AWS CLI 버전 확인
aws --version
aws-iam-authenticator
IAM을 사용하여 Kubernetes 클러스터에 인증을 제공하기 위해 설치
- S3에서 aws-iam-authenticator 바이너리 파일 설치
# mac os
brew install aws-iam-authenticator-
실행권한 부여
chmod +x ./aws-iam-authenticator -
바이너리 파일을 $HOME/bin 위치로 이동
mkdir -p $HOME/bin && cp ./aws-iam-authenticator $HOME/bin/aws-iam-authenticator && export PATH=$PATH:$HOME/bin -
환경변수 추가
echo 'export PATH=$PATH:$HOME/bin' >> ~/.bashrc -
실행 확인
aws-iam-authenticator help
eksctl
AWS EKS 클러스터 구축을 위한 프로그램입니다.
- 최신버전 설치
curl --silent --location "https://github.com/weaveworks/eksctl/releases/latest/download/eksctl_$(uname -s)_amd64.tar.gz" | tar xz -C /tmp- 바이너리 파일을 /usr/local/bin 위치로 이동
sudo mv /tmp/eksctl /usr/local/bin- 버전 확인
eksctl version
yq 설치
$ echo 'yq() {
docker run --rm -i -v "${PWD}":/workdir mikefarah/yq yq "$@"}' | tee -a ~/.bashrc && source ~/.bashrcjq 설치
brew install jqAWS LBC 버전 설정
echo 'export LBC_VERSION="v2.0.0"' >> ~/.bash_profile
. ~/.bash_profileIAM Role
Bastion Server가 관리자 권한으로 AWS Application에 접근할 수 있도록 IAM Role을 부여해야 합니다.
