Ch 02. 컴퓨터 시스템의 구성
01. 컴퓨터 하드웨어의 구성
컴퓨터 시스템은 데이터를 처리하는 물리적 기계장치인 하드웨어(hardware)와 어떤 작업을 지시하는 명령어로 작성한 프로그램인 소프트웨어(software)로 구성된다. 운영체제(OS : Operating System)는 컴퓨터 하드웨어를 관리하는 소프트웨어이다. 컴퓨터 하드웨어는 크게 프로세서, 메모리(기억장치), 주변장치로 구성되고, 이들은 시스템 버스로 연결된다.
1. 프로세서
프로세서(processor)는 컴퓨터 하드웨어에 부착된 모든 장치의 동작을 제어하고 명령을 실행한다. 중앙처리장치(CPU : Central Processing Unit)이라고도 한다.
(1) 프로세서 구성
프로세서는 연산장치, 제어장치, 레지스터로 구성되고, 이들은 내부 버스로 연결된다.
(2) 레지스터의 구분
레지스터는 여러 관점에서 구분할 수 있다.
용도에 따른 구분 : 전용 레지스터와 범용 레지스터로 구분한다.
정보의 종류에 따른 구분 : 데이터 레지스터, 주소 레지스터, 상태 레지스터 등으로 세분화할 수 있다.
사용자가 정보를 변경할 수 있는지에 따른 구분
사용자 지시(user-visible) 레지스터
사용자가 운영체제와 사용자 프로그램을 이용하여 정보를 변경할 수 있고, 접근이 가능한 데이터와 주소, 일부 조건 코드를 보관한다.
데이터 레지스터(DR :Data Register) : 함수 연산에 필요한 데이터를 저장한다. 값, 문자 등을 저장하므로 산술 연산이나 논리 연산에 사용하며, 연산 결과로 플래그 값을 저장한다.
주소 레지스터(AR : Address Register) : 주소나 유효 주소를 계산하는 데 필요한 주소의 일부분을 저장한다. 주소 레지스테 저장한 값(데이터)을 사용하여 산술연산을 할 수 있따.
기준 주소 레지스터, 인덱스 레지스터, 스택 포인터 레지스터로 세분한다.
기준 주소 레지스터 : 프로그램을 실행할 때 사용하는 기준 주소 값을 저장한다. 기중 주소는 하나의 프로그램이나 일부처럼 서로 관련 있는 정보를 저장하며, 연속된 저장 공간을 지정하는데 참조할 수 있는 주소이다. 따라서 기준 주소 레지스터는 페이지나 세그먼트처럼 블록화된 정보에 접근하는 데 사용된다.
인덱스 레지스터 : 유효 주소를 계산하는데 사용하는 주소 정보를 저장한다.
스택 포인터 레지스터 : 메모리에 프로세서 스택을 구현하는 데 사용한다. 많은 프로세서와 주소 레지스터를 데이터 스택 포인터와 큐 포인터로 사용한다. 일반적으로 반환 주소, 프로세서 상태 정보, 서브루틴의 임시 변수를 저장한다.
사용자 불가시(user-invisible) 레지스터
사용자가 정보를 변경할 수 없는 레지스터로 프로세서의 상태와 제어를 관리한다.
프로그램 카운터(PC : Program Counter) : 다음에 실행할 명령어의 주소를 보관하는 레지스터이다. 계수기로 되어 있어 실행할 명령어를 메모리에서 읽으면 명령어의 길이만큼 증가하여 다음 명령어를 가리키며, 분기 명령어는 목적 주소를 갱신할 수 있다.
명령어 레지스터(IR : Instruction Register) : 현재 실행하는 명령어를 보관하는 레지스터이다.
누산기(ACC : ACCumulator) : 데이터를 일시적으로 저장하는 레지스터이다.
메모리 주소 레지스터(MAR : Memory Address Register) : 프로세서가 참조하려는 데이터의 주소를 명시하여 메모리에 접근하는 버퍼 레지스터이다.
메모리 버퍼 레지스터(MBR : Memory Buffer Register) : 프로세서가 메모리에 읽거나 메모리에 저장할 데이터 자체를 보관하는 버퍼 레지스터이다. 메모리 데이터 레지스터(MDR : Memory Data Register)라고도 한다.
프로세서 수가 많을수록 처리 속도가 빠르다. 탑재한 프로세서 수가 한 개인 싱글코어(Single core), 2개인 듀얼코어(Dual Core), 3개인 트리플코어(Triple Core), 4개인 쿼드코어(Quad Core), 6개인 핵사코어(Hexa Core), 8개인 옥타코어(Octa Core) 등이 있다.
2. 메모리
메모리는 컴퓨터 성능과 밀접하다. 사용자는 당연히 크고 빠르다. 사용자는 당연히 크고 빠르며 비용이 저렴한 메모리를 요구하지만 속도가 빠른 메모리는 가격이 비싸므로 일반적으로 메모리 계층 구조를 구성하며 비용, 속도, 용량, 접근시간 등을 상호보완한다.
속도는 느리나 용량이 큰 보조기억장치부터 속도는 빠르나 용량이 작은 레지스터까지 메모리의 종류는 다양하다. 메모리 계층 구조는 메인 메모리를 중심으로 아래에는 대용량의 자기디스크, 이동이 편리한 광디스크, 하일을 저장하는 속도가 느린 자기테이프가 있다. 그리고 메인 메모리 위에는 프로세서의 속도 차이를 보완하는 캐시가 있고, 최상위에는 프로세서가 사용한 데이터를 보관하는 가장 빠른 레지스터가 있다.
메모리 계층 구조는 1950~60년대 너무 비싼 메모리의 가격 문제 때문에 제안한 방법이 있다. 프로그램을 실행하거나 데이터를 참조하려면 모두 메인 메모리에 올려야 한다. 그렇다고 고가인 메인 메모리를 무작정 크게 할 수는 없어서 불필요한 프로그램과 데이터는 보조기억장치에 저장했다가 실행, 참조할 때만 메인 메모리로 옮기는 원리를 적용한 방법을 사용한다. 따라서 메모리 계층 구조는 비용, 속도, 크기(용량)가 다른 메모리를 효과적으로 사용함으로써 시스템의 성능을 향상시킨다.
메모리 기술이 발달하면서 SSD(Solid State Disk), NVRAM(Non-Volatile RAM) 등도 등장했다. SSD는 자기디스크로 된 하드디스크를 대체하려고 개발한 보조기억장치로 플래스 메모리로 구성되어 있고, 하드디스크보다 데이터 입/출력 속도가 빠르다. 하지만 하드디스크보다 용량이 작고 가격은 비싸 아직은 하드디스크가 대세이다. NVRAM은 외부 전원이 꺼지거나 상실되더라도, 내용은 보존되는 RAM이다.
