
1장 데이터의 이해
01. 데이터와 정보
1. 데이터의 정의
데이터는 객관적 사실(fact)이라는 존재적 특성을 가진다
-> 데이터는 개별 데이터 자체로는 의미가 중요하지 않은 객관적인 사실을 말한다.
동시에 추론/예측/전장/추정을 위한 근거(basis)로 기능하는 당위적 특성을 가진다.
-> 다른 객체와의 상호 관계 속에서 가치를 갖는다는 의미이다.
데이터 정의에 대한 설명이다. 가장 부적절한 것은?
1) 객관적인 사실이다
2) 데이터는 추론과 추정의 근거를 이루는 사실이다.
3) 개별 데이터 자체로는 의미가 중요한 객관적 사실이다.
4) 데이터는 단순한 객체로서의 가치와 다른 객체와의 상호관계 속에서 가치를 갖는다.
2. 데이터의 유형
정성적 데이터(qualitative data)
형태 : 언어, 문자 등
예 :
회사 매출액이 증가한다
특정을 측정하지는 않지만 특성을 설명한다.
정량적 데이터(quantitative data)
형태 : 수치, 도형, 기호
예 :
나이, 몸무게, 주가
정량적(Quantitative)이란 자료를 수치화하는 것이고, 정성적(Qualitative)은 자료의 성질,특징을 자세히 풀어 쓰는 방식으로 설명하고 숫자나 금액으로 환산할 수 없는 것(만족도, 선호도)을 말한다.
아래 보기의 데이터의 유형을 무엇이라고 하는가?
지역별 온도/풍속/강우량과 같이 수치로 명확하게 표현되는 이것은 데이터의 양이 크게 증가하더라도 이를 관리하는 시스템에 저장/검색/분석하여 활용하기가 매우 용이하다
-> 정성적 데이터
3. 지식경영 핵심 이슈
지식의 차원에 대해 널리 활용되고 있는 것은 Polanyi(1966)에 두 가지 차원으로 구분한 암묵지와 형식지이다.
암묵지 : 학습과 체험을 통하여 개인에게 습득되지만 겉으로는 드러나지 않는 상태의 지식
(예 : 관찰, 모방, 현장, 작업과 같은 경험을 통해 획득할 수 있는 지식)
형식지 : 암묵지가 무서나 메뉴얼처럼 외부로 표출되어서, 여러 사람이 공유할 수 있는 지식
(예 : 책, 설계도 등 쳬계화된 재료 등을 통해서 획득할 수 있는 지식)
-> 데이터는 지식 경영의 핵심 이슈인 암묵지와 형식지의 상호작용 역할을 한다.
1) 암묵지와 형식지의 상호작용
- 공통화(Socialization) : 암묵지 지식 노하우를 다른 사람에게 알려준다.
- 표출화(Externalization) : 암묵지 지식 노하우를 책, 교본 형식으로 전환한다.
- 연결화(Combination) : 책, 교본에 자신이 알고 있는 새로운 지식을 추가한다.
- 내면화(Internalizatation) : 만들어진 책, 교본을 보고 다른 직원의 암묵적 지식을 습득한다.
- 일본의 경영학자
노나카 이쿠지로는 경험을 공유하여 암묵지를 체득하는 공동화, 구체화된 암묵지를 명시지로 표출화, 표출된 명시지를 체계화하는 연결화, 표출화와 연결화를 공유된 정신모델이나 기술적 노하우가 개인의 암묵지로 내면화하는 4가지 과정이 순환하면서 참조된다고 하였다.- 이것을 SECI 모델(Socilaization - Externalization - Combination - Internalization Model)이라고 한다.
