JPA
1.[JPA] 2차 캐시에 대하여
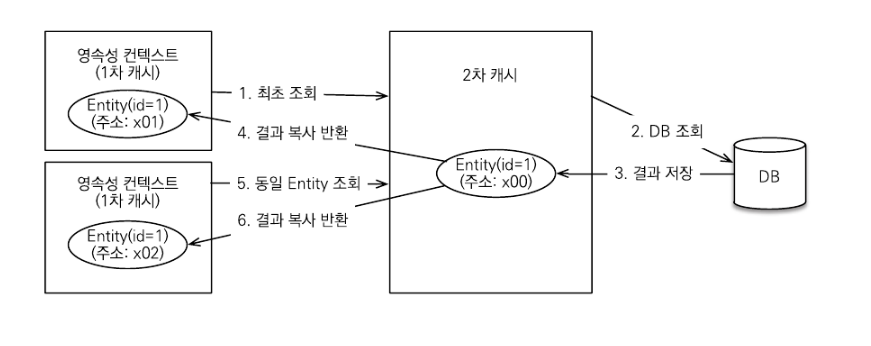
1차 캐시에 대한 내용은 학습하고 기록도 했었지만, 2차 캐시에 대해서는 잘 기억이 나지 않아 정리해놓으려 합니다. 1차 캐시는 영속성 컨텍스트 내부에 존재하는 엔티티 보관소이다. 링크 2차 캐시 애플리케이션 범위에서 공유하는 캐시를 JPA에서는 공유 캐시(
2.[JPA] 테스트 도중 만난 Lazyloading Exception
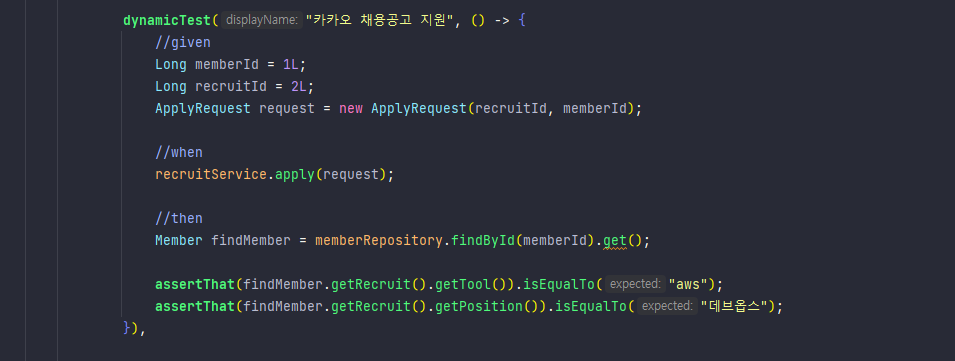
백엔드 API를 만들고 테스트 코드를 짜던 도중 lazyloading exception을 만났다.이 부분에서 findMember의 recruit를 호출하는데, 영속성 컨텍스트?트랜잭션? 밖에서 호출했기 때문이다.테스트 메서드/클래스 레벨에 @Transactional 붙
3.(Error Resovled) MappingException 과 @JoinColumn의 동작 방식

테스트 코드 작성 도중 아래와 같은 에러를 만났다구글링 해본 결과, Entity와 DB 테이블 간에 충돌로 인해 발생하는 에러였다.예를 들어 Entity 설정이 DB 테이블 설정을 위반하거나, 해당 Entity를 DB 테이블로 생성할 수 없을때 발생한다.에러 내용은 R
4.(QueryDsl) DTO Projection과 사용 방법

projection이란 select 절에 대상을 지정하여 원하는 값만 뽑아오는 것을 의미한다. projection 대상이 하나인 경우, 간단하게 작성할 수 있다. > projection 대상이 둘 이상인 경우, 타입을 명확하게 지정할 수 없으므로 이나 로 조회해
5.(JPA) Embedded Type

기본 값 타입들을 모아 새로운 타입으로 생성된 하나의 값 타입이며, 복합 값 타입이라고도 한다.임베디드 타입은 int, String과 같은 기본 값 타입들을 포함한 클래스라고 볼 수 있다.예를 들어 위와 같은 Member 테이블이 있다면, 하나의 범주로 묶을 수 있는
6.OSIV (Open Session In View)

여태까지 JPA를 사용하면서 서버를 시작할 때마다 만났던 warning 로그이다.구글링을 통해 대충 무엇인지 개념 정도만 알고 있었는데, 강의를 보던 중 강사님께서 다뤄주신 부분을 보게 되었다.OSIV 전략은 최초 데이터베이스 커넥션 시작 시점부터 API 응답이 끝날
7.(JPA) fetch join과 N+1 문제