(1) 레지스터
프로세서 내부에 있으며, 프로세서가 사용할 데이터를 보관하는 가장 빠른 메모리이다. 종류는 사용자 지시 레지스터와 사용자가 불가시 레지스터의 내용과 같다.
(2) 메인 메모리
프로그램 저장 또는 데이터 저장
프로세서 외부에 있으며, 프로세서에 즉각적으로 수행할 프로그램과 데이터를 저장하거나 프로세서에서 처리한 결과를 저장한다. 입/출력장치도 메인 메모리에서 데이터를 받거나 저장한다. 주기억장치 또는 1차 기억장치라고도 한다. 저장 밀도가 높고, 가격이 싼 DRAM(Dynamic RAM)을 많이 사용한다.
입/출력 병목 현상 해결
메인 메모리는 프로세서와 보조기억장치 사이에 있으며, 여기서 발생하는 디스크 입/출력 병목 현상을 해결하는 역할을 한다. 그런데 프로세서와 메인 메모리 간에 속도 차이가 나면서 메인 메모리의 부담을 줄이려고 프로세서 내부와 외부에 캐시를 구현하기도 한다.
메인 메모리의 주소 지정
메인 메모리는 다수의 셀(cell)로 구성되며, 각 셀은 비트로 구성된다. 셀이 k비트이면 셀에 2에 k승 값을 저장할 수 있다. 메인 메모리에 데이터를 저장할 때는 셀 한 개나 여러 개에 나눠서 저장한다. 셀은 주소로 참조하는데, n비트라면 주소 범위는 0~(2에 (n-1)승)
메모리 매핑
컴퓨터에 주어진 주소를 물리적 주소라고 한다. 프로그래머는 물리적 주소 대신 수식이나 변수를 사용한다. 그리고 컴파일러가 프로그램을 기계 명령어로 변환할 때 변수와 명령어에 주소를 할당하는데, 이 주소를 논리적 주소(가상 주소, 프로그램 주소)라고 한다. 논리적 주소는 별도의 주소 공간에 나타낸다. 컴파일러로 논리적 주소를 물리적 주소로 변환하는데, 이 과정을 매핑(사상 : mapping) 또는 메모리 맵(memory map)이라고 한다. 운영체제는 가상 메모리(virtual memory) 방법을 사용하며 메인 메모리의 유효 크기를 늘릴 수 있다.
메모리 접근 시간과 메모리 사이클 시간
메모리 속도는 메모리 접근 시간과 메모리 사이클 시간으로 표현할 수 있다. 일반적으로 사이클 시간이 접근 시간보다 약간 길며, 메모리의 세부 구현 방법에 따라 다르다.
메모리 접근 시간
명령이 발생한 후 목표 주소를 검색하여 데이터 쓰기(읽기)를 시작할 때까지 걸린 시간이다. 예를 들면 읽기 제어 신호를 가한 후 데이터를 메모리 버퍼 레지스터에 저장할 때까지 걸린 시간이다.
메모리 사이클 시간
두 번의 연속적인 메모리 동작 사이에 필요한 최소 지연시가닝다. 예를 들면 읽기 제어신호를 가한 후 다음 읽기 제어신호를 가할 수 있을 때까지 필요한 시간이다.
(3) 캐시
캐시의 개념
캐시(cache)는 메모리와 CPU 간의 속도 차이를 완화하기 위해 메모리의 데이터를 미리 가져와 저장해두는 임시 기억 장소이다. 캐시는 필요한 데이터를 모아 한꺼번에 전달하는 버퍼의 일종으로 CPU가 앞으로 사용할 것으로 예상되는 데이터를 미리 가져다 놓는다. 이렇게 미리 가져오는 작업을 '미리 가져오기(prefetch)'라고 한다.
캐시는 CPU 안에 있으며 CPU 내부 버스의 속도로 작동하고, 메모리는 시스템 버스의 속도로 작동하기 때문에 캐시에 비해 느리다. 캐시는 빠른 속도로 작동하는 CPU와 느린 속도로 작동하는 메모리 사이에서 두 장치의 속도 차이를 완화해준다.
캐시의 구조
캐시는 메모리의 내용 중 일부를 미리 가져오고, CPU는 메모리에 접근해야 할 때 캐시를 먼저 방문하여 원하는 데이터가 있는지 찾아본다. 캐시에서 원하는 데이터를 찾았다면 캐시 히트(cache hit)라고 하며, 그 데이터를 바로 사용한다. 그러나 원하는 데이터가 캐시에 없으면 메모리로 가서 데이터를 찾는데 이를 캐시 미스(cache miss)라고도 한다. 캐시 히트가 되는 비율을 캐시 적중률(cache hit ratio)이라고 하며, 일반적으로 컴퓨터의 캐시 적중률은 약 90%이다.
캐시의 적중률
컴퓨터의 성능을 향상시키려면 캐시 적중률을 높여야 한다. 캐시 적중률을 높이는 방법은 다음 두 가지가 있다.
캐시의 용량 증가
캐시 적중률을 높이는 방법 중 하나가 캐시의 크기를 늘리는 것이다. 캐시의 크기가 커지면 더 많은 데이터를 미리 가져올 수 있어 캐시 적중률이 올라간다. 클록이 같은 CPU라도 저가형과 고가형은 캐시의 크기가 다르다. 예를 들면 저가인 i7은 캐시 메모리가 4MByte이지만 고가의 i7은 8MByte 이상이 된다. 캐시는 가격이 비싸기 때문에 크기를 늘리는 데 한계가 있어 몇 MByte 정도만 사용한다.
앞으로 많이 사용될 데이터를 가져오기
캐시 적중률을 높이는 또 다른 방법은 앞으로 많이 용도리 데이터를 가져오는 것이다. 이와 관련된 이론으로는 현재 위치에 가까운 데이터가 멀리 있는 데이터보다 사용될 확률이 더 높다는 지역성(locality) 이론이 있다. 예를 들면 현재 프로그램의 100번 행이 실행되고 있다면 다음에 101번 행이 실행될 확률이 200번 행이 실행될 확률보다 더 높다. 따라서 현재 100번 행을 실행하는 경우 지역성 이론에 따라 101~120번 행을 미리 가져오면 된다.
웹 브라우저의 캐시
캐시는 소프트웨어적으로도 사용되는데 대표적인 예가 웹 브라우저 캐시이다. 웹에서 사용하는 캐시는 '앞으로 다시 방문할 것을 예상하여 지우지 않는 데이터'라고 정의할 수 있다. 네이버 같이 자주 방문하는 사이트의 경우 로고나 버튼들의 작은 그림이 자주 바뀌지 않으므로, 로고나 버튼 등의 데이터를 캐시에 보관하고 있다가 사이트를 다시 방문하면 캐시에 있는 데이터를 사용하여 웹 페이지가 열리는 속도를 높인다. 이처럼 웹 브라우저의 캐시는 방문했던 사이트의 데이터를 보관하여 재방문 시 속도를 높이는 역할을 한다. 그러나 너무 많은 데이터가 캐시에 보관되어 있으면 웹 브라우저의 속도를 떨어뜨릴 수 있으므로 가끔 청소를 하는 것이 좋다.