- IAM - 역할 - 역할 만들기
- 일반 사용 사례: EC2 선택
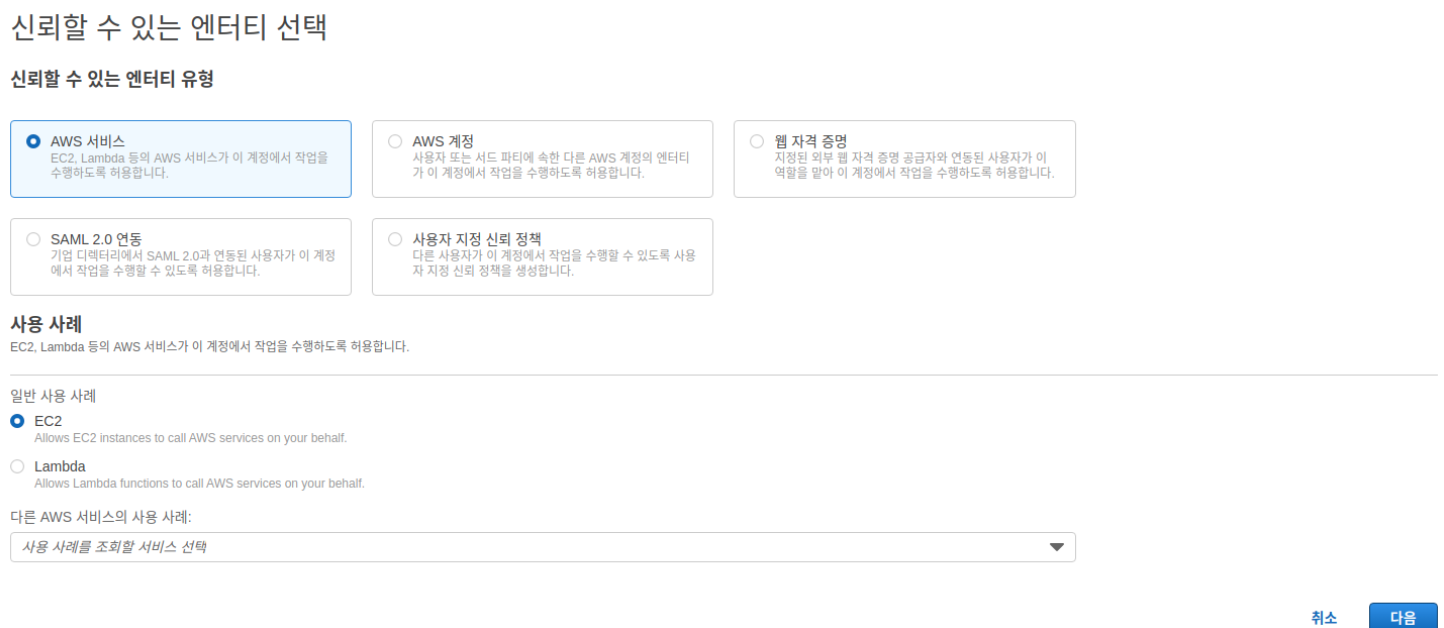
- AdministratorAccess 검색 후 선택
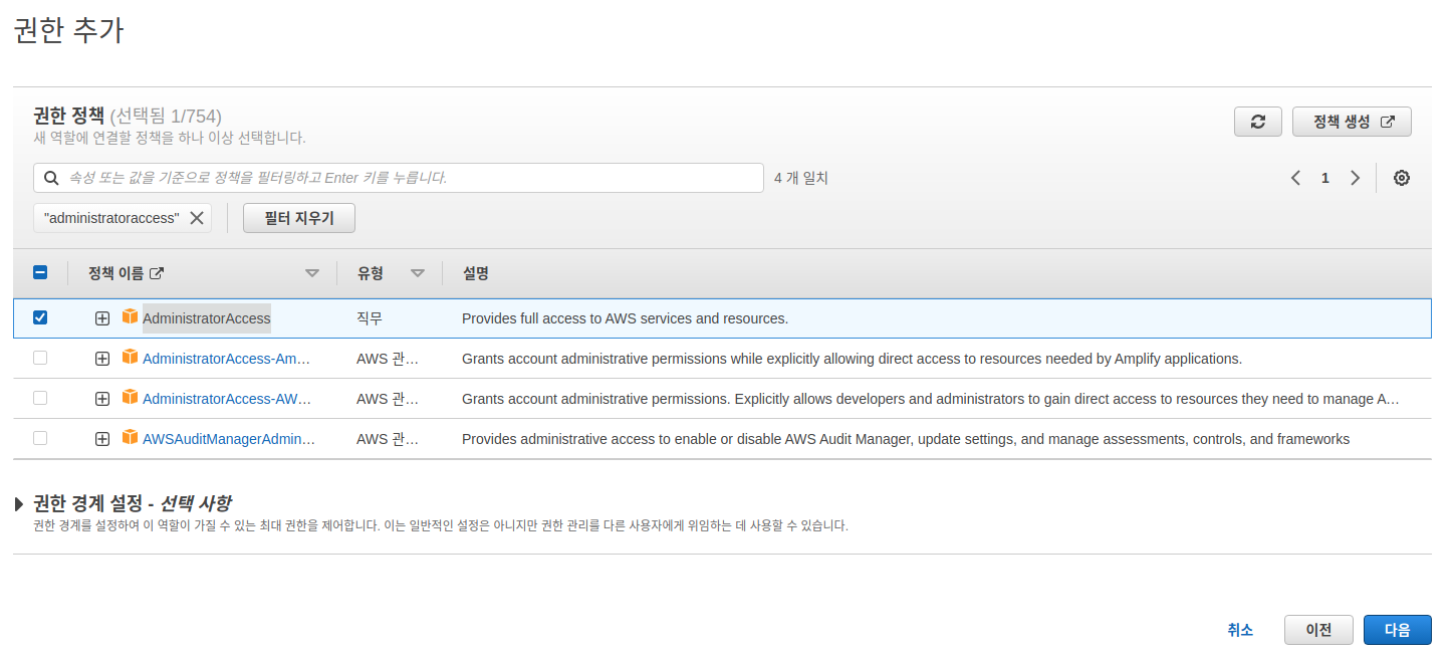
- 역할 이름 입력 후 역할 생성
- EC2 콘솔로 이동하여 Bastion Server의 IAM Role을 생성한 Role로 수정
작업 - 보안 - IAM 역할 수정 - Bastion Server에 .aws/credentials 파일이 있다면 삭제
- AWS REGION이 불러와지는지 확인
export ACCOUNT_ID=$(aws sts get-caller-identity --output text --query Account)
export AWS_REGION=$(curl -s 169.254.169.254/latest/dynamic/instance-identity/document | jq -r '.region')
test -n "$AWS_REGION" && echo AWS_REGION is "$AWS_REGION" || echo AWS_REGION is not set- AWS 계정 정보를 환경병수로 설정
echo "export ACCOUNT_ID=${ACCOUNT_ID}" | tee -a ~/.bash_profile
echo "export AWS_REGION=${AWS_REGION}" | tee -a ~/.bash_profile
aws configure set default.region ${AWS_REGION}
aws configure get default.region- IAM Role이 제대로 등록됐는지 확인
aws sts get-caller-identity --query Arn | grep eksworkshop-admin-i -q && echo "IAM role valid" || eEKS 생성
해당 포스팅에서는 EC2를 노드로 구성하는 방법으로 진행됩니다.
