인덱스(Index)
인덱스(Index)는 DB 테이블에 대한 검색 속도를 높여주는 자료 구조이며,인덱싱은 이러한 인덱스를 DB에 남기는 것이다.
쉽게 말하면 일종의 목차를 생성하는 개념이며, 생성된 목차를 이용하여 검색 범위를 줄여 속도를 높일 수 있는 것이다.
인덱싱을 사용하는 이유
우리가 테이블을 생성하고 데이터가 쌓이면, 테이블의 레코드는 내부적으로 순서가 없이 뒤죽박죽으로 저장된다.
이 상황에서는 Where절에 특정 조건에 부합하는 데이터들을 조회할 때에도 레코드의 처음부터 끝까지 다 읽어서 검색 조건과 맞는지 비교해야 하며, 이것을 Full Table Scan 이라고 한다.
이 경우 테이블에 데이터가 적다면 성능에 영향을 주지 않겠지만, 수십만개의 데이터가 들어있는 경우라면 성능 저하가 생길 것이 분명하다.
이와 같이 DB를 다룰 때 대부분의 성능 저하는 조회 쿼리에서 나타나며, 특히 Where절에서 많이 발생한다.
이럴 때 가장 먼저 생각해 볼 수 있는 대안이 인덱스가 될 수 있으며, SQL 튜닝에서도 Index와 관련된 문제사항과 해결책이 많다.
인덱싱 동작 방식
먼저 해당 테이블을 생성시 생성하고 싶은 인덱스 컬럼을 지정한다.
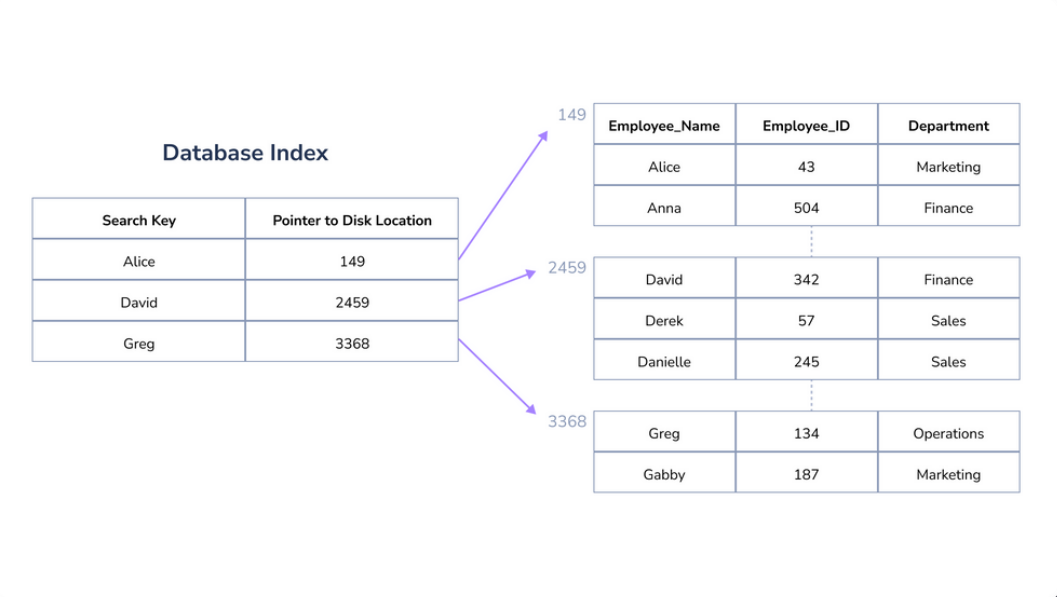
특정 컬럼에 대한 인덱스를 생성하면 해당 컬럼의 데이터들을 정렬하여 별도의 메모리 공간에 데이터의 물리적 주소와 함께 저장된다.
인덱스가 생성되면 해당 컬럼에 대한 Where 조건문을 사용하여 쿼리를 날릴 때 옵티마이저에 의해 판단되어 생성된 인덱스를 탈 수 있게 되고, 인덱스에 저장되어 있는 데이터의 물리적 주소로 가서 데이터를 가져오는 방식으로 동작하여 검색 속도의 향상을 가져올 수 있는 것이다.