(4) 보조기억장치
주변장치 중 프로그램과 데이터를 저장하는 하드웨어로, 2차 기억장치 또는 외부기억장치라고도 한다. 자기디스크, 광디스크, 자기테이프 등이 있다. 메모리는 전자의 이동으로 데이터를 처리하지만 하드디스크나 CD와 같은 저장장치는 구동장치가 있는 기계이므로 속도가 느리다. 이렇게 느린 저장장치를 사용하는 이유는 저장용량에 비해 가격이 싸기 때문이다. 저장장치는 메모리보다 느리지만 저렴하고 용량이 크며, 전원의 온/오프와 상관없이 데이터를 영구적으로 저장한다.
시스템 버스
시스템 버스(System Bus)는 하드웨어를 물리적으로 연결하여 서로 데이터를 주고받을 수 있게 하는 통로이다. 컴퓨터 내부의 다양한 신호(데이터 입/출력 신호, 프로세서 상태 신호, 인터럽트 요구와 허가 신호, 클록 신호 등)가 시스템 버스로 전달된다. 시스템 버스는 기능에 따라 데이터 버스, 주소 버스, 제어 버스로 구분한다.
(1) 데이터 버스(data bus)
프로세서와 메인 메모리, 주변 장치 사이에서 데이터를 전송한다. 데이터 버스를 구성하는 배선 수는 프로세서가 한 번에 전송할 수 있는 비트 수를 결정하는데, 이를 워드라고 한다. 제어 버스가 다음에 어떤 작업을 할지 신호를 보내고 주소 버스가 위치 정보를 전달하면 데이터가 데이터 버스에 실려 목적지까지 이동한다. 데이터 버스는 메모리 버퍼 레지스터(MBR)와 연결되어 있으며 양방향이다.
(2) 제어 버스(Control Bus)
제어 버스에서는 다음에 어떤 작업을 할지 지시하는 제어신호가 오고 간다. 메모리에서 데이터를 가져올지 아니면 처리한 데이터를 옮겨놓을 지에 대한 지시 정보가 오고 가는데, 메모리에서 데이터를 가져올 때는 읽기 신호를 보내고, 처리한 데이터를 메모리로 옮겨놓을 때는 쓰기 신호로 보낸다. 주변 장치의 경우도 마찬가지로 하드디스크에 저장명령을 내리거나 사운드카드에 소리를 내라는 명령을 내릴 때 제어 버스를 통해 전달된다.
제어 버스는 CPU의 제어 장치와 연결되어 있다. 메모리에서 오류가 발생하거나 네트워크 카드에 데이터가 모두 도착했다는 신호는 모두 제어 버스를 통해 CPU로 전달된다. 제어 버스의 신호는 CPU, 메모리, 주변장치와 양방향으로 오고 간다.
(3) 주소 버스(address bus)
주소 버스에서는 메모리의 데이터를 읽거나 쓸 때 어느 위치에서 작업할 것인지를 알려주는 위치 정보(주소)가 오고 간다. 주변 장치의 경우도 마찬가지로 하드디스크의 어느 위치에서 데이터를 읽어올지, 어느 위치에 저장할지에 대한 위치 정보가 주소 버스를 통해 전달된다. 주소 버스는 메모리 주소 레지스터(MAR)와 연결되어 있으며 단방향이다. CPU에서 메모리나 주변장치로 나가는 주소 정보는 있지만 주소 버스를 통해 CPU로 전달되는 정보는 없다.
데이터 버스 :
메모리 버퍼 레지스터(MBR)와 연결된 버스로, 데이터의 이동이 양방향으로 이루어진다.
제어 버스 :
제어장치와 연결될 버스로, CPU가 메모리와 주변장치에 제어신호를 본개이 위해 사용된다. 메모리와 주변장치에서도 작업이 완료되거나 오류가 발생하면 제어신호를 보내기 때문에 양방향이다.
주소 버스 :
메모리 주소 레지스터(MAR)와 연결된 버스로 메모리나 주변장치에 데이터를 읽거나 쓸 때 위치 정보를 보내기 위해 사용하여 단방향이다.
(4) 버스의 대역폭(band width)
버스의 대역폭은 한 번에 전달할 수 있는 데이터의 최대 크기를 말한다. 8차선 도로는 한 번에 8대의 차가 동시에 다닐 수 있듯이 대역폭의 크기만큼 데이터가 오고 갈 수 있다. 버스의 대역폭은 CPU가 한 번에 처리할 수 있는 데이터의 크기와 같다. 흔히 32bit CPU, 64bit CPU라고 하는데 여기서 32bit, 64bit는 CPU가 한 번에 처리할 수 있는 데이터의 최대 크기이다. 32 bit CPU는 메모리에서 데이터를 읽거나 쓸 때 한 번에 최대 32bit를 처리할 수 있음, 이 경우 레지스터의 크기도 32bit, 버스의 대역폭도 32bit이다. 버스의 대역폭, 레지스터의 크기, 메모리에 한 번에 저장할 수 있는 데이터의 크기는 항상 같다. 참고로 CPU가 한 번에 처리할 수 있는 데이터의 최대 크기를 워드(word)라고 하며, 버스의 대역폭과 메모리에 한 번에 저장되는 단위도 워드이다. 32bit CPU에서 1워드는 32bit이다.
주변장치
주변장치는 프로세서와 메인 메모리를 제외한 나머지 하드웨어 구성요소이다. 단순히 입/출력 장치라도고 하나 크게 입력장치, 출력장치, 저장장치로 구분한다.
(1) 입력장치
컴퓨터에서 처리할 데이터를 외부에서 입력하는 장치이다
(2) 출력 장치
입력장치와 반대로 컴퓨터에서 처리한 데이터를 외부로 보내는 장치이다.
(3) 저장 장치
메인 메모리와 달리 거의 영구적으로 데이터를 저장하는 장치이다. 데이터를 입력하여 저장하며, 저장한 데이터를 출력하는 공간이므로 입/출력 장치에 포함하기도 한다.
저장장치는 자성을 이용하는 장치, 레이저를 이용하는 장치, 메모리를 이용하는 장치로 구분할 수 있다.
