Elastic Search (3) Logstash (Connect with Mysql)

Logstash
오픈 소스 서버 측 데이터 처리로 파이프라인의 역할을 하고 있다. 다양한 소스에서 동시에 데이터를 수집하여 변화는 과정을 거치고 그다음 자주 사용하는 일래스틱 서치에 전달하게 된다. 물론 다른 출력으로도 전달이 가능한다.
Logstash Pipeline
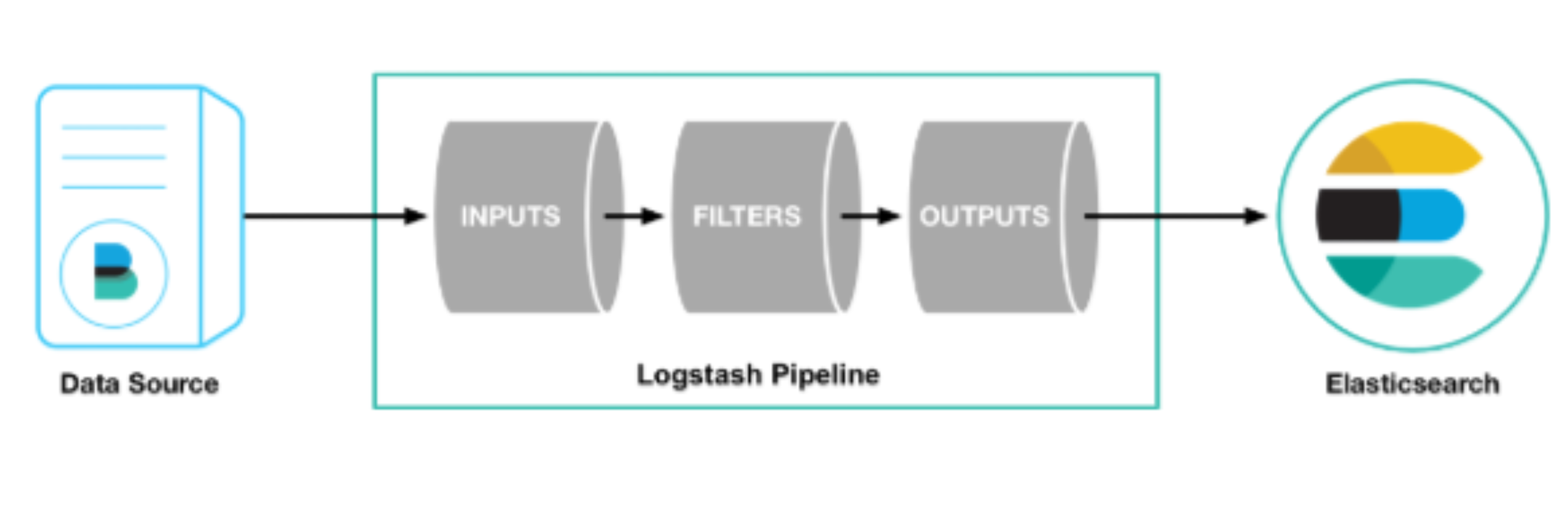
Logstash Pipeline은 총 3가지로 구성되어 있다. Inputs, Filter, Outputs
- Inputs : 모든 형태, 크기, 소스의 데이터 수집한다. 형태가 매우 자유롭게 때문에 대부분의 데이터를 가져올 수 있다.
- Filters : 데이터 이동 과정에서의 구문 분석 및 변환 처리를 한다.
- Outputs : 스태시를 선택하여 데이터 전송한다.
Inputs
- file : UNIX 명령 tail -0F와 매우 비슷하게 파일 시스템의 파일에서 읽음
- syslog : RFC3164 형식에 따라 syslog 메시지 및 구문 분석을 위해 잘 알려진 포트 514를 수신
- redis : redis 채널과 redis 목록을 모두 사용하여 redis 서버에서 읽음
- beat : Filebeat에서 보낸 이벤트를 처리합니다.
Filters
- grok : 임의의 텍스트를 구성. 임의의 텍스트를 구성 현재 구조화되지 않은 로그 데이터를 구문 분석
- mutate : 이벤트 필드에서 일반적인 변환을 수행합니다. 이벤트의 이 및 데이터 수정 및 제거 - - drop : 이벤트를 완전히 삭제
- clone : 이벤트를 복사
- geoip : IP 주소의 지리적 위치에 대한 정보를 추가 (Kibana의 지도 차트로 사용)
Outputs
- elasticsearch : Elasticsearch에 데이터 전송. 데이터를 효율적이고 편리하며 쉽게 쿼리 형식으로 저장
- file : 이벤트 데이터를 디스크의 파일로 저장
- graphite : 이벤트 데이터를 Graphite에 전송. 이 데이터는 통계를 저장하고 그래프로 나타내기 위한 널리 사용되는 오픈 소스 도구(http://graphite.readthedocs.io/ko/latest/)
- statsd : statsd에 이벤트 데이터를 전송. “카운터 및 타이머와 같은 통계를 수신하고 UDP를 통해 전송되며 하나 이상의 플러그 가능한 백엔드 서비스의 집계를 보내는” 서비스
Connect with Mysql
기존에 있는 DB를 elastic search와 연동을 시켜줄 것이다. 필자는 이미 logstash와 DB가 존재한다는 가정하에 진행하겠습니다.
