쓰레드는 경량급 프로세스이다. 포크할 때 메모리를 복제하는 중량급 프로세스와 달리, 쓰레드는 data, heap, open file 등 많은 부분을 공유하기 때문에 시간이 적게 걸리고, 메모리도 적게 든다.
call stack은 function call을 했을 때 돌아갈 위치가 쌓이는 곳인데, 그렇다면 이 stack 공간만은 따로 가져야한다고 생각할 수 있다. 그러나 실제로 쓰레드에서는 이 메모리를 따로 만드는 대신, stack pointer를 통해 프라이빗 스택과 유사한 동작을 한다.
그러나 process와 thread 모두 CPU를 차지하기 위해 경쟁한다는 점은 변하지 않는다.
멀티 쓰레드 프로그램에서 프로세스는 주소 공간을 주는 모체라고 생각할 수 있다. 이 주소 공간 속에서 쓰레드 여러개가 돌아간다. 쓰레드는 몇 개를 만들든 모두 sibling 관계이다.
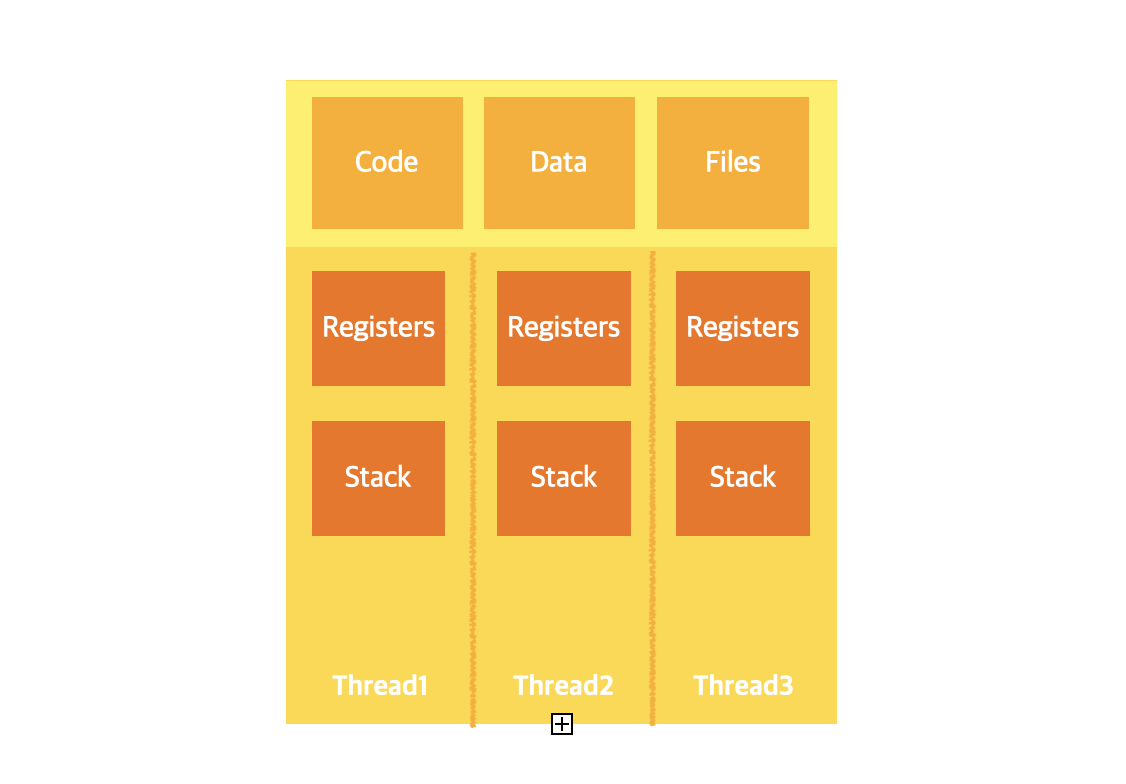
메모리를 공유한다는 것은 어떤 의미일까? 우선 fork를 해서 위의 영역들을 복제하는 프로세스의 경우, 통신을 위해 파이프를 사용한다. 그러나 쓰레드는 데이터 영역을 공유하기 때문에, 이런 파이프 없이도 쓰레드끼리의 통신이 용이하다. 그러나, 이 공유하는 영역은 critical section이 된다는 문제점을 갖는다.
프로세스에서는 자신을 fork한 자식 프로세스(카피하긴 했지만 전혀 다른 프로세스. 부모의 데이터를 물려받긴하지만 따로 존재)가 exit()하는 것은 wait()해야하고, 쓰레드에서는 메인 쓰레드가 자신이 만드는 여러 쓰레드들의 작업이 끝나기를 기다렸다가 join()한다.