자성을 이용하는 장치는 카세트테이프, 플로피디스크, 하드디스크가 있고, 레이저를 이용하는 장치는 CD(Compact Disk), DVD(Digital Versatile Disk), 블루레이(Blue-Ray Disc) 등이 있다. 메모리를 이용하는 장치는 USB 드라이버(Universial Serial Bus Driver), SD 카드(Secure Digital card), CF 카드(Compact Flash card), SSD(Solid State Drive) 등이다.
폰 노이만 구조
오늘날 컴퓨터는 대부분 폰 노이만 구조(von Neumann architecture)를 따른다.
(1) 폰 노이만 구조의 개념
폰 노이만 구조는 CPU, 메모리, 입/출력장치, 저장장치가 버스로 연결되어 있는 구조를 말한다. 폰 노이만 구조가 등장하기 전의 컴퓨터는 전선을 연결하여 회로를 구성하는 하드 와이어링 형태였기 때문에 다른 용도로 사용하려면 전선의 연결을 바꾸어야 했다. 이러한 문제를 해결하기 위해 미국의 수학자 존 폰 노이만(John von Neumann)은 메모리를 이용하여 프로그래밍이 가능한 컴퓨터 구조, 즉 하드웨어는 그대로 둔 채 작업을 위한 프로그램만 교체하여 메모리에 올리는 방식을 제안했다. 폰 노이만 구조 덕분에 오늘날에는 프로그래밍 기술을 이용하여 컴퓨터로 다양한 작업을 할 수 있게 되었다.
(2) 폰 노이만 구조의 특징
폰 노이만 구조의 가장 중요한 특징은 '모든 프로그램은 메모리에 올라와야 실행할 수 있다'는 것이다. 예를 들면 워드프로세서 보고서를 작성한다고 가정해 보면 워드프로세서 프로그램과 보고서 파일은 저장장치인 하드디스크에 저장되지만 프로그램과 데이터가 저장장치에서 바로 실행되지 않는다. 저장장치에 있는 프로그램을 실행하려면 프로그램이 메모리에 올라와야 하며, 운영체제도 프로그램이기 때문에 메모리에 올라와야 실행이 가능하다. 폰 노이만 구조의 특징은 운영체제와 관련된 전반적인 내용을 이해하는데 밑거름이 된다.
02. 컴퓨터 시스템의 동작
컴퓨터 시스템으로 작업을 처리할 때는 다음 순서에 따라 동작하며, 제어장치가 이 동작을 제어한다.
(1) 입력장치로 정보를 입력받아 메모리에 저장한다.
(2) 메모리에 저장한 정보를 프로그램 제어에 따라 입출력하여 연산장치에서 처리한다.
(3) 처리한 정보를 출력장치에 표시하거나 보조기억장치에 저장한다.
입력장치로 컴퓨터에 유입되는 정보는 명령어와 데이터로 분류한다. 명령어는 실행할 산술/논리 연산의 동작을 명시하는 문장으로 어떤 작업을 수행하는 명령어 집합이 프로그램이다. 프로그램은 컴파일러 등을 이용하여 0과 1로 이진화된 기계 명령어로 변환해야 컴퓨터가 이해할 수 있다.
- 명렁어의 구조
명령어는 프로세서가 실행할 연산이 연산 부호와 명령어가 처리할 데이터, 데이터를 저장한 레지스터나 메모리 주소인 피연산자로 구성된다. 명령어는 프로세서에 따라 고정 길이나 가변 길이를 구성한다. 연산 부호는 특별한 경우가 아니면 한 개이나 피연산자는 여러 개일 수 있다.
(1) 연산 부호
연산 부호(Op code : Operation Code)는 프로세서가 실행할 동작인 연산을 지정한다. 예를 들면 산술연산, 논리연산, 시프트(shift), 보수 등 연산을 정의한다. 연산 부호가 n비트이면 최대 2에 n승 개의 연산이 가능하다.
(2) 피연산자
피연산자(operand)는 연산할 데이터 정보를 저장한다. 데이터는 레지스터나 메모리, 가상기억장치, 입/출력 장치 등에 위치할 수 있다. 일반적으로 데이터 자체보다는 데이터의 위치를 제공한다. 가장 일반적인 명령어 구조는 다음과 같다. 여기서는 피연산자가 2개로 하나는 소스 피연산자(source operand)이고, 다른 하나는 목적지 피연산자(destination operand)이다.
명령어의 실행
명령어 실행 과정
명령어는 다음과 같은 과정을 거쳐 실행한다/.
1. 명령어 인출 :
명령어 레지스터에 저장된 다음 명령어를 인출한다.
2. 명령어 해석, PC 변경 :
인출한 명령어를 해석하고 다음 명령어를 지정하려고 프로그램 카운터를 변경한다.
3. 피연산자 인출 :
명령어가 메모리에 있는 워드를 한 개 사용하려면 사용 장소를 결정하여, 피연산자를 인출하고, 필요하면 프로세서 레지스터로 보낸다.
4. 명령어 실행
5. 결과 저장
(2) 명령어 실행 사이클
프로세서의 제어장치가 명령어를 실행한다. 프로세서는 메모리에서 명령어를 한 번에 하나씩 인출하고 해석하여 연산한다. 명령어를 인출하여 연산 완료한 시점까지를 인출-해석-실행 사이킃 또는 인출-실행 사이클이라고 한다. 간단히 명령어 실행 사이클(명령어 실행 주기)이라고 한다.
명령어 실행 사이클은 명령어의 인출과 실행을 반복하는데, 가장 일반적인 명령어 사이클이다. 메모리 간접 주소 지정 방법은 실행 사이클을 시작하기에 앞서 그 데이터의 실제 주소를 기억장치에서 읽어오는 간접 사이클을 사용하기도 한다. 그리고 인터럽트를 처리하려고 인터럽트 사이클을 사용하기도 한다.
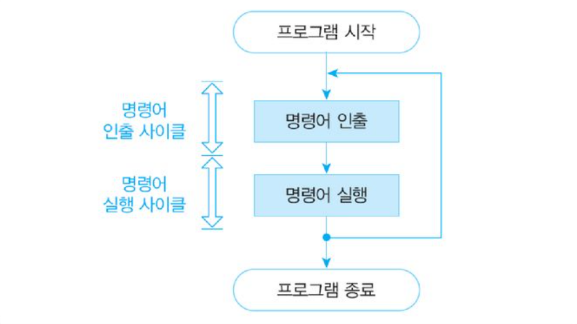
(3) 인출 사이클
인출 사이클(fetch cycle)은 명령어 실행 사이클의 첫 번계 이다. 인출 사이클은 메모리에서 명령어를 읽어 명령어 레지스터에 저장하고, 다음 명령어를 실행하려고 프로그램 카운터를 증가시킨다. 인출 사이클에 소요되는 시간을 명령어 인출 시간이라고 하는데, 이 사이클에서 시간에 따른 세부 동작은 다음과 같다.