옵티마이저(Optimizer)란?
SQL을 빠르고 효율적으로 수행할 최적의 처리 경로를 생성해주는 DBMS 내부의 핵심 엔진
Index의 종류
인덱스의 종류에는 여러가지가 있으며, B-tree가 가장 많이 사용된다.
- B-tree Index
- Bitmap Index
- IOT Index
- Clustered Index
B-Tree 인덱스
B-Tree 인덱스는 대표적인 밸런스 트리 중 하나이다.
밸런스 트리(Balanced Tree)란, 노드 삽입 및 삭제 시 특정 규칙에 맞게 재정렬되어 양쪽 자식 노드 수의 밸런스를 유지하는 트리이다.
밸런스를 유지하므로, 항상 O(logN)의 시간 복잡도를 가지기 때문에 탐색 시간에 매우 효율적인 자료구조이다.
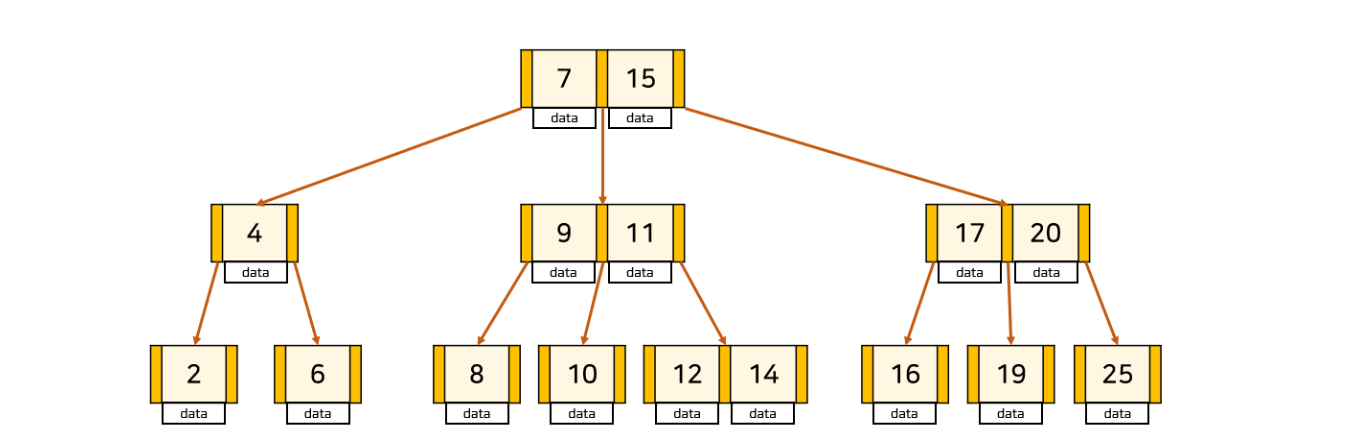
구조는 위와 같이 Root, Branch, Leaf 노드로 구성된다.
특정 컬럼에 대한 인덱스를 생성할 때 컬럼의 값들을 정렬하는데, 정렬한 순서가 중간 쯤 되는 데이터를 뿌리에 해당하는 ROOT 블록으로 지정하는 것이다.