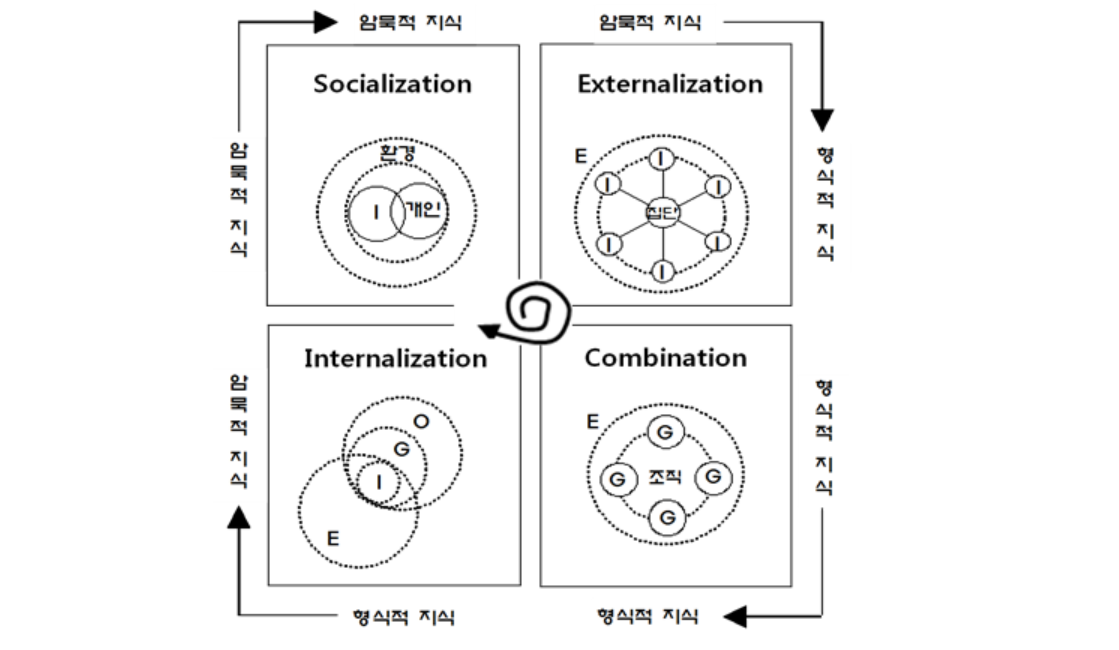
위의 그림과 같이 개인의 암묵지와 집단에서의 형식지가 나선형의 형태로 회전하면서 생성, 발전, 전환되는 지식의 발전을 기반으로 한 기업의 경영을
지식 경영(Knowledge Management)
다음 중 암묵지가 아닌 것은
1) 김장김치 담그기의 노하우
2) 암묵지는 개인에게 체화되기 되어 있기 때문에 공유하기 어렵다
3) 현장작업과 같은 경험을 통해 획득할 수 있는 지식
4) 회계, 재무 관련 대차대조표에 요구되는 지식의 메뉴얼 등이 암묵지다.
4. 데이터와 정보의 관계
DIKW 피라미드(Data Information Knowledge Wisdom)에서는 데이터, 정보, 지식을 통해 최종적으로 지혜를 얻어가는 과정을 계층구조로 설명하고 있다.
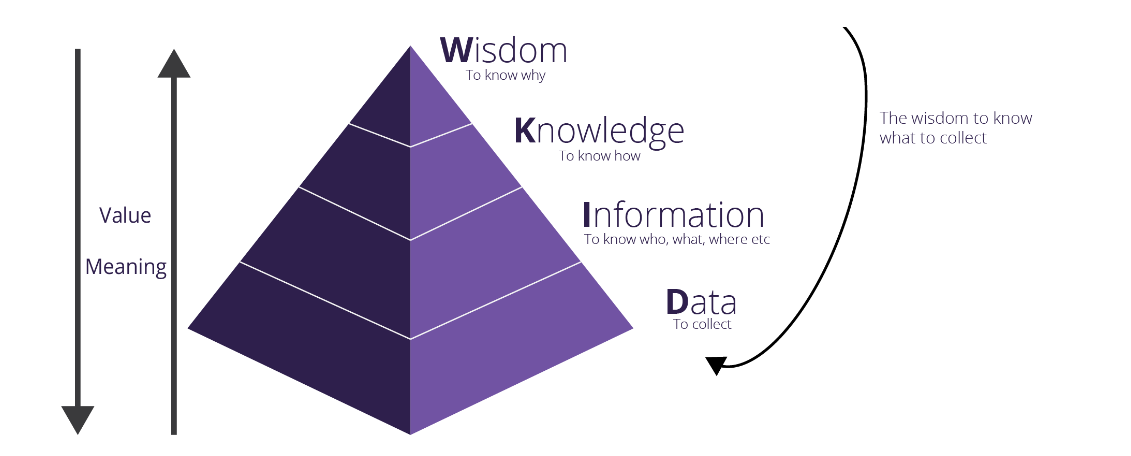
Data : 존재 형식을 불문하고 타 데이터와 상관관계가 없는 가공하기 전의 순수한 수치나 기호
-> A 마트 100원, B 마트는 200원에 연필을 판매하다
Information : 데이터의 가공 및 상관관계 간 이해를 통한 패턴을 인식하고 의미를 부여
-> A 마트의 연필 가격이 더 싸다
Knowledge : 상호 연결된 정보 패턴을 이해하여 이를 토대로 예측한 결과물
-> 상대적으로 저렴한 A마트에서 연필을 사야겠다.