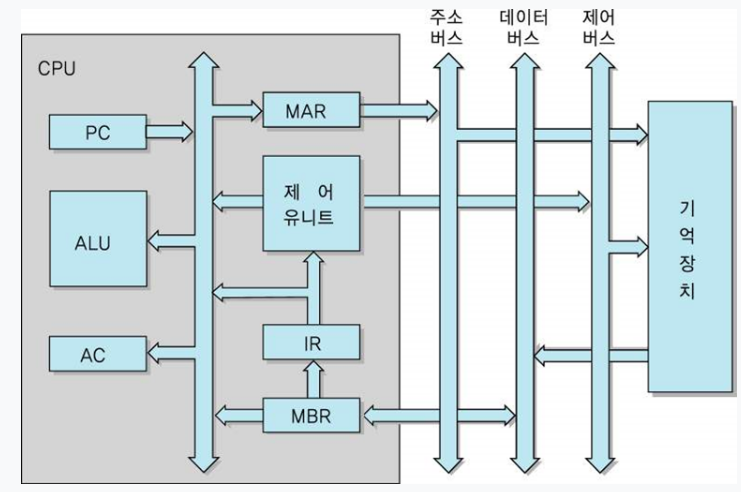
PC -> MAR :
PC에 저장된 주소를 프로세서 내부 버스를 이용하여 MAR에 전달한다.
MAR(Memory) -> MBR
MAR에 저장된 주소에 해당하는 메모리 위치에서 명령어를 인출한 수 이 명령어를 MBR에 저장한다. 이때 제어장치는 메모리에 저장된 내용을 읽도록 제어신호를 발생시킨다.
PC + 1 -> PC
다음 명령어를 인출하려고 PC를 증가시킨다
MBR -> IR
MBR에 저장된 내용을 IR에 전달한다.
(4) 실행 사이클
실행 사이클(execution cycle)에서는 인출한 명령어를 해독하고 그 결과에 따라 제어신호를 발생시켜 명령어를 실행한다. 이 단계에서 소비되는 시간을 실행 시간이라고 한다.
(5) 간접 사이클
직접 주소 지정 방법을 사용하는 실행 사이클은 명령어를 즉시 수행하지만, 간접 주소 지정 방법을 사용하는 사이클은 명령어를 수행하기 전에 실제 데이터가 저장된 주기억장치의 주소인 유효주소를 한 번 더 읽어온다. 간접 사이클(indirect cycle)에 시간에 따른 세부동작은 다음과 같다.
PC -> MBR : PC의 내용을 MBR에 저장한다.
IntRoutineAddress -> PC : 인터럽트 루틴 주소를 PC에 저장한다.
Save_Address -> MAR : PC에 저장된 인터럽트 루틴 주소를 MAR에 저장한다.
MBR -> MAR : MBR의 주소에 있는 내용을 지시된 메모리 셀로 이동한다.
- 인터럽트 명령어
(1) 인터럽트의 개념
초기의 컴퓨터 시스템에는 주변장치가 많지 않았다. 당시에는 CPU가 직접 입/출력장치에서 데이터를 가져오거나 내보냈는데, 이러한 방식을 폴링(Polling) 방식이라고 한다. 폴링 방식에서 CPU가 입/출력 장치의 상태를 주기적으로 검사하여 일정한 조건을 만족할 때 데이터를 처리한다. CPU가 명령어 해석과 실행이라는 본래 역할 외에 모든 입/출력까지 관여해야 하므로 작업 효율이 떨어진다. 오늘날의 컴퓨터에는 많은 주변장치가 있기 때문에 CPU가 모든 입/출력에 관여하면 작업 효율이 현저하게 떨어진다. 이러한 문제를 해결하기 위해 등장하는 것이 인터럽트(Interrupt) 방식이다. 인터럽트 방식은 CPU의 작업과 저장장치의 데이터 이동을 독립적으로 운영함으로서 시스템의 효율을 높인다. 즉 데이터의 입출력이 이루어지는 동안 CPU가 다른 작업을 할 수 있따.
(2) 인터럽트의 종류
인터럽트는 시스템에 예기치 않은 상황이 발생하였을 때, 그것을 운영체제에 알리기 위한 메커니즘이다. IBM 계열의 기계에는 그 발생 원인에 따라 여섯 가지 종류의 인터럽트가 있다.
입/출력 인터럽트 : 해당 입/출력 하드웨어가 주어진 입/출력 동작을 완료하였가나 또는 입/출력의 오류 등이 발생하였을 때 CPU에 대하여 요청하는 인터럽트이다.
외부(external) 인터럽트 : 시스템 타이머에서 일정한 시간이 만료된 경우나 오퍼레이터가 콘솔 상의 인터럽트 키를 입력한 경우, 또는 다중 처리 시스템에서 다른 처리기로부터 신호가 온 경우 등에 발생한다.
SVC(SuperVisor Call) 인터럽트 : 사용자 프로그램이 수행되는 과정에서 입/출력 수행, 기억장치의 할당 또는 오퍼레이터의 개입 요구 등을 위하여 실행 중인 프로그램이 SVC 명령을 수행하는 경우에 발생한다.
기계 검사(machine Check) 인터럽트 : 컴퓨터 자체 내의 기계적인 장애나 오류로 인한 인터럽트이다.
프로그램(program error) 인터럽트 : 주로 프로그램의 실행 오류로 인해 발생한다. 예를 들면 수행 중인 프로그램으로 0으로 나누는 연산이다. 보호(protection)되어 있는 기억장소에 대한 접근, 허용되지 않은 명령어의 수행 또는 스택의 오버플로(Overflow) 등과 같은 오류가 생길 때 발생한다.
재시작(restart) 인터럽트 : 오퍼레이터가 콘솔상의 재시작 키를 누를 때 발생한다.
(3) 인터럽트의 동작 과정
인터럽트 방식의 동작 과정
1. CPU가 입/출력 관리자에게 입/출력 명령을 보낸다.
2. 입/출력 관리자는 명령받은 데이터를 메모리에 가져다 놓거나 메모리에 있는 데이터를 저장장치로 옮긴다.
3. 데이터 전송이 완료되면 입/출력 관리자는 완료 신호를 CPU에 보낸다.
입/출력 관리자가 CPU에 보내는 완료 신호를 인터럽트라고 한다. CPU는 입.출력 관리자에게 작업 지시를 내리고 다른 일을 하다가 완료 신호를 받으면 하던 일을 중단하고 옮겨진 데이터를 처리한다. 이처럼 하던 작업을 중단하고 처리해야 하는 신호라는 의미에서 인터럽트라고 불리게 되었다.
