마이크로 서비스는 대규모 소프트웨어 프로젝트를 마이크로 단위의 모듈로 분리하여 loosely-coupled한 구조로 만들고 API를 통해 서로 통신합니다.
지난 몇 년동안 마이크로 서비스에 대해서 많은 이야기가 있었습니다. 모듈형 아키텍처 스타일은 클라우드 기반 환경에 적합하며 인기가 높아지고 있습니다.
마이크로 서비스는 대형 소프트웨어 프로젝트의 기능들을 작고 독립적이며 느슨하게 결합 된 모듈로 분해하여 서비스를 제공하는 아키텍처 입니다.
각 개별 모듈은 개별적인 작업을 담당하며 간단하고 보편적으로 엑세스 할 수 있는 API를 통해 다른 모듈과 통신 합니다.
마이크로 서비스는 웹 기반의 복잡한 응용 프로그램을 설계하기 위한 또 다른 아키텍처입니다. 일반적으로 SOA(Service Oriented Architecture)와 비슷하게 바라보는 시각도 존재합니다만 엄연히 다른 아키텍처입니다.
SOA 문제점
그렇다면 SOA와 같은 기존 아키텍처의 문제점은 무엇일까요?
Java를 사용하여 기존 웹 프로그램을 만든다고 가정합시다. 가장 먼저 해야 할 일은 presentation layer (사용자 인터페이스)를 디자인을 하고 Business logic을 처리하는 Application layer와 구성 요소 간의 느슨한 결합을 가능하게 하는 Integration layer 그리고 마지막으로 데이터에 접근이가능하도록 Persistence layer를 디자인 하고 구현해야 합니다.
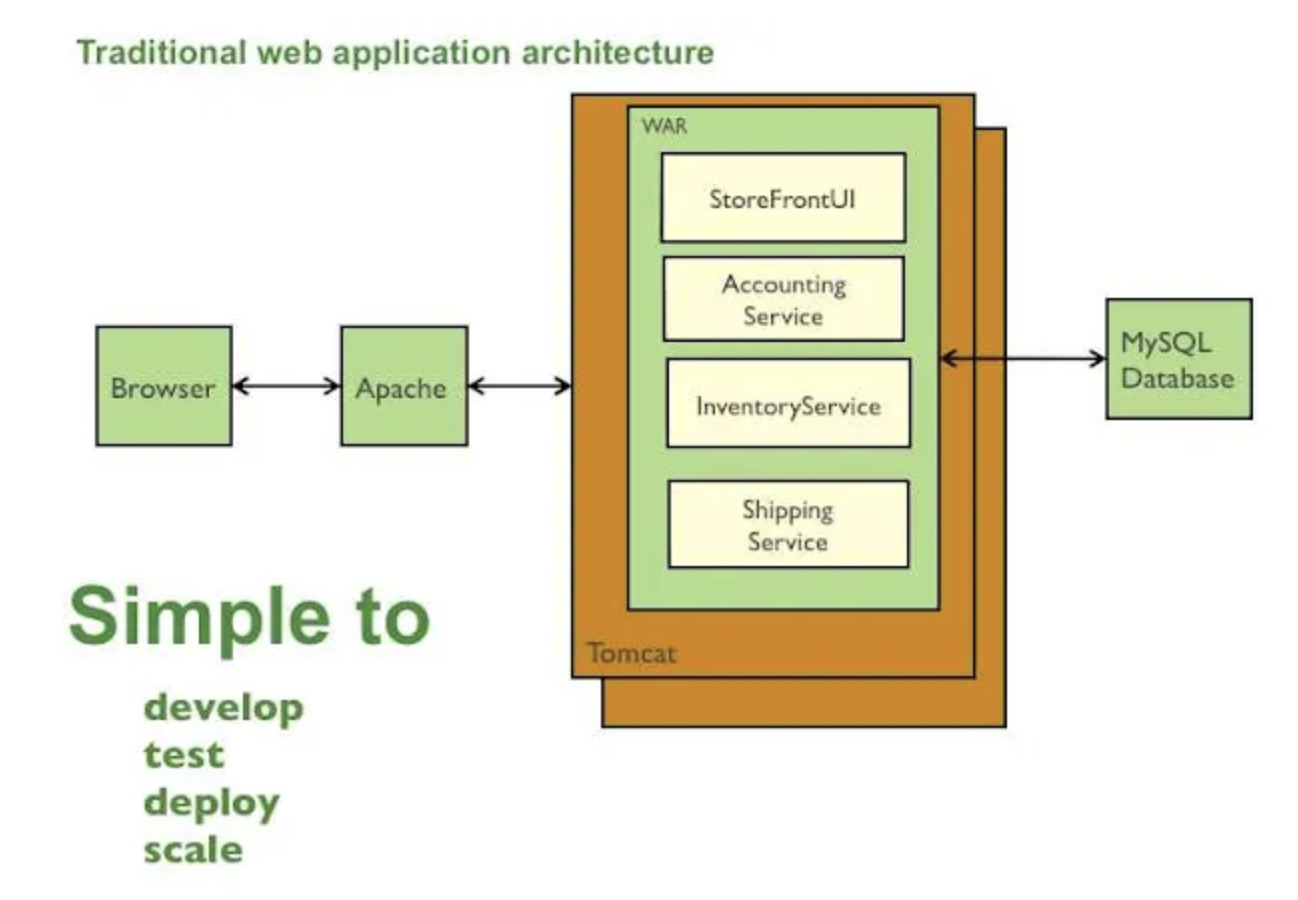
어플리케이션을 구동하기 위해 war or ear 패키지를 생성하고 이를 Tomcat or JBoss와 같은 Application server에 배포합니다. 모든 모듈이 war or ear로 패키징 되었기에 우리는 이것을 Monolithic이라고 부릅니다. 다시 말해서 별도의 구현 가능한 구성 요소가 존재해도 모두 하나의 지붕 아래에 패키징되어 있습니다. 아래의 그림을 참조하세요.
