
📌SimpleJpaRepository
✅어노테이션 기능
@Repository
@Transactional(readOnly = true)
public class SimpleJpaRepository<T, ID> implements JpaRepositoryImplementation<T, ID>
@Repository
- 컴포넌트 스캔의 대상이 되어 IoC 컨테이너에 등록된다.
- JPA, JDBC는 exception이 다르기 때문에 spring에서 제공하는 exception으로 변경된다.
- 하부 구현체를 바꿔도 기존 비즈니스 로직에 영향을 주지 않는다.
@Transactional
- JPA의 모든 변경은 트랜잭션 안에서 동작한다.
- Spring Data JPA는 변경(등록, 수정, 삭제) 메서드를 트랜잭션 처리한다.
- 서비스 계층에서 트랜잭션을 시작하지 않으면 리파지토리에서 트랜잭션을 시작한다.
- 서비스 계층에서 트랜잭션을 시작하면 리파지토리는 해당 트랜잭션을 전파 받아서 사용한다.
@Transactional(readOnly = true)
- 데이터를 단순히 조회만 하고 변경하지 않는 트랜잭션에서 사용하면 플러시를 생략해서 약간의 성능 향상을 얻을 수 있다.
✅save() 메서드
@Transactional
@Override
public <S extends T> S save(S entity) {
Assert.notNull(entity, "Entity must not be null.");
if (entityInformation.isNew(entity)) {
em.persist(entity);
return entity;
} else {
return em.merge(entity);
}
}entityInformation.isNew(entity) 를 사용하여 엔티티가 새로운 엔티티인지 디비에서 가져온 엔티티인지 판별하여 새로운 엔티티면 em.persist()하여 저장하고 디비에서 가져온 엔티티면 em.merge()하여 병합(update)한다.
em.merge()는 해당 데이터가 있는지 조회 쿼리를 한번 보내고 병합을 시도하기 때문에 성능면에서 좋지 않다.
새로운 엔티티를 판별하는 방법❓
식별자(PK)값이 null이면 새로운 엔티티로 판별하게 된다.
@Transactional @Override public <S extends T> S save(S entity) { Assert.notNull(entity, "Entity must not be null."); // 아래줄에 중단점 설정 if (entityInformation.isNew(entity)) { em.persist(entity); return entity; } else { return em.merge(entity); } }
if(entityInformation.isNew(entity))에 중단점을 설정하고@Test public void save() { Item item = new Item(); itemRepository.save(item); }해당 테스트 코드를 실행하면
id = null 이므로 새로운 객체로 판별된다.
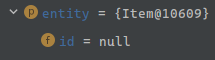
이후
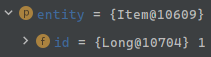
em.persist()호출이 되고
id = 1 이 된다.

으쌰 으쌰