- 생성할 클러스터 정보가 들어있는 cluster.yaml 파일을 생성
apiVersion: eksctl.io/v1alpha5
kind: ClusterConfig
metadata:
name: kube-test
region: ap-northeast-2
version: '1.20'
nodeGroups:
- name: cpu-nodegroup
instanceType: m5.xlarge
desiredCapacity: 3
minSize: 0
maxSize: 6
volumeSize: 20
ssh:
allow: true
publicKeyPath: '~/.ssh/id_rsa.pub'주의사항
yaml 파일은 들여쓰기가 중요합니다. 주의해서 작성해주세요.
포스팅 작성시점 기준 EKS에서 지원하는 Kubernetes 최신 버전은 1.21입니다. 1.21 버전은 jwt 호환성 문제가 있습니다. 1.21 버전으로 진행하셔도 좋으나 호환성 문제 해결을 별도로 진행해주셔야 합니다.
Auth Dex 에러 해결 : 참고
클러스터 구성 노드가 낮은 스펙인 경우 추후 kubeflow 설치에 문제가 발생할 수 있습니다.
(t2.micro 인스턴스에서 문제 발생)
- ssh key를 생성
ssh-keygen -t rsa
cat .ssh/id_rsa.pub - eksctl 명령어를 사용하여 EKS 클러스터 구성
eksctl create cluster -f cluster.yaml - 노드 상태 확인
kubectl get nodes 2. kubeflow 설치하기
Kubeflow 설치
AWS EKS와 호환이 검증된 kubeflow 1.2버전을 설치합니다.
- 이전 포스트에서 구축한 Bastion Server에 kubeflow 1.2버전 다운로드 및 압축해제
curl -L -O -J https://github.com/kubeflow/kfctl/releases/download/v1.2.0/kfctl_v1.2.0-0-gbc038f9_linux.tar.gz
tar -xvf kfctl_v1.2.0-0-gbc038f9_linux.tar.gz- kfctl 파일을 bin 폴더로 이동
mv ./kfctl /usr/local/bin - kubeflow 배포에 필요한 환경변수 설정
export PATH=$PATH:"/usr/local/bin"
export CONFIG_URI="https://raw.githubusercontent.com/kubeflow/manifests/v1.2-branch/kfdef/kfctl_aws.v1.2.0.yaml"
export AWS_CLUSTER_NAME=kube-test- 설치 폴더 생성 및 manifest 다운로드
mkdir ${AWS_CLUSTER_NAME} && cd ${AWS_CLUSTER_NAME}
wget -O kfctl_aws.yaml $CONFIG_URI- kubeflow apply
kfctl apply -V -f kfctl_aws.yaml
주의사항
설치까지 수 분이 소요될 수 있습니다.
이전 포스트에서 언급했듯이 너무 낮은 스펙의 EC2를 노드로 설정하면 apply과정에서 에러가 발생할 수 있습니다.
- kubectl 명령어로 pod들의 동작 확인
kubectl -n kubeflow get all
Kubeflow 대시보드 접근
- Kubeflow 서비스 Endpoint 확인
kubectl get ingress -n istio-system - 만약 확인이 안되는 경우
kubectl port-forward --address=0.0.0.0 -n istio-system svc/istio-ingressgateway 8080:80
주의사항
포트포워딩 하는 경우 접근해야 하는 ip는 클러스터 ip가 아닌 Bastion Server ip입니다.
-
기본 계정
계정: admin@kubeflow.org
비밀번호 : 12341234
3. kubeflow 실습
본 예제에서는 보스턴 집값 예측 모델 학습 및 평가 코드를 사용합니다.
Source Git데이터 로드 및 전처리
scikit-learn에서 제공하는 예제 데이터를 로드한 뒤 train_test_split 함수로 학습 데이터와 테스트 데이터를 나눠 저장하는 작업을 합니다.
from sklearn import datasets
from sklearn.model_selection import train_test_split
import numpy as np
def _preprocess_data():
X, y = datasets.load_boston(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33)
np.save('x_train.npy', X_train)
np.save('x_test.npy', X_test)
np.save('y_train.npy', y_train)
np.save('y_test.npy', y_test)
if __name__ == '__main__':
print('Preprocessing data...')