Monolithic 아키텍처: challenges
- 어플리케이션이 커질 수록 코드도 방대해지고 로드시에 IDE에 과부하가 걸릴 수 있습니다. 이런 부분은 개발자의 생산성을 저하시키는 요인이 됩니다.
- 하나의 war or ear에 모든 것을 포함하였기에 어플리케이션의 기술 스택을 변경하는 것을 주저하게 됩니다. 예를 들어서 일부 컴포넌트는 JVM내에서 동작하는 Groovy나 Scala와 같은 다른 언어를 사용하여 처리하려고 할 경우 이런 종류의 아키텍처를 사용하면 어떤 side-effect가 발생 할지 예측이 어려우므로 리펙토링을 해야 하지만 코드가 너무 방대해서 리펙토링을 하기가 어렵습니다.
- 어플리케이션내의 특정 기능이 실패하면 전체 어플리케이션에 영향을 미칩니다. 그리고 퍼포먼스가 나쁜 특정 함수/메소드의 영향이 전체 어플리케이션에 고통을 주게 됩니다.
- 이런 아키텍처에서의 scaling은 서버마다 동일한 war or ear을 배포하여 수행해야 합니다. 각각 서버는 동일한 리소스를 사용하게 되므로 이 것은 효율적인 방법이 아닙니다.
- 어플리케이션이 커질수록 개발자는 작은 단위로 작업을 축소할 수 있어야 합니다. Monolithic은 모든 것이 하나로 묶여 있기 때문에 개발자가 독립적으로 모듈을 개발하고 배포 할 수 없습니다. 그리고 개발은 협업으로 진행되므로 다른 개발자에 의존성때문에 개발 시간이 길어지게 됩니다.
마이크로 서비스
아키텍처의 중요한 포인트는 바로 확장성입니다. 많은 사람들이 확장성을 얘기 할 때는 The Art of Scalability라는 책을 인용합니다. 이 책에서는 Scaling을 세 가지로 정의합니다.