Wisdom : 근본 원리에 대한 깊은 이해를 바탕으로 도출되는 아이디어
-> A 마트의 다른 상품들도 B보다 쌀 것이라고 판단된다.
02. 데이터베이스 정의와 특징
1. 용어의 변혁
1950년대
미국 정부가 전 세계에 산재한 자국 군대의 구닙 상황을 집중관리하기 위하여 컴퓨터 기술로 구현한 도서관 설립에서 비롯, 이때 수집된 자료를 일컫는
'데이터(data)의 기저(Base)'라는 뜻으로 데이터베이스가 탄색
1960년대
미국 SDC가 개최한 심포지엄에서 데이터베이스라는 용어가 공식적으로 사용
시스템을 통한 체계적 관리와 저장 등의 의미를 담은 데이터베이스 시스템이라는 용어가 등장
1970년대
유럼에서 데이터베이스라는 단일어가 일반화된다.
CAC가 한국과학기술정보센터를 통해 서비스되면서 우리나라에서 데이터베이스 이용이 도입된다.
1980년대
TECHNOLINE이라는 온라인 정보 검색 서비스를 개시하여 본격적인 데이터베이스 서비스 시대를 맞이한다.
국내의 데이터베이스 관련 기술의 연구개발은 1980년대 중반부터 시작되어 오늘에 이르고 있다.
2. 데이터베이스 정의
데이터베이스는 "동시에 복수의 적용 업무를 지원할 수 있도록 복수 이용자의 요구에 대응해서 데이터를 받아들이고 저장, 공급하기 위하여 일정한 구조에 따라서 편성된 데이터의 집합", "관련된 레코드의 집합"을 의미하며, 소프트웨어로는 데이터베이스 관리 시스템(DBMS)을 의미한다. 데이터베이스가 DBMS와 혼용되고 있는데, DBMS는 이용자가 쉽게 데이터베이스를 구축하고 유지할 수 있도록 하는 소프트웨어로서 데이터베이스와 구분되며, 일반적으로 데이터베이스와 DBMS를 함께 데이터베이스 시스템이라고 칭한다.
3. 데이터베이스 특징
통합된 데이터(Integrated data) : 데이터메이스에서 동일한 재용의 데이터가 중복되어 있지 않다는 것을 의미한다.
저장된 데이터(Storaged data) : 자기 디스크나 자기 테이프 등과 같이 컴퓨터가 접근할 수 있는 저장매체에 저장되는 것을 의미한다.
공용 데이터(shared data) : 여러 사용자가 서로 다른 목적으로 데이터베이스의 데이터를 공동 이용한다.
변화되는 데이터(Changed data) : 새로운 데이터의 추가, 기존 데이터의 삭제, 갱신으로 항상 변화하면서도 항상 현재의 정확한 데이터를 유지해야 한다는 것을 의미한다.
4. 데이터베이스 특성
정보의 축적 및 전달 측면 : 대량의 정보를 정보처리기기가 읽고 쓸 수 있는 기계가독성과 필요한 정보를 검색할 수 있는 검색가능성, 정보통신망을 이용하여 원거리에서도 온라인으로 이용할 수 있는 원격조작성을 갖는다.
정보이용 측면 : 이용자의 정보 요구에 따라 다양한 정보를 신속하게 획득하고, 원하는 정보를 경제적으로 찾아낼 수 있다.
정보관리 측면 : 방대한 양의 정보를 체계적으로 축적하고 새로운 내용 추가나 갱신이 용이하다.
정보기술발전 측면 : 데이터베이스는 정보처리, 검색, 관리 소프트웨어 등 네트워크 발전 기술을 견인할 수 있다.
경제/산업적 측면 : 데이터베이스는 인프라로서 특성을 가지고 있어 경제, 산업, 사회 활동의 효율성을 제고하고 국민의 편의를 증진하는 수단으로 의미를 가진다.
