
여러방면으로 이용되는 Transformer 구조의 바탕이 되는 Sequence to Sequence란 무엇일까? 해당논문을 바탕으로 정리해보았다.
Architectrue
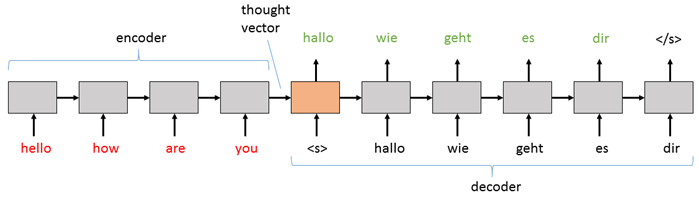
- DNN은 고정된 input, output의 차원을 지정해야 해야 하기 때문에 음성이나 자연어 시계열 같은 sequential data에 사용하기 어렵다
- seq2seq 구조는 크게 입력을 받는 인코더와 출력하는 디코더로 이루어진 구조이다.
- 인코더에서 input sequence는 고정된 길이의 context vector를 생성한다.
- 디코더에서 위의 context vector를 넘겨 받아 시작을 의미하는 토큰을 차례로 output sequence를 출력한다.
- 👩🏫왜 시작하는 토큰을 넣어주나요?
해당 논문에서는 인코딩이 끝났다는 의미로<EOS>토큰을 넣어주게 된다. 그 신호를 받은 디코더에서 예측을 순차적으로 진행하고 끝이나면<EOS>가 붙는 구조이다. 이와 같은 구조 때문에 input, output의 차원이 달라도 되는 것이다.
input과 output 차원을 정해주지 않았기 때문에 인코더와 디코더의 구분을 지어주는 역할. 그리고 각각의 과정(인코딩, 디코딩)을 끝내는 역할이라고 설명할 수 있다.
- 👩🏫왜 시작하는 토큰을 넣어주나요?
- 위 논문(Sequence to Sequence Learning with Neural Networks(2014))에서는