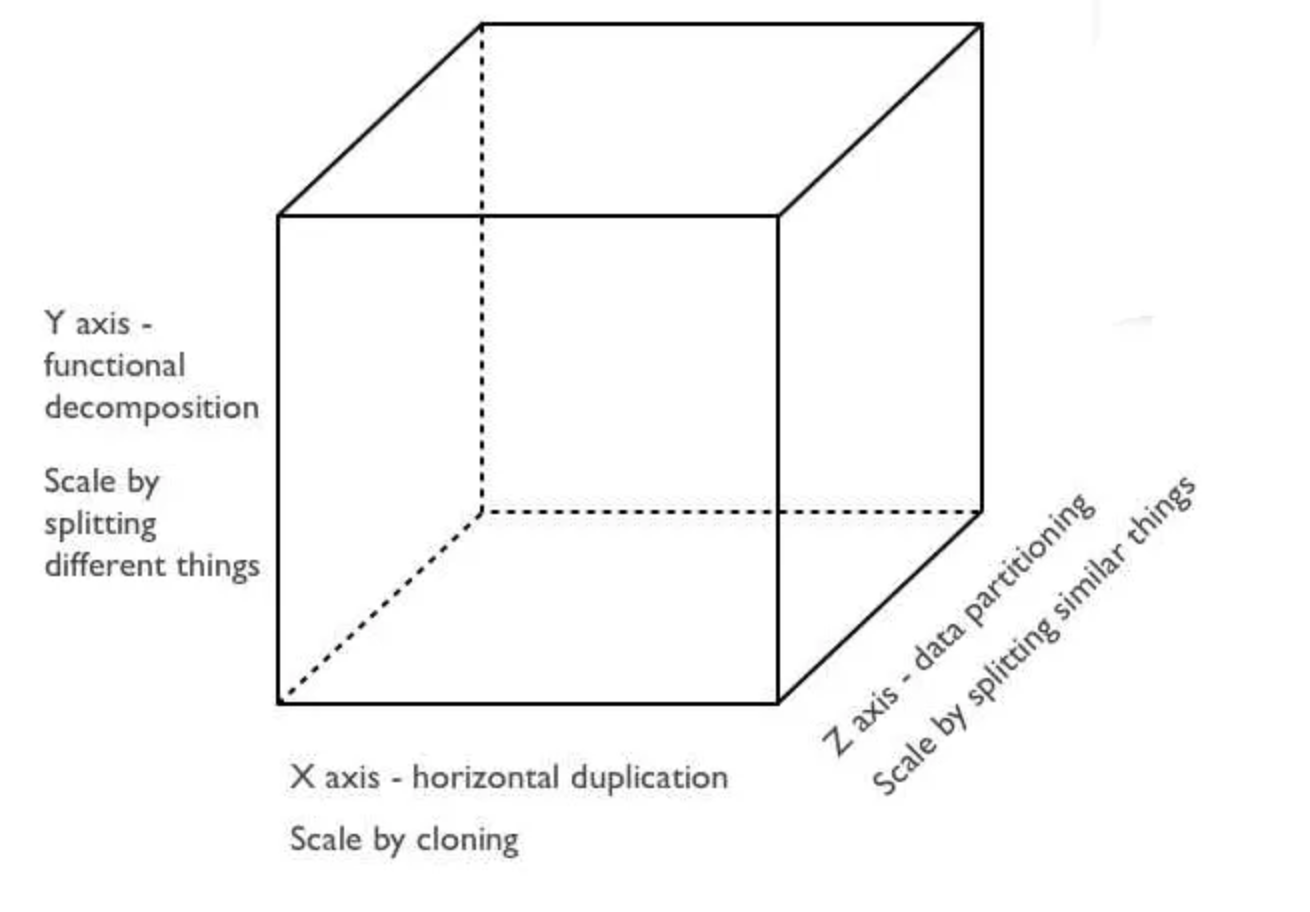
X 축은 horizontal(수평) application scaling (Monolithic 아키텍처에서도 가능)을 나타내며, Z축은 비슷한 것들을 분할하여 어플리케이션을 스케일링함을 의미합니다. (Z축은 데이터를 분할하여 사용자의 요청에 따라 해당 샤드에 redirect하는 샤딩 개념으로 이해하면 됩니다.)