JPQL에서 성능 최적화를 위해 제공하는 기능으로써, 특정 엔티티를 DB에서 가져올 때 연관된 엔티티 또는 컬렉션까지 모두 가져오는 방법이며,주로 N+1 문제를 해결하기 위해 자주 사용된다.N+1 문제란, 먼저 조회하는 엔티티를 가져오는 쿼리가 1번 실행된 후에, 연관
8.프록시(Proxy)와 지연로딩(Lazy Loading)
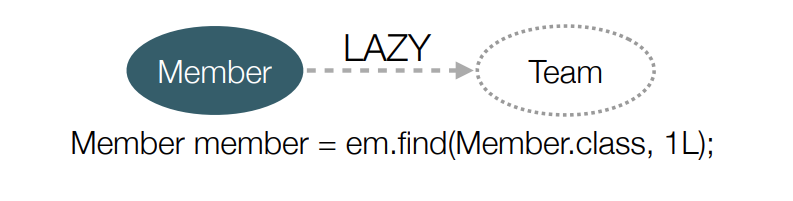
프록시(Proxy)란? 특정 객체를 호출하려고 할 때 해당 객체에 직접 요청하는 것이 아닌, 중간에 Proxy 객체(가짜)를 두어 Proxy 객체가 대신 요청을 받아 실제 객체를 호출해 주도록 하는 것이다. 프록시 패턴을 쓰는 일반적인 이유는 접근을 제어하고 싶거
9.JPA(Java Persistence API) 기초
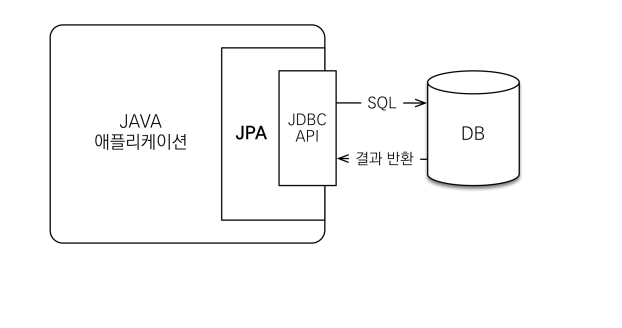
Java Persistence API자바 진영의 ORM 기술의 표준Object-relational mapping객체와 데이터베이스의 차이를 ORM 프레임워크가 중간에서 매핑하여 해결해준다.JPA는 쿼리를 작성해주기 때문에, 기존의 애플리케이션 개발 방식인 객체 중심으로
10.[JPA] @Transactional의 readOnly는 내부적으로 어떻게 성능 향상을 도와줄까?

조회 전용 트랜잭션에 readOnly = true 속성을 사용하면 성능을 높일 수 있으며, 불필요한/의도하지 않은 데이터의 변경을 예방할 수 있다.지금까지는 이 정도로만 알고 사용해왔지만, 내부적으로 어떻게 동작하는지는 몰랐다. JPA 기초 (영속성 컨텍스트와 dir
11.[JPA] Fetch join + Paging 에러
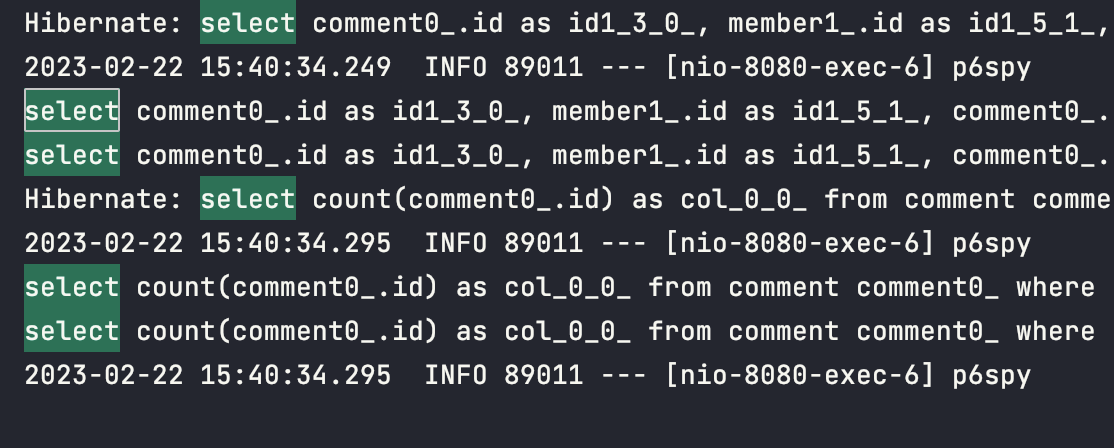
Spring Data JPA를 사용하여 fetch join + paging을 시도하던 도중 다음과 같은 에러를 만났다.현재 Comment와 Member 테이블 (N:1)이 존재하고, Comment List 조회 시 Member(작성자) fetch join + pagin
12.[JPA] @Query를 사용한 Update 쿼리 에러

Update는 Spring Data JPA에서 메서드 명명법을 지원하지 않는다고 한다. Dirty Cheking이라는 편리한 기능을 제공하기 때문인 것 같다.따라서 다음 두가지 방법을 사용할 수 있다.Dirty Checking직접 쿼리대부분 1번 방식을 사용할 것이고,
13.(JPA) 비밀번호 암호화에 Converter 적용해보기