gRPC는 HTTP/2.0을 기반으로 하는데,
HTTP/2.0과 1.1은 모두 long lived connection이라는 공통점이 있지만, HTTP/2.0는 1.1과는 달리 multiplexing 기술을 connection에 적용한다는 차이점이 있다.
HTTP/1.1은 멀티플렉싱을 적용하지 않기 때문에, 커넥션이 오래 살아있더라도 커넥션 하나를 이용해서는 한 순간에 하나의 요청만 주고 받을 수 있다. 따라서 클라이언트는 하는 수 없이 동일 서버와 여러 개의 커넥션을 맺고 동시에 데이터를 주고 받는다.
한편, HTTP/2.0은 멀티플렉싱으로 이러한 문제를 개선했고, 하나의 커넥션으로 동시다발적 요청을 처리할 수 있다.
=> 언뜻 보기에는 장점만 있을거 같지만, 이러한 변화는 connection 레벨의 로드밸런싱(커넥션 별로 서로 다른 파드에 요청을 주는 방식)을 불가능하게 한다.
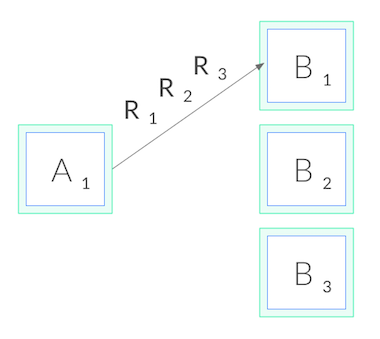
위 사진과 같이, 한 번 connection을 맺으면 하나의 파드가 모든 부하를 받게 된다.
이 문제의 해결 방법?
HTTP/2.0에서 과거와 같이 모든 파드들이 동등하게 부하를 받도록 하기 위해서는,
connection level load balancing에서 request level load balancing으로의 전환이 필요하다.
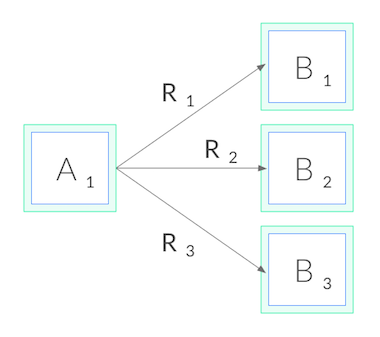
그런데 이것은, 더 이상 로드밸런싱을 네트워크 밑단인 L3/L4 layer가 아닌, L5/L7 layer에서 담당해야함을 의미한다.
이를 위한 구체적인 방안은 다음과 같다.
- 앱 레벨에서 로드밸런싱 풀을 static하게(혹은 유레카 등 툴을 이용해서 동적으로?) 관리하며 부하를 분산한다
- 앱을 headless 서비스로 변경하고(ClusterIp 가 할당되지 않고, kube-proxy가 해당 서비스를 관리하지 않는다), 클라이언드에서 각 파드를 직접 찌를 수 있게 한다. (찌르는 방식은 구현에 따라 다름)
- lightweight proxy(경량 프록시)를 사용한다.
Istio와 Linkerd (Service Mesh)
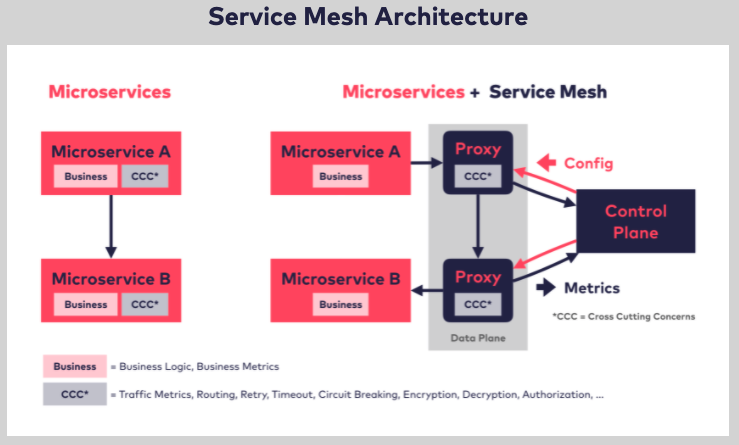
마이크로서비스 간에는 공통의 외부 프록시를 이용해서 통신했던 이전과 달리,
마이크로서비스마다 앞단에 경량 프록시와 이를 관리할 수 있는 control plane을 붙여서 로드밸런싱을 수행하는 방식.
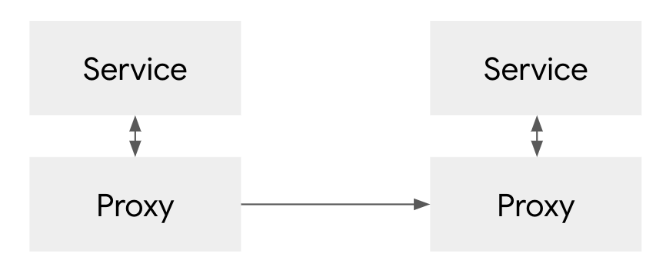
이렇게 하면 기존 TCP 기반 프록시의 한계를 극복하고, 더 나아가 서비스로 들어가고 나오는 트래픽을 프록시가 네트워크 단에서 통제하며 다양한 기능을 붙일 수 있다.
이 글을 쓰면서 여기서 말하는 부하분산이 어떤 레벨의 부하 분산인지가 좀 헷갈린다고 느꼈다.
클러스터가 여러개라면 클러스터를 고르는 방식일 수도 있고, 여러 파드 중 하나를 고르는 방식일 수도 있고...
만약 cluster 앞단의 진입점으로 ingress nginx를 쓴다면 nginx에서는 클러스터 부하분산을 담당한다.
이렇게 클러스터에 들어가면 또 하나의 서비스로 파드들이 묶여있는데, 이 부하분산은 아마 kube-proxy에서 담당하는 것 같다.
부하분산을 하는 주체는 다르지만 테크닉은 거의 유사한 것 같다.
주로 default 옵션은 라운드로빈이고, 그 외에 least connection, source hashing(출발지 IP 주소를 해싱해서 서버 선택) 등 다양한 테크닉이 있는데, 이 기법들은 부하분산의 주체마다 지원하는 것이 다르다.
kube-proxy는 또 다양한 모드들이 있는데, 이 모드(userspace/iptables/IPVS mode)에 따라서 kube-proxy가 네트워킹을 관리하는 방식이 다른 것 같다.
(kube-proxy에 대한 자세한 설명은 요 블로그 참조: https://ikcoo.tistory.com/130)
https://kubernetes.io/blog/2018/11/07/grpc-load-balancing-on-kubernetes-without-tears/
https://techdozo.dev/grpc-load-balancing-on-kubernetes-using-headless-service/
https://daddyprogrammer.org/post/13700/service-mesh/