컴퓨터에는 하드디스크뿐만 아니라 마우스, 키보드, 프린터 등 다양한 입/출력장치가 있다. 하드디스크가 여러 개 장착된 경우도 있고 USB 드라이버와 같은 외부 저장장치를 사용하는 경우도 있다.
인터럽트 방식에는 많은 주변장치 중 어떤 것이 작업이 끝났는지를 CPU에 알려주기 위해 인터럽트 번호(Interrupt number)를 사용한다. 인터럽트 번호는 완료 신호를 보낼 때 장치의 이름 대신 사용하는 장치의 고유 번호로서 운영체제마다 다르다. 윈도우 운영체제의 경우 인터럽트 번호를 IRQ(Interrupt ReQuest)라고 부르며, 키보드의 IRQ는 1번, 마우스의 IRQ는 12번, 첫 번째 하드디스크의 IRQ는 14번과 같이 구분해서 사용한다.
인터럽트 요청 신호가 발생하면 대부분의 컴퓨터는 정보를 단일 명령어로 저장할 수 있으므로 실행 중인 프로그램을 메모리에 저장하고 인터럽트 처리 프로그램으로 분기한다. 그리고 인터럽트 처리 프로그램을 완료하면 발생시킨 프로그램에 제어를 돌려준다.
(a)와 같이 인터럽트가 도달하기 전에 프로그램 A를 실행한다고 가정하자. 프로그램 카운터는 현재 명령어를 가리킨다.
(b)에서 프로세서에 인터럽트 신호가 도달하여 현재 명령어를 종료한다. 래지스터의 모든 내용을 스택 영역(또는 프로세서 제어 블록)에 보낸다. 그리고 프로그램 카운터에는 인터럽트 처리 프로그램(프로그램 B)의 시작 위치를 저장하고 제어를 넘긴 프로그램 B를 실행한다.
(c)에서 인터럽트 처리 프로그램을 완료하면 스택 영역에 있던 내용을 레지스터에 다시 저장하며, 프로그램 A가 다시 시작하는 위치를 저장하고 중단했던 프로그램 A를 재실행한다.
인터럽트는 서브루틴 호출과 매우 비슷하지만, 몇 가지 면에서 다르다. 일반적으로 서브루틴은 자신을 호출한 프로그램이 요구한 기능을 수행하지만, 인터럽트 처리 프로그램은 인터럽트가 발생했을 때 실행 중인 프로그램과 관련이 없을 수 있다. 그러므로 프로세서는 인터럽트 프로그램을 처리하기 전에 프로그램 카운터를 비롯해 중단된 프로그램으로 복귀하여 실행할 때 영향을 미치는 정보를 저장해야 한다. 특히 인터럽트가 발생할 때의 상태코드(상태워드)를 임시기억장치에 저장해두었다가 나중에 복귀했을 때 이를 다시 적재해야 한다. 그래야 원래 프로그램을 인터럽트의 영향을 받지 않고 다시 실행할 수 있다.
(4) 인터럽트 요청 회선 연결 방법
인터럽트는 크게 인터럽트 요청과 인터럽트 서비스 루틴으로 구분할 수 있다. 인터럽트 요청 신호에 따라 수행하는 루틴이 인터럽트 처리 프로그램, 즉 인터럽트 서비스 루틴(Interrupt Service Routine)이다.
인터럽트 요청은 단일 회신과 다중 회선으로 연결할 수 있다.
단일 회선 : 인터럽트 요청이 가능한 모든 장치를 공통의 단일 회선으로 프로세서에 연결하는 방법이다. 회선 하나에 장치를 여러 개 연결하여 인터럽트를 요청하는 방치를 판별하는 기능이 필요하다.
다중 회선 : 모든 장치를 서로 다른 고유의 회선으로 프로세서와 연결하는 방법이다. 그러므로 인터럽트를 요청한 장치를 바로 판별할 수 있다.
03. 컴퓨터 시스템의 서비스
컴퓨터 시스템은 어떤 서비스를 제공하는지 알아본다
부팅 서비스 : 컴퓨터 하드웨어를 관리하고 프로그램을 실행할 수 잏도록 컴퓨터에 시동을 건다.
사용자 서비스 : 사용자 인터페이스 제공, 프로그램 실행, 압/출력 동작 수행, 파일 시스템 조작, 통신(네트워크) 등으로 프로그래머가 프로그래밍 작업을 쉽게 수행할 수 있도록 한다.
시스템 서비스 : 자원 할당, 계정, 보호와 보안 등으로 시스테므이 효율적인 동작을 보장한다
시스템 호출 : 프로세서 제어, 파일 조작, 장치 조작, 정보 관리, 통신 등으로 프로그램이 운영체제의 기능을 서비스 받을 수 있는 프로그램과 운영체제 간의 인터페이스를 제공한다.
1. 부팅 서비스
운영체제를 메인 메모리에 적재하는 과정을 부팅(booting) 또는 부트스트래핑(bootstrapping)이라고 한다. 부트 로더는 부스트랩 로더(bootstrap loader)를 줄인 말로, 하드디스크와 같은 보조기억장치에서 저장된 운영체제를 메인 메모리에 적재하는, ROM에 고정시킨 소규모 프로그램이다.
메인 프레임과 같은 대형 컴퓨터에서는 부팅의 의미로 IPL(Initial Program Load), 즉 초기 프로그램 적재라는 용어를 사용한다.
초기 운영체제는 하드웨어를 초기화하지 않고 컴퓨터를 작동시켰다. 하지만 메모리의 효율적인 활동 등에 관심을 가지면서 전체적인 초기화뿐만 아니라, 일시적인 하드웨어 오류로 활동 중인 작업이 손실되지 않도록 복구하거나 회복하는 방법과 비정상적인 작업을 처리하는 부분인 초기화가 포함되었다.
초기화의 목적으로는 시스템 장치의 초기화, 시간 설정, 명령 해석기 적재와 준비 등이 있다. 이중 시스템 장치의 초기화는 디렉터리, 파일 등을 점검하고, 시스템 버퍼와 인터럽트 벡터를 초기화하며, 운영체제의 루틴 대부분을 메모리 하위 주소에 적재하도록 설정하는 것이다.
2. 사용자 서비스
운영체제는 프로그래머가 프로그래밍 작업을 쉽게 수행할 수 있도록 다음 사용자 서비스를 제공한다.
(1) 사용자 인터페이스 제공
운영체제의 기능 중 상당수가 컴퓨터 화면에는 나타나지 않는다. 사용자가 보는 것은 사용자 인터페이스 뿐이다. 사용자 인터페이스는 사용자와 컴퓨터 간의 상호작용이 발생하는 공간으로 CLI, 메뉴, GUI 등의 형태로 구현할 수 있다.