LSTM을 각 인코더/디코더에 사용한다.
RNN / LSTM / GRU
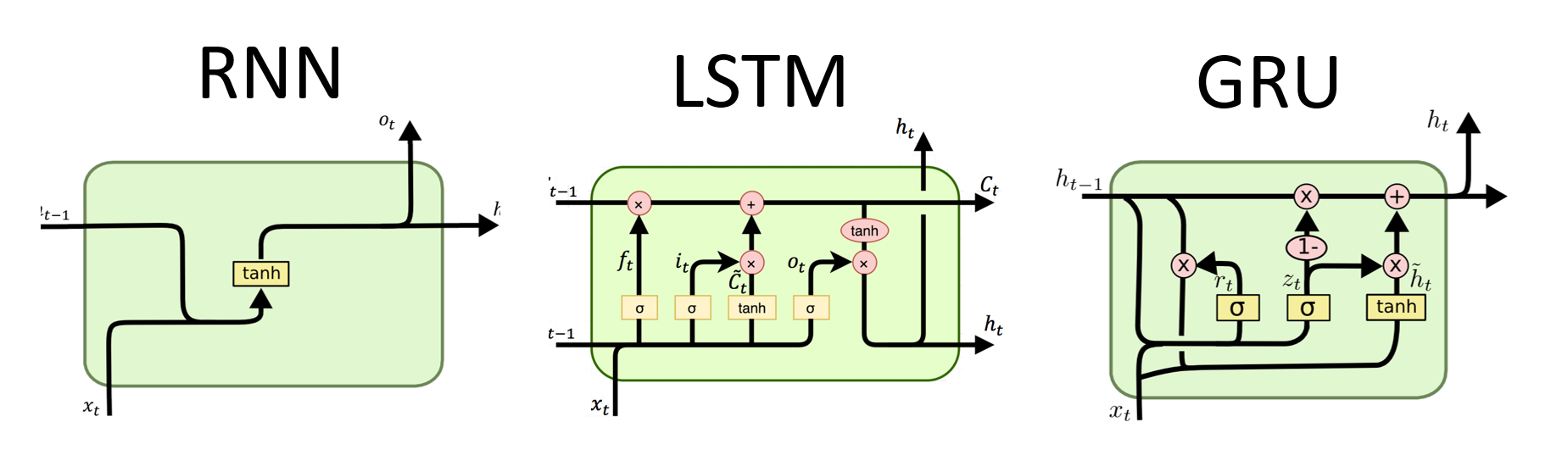
-
RNN(Recurrent Neural Network) *vanilla RNN
RNN에서 장기의존성이라는 문제가 발생하는데, 그 이유는 그림에서 보이는tanh를 활성화 함수로 사용하기 때문이다.장기의존성(long term dependency)
은닉층의 과거의 정보가 마지막까지 전달되지 못하는 현상-tanh(hyperbolic tangent)
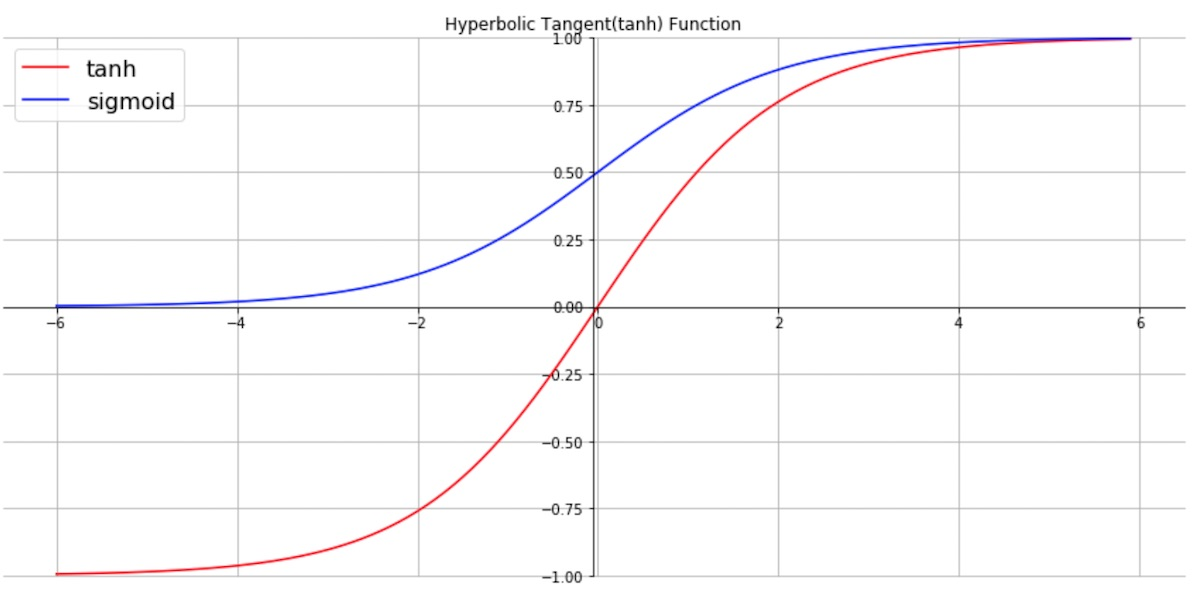
http://taewan.kim/post/tanh_diff/
→ 함수는 (-1~1)의 출력 값을 가지고 있어 1보다 작은 값이 계속 곱해지므로 긴 문장일수록 앞의 정보를 충분히 전달하기 어렵다.
-
[LSTM]
RNN의 장기의존성 문제를 해결하고자 고안되었고, Memory-Cell이라는 것이 추가되었다.- Forget gate
과거의 정보를 얼마나 잊을지 결정한다.
현시점의 정보와 과거의 은닉층의 값에 각각 가중치를 곱하여 더한 후 sigmoid 함수를 적용해 1에 가까울 수록 과거정보를 많이 활용. (0에 가까울수록 과거정보(기존에 가진 것)을 많이 잃는다.) - Input gate + Candidate
현 시점의 정보를 얼마나 입력할 지에 대해 결정한다.