Y축이 가장 중요하고 우리가 눈여겨 봐야할 대상입니다. 이 축은 기능적인 분해(해체)를 의미합니다. Monolithic에 포함되어 있는 다양한 기능을 독립적인 서비스로 바라보는 전략을 취합니다.
따라서 모든 기능을 전체 어플리케이션에 배포하지 않고 각각 서비스를 독립적으로 배포 할 수 있습니다.
이렇게 하면 개발자의 생산성이 향상되고 기능 변경시 side-effect 걱정 없이 변경하고 배포 할 수 있는 유연성을 제공합니다.
마이크로 서비스의 배포 및 가상화
마이크로 서비스기반의 어플리케이션을 배포하는 가장 좋은 방법은 컨테이너 가상화를 이용하는 것입니다. (Docker)
AWS와 같은 IaaS업체의 VM을 이용하여 마이크로 서비스를 배포할 수 있지만 작은 단위의 마이크로 서비스는 VM의 리소스를 전부 활용 하지 못해 비용 효율성을 저하 시킬 수 있습니다.
따라서 컨테이너 기반으로 배포를 하는 것이 유리합니다.
OSGI(Open Service Gateway Initiative) 번들을 사용하여 코드를 배포 할 수도 있지만, 이 경우에는 management and isolation tradeoff와 관련된 단점이 존재합니다.
마이크로 서비스의 약점
아래는 마이크로 서비스 설계와 관련된 잠재적인 약점에 대한 부분입니다.
분산 시스템 개발은 일반 개발보다 복잡합니다. 모든 것이 독립적인 서비스이기 때문에 각 모듈간의 인터페이스를 신중하게 처리 해야 합니다. 서비스 중 하나가 응답하지 않게 될 경우에 대한 방어코드도 작성해야 합니다. 호출 대기 시간이 발생하게 되면 복잡한 상황이 발생할 수 있습니다.
Multiple Databases 및 트랜젝션 관리가 어려울 수 있습니다.
마이크로 서비스 기반의 어플리케이션을 테스트하는 것은 번거로울 수 있습니다. 테스트를 시작하기 전에 의존성이 있는 서비스를 미리 확인해야 합니다.
마이크로 서비스의 배포는 복잡 할 수 있습니다. 각 서비스 간의 조정이 필요 할 수 있습니다.
DEVOPS
Devops는 운영과 개발을 한팀에서 하는 모델을 말하는데, 팀이 개발과 운영을 모두 담당함으로써 개발과 운영 사이에서 오는 간극을 해결하고 개발된 시스템을 빠르게 배포하고, 운영 과정에서 얻은 노하우를 개발에 반영해서 시장의 요구 사항에 빠르게 반응 하는데 그 목적을 둔다.
개발과 운영을 한팀에서 담당함에도 불구하고, Devops 엔지니어, SRE (Site Reliability engineer)등과 같이 기존의 운영팀이 하던 일을 하는 역할이 여전히 남아 있는데, 그렇다면 Devops로 넘어왔음에도 불구하고 이러한 역할이 계속 남아 있는 이유와 정확한 역할은 무엇일까?
SRE
개발자가 셀프 서비스로 운영을 하려면 그 플랫폼이 자동화되어 있어야 한다. 애플리케이션을 빌드하고 유연하게 배포하고, 이를 모니터링할 수 있는 플랫폼이 필요한데, SRE의 역할은 이러한 플랫폼을 개발하고, 이 플랫폼 위에서 개발자들이 스스로 배포,운영을 하는 것이 목표이다.
물론 완벽한 셀프 서비스는 불가능하다. 여전히 큰 장애 처리나 배포등은 SRE 엔지니어가 관여하지만 많은 부분을 개발팀이 스스로 할 수 있도록 점점 그 비중을 줄여 나간다.DevOps vs SRE
Devops가 개발과 운영의 사일로(분단) 현상을 해결하기 위한 방법론이자 하나의 조직문화에 대한 방향성이다.