CLI(Command Line Interface : 명령 라인 인터페이스)
CLI는 사용자가 키보드 등으로 명령어를 입력하여 시스템에서 응답을 받은 후, 또 다른 명령어를 입력하여 시스템을 동작하게 하는 텍스트 전용 인터페이스이다. 사용자가 프롬프트에서 명령어를 입력하여 컴퓨터와 상호작용할 수 있고, 명령어를 입력한 후에는 반드시 엔터를 눌러야 한다.
프롬프트(Prompt)
컴퓨터가 입력을 기다리고 있음을 가리키려고 화면에 나타나는 표시이다. 유닉스에는 $ 또는 %를 사용하며, 도스에서는 C:> 등으로 표시한다.
메뉴 인터페이스
메뉴 등을 사용하여 시스템과 상호작용한다. 사용이 매우 편리하며, 배우거나 기억해야 할 명령이 없다. iPad나 휴대폰, 현금 자동 인출기(ATM) 등이 대표적인 예이다.
GUI(Graphical User Interface : 그래픽 사용자 인터페이스)
GUI는 윈도우 환경에서 사용자에게 정보와 작업을 표현하는 텍스트, 레이블이나 텍스트 탐색과 함께 그래픽 아이콘과 시각적 표시기, 버튼이나 스크롤바와 같은 위젯(Widget) 그래픽 제어 요소를 사용하여 컴퓨터와 상호작용할 수 있는 가장 보편적인 유형이다. 마이크로소프트의 윈도우나 애플의 맥 OS에 사용하는 방법이 대표적인 예이다.
(2) 프로그램 실행
프로그램을 실행하려면 먼저 메모리에 적재해야 하고, 프로세서 시간을 할당해야 한다. 운영체제는 프로그램을 실행하려고 메모리 할당이나 해제, 프로세서 스케줄링과 같은 중요 작업을 처리한다.
(3) 입/출력 동작 수행
수행 중인 프로그램은 입력이 필요하며, 사용자가 제공하는 입력을 처리한 후 에는 출력을 수행해야 한다. 운영체제는 입/출력 동작을 직접 수행할 수 없는 사용자 프로그램의 입/출력 동작 방법을 제공한다.
(4) 파일 시스템의 조작
사용자는 디스크에서 파일을 열고, 파일을 저장하고, 파일을 삭제하는 등 다양하게 파일을 조작한다. 디스크에 파일을 저장하면 특정 블록에 할당해서 저장하고, 이 파일을 삭제하면 파일 이름이 제거되면서 할당한 블록이 자유롭게 된다. 운영체제는 파일 시스템 조작 서비스를 제공하여 사용자가 이런 파일 관련 작업을 쉽게 할 수 있도록 한다.
(5) 통신(네트워크)
프로세스가 다른 프로세스와 정보를 교환하는 방법은 크게 두 가지이다. 첫 번째는 동일한 컴퓨터에서 수행하는 프로세스 간의 정보 교환이고, 두 번째는 네트워크로 연결된 컴퓨터 시스템에서 수행하는 프로세스 간의 정보 교환이다. 운영체제는 다중 작업 환경에서 공유 메모리를 이용하거나 메시지 전달로 다양한 유형의 프로세스와 통신을 지원한다.
(6) 오류 탐지
운영체제는 가능한 모든 하드웨어와 소프트웨어 수준에서 오류를 탐지하고 시스템을 모니터링하여 조정함으로써 하드웨어 문제를 예방한다. 입/출력 장치에 관련된 오류와 메모리 오버플로, 하드디스크의 불량 섹터 검출, 부적절한 메모리 접근과 데이터 손상 등이 그 예이다. 그리고 운영체제는 다음 오류 유형을 감지한 후 유형별로 적절히 조치한다.
프로세서, 메모리 하드웨어와 관련된 오류 : 기억 장치 메모리 오류, 정전
입/출력장치 오류 : 테이프의 패리티 오류, 카드 판독기의 카드 체증(Jam), 프린터의 종이 부족
사용자 프로그램 오류 : 연산의 오버플로, 주적절한 기억장치 장소 접근, 프로세서 시간을 지나치게 많이 사용
- 시스템 버스
시스템 버스는 사용자가 아닌 시스템 자체의 효율적인 동작을 보장하는 기능이다. 여러 사용자가 사용하는 시스템에서는 컴퓨터 자원을 공유하여 시스템 자체의 효율성을 높일 수 있다.
(1) 자원 할당
운영체제는 다수의 사용자가 작업을 동시에 실행할 때 운영체제가 자원을 각각 할당하도록 관리한다. 프로세서 사이클, 메인 메모리, 파일 저장 장치 등은 특수한 할당 코드를 갖지만, 입/출력 장치 등은 더 일반적인 요청과 해제 코드를 가질 수 있다.
(2) 계정
운영체제는 각 사용자가 어떤 컴퓨터 자원을 얼마나 많이 사용하는지 정보를 저장하고 추적한다. 이 정보는 사용자 서비스를 개선하려고 시스템을 재구성하는 연구자에게는 귀중한 도구가 될 수 있다.
(3) 보호와 보안
운영체제는 다중 사용자 컴퓨터 시스템에 저장된 정보 소유자의 사용을 제한할 수도 있다. 서로 관련이 없는 여러 작업을 동시에 수행할 대는 한 직업이 다른 직업이나 운영체제를 방해하지 못하게 해야 한다. 즉 사용자가 다수인 컴퓨터 시스템에서 여러 프로세스의 동시 실행을 허용하려면 각 프로세스를 서로의 활동에서 보호해야 한다.
보호는 시스템 호출을 하려고 전달한 모든 매개변수의 타당성을 검사하고, 시스템 자원에 모든 사용자 접근을 제어하도록 보장하는 것이다. 보안은 잘못된 접근 시도에서 외부 입/출력 장치를 방어하며, 외부에 사용자 인증을 요구하는 것이다.
- 시스템 호출
시스템 호출(system call)은 커널이 자신을 보호하기 위해 만든 인터페이스이다.
04. 커널의 구성
1. 커널과 인터페이스
(1) 커널(kernel)
커널은 프로세스 관리, 메모리 관리, 저장 장치 관리와 같은 운영체제의 핵심적인 기능을 모아놓은 것으로 자동차에 비유하자면 엔진에 해당한다. 세단, 스포츠카, SUV 등 자동차의 종류는 다양하지만 성능은 엔진이 좌유하는데, 이와 마찬가지로 운영체제의 성능은 커널이 좌우한다.
스마트폰의 운영체제에도 커널이 있다. 유닉스 운영체제의 커널을 이용하여 만든 구글의 안드로이드는 다양한 제조사가 사용할 수 있도록 커널이 공개되어 있다. 애플의 iOS도 유닉스 커널을 기반으로 하지만 안드로이드와 달리 커널을 공개하지 않고 자사 제품에만 탑재한다.