5. 데이터베이스 관리시스템 등장 배경
- 같은 내용의 데이터가 여러 파일에 중복저장 및 응용프로그램이 데이터 파일에 종속되는 파일시스템 문제점 발생
- 파일 시스템의 문제를 해결하기 위해 제시된 소프트웨어인 DBMS이 등장
6. 데이터베이스 관리시스템의 발전 과정
1세대 : 네트워크 DBMS, 계층 DBMS
복잡하고 변경이 어렵다
2세대 : 관계(Relation) DBMS
데이터베이스를 테이블 형태 구성
ex. 오라클(유료), 엑세스, MySQL
3세대
객체 지향(Objected) DBMS : 멀티미디어 데이터의 확산으로 관계형 데이터 모델 표현하기 어려움 같은 행위를 갖는 객체는 한 클래스에 속하며, 클래스 연산을 나타내기 위해 메소드 함수를 정의한다.
RDBMS와 ODBMS 차이
- RDBMS
- 주된 장점
- 검증된 시스템
- 대규모 정보처리가능
- 주된 단점
- 제한된 형태의 정보만 처리 가능
- 복잡한 정보구조의 모델링이 어렵다
- ODBMS
- 주된 장점
- 복잡한 정보구조의 모델링 가능
- 주된 단점
- 사용자 정의 타입 및 비정형 복합 정보 타입 지원
객체 관계형 모델(ORDBMS) : 기존의 관계형 모델에 객체 지향된 모델의 장점을 선별하여 관계형 모델에 통합한 새로운 개념의 데이터 모델
4세대 : NoSQL DBMS
데이터 구조를 미리 정해두지 않기 때문에 비정형 데이터를 저장하고 처리한다.
7. 데이터베이스 설계 절차
요구조건 분석/명세서 작성 : 데이터베이스의 사용자, 사용목적, 사용범위, 제약조건 등에 대한 내용을 정리하고 명세서를 작성
개념적 설계(E-R 모델) : 정보를 구조화하기 위해 추상적 개념으로 표현하는 과정으로 개념 스키마 모델링과 트랜잭션 모델링을 병행하고, 요구조건 분석을 통해 DBMS 독립적인 E-R 다이어그램을 작성
논리적 설계(데이터 모델링) : 자료를 컴퓨터가 이해할 수 있도록 특정 DBMS의 논리적 자료 구조로 변환하는 과정
물리적 설계(데이터 구조화) : 논리적 구조로 표현된 데이터를 물리적 구조의 데이터로 변환하는 과정
8. 데이터웨어하우스(Data Warehouse, DW)
1) 정의
데이터웨어하우스는 업무 트랜잭션을 처리하는 데이터베이스 시스템에서 사용자들이 필요로 하는 정보를 추출해서 가공된 데이터 형태로 구성되는 업무 분석을 위한 데이터베이스이다.
이는 데이터베이스 관련자들이 업무 처리와 관련된 데이터들은 잘 저장하지만 저장된 데이터들을 제대로 활용하지 못한다는 점에 착안하여 어떻게 하면 데이터베이스에 저장되어 있는 데이터들을 보다 유익하게 효율적으로 활용할지에 대한 관점에서 시작한 개념이다.
2) 데이터베이스와 데이터웨어하우스 비교
흔히 데이터베이스는 OLTP(On-Line Transaction Processing) 데이터를 저장하는 자료 저장소이고, 데이터 웨어하우스는 OLAP(On-Line Analytical Processing) 데이터를 저장하는 자료저장소라고 비교할 수 있다. 이는 저장되는 데이터의 성격에 따라 비교하는 방법으로 데이터 웨어하우스는 기존의 운용 데이터베이스에 비교하여 의사 결정을 지원할 수 있는 분석 정보를 제공한다는 것이 데이터베이스와 가장 큰 차이점이며 특징이라고 할 수 없다.
데이터베이스 언어 SQL
SQL(Structure Query Language)은 관계 데이터베이스를 위한 표준 질의어로 많이 사용하는 언어이다.
SQL은 기능에 따라 데이터 정의어(DDL), 데이터 조작어(DML), 데이터 제어어(DCL)로 나눈다.
데이터 정의어(DDL): 테이블을 생성(Create)하고 변경(Alter), 제거(Drop)하는 기능을 제공
데이터 조작어(DML): 데이터를 검색(Select), 데이터 삽입(Insert), 데이터 수정(Update), 데이터 삭제(Delete)하는 기능 제공
데이터 제어어(DCL): 보안을 위해 데이터에 대한 접근 및 사용권한을 사용자별로 부여하거나 취소하는 기능을 제공
3) 데이터웨어하우스 특징
- 데이터의 주제지향성
- 데이터웨어하우스는 의사결정에 필요한 주제와 관련된 데이터만 유지하는 주제지향적인 특징을 가진다.