그렇다면 SRE는 구글이 Devops에 적용하기 위한 구체적인 프렉틱스(실사례)와 가이드로 생각하면 된다.
구글도 다른 기업들과 마찬가지로 회사의 성장과 더블어 2000 년도 즈음에 개발자들이 속도에 무게를 두고 운영팀이 안정성에 무게를 둬서 발생하는 문제에 부딪혔고, 이 문제를 풀고자 하는 시도를 하였는데 이것이 바로 SRE (Site Reliability Engineering)이다.
앞에서도 언급했듯이 Devops는 개발팀이 개발/배포/운영을 모두 담당하는 셀프 서비스 모델이다. 셀프 서비스를 하기 위해서는 인프라가 플랫폼화되어 있어야 한다.
개발팀이 직접 데이타 센터에 가서 서버를 설치하고 OS를 설치하고 네트워크 구성을 하기는 어렵고, 온라인으로 서버를 설치하고 네트워크를 구성할 수 있어야 하고, 무엇보다 쉬워야 한다.
인프라 구성뿐 아니라 그위에 소프트웨어를 쉽게 빌드 및 배포하고 운영 중인 시스템에 대한 모니터링이 가능해야 하는데, 이러한 인프라를 일일이 구성하기는 어렵기 때문에 플랫폼화가 되어 있어야 하는데, Devops 엔지니어의 역할은 이러한 플랫폼을 만드는 역할이 된다.
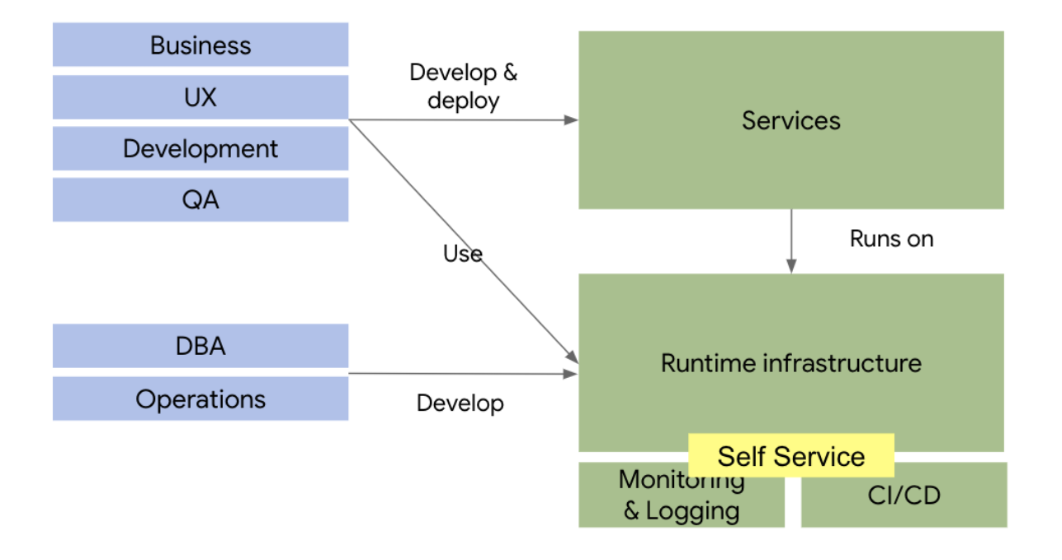
위의 그림과 같이 Devops 팀은, 시스템을 실행할 수 있는 런타임 인프라를 개발 배포하고, 런타임 시스템에 대한 모니터링과 로깅을 제공하며, 이 시스템에 자동으로 배포할 수 있는 CI/CD 플랫폼을 구축한다.
이렇게 개발된 플랫폼에 개발팀은 개발된 시스템을 스스로 배포하고 운영하는 모델이다.
이러한 모델은 구글의 SRE (Site Reliability Engineering)에서 좋은 사례를 찾아볼 수 있는데, SRE 엔지니어는 시스템이 개발된 후에, 인프라 시스템에 대한 플랫폼화 작업을 수행하고, 이 플랫폼이 완성되어 안정화 될때까지 지속적인 지원을 하며, 플랫폼에 대한 안정화 작업이 끝나면 플랫폼의 운영을 개발팀에 맏기고 다른 프로젝트를 위한 플랫폼 작업을 하는 방식이다.