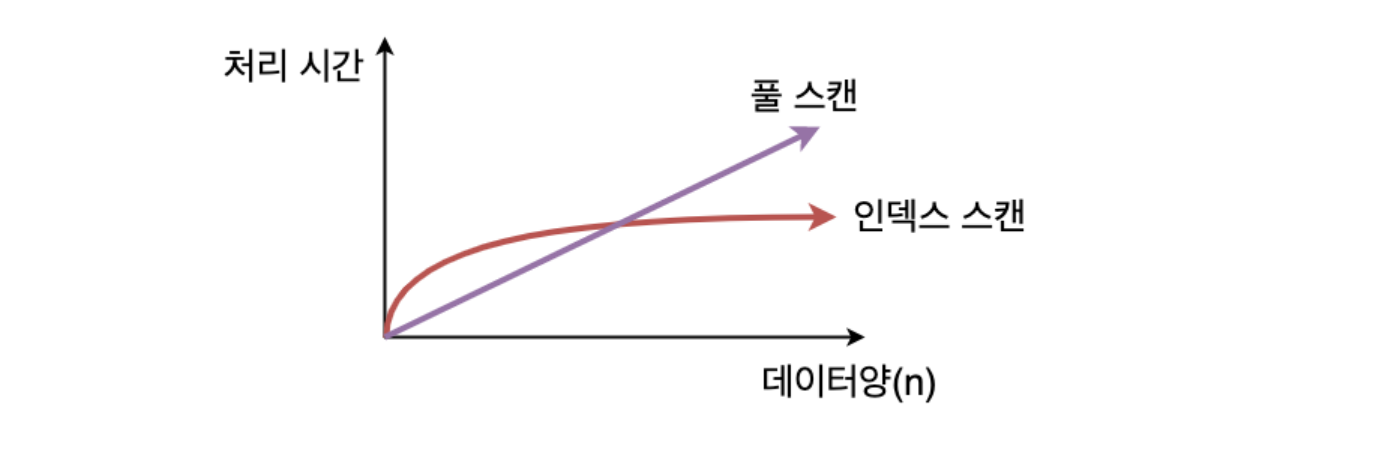
풀 스캔(Full Table Scan)의 경우 테이블의 크기에 비례하는 형태로 탐색 시간이 늘어나지만, 인덱스 스캔(Index Scan)의 경우 탐색 성능의 저하는 보통 완만한 곡선을 그리게 된다.
하지만, 데이터 변경이 발생할 때마다 재정렬이 필요하므로 데이터의 삽입/수정/삭제가 빈번히 일어날 경우에는 적합하지 않을 것이다.
인덱싱의 단점
위와 같은 장점에도 불구하고, Index는 어떤 상황에서나 유용하게 사용되는 기술은 아니다.
앞서 언급했듯이 인덱스의 가장 큰 문제점은 정렬된 상태를 계속 유지 시켜줘야 한다는 점이다. INSERT, UPDATE, DELETE를 통해 데이터가 추가되거나 값이 바뀐다면 index 테이블 내에 있는 값들을 다시 정렬해야 한다.
또한 INDEX 테이블과 기존 테이블 두 곳 모두 데이터 수정 작업해줘야 한다는 단점도 있다.
따라서 레코드 내에 데이터 값이 빈번하게 바뀌는 경우에는 악영향을 미친다.
검색 시에도 인덱스가 무조건 유용한 것은 아니다.
인덱스는 테이블의 전체 데이터 중에서 10~15% 이하의 데이터를 처리하는 경우에만 효율적이고 그 이상의 데이터를 처리할 땐 인덱스를 사용하지 않는 것이 더 낫다.
그리고 인덱스를 관리하기 위해서는 데이터베이스의 약 10%의 저장공간이 추가로 필요하기 때문에, 상황을 고려하여 index를 만들어야 한다.
Index 생성 전략
인덱스를 효율적으로 사용하려면 조건절에 자주 사용되는 컬럼을 인덱스로 생성하는 것이 좋다.
인덱스는 특정 컬럼을 기준으로 생성하고 기준이 된 컬럼으로 정렬된 Index 테이블이 생성된다. 이때, 기준 컬럼은 최대한 중복이 되지 않는 값이 좋기 때문에 PK로 인덱스를 만드는 것이 이상적이다.
중복된 값이 적을수록
최적의 검색 효율을 보일 것이고,
반대로 중복되는 값이 많은 컬럼일 수록낮은 효율을 보일 것이다.
index 선정 기준
- 조건절에 자주 등장하는 컬럼
- 항상 = 으로 비교되는 컬럼
- 중복되는 데이터가 최소한인(분포도가 좋은) 컬럼
- ORDER BY 절에서 자주 사용되는 컬럼
- JOIN 조건으로 자주 사용되는 컬럼
❗️ 사용 시 주의점
insert, update, delete가 빈번히 일어나는 경우 인덱스 테이블에서도 해당 동작들이 수행되기 때문에 성능 저하를 초래할 수 있기 때문에, facebook 같은 소셜 서비스에서는 인덱싱을 사용할 경우 오히려 엄청난 성능 저하가 발생하게 될 것이다.
따라서 상황을 잘 고려하여 인덱싱 사용 여부를 결정해야 한다.
📃 Reference