그리고 현시점의 정보를 계산하는 입력후보 - Output gate
계산된 memory cell를 다음 hidden states로 얼마나 보낼 지 결정한다.
- Forget gate
-
[GRU]
LSTM의 구조가 복잡하고 연산량이 많아 시간이 오래걸리는 것을 개선하고자 단순화했다.-
과거의 은닉정보를 얼마나 무시할지 결정
-
은닉층에 정보갱신 (update gate)
-
The model
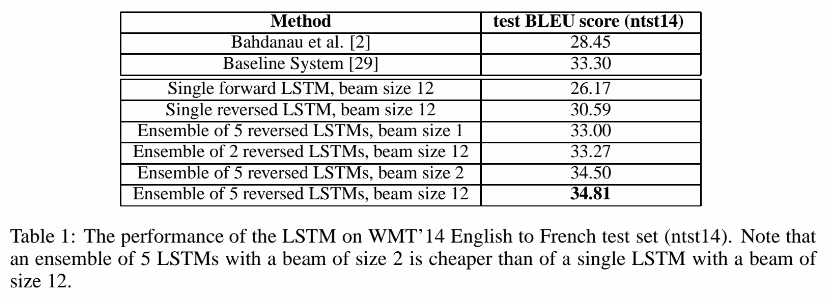
*여러개의 LSTM을 조합했을 때, beam size가 작은 경우에도 높은 성능을 보임
1) Decoding
왼쪽에서 오른쪽으로 진행되며 가능성이 높은 k개를 찾는 Beam Search Decoder 를 사용했고, beam size(k)가 1인 경우(=Greedy Search)에도 좋은 성능을 보였다.
2) Reversing the Source Sentences
problem
👉 a b c → α β γ
.
training
👉 c b a → α β γ
-
a b c 와 α β γ 를 매핑 하고자 할 때 a b c의 순서를 바꾸어 c b a 로 학습시킨다.
-
이 경우에 시작 하는 단어인
a와 타겟인α의 거리가 가까워 지며 source 문장과 target문장에 각 단어가 멀리 떨어져 있는 minimal time lag 문제를 해결한다. -
이와 같이 source sentences를 역순으로 뒤집는 방법을 통해 성능을 향상시켰다.
- input과 output의 어순이 비슷한 경우(위 논문의 경우 영어-프랑스어)에 높은 성능을 보이지만 문법구조가 다른 (ex. 한국어-영어)경우에는 큰 성능향상을 기대할 수 없다.
❓
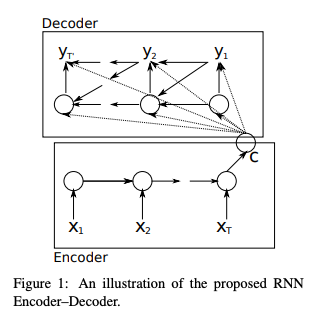
1. Learning Phrase Representations using RNN Encoder–Decoder
for Statistical Machine Translation (2014)와의 차이점? LSTM?
Encoder-Decoder Long Short-Term Memory Networks - Machine Learning Mastery
> Encoder-Decoder LSTM Architecture 부분 참고→ Seq2Seq 모델의 바탕이 된 구조(인코더와 디코더 연결). RNN을 이용함.
정리
알고있는 개념이라고 생각했지만 누군가에게 알려주기 위한 목적, 또는 이후에 내가 다시 읽어볼 목적으로 정리하는 것은 쉬운 일이 아니구나...
정리하면서 정확하게 개념을 확립하는 계기가 되었다. 어떻게 정리하고 구성하는 것이 좋을지 고민해보아야 겠다.
참고
https://github.com/microsoft/CNTK/blob/master/Tutorials/CNTK_204_Sequence_To_Sequence.ipynb
http://dprogrammer.org/rnn-lstm-gru