- 데이터의 통합성
- 데이터웨어하우스는 데이터가 항상 일괄된 상태를 유지하도록 여러 개의 데이터베이스에서 추출한 데이터를 통합하여 저장하는 특징이다.
- 데이터의 시계열성
- 데이터웨어하우스는 과거와 현재의 데이터를 동시에 유지하여 데이터 간의 시간적 관계나 동향을 분석해 의사결정에 반영할 수 있도록 하는 특징을 가진다.
- 데이터웨어하우스의 시계열성은 어떤 자료가 시간에 따라 변경되어야 하는 것이 아니고, 시간에 따른 변경을 항상 반영하고 있어야함을 의미한다.
- 데이터의 비휘발성
- 데이터베이스의 저장된 데이터는 삽입, 삭제, 수정 작업이 자주 발생하지만 데이터웨어하우스는 검색작업만 수행되는 읽기 전용의 데이터를 유지한다.
다음의 데이터베이스 설계 순서로 올바른 것은
1) 요구사항 분석 - 개념적 설계 - 논리적 설계 - 물리적 설계
2) 개념적 설계 - 요구사항 분석 - 논리적 설계 - 물리적 설계
3) 요구사항 분석 - 개념적 설계 - 물리적 설계 - 논리적 설계
4) 물리적 설계 - 개념적 설계 - 논리적 설계 - 요구사항분석
데이터마트와 데이터웨어하우스의 차이
데이터웨어하우스는 의사결정 요청을 충족시키기 위해 정보 지향을 저장하는 데이터베이스이며 데이터마트는 전체 데이터웨어하우스의 완전한 논리 하위 집합이다.
03. 데이터베이스 활용
1. 기업 내부 데이터베이스
정보통신망 구축이 가속화되면서 1990년대에는 기업 내부 데이터베이스는 기업경영 전반에 관한 인사 조직 생산 영업 활동을 포함한 모든 자료를 연계하여 일관된 체계로 구축 운영하는 경영활동의 기반이 되는 전사 시스템으로 확대되었다.
전사 시스템 : 즉 모등 회사의 자원을 통합적으록 관리하는 시스템
- 1980년대 기업 내부 데이터베이스
OLTP(On-line Transaction Processing) 온라인 거래 처리: 주 컴퓨터와 통신회선으로 접속되어 있는 복수의 사용자 단말에서 발생한 트랜잭션을 주컴퓨터에서 처리하여 그 결과를 즉석에서 사용자에게 되돌려 보내 주는 처리 형태 여러 과정이 하나의 단위 프로세스로 실행되도록 하는 프로세스OLAP(On-line Analytical Processing) 온라인 분석 처리: 다차원으로 이루어진 데이터로부터 통계적인 요약 정보를 제공할 수 있는 기술
2000년대 기업 내부 데이터베이스
CRM(Customer Relationship Management) : 선별된 고객으로부터 수익을 창출하고, 장기적인 고객관계를 가능케 함으로써 보다 높은 이익을 창출할 수 있는 솔루션을 말한다.
SCM(Supply Chain Management) : SCM이란 제조, 물류, 유통업체 등 유통공급망에 참여하는 모든 업체들이 협력을 바탕으로 정보기술(Information Technology)을 활용재고를 최적화하기 위한 솔루션이다.
OLTP vs OLAP 차이
OLTP(On - Line Transaction Processing) :
네트워크 상의 여러 사용자가 실시간으로 데이터베이스의 데이터를 갱신하거나 조회하는 등의 단위 작업을 처리하는 방식
OLAP(On - Line Analytical Processing) :
정보 위주의 처리 분석을 의미, 의사결정에 활용할 수 있는 정보를 얻을 수 있게 해주는 기술
2. 분야별 기업 내부 데이터베이스
제조 부문
DW(Data warehouse) : 정보검색을 목적으로 구축된 데이터베이스이다. 데이터웨어하우스가 전사적인 규모의 시스템이라 한다면 데이터 마트는 사업부 단위의 소규모 데이터 웨어하우스라 할 수 있다.
ERP(Enterprise Resource Planning) : 제조업을 포함한 다양한 비즈니스 분야에서 생산, 구매, 재고, 주문, 공급자와의 거래, 고객서비스 제공 등 주요 프로세스 관리를 돕는 여러 모듈로 구성된 통합 애플리케이션 소프트웨어 패키지를 의미한다.