_preprocess_data()모델 학습
전처리된 학습 데이터를 입력으로 받아 확률적 경사하강법 모델을 학습 후 모델을 저장하는 작업을 합니다.
import argparse
import joblib
import numpy as np
from sklearn.linear_model import SGDRegressor
def train_model(x_train, y_train):
x_train_data = np.load(x_train)
y_train_data = np.load(y_train)
model = SGDRegressor(verbose=1)
model.fit(x_train_data, y_train_data)
joblib.dump(model, 'model.pkl')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--x_train')
parser.add_argument('--y_train')
args = parser.parse_args()
train_model(args.x_train, args.y_train)모델 평가
전처리된 테스트 데이터로 학습된 모델의 MSE(Mean Squared Error)를 계산해 파일로 저장합니다.
import argparse
import joblib
import numpy as np
from sklearn.metrics import mean_squared_error
def test_model(x_test, y_test, model_path):
x_test_data = np.load(x_test)
y_test_data = np.load(y_test)
model = joblib.load(model_path)
y_pred = model.predict(x_test_data)
err = mean_squared_error(y_test_data, y_pred)
with open('output.txt', 'a') as f:
f.write(str(err))
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--x_test')
parser.add_argument('--y_test')
parser.add_argument('--model')
args = parser.parse_args()
test_model(args.x_test, args.y_test, args.model)모델 deploy
평가된 모델을 deploy하는 작업을 합니다.(보통 S3같은 스토리지에 저장하게되는데 본 예제에서는 다루지 않습니다.)
import argparse
def deploy_model(model_path):
print(f'deploying model {model_path}...')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--model')
args = parser.parse_args()
deploy_model(args.model)Docker Hub
작성한 예제 코드와 Dockerfile을 이용해 Docker Hub에 이미지를 push합니다.
아래 작업 전 Docker Hub 계정 생성 및 Repository 생성이 필요합니다.(DockerHub)
- docker build & tag
docker build ./boston_housing/preprocess_data --tag bell/boston_pipeline_preprocessing
docker build ./boston_housing/train --tag bell/boston_pipeline_train
docker build ./boston_housing/test --tag bell/boston_pipeline_test
docker build ./boston_housing/deploy_model --tag bell/boston_pipeline_deploy_model- docker push
docker push bell/boston_pipeline_preprocessing
docker push bell/boston_pipeline_train
docker push bell/boston_pipeline_test
docker push bell/boston_pipeline_deploy_modelPipeline
push한 컨테이너 이미지들을 이용하여 pipeline을 구축합니다.
- 컨테이너 정의
위에서 업로드한 docker image와 컨테이너로 전달하는 arguments, 컨테이너가 출력하는 file_outputs을 정의하여 각 Task 함수를 작성합니다.
from kfp import dsl
def preprocess_op():
return dsl.ContainerOp(
name='Preprocess Data',
image='bell/boston_pipeline_preprocessing:latest',
arguments=[],
file_outputs={
'x_train': '/app/x_train.npy',
'x_test': '/app/x_test.npy',
'y_train': '/app/y_train.npy',
'y_test': '/app/y_test.npy',
}
)
def train_op(x_train, y_train):
return dsl.ContainerOp(
name='Train Model',
image='bell/boston_pipeline_train:latest',
arguments=[
'--x_train', x_train,
'--y_train', y_train
],
file_outputs={
'model': '/app/model.pkl'
}
)
def test_op(x_test, y_test, model):
return dsl.ContainerOp(
name='Test Model',
image='bell/boston_pipeline_test:latest',
arguments=[
'--x_test', x_test,
'--y_test', y_test,
'--model', model
],
file_outputs={
'mean_squared_error': '/app/output.txt'
}
)
def deploy_model_op(model):
return dsl.ContainerOp(
name='Deploy Model',
image='bell/boston_pipeline_deploy_model:latest',
arguments=[
'--model', model
]
)- 파이프라인 구축
작성된 함수를 이용해 파이프라인을 구축합니다.
@dsl.pipeline(
name='Boston Housing Pipeline',
description='An example pipeline that trains and logs a regression model.'
)
def boston_pipeline():
_preprocess_op = preprocess_op()
_train_op = train_op(
dsl.InputArgumentPath(_preprocess_op.outputs['x_train']),
dsl.InputArgumentPath(_preprocess_op.outputs['y_train'])
).after(_preprocess_op)
_test_op = test_op(
dsl.InputArgumentPath(_preprocess_op.outputs['x_test']),
dsl.InputArgumentPath(_preprocess_op.outputs['y_test']),
dsl.InputArgumentPath(_train_op.outputs['model'])
).after(_train_op)
deploy_model_op(
dsl.InputArgumentPath(_train_op.outputs['model'])
).after(_test_op)- 파이프라인 컴파일
파이프라인을 업로드하기 위해 컴파일합니다.
if __name__ == "__main__":
import kfp.compiler as compiler
compiler.Compiler().compile(boston_pipeline, __file__ + ".tar.gz")
dsl-compile --py pipeline.py --output ironkey-boston-pipeline.tar.gzKubeflow 대시보드
컴파일된 파이프라인을 업로드하고 실행시켜봅니다.