컨테이너
이러한 플랫폼을 지원하기 위해서는 벤더 종속적이지 않고, 개발자가 손쉽게 운영 및 접근할 수 있는 인프라 관리 기술이 필요한데, 이런 기술로 많이 언급되는 기술이 컨테이너이다.

가상머신 (VM)의 경우에는 하이퍼바이저의 종류에 따라서, 호환이 되지 않는 경우가 있고, 무엇보다 가상 머신 이미지의 사이즈가 매우 크기때문에 (수백~기가 이상) 손쉽게 이식하기가 쉽지 않다.
또한 하드웨어 계층 부터 가상화 하기 때문에 실행하는데 컨테이너에 비해서 상대적으로 많은 자원이 소요된다.
컨테이너의 경우 가상 머신을 사용하지 않고 호스트 OS의 커널에서 바로 실행이 된다. 실행되는 컨테이너의 OS가 호스트 OS와 다른 경우, 이 다른 부분 (알파)만을 컨테이너에서 추가로 패키징하여 실행이 된다.
예를 들어 호스트 이미지에 기능이 A,B,C가 있고, 컨테이너는 A,B,C,D가 필요하다면, 컨테이너에는 다른 부분인 D만 묶어서 패키징 하는 개념이다.
그래서 가상머신에 비해서 크기가 훨씬 작고 가상화 계층을 거치지 않기 때문에 훨씬 효율적이라고 말할 수 있다.
가상 머신위의 컨테이너
보통 이런 컨테이너 환경을 운영할때 베어메탈 (하드웨어)위에 바로 컨테이너 솔루션을 올리지 않고, 가상화 환경을 올린 후에, 그 위에 컨테이너 환경을 올리는 경우가 많다.
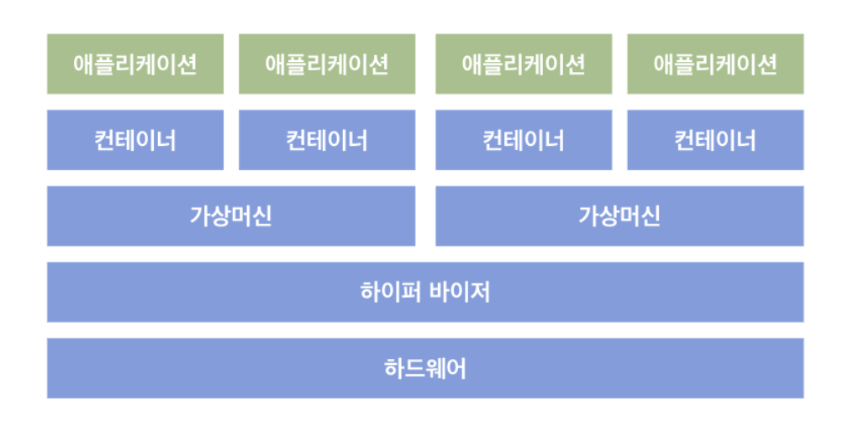
베어메탈 위에 바로 컨테이너 환경을 올리면 성능적 이점도 있고, 계층도 줄어들어 관리도 편리한데, 왜 가상화 계층을 한번 더 두는 것일까?
이유는 컨테이너 환경을 조금 더 유연하게 사용할 수 있기 때문이다.
먼저 가상 머신을 이용해서 컨테이너 환경을 isolation할 수 있고, 가상화를 통해서 자원의 수를 더 늘려서 이를 잘게 쪼게서 사용이 가능하다.
예를 들어 설명하면, 8 CPU 머신을 쿠버네티스로 관리 운영하면, 8 CPU로밖에 사용할 수 없지만, 가상화 환경을 중간에 끼면, 8 CPU를 가상화 해서 2배일 경우 16 CPU로, 8배일 경우 64 CPU로 가상화 하여 좀 더 자원을 잘게 나눠서 사용이 가능하다.