BI(Business Intelligence)
기업의 DW(Data Warehouse)에 저장된 데이터에 접근해 경영 의사 결정에 필요한 정보를 획득하고 이를 경영활동에 활용하는 것을 말한다
CRM(Customer Relationship Management)
선별된 고객으로부터 수익을 창출하고 장기적인 고객관계를 가능케 함으로써 보다 높은 이익을 창출할 수 있는 솔루션을 말한다.
금융 부문
EAI는 Enterprise Architecture Integration의 약자로 기업 애플리케이션 통합을 의미한다. 기업 내의 ERP(전사적 자원관리), CRM(고객관계관리), SCM(공금망계획), 스템이나 인트라넷 등의 시스템 간에 상호 연동이 가능하도록 통합하는 솔루션이다
EDW(Enterprise Data Warehouse)는 기존 DW(Data Warehouse)를 전사적으로 확장한 모델인 동시에 BPR과 CRM, BSC 같은 다양한 분석 애플리케이션들을 위한 원천이 된다. 따라서 EDW를 구축하는 것은 단순히 정보를 빠르게 전달하는 대형 시스템을 도입한다는 의미가 아니라 기업 리소스의 유기적 통합 다원화된 관리 체계 정비, 데이터의 중복 방지 등을 위해 시스템을 재설계하는 것이다.
블록체인(Blockchain) : 데이터 분산처리 기술 네트워크에 참여하는 모든 사용자가 모든 거래 내역 등의 데이터를 분산, 저장하는 기술을 말한다. 블록들을 체인 형태로 묶는 형태이기 때문에 블록체인이라는 명칭이 생겨난다. 기존 거래 방식에서 데이터를 위/변조하기 위해서는 은행의 중앙서버를 공격하면 가능했으나(최근 몇몇 은행 전산망 해킹 사건이 발생했다) 블록체인인 경우 사실상 해킹이 불가능하다.
이밖에 ERP, e-CRM 등 이용
유통 부문
KMS(Knowledge Management System) 지식관리시스템의 약자 조직 내의 지식을 체계적으로 관리하는 시스템을 의미하며 지식을 저장하고 검색하여 이해, 협업 프로세스 정렬을 향상시키는 모든 종류의 IT 시스템을 말한다. 예전에는 대부분의 기업이 물품을 생산하던 환경이었지만 요즘에는 지적 재산이 매우 중요해짐에 따라 기업을 관리하는 시스템이 등장한다.
RFID는 무선주파수(RF, Raio Frequency)를 이용하여 대상(물건, 사람 등을) 식별할 수 있는 기술로서 안테나와 칩으로 구성된 RF 태그에 사용 목적에 알맞은 정보를 저장하여 적용 대상에 부착한 후 판독기에 해당되는 RFID 리더를 통하여 정보를 인식한다.
이외에도 CRM, SCM 등 이용
3. 사회 기반 구조로서의 데이터베이스
1990년대 사회 각 부문의 정보화가 본격화되면서 데이터베이스 구축이 활발하게 추진되었다. 특히 정부부처를 중심으로 사회간접자본 차원에서 전자문서교환(EDI)의 활용이 본격화되었고, 부가가치통신망(VAN)을 통한 정보망이 구축되기 시작하였다. 인터넷의 보편화로 인해 일반 국민들도 가정에서 손쉽게 생활에 필요한 정보를 습득할 수 있게 되었고, 이로 인해 데이터베이스는 사회 전반의 기간제로서 자리매김하게 되었다.
EDI(Electronic Data Interchange) : 표준화된 상거래 서식 또는 공공 서식을 서로 합의된 표준에 따라 전자문서를 만들어 컴퓨터 및 통신을 매개로 상호 교환하는 것을 의미한다.
CALS : 광속상거래(Commerce At Lighted Speed)의 약칭이다. 각종 기술 자료를 디지털화해 관련 데이터를 통한 통합 운영하는 업무 환경을 의미한다.
