
shard와 replica는 elasticserarch에서 크게 사용하는 개념이지만.
비단 elasticsearch 뿐만 아니라 db에서도 쓰이는 개념이다.
RAID
RAID는 여러개의 하드디스크를 용도에 맞게 구성해 사용하는 기술이다.
저장 속도를 높이기 위해 분할 저장을 하거나 안정성을 위해 복제본을 만들거나 패러티 비트를 쓰거나 하는 등의 기술이다.
RAID의 종류로 RAID0, RAID1이 있는데.
RAID0
RAID0은 stripe라고도 합니다. 2개의 disk가 있을경우 데이터를 나눠서 기록하는 방식입니다.
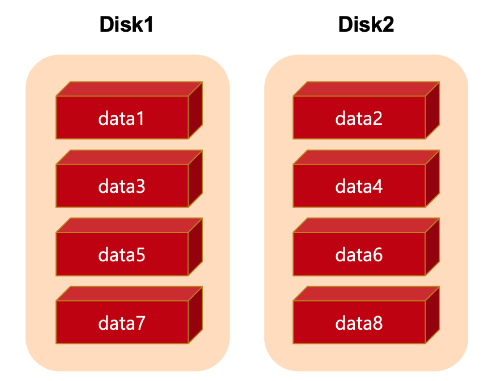
이는 데이터를 저장하는 속도를 높여줍니다.
가령 disk가 한개라면 동시에 1개 데이터만 기록할 수 있지만 disk가 2개일 경우 동시에 2개 데이터를 분산해서 기록할 수 있습니다.
RAID1
RAID1은 mirror라고 합니다.
2개의 disk가 있을 경우 데이터를 각 디스크에 똑같이 기록하는 방식입니다.
일종의 백업이죠. disk 한개가 고장나도 다른 disk에 데이터가 있기 떄문에 안정성이 높아집니다.

Shard
Shard는 쉡게말하면 RAID0과 같습니다.
elasticsearch는 indexing을 할 때 node 내부에 논리적으로 데이터 저장 공간을 만듭니다.
그리고 그 논리적 저장 공간들에 데이터를 씁니다.
저장 공간이 1개라면 한번에 1개 데이터만 쓸 수 있겠지만 저장 공간을 논리적으로 나누게 되면 동시에 여러개 데이터를 분산해서 저장할 수 있게됩니다.
2개의 노드에 3,2의 shard를 정의하면 아래처럼 정의되게 됩니다.
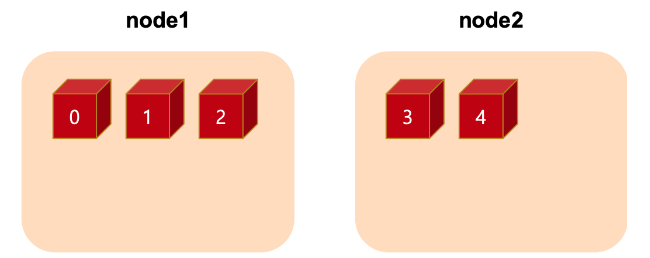
Replica
replica는 RADI1과 유사합니다.
데이터가 shard에 저장되게 되면 이 shard에 대한 복제본을 만드는 것입니다.
원본 shard가 장애가 나더라도 복제본 shard를 통해 데이터를 제공할 수 있게 되어 가용성을 증가할 수 있습니다.
또한 하나의 데이터를 2개의 shard가 갖고 있기 때문에 검색 성능 향상에도 도움이 됩니다.
elasticsearch는 replica default가 1개다 즉 하나의 index를 생성하고 데이터를 인덱싱 하게되면 1개의 replica가 추가로 생성된다는 겁니다.
replica의 기본 기능은 복제본을 통해 원본 shard의 장애를 대응하는 것입니다.
한 node안에 동일한 shard에 대한 primart와 replcia가 함께 존재할 수 없습니다.
왜냐면 같이 존재할 경우 node에 장애가 나면 모두 날라가... 정상적으로 데이터 제공을 할 수 없기 때문입니다.
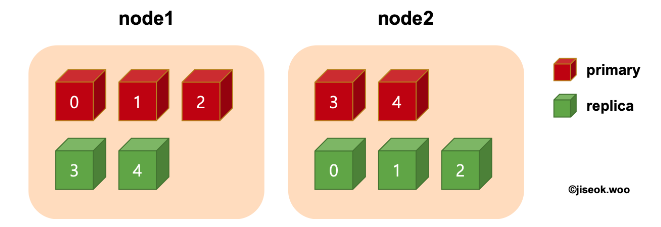
그래서 위 그림에서 보이듯 초록색 replica는 서로 다른 node에 설치되게됩니다.