pipeline.yml
logstash의 성절 파일을 변경해 줄 것이다. 대부분 주석 처리되어 있어 실질적인 내용은 없는 것과 마찬가지이다.
pipeline.id: "mysql"
path.config: "/Users/sunhobaik/Desktop/lo-711/mysql.conf"
필자는 mysql에 데이터 베이스와 연동할 것이기 때문에 mysql로 변경해 주었고 config 파일을 생성할 위치를 미리 지정해 주었다. 반드시 해당하는 위치에 config 파일이 존재해야 한다.
JDBC
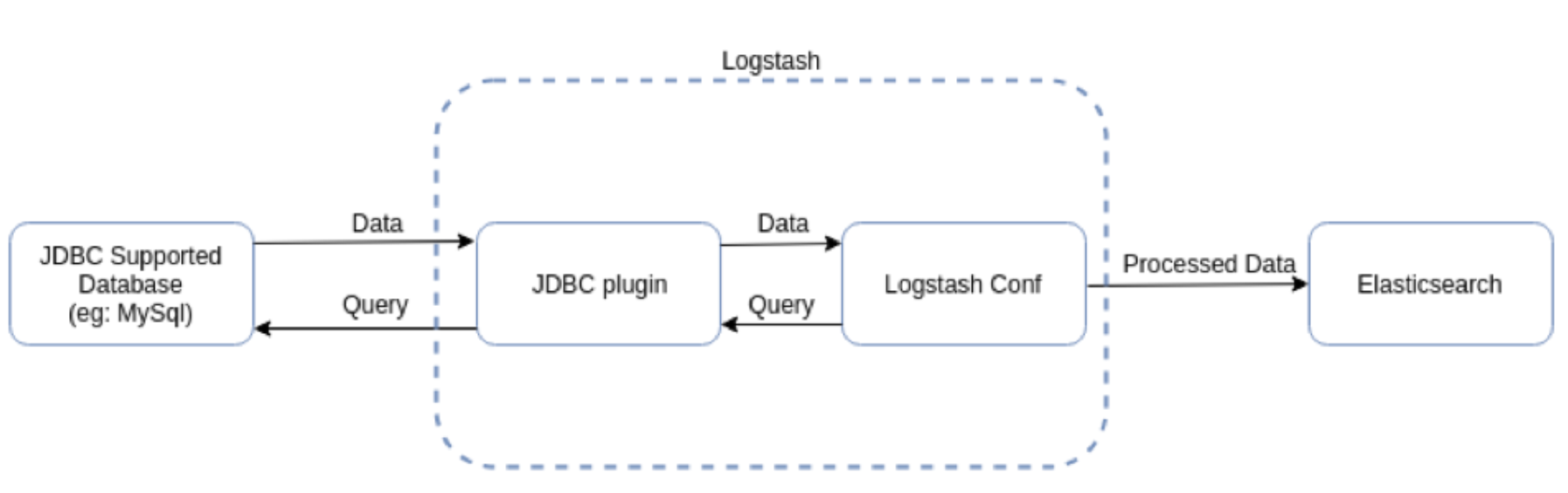
codfig 파일을 작성하기 전에 JDBC는 기본적으로 제공되지가 않기 때문에 다운로드해야 한다. JDBC는 다양한 데이터 소스에 대응하는 많은 인풋 플러그인을 가지고 있고 플러그인 구조로 확장이 가능하기 때문에 모든 데이터 소스에서 데이터를 불러오는 데 편리하게 활용이 된다. 즉 쉽게 말해 DB에서 logstash를 연동해 주는 플러그인이라고 생각하면 된다.
Mysql Connector
RDBMS의 connector jar 라이브러리를 설치한다. mysql의 경우 mysql-connector-java.jar를 다운로드해서 logstash의 lib 폴더에 넣어준다. 추후의 경로를 찾기 쉽게 하기 위해서이다.