BI vs BA 차이
BI(Business Intelligence) : 데이터 기반 의사결정을 지원하기 위한 리포트 중심의 도구
BA(Business Analytics) : 의사결정을 위한 통계적이고 수학적인 분석에 초점
4. 분야별 사회기반 구조로서의 데이터베이스
물류 부문
종합물류정보망: 실시간 챠량 추정이라고 할 수 있다. 전자지도상에서 운행중인 차량의 위치 및 상태를 실시간으로 파악하여 운송 회사 및 화주 등 서비스 가입자의 합리적인 의사결정을 지원하는 시스템부가가치통신망(VAN, Value Added Network): 일반적인 의미는 통신회선을 소유 또는 임차하여 구성한 네트워크에 단순한 전송 기능 이상의 부가가치를 첨가하여 정보를 축적, 가공, 변환 처리하여 음성 또는 데이터 정보를 제공해주는 광범위하고도 복합적인 통신서비스의 집합을 말한다.
지리 부문
국가지리정보체계(NGIS),RS,GPS
교통 부문
지능형교통시스템(ITS)
의료 부문
의료 EDI
교육 부문
교육행정정보시스템(NEIS)
물류, 유통업체 등 유통공급망에 참여하는 모든 업체들이 협력을 바탕으로 정보 기술(Information Technology)을 활용하고 재고를 최적화하기 위한 기업 내부 데이터베이스 솔루션을 무엇이라고 하는가?
SCM
2장. 데이터의 가치와 미래
01. 빅데이터의 이해
1. 빅데이터의 정의
규모(Volume)
규모는 미디어나 위치 정보, 동영상 등과 같이 다루어야 할 데이터의 크기를 말한다. 물리적인 크기뿐만 아니라 현재의 기술로, 처리가능한 양인지, 불가능한 양인 지에 따라 빅데이터를 판단한다. 기술의 발달에 따라 킬로바이트, 메가바이트, 기가바이트 최근에는 테라바이드를 훌쩍 넘어 요타바이트까지 빅데이터로 통칭한다.
다양성(Variety)
다양성은 다양한 종류의 데이터를 수용하는 속성을 말한다. 빅데이터는 형식이 정해져 있는 정형 데이터뿐만 아니라, 감시카메라에서 생성되는 동영상, 개인이 디지털 카메라로 생성하여 웹 사이트에 울리는 사진, 소셜 네트워크 서비스로 전달되는 메시지, 물건에 부착되거나 주변에 설치된 센서에서 발생하는 RFID 태그나 센서 값 등 다양한 비정형 데이터도 생성한다.
속도(Velocity)
속도는 대용량의 데이터를 빠르게 처리하고 분석할 수 있는 속성을 말한다. 데이터를 자동으로 생성하는 센서, 스마트폰 등 데이터 생성 및 유통채널의 다변화로 데이터 생성속도가 빨라진다. 이는 처리속도의 가속화를 요구한다.
진실성 또는 신뢰성(Veracity)
진실성이라고 번역하는 Veracity는 빅데이터셋이 얼마나 신뢰할 수 있는지를 의미한다.
정확성(Validity)
Validity의 개념은 그 데이터의 정확성을 의미한다. 데이터가 타당한지, 정확한 지의 여부는 결정을 내리는데 중요하다. Veracity와 Validity는 비슷한 개념이다. 데이터에 Veracity가 없다면, 노이즈와 바이어스로 인해 잘못된 결론을 이끌어낼 수 있으며, Validity가 없다면, 데이터는 규모가 크더라도 쓸모가 없어진다. 개와 고양이 사진 DB를 예로 들어보면 개와 고양이 사진에 기술적 결합으로 생겨난 인공적 노이즈가 많다면, Veracity가 없는 것이다. 하지만 개와 고양이의 Labeling이 잘못된 데이터라면 Validity가 없는 것이다.
휘발성(Volatility)
아무리 데이터의 양이 많고 깔끔하게 정리되고 있더라도 몇 년만 지나면 의미가 없어지는 유형의 데이터이거나 데이터의 양이 너무나도 커서 오래 저장되기 힘들다면, 빅데이터로서의 활용성을 점검해야 한다. 빅데이터는 단기적으로 활용하기보다는 장기적인 관점에서 유용한 가치를 창출할 수 있어야 한다.
가치(Value)
빅데이터는 결국 비즈니스나 연구에 사용되며, 유용한 가치를 이끌어내ㅑㄹ 수 있어야 의미가 있다. Value는 이러한 빅데이터의 가치를 의미한다.
가트너 그룹 더그래니가 언급한 빅데이터 정의
Volume(데이터의 크기) : 생성되는 모든 데이터를 수집
Variety(데이터의 다양성) : 정형화된 데이터를 넘어 텍스트, 오디오, 비디오 등 모든 유형의 데이터를 분석대상으로 한다.