(2) 인터페이스
자동차가 움직이는 데에는 엔진은 물론이고 사람이 조작할 수 있는 핸들과 브레이크가 필요하다. 또한 현재 시속, 기어의 상태, 엔진의 온도 등을 알려주는 계기판이 있어야 하는데 이를 인터페이스라고 한다. 운영체제에도 인터페이스가 있는데, 이는 커널에 사용자의 명령을 전달하고 실행 결과를 사용자에게 알려주는 역할을 한다.
운영체제는 크게 두 부분으로 나뉜다. 사용자와 응용 프로그램에 인접하여 커널에 명령을 전달하고 실행 결과를 사용자와 응용 프로그램에 돌려주는 인터페이스와 운영체제에 핵심 기능을 모아놓은 커널이 그것이다.
운영체제는 커널과 인터페이스를 분리하여, 같은 커널을 사용하더라도 다른 인터페이스를 가진 형태로 제작할 수 있다. 같은 커널이라도 다른 인터페이스가 장착되면 사용자에게 다른 운영체제처럼 보인다.
(3) 커널과 인터페이스의 관계
유닉스를 예로 들어보면 유닉스의 사용자 인터페이스는 셸(shell)이라고 하며 C셸(csh), T셀(tsh), 배시셸(bash) 등 여러 종류의 셀이 있다. 셸은 명령어 기반이라 일반인이 사용하기 불편하여 유닉스 운영체제를 어렵게 느끼는 사람이 많다. 그런데 편리한 인터페이스와 화려한 그래픽을 자랑하는 매킨토시의 운영체제 Mac OS X도 알고 보면 유닉스 계열의 커널을 이용해서 만든 것이다. 엄밀히 말하면 유닉스 운영체제가 어려운 것이 아니라 명령어 기반의 인터페이스가 어려운 것이다. 사용자 입장에서는 커널보다 인터페이스가 먼저 보이기 때문에 좋은 커널의 컴퓨터보다 좋은 인터페이스의 컴퓨터를 사용하려는 경향이 있다.
- 시스템 호출과 디바이스 드라이버
(1) 시스템 호출
시스템 호출(system call)은 커널이 자신을 보호하기 위해 만든 인터페이스다. 커널은 사용자나 응용 프로그램으로부터 컴퓨터 자원을 보호하기 위해 자원에 직접 접근하는 것을 차단한다. 따라서 자원을 이용하려면 시스템 호출이라는 인터페이스를 이용하여 접근해야 한다.
-
직접 접근
사용자가 직접 컴퓨터 자원에 접근하여 작업하는 방식으로 사용자가 모든 것을 처리해야 한다. 예를 들면, 원두 커피를 내려먹기 위해서는 원두는 어디에 있는지, 커피 머신은 어떻게 작동하는지를 모두 알아야 한다. 그리고 본인 입맛에 맞는 커피를 만들 수도 있지만 부주의로 커피머신을 고장내거나 주변을 더럽힐 수도 있다. 즉, 커피머신을 보호하기 어렵다는 단점이 있다.
직접 접근의 예와 같이 어떤 응용 프로그램은 숫자 14를, 또 어떤 응용 프로그램은 숫자 21을 하드디스크에 저장하려 한다고 가정하면 두 응용 프로그램이 자기 마음에 드는 위치에 데이터를 저장하려 할 것이다. 이 경우 다른 사람의 데이터를 지울 수도 있고 내 데이터가 다른 사람에 의해 지워질 수도 있다. -
시스템 호출을 통한 접근
누군가에게 요청하여 작업의 결과만 받는 방식으로 커피를 직접 만드는 경우가 아니라, 다른 사람에게 커피를 만들어 달라고 부탁하는 경우이다. 이와 마찬가지로 운영체제는 사용자나 응용 프로그램이 하드웨어에 직접 접근하지 못하도록 막음으로써 컴퓨터 자원을 보호한다. 그리고 대신 하드웨어와 같은 시스템 자원을 사용할 수 있도록 인터페이스를 제공하는데 이것이 바로 시스템 호출이다. 시스템 호출을 통한 접근의 예와 같이 응용 프로그램이 직접 하드디스크에 데이터를 저장하지 않고 커널이 제공하는 write() 함수를 사용하여 데이터를 저장해달라고 요청한다. 응용 프로그램은 데이터가 하드디스크의 어느 위치에 어떤 방식으로 저장되는지 알 수 없다. 만약 자신이 저장한 데이터를 읽고 싶다면 read() 함수로 시스템 호출을 이용하여 가져오면 된다. 시스템 호출을 이용하면 커널이 데이터를 가져오거나 저장하는 것을 전적으로 책임지기 때문에 컴퓨터 자원을 관리하기가 수월하다.
시스템 호출에 대한 내용을 정리하면 다음과 같다.
시스템 호출은 커널이 제공하는 시스템 자원의 사용과 연관된 함수이다
응용 프로그램이 하드웨어 자원에 접근하거나 운영체제가 제공하는 서비스를 이용하여 할 때는 시스템 호출을 사용해야 한다.
운영체제는 커널이 제공하는 서비스를 시스템 호출로 제한하고 다른 방법으로 커널에 들어오지 못하게 막음으로써 컴퓨터 자원을 보호한다.
시스템 호출은 커널이 제공하는 서비스를 이용하기 위한 인터페이스이며, 사용자가 자발적으로 커널 영여겡 진입할 수 있는 유일한 수단이다.
(2) 드라이버
응용 프로그램과 커널의 인터페이스가 시스템 호출이라면 커널과 하드웨어의 인터페이스는 드라이버(driver)가 담당한다. 컴퓨터 하드웨어는 종류가 아주 많은데, 운영체제가 많은 하드웨어를 다 사용할 수 있는 환경을 제공하려면 각 하드웨어에 맞는 프로그램을 직접 개발해야 한다. 그러나 커널에서 모든 하드웨어에 맞는 인터페이스를 다 개발하기 어렵다. 또한 각 하드웨어의 특성은 하드웨어 제작의 시스템 호출 부분을 보면 커널 앞부분 전체를 감싸고 있는데, 이는 시스템 호출을 거치지 않고 커널에 진입할 수 없다는 의미이다. 반면에 드라이버는 커널 전체를 감싸고 있지 않다. 이는 커널이 제공하는 드라이버도 있고 하드웨어 제작자가 제공하는 드라이버도 있다는 뜻으로, 하드웨거는 커널과 직접 연결되기도 하고, 하드웨어 제작자가 제공하는 드라이버를 통해 연결하기도 한다.
- 커널의 구성
운영체제의 핵심 기능을 모아놓은 커널의 기능은 프로세스 관리, 메모리 관리, 파일 시스템 관리, 입/출력 관리, 프로세스 간 통신 관리 등이다.