.conf
input {
jdbc {
jdbc_driver_library => "/Users/sunhobaik/Desktop/lo-711/mysql-connector-java-8.0.25.jar"
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_connection_string => "jdbc:mysql://localhost:3306/database 계정명"
jdbc_user => "database 계정명"
jdbc_password => "database 비밀번호"
schedule => "* * * * *"
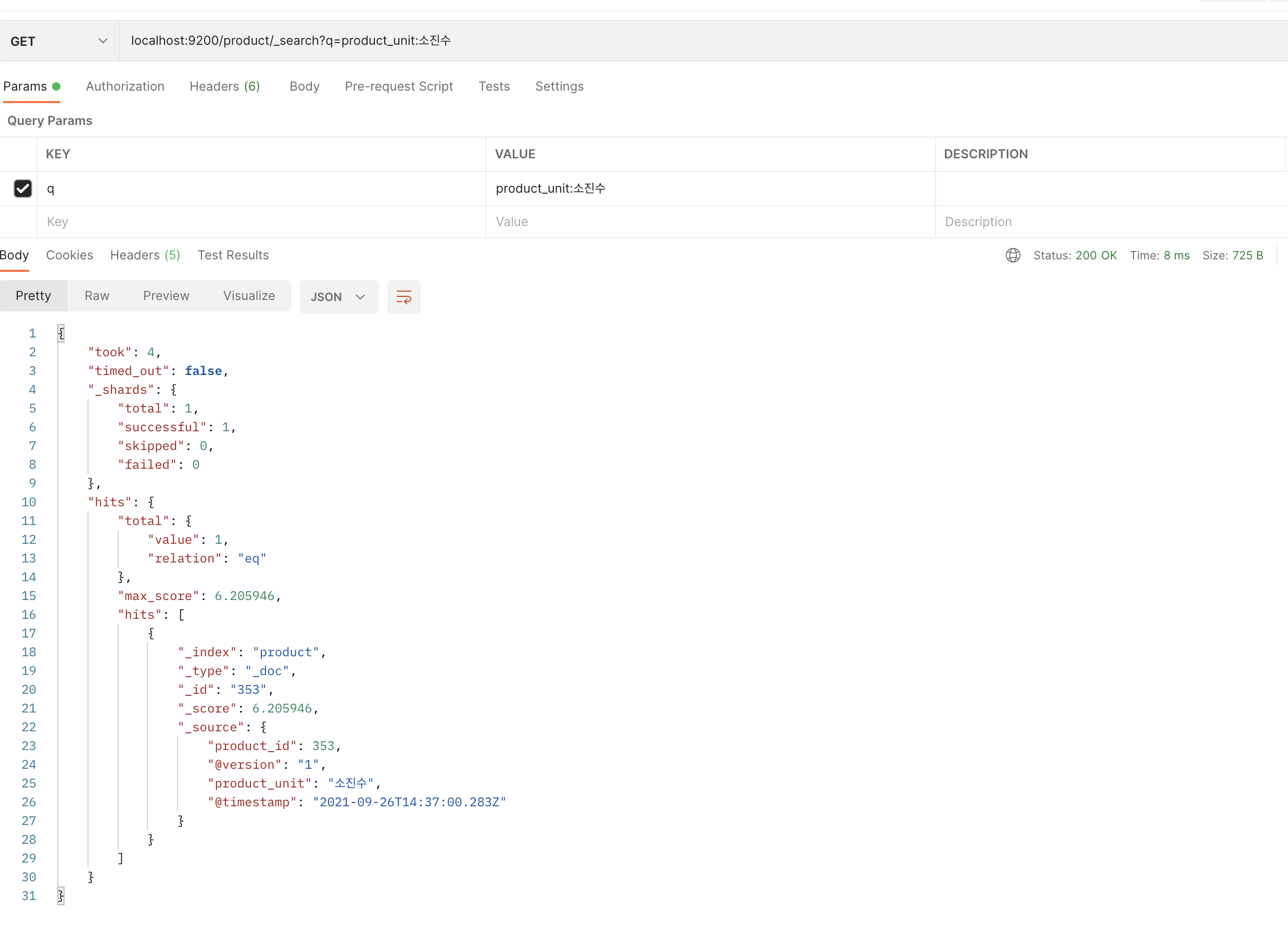
statement => "SELECT product_id ,product_unit FROM scm_product"
}
}
filter {
ruby {
}
mutate {
}
}
output {
elasticsearch {
hosts => ["localhost:9200"]
index => "product"
document_id => "%{product_id}"
}
stdout { codec => "rubydebug"}
}Input에는 Mysql에 대한 설정이 들어간다.
- jdbc_driver_library : Mysql Connector jar 설치 경로
- jdbc_driver_class : mysql 드라이버 클래스
- jdbc_connection_string : Mysql에서 가져올 DB
- schedule : Sql Query 실행하는 주기. 필자는 매 분마다 실행되도록 설정되어 있으며 schedule을 설정하지 않으면 한 번만 실행된다.
- statement: 직접 Sql 문을 지정하여 원하는 칼럼만 가져온다. SQL 문을 파일을 읽어 실행할 수도 있다.
Output에는 연결해 줄 Elastic Search에 대한 설정이 들어간다.
- host: Elasticsearch의 호스트 주소를 설정
- index: 생성할 index 명 설정
- document_id: RDBMS의 Row에 해당된다. Primary Key를 지정해 준다.
Start Logstash


완성된. conf와 함께 logstash를 실행하면 설정된 Scheduler에 따라 Elastic Search와 연동되게 된다. 또 http://localhost:9200/_cat/indices에 들어가서 index가 잘 생성되었는지 확인할 수 있다. 아직 yellow 지만 시간이 지나면 green으로 변할 것이다.