-
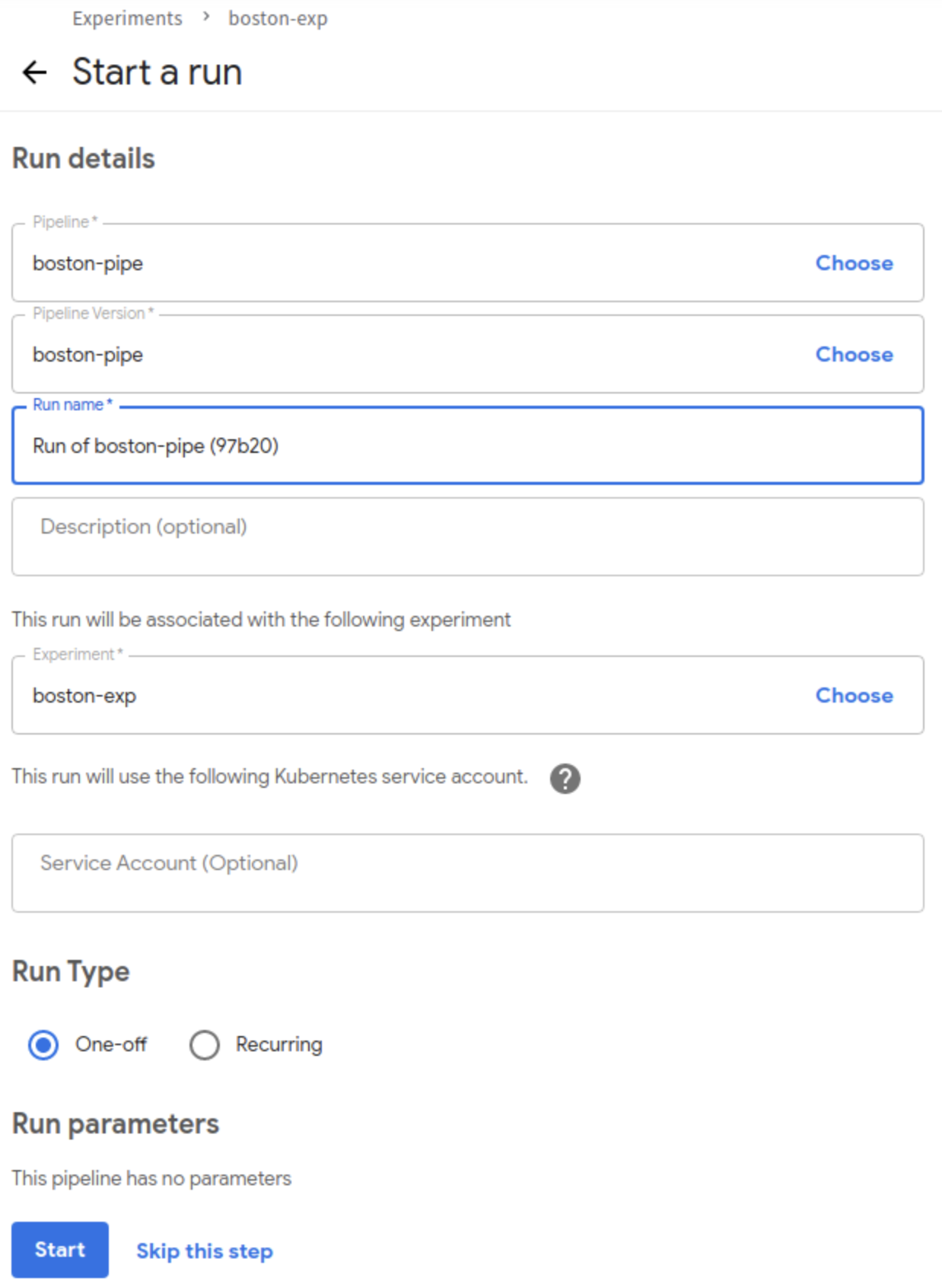
파이프라인 업로드
updload pipeline 버튼을 클릭한 뒤 생성한 tar.gz 파일을 업로드합니다.

-
환경 생성
create experiment 버튼을 클릭합니다.

run name을 입력후 Start 버튼을 클릭합니다.
- 실행 확인
실행이 잘 되는 것을 확인할 수 있습니다.

참조 :
https://towardsdatascience.com/machine-learning-pipelines-with-kubeflow-4c59ad05522
https://github.com/gnovack/kubeflow-pipelines