Velocity(데이터의 속도) : 두 가지 관점의 속도를 의미한다. 사용자가 원하는 시간 내에 데이터 분석결과를 제공하는 것과 데이터의 업데이트되는 속도가 매우 빨라지는 것을 의미한다.
빅데이터 등장하게 된 결정적 요인으로 기술변화인 클라우드 컴퓨팅과 분산처리 기술이라 할 수 있다.
2. 출현 배경
산업계 : 고객 데이터를 축적하여 보유 데이터에 숨어 있는 가치를 발굴해 새로운 성장동력원으로 만들어낼 수 있는 빅데이터 기술 확보가 관건이다
ex
테스코는 매월 15억 건 이상의 고객 데이터를 수집하낟. 매킨지 보고에 의하면 미국의 상장 기업 대부분이 100테라바이트 이상의 데이터를 보유 중이며, 상당수는 1테라바이트 이상의 데이터를 보유하고 있다.
학계 거대 데이터 활용 과학 확산
ex. 인간 게놈 프로젝트
관련 기술 발전 : 디지털화, 저장 기술, 인터넷 보급, 모바일 혁명, 클라우드 컴퓨팅
ex
디지털 데이터 양은 2년마다 약 2배씩 증가해 2020년 약 40제타바이트에 다다를 것으로 전망되고 있다.
3. 빅데이터 기능
빅데이터는 산업혁명의 석탄, 철에 비유된다.
빅데이터는 석탄과 철이 산업혁명에서 했던 역할을 차세대 산업혁명에서 해낼 것으로 기대된다. 빅데이터 역시 지금의 제조업뿐만 아니라 서비스 분야의 생산성을 획기적으로 끌어올려 혁명적 변화를 가져올 것으로 기대되고 있다.
빅데이터는 원유에 비유된다
빅데이터는 원유처럼 각종 비즈니스, 공공기관 대국민 서비스, 경제 성장에 필요한 정보를 제공함으로써 산업 전반의 생산성을 한 단계 향상시킬 것으로 기대된다.
빅데이터는 렌즈에 비유된다.
현미경이 생물학 발전에 미쳤던 영향만큼 나아가 데이터가 산업 전반에 영향을 미칠 것으로 기대된다.
ex.
구글의 "Ngram Viewer"로써 미국을 의미하는 "The United States"는 미국의 남북전쟁이 반발하기 전까지는 아메리카 대륙의 주들의 연합이라는 의미로 복수였다. 그런데 남북전쟁이 끝나고 연방정부의 역할이 커지고 모두 하나의 나라가 돼야 한다는 연방국의 개념이 강화되면서 단수로 취급되기 시작했다. 구글의 Ngram Viewer를 이용하면 이러한 변화 과정을 한 눈에 볼 수 있다.
빅데이터는 플랫폼에 비유된다.
플랫폼이란 다양한 차원에서 활용되는 개념이지만, 비즈니스 측면에서는 일반적으로 공동 활용의 목적으로 구축된 유무형의 구조물을 의미한다.
ex
페이스북은 SNS 서비스로 시작했지만, 2006년 F8 행사를 기점으로 자신들의 소셜그래프 자산을 외부 개발자들에게 공개하고 서드파티 개발자들이 페이스북 위에서 작동하는 앱을 만들기 시작하면서 플랫폼 역할을 하기에 이르렀다.
4. 빅데이터가 만들어내는 본질적인 변화
사전처리에서 사후처리 시대로
산업혁명 시대에 발전해온 것이 바로 정보의 사전처리(pre-preprocessing) 방식이다. 사전처리의 대표적인 예로는 표준화 문서 포맷을 들 수 있다. 사전에 정한 포맷으로 인쇄된 문서를 통해 자신들이 원하는 정보만 수집하고, 특수한 상황을 반영하는 정보의 수집을 포기함으로써 정보관리 비용을 줄인다. 빅데이터 시대에는 가능한 한 많은 데이터를 모으고 그 데이터를 다양한 방식으로 조합해 숨은 정보를 찾아낸다. 이른바 사후 처리(post-processing) 방식이라고 부를 수 있다.
표본조사에서 전수조사로
빅데이터 시대가 되면서 많은 제약이 사라졌다. 데이터 수집 비용은 더는 문제가 되지 않았고, 클라우드 컴퓨팅 기술의 발전에 따라 데이터 처리 비용이 급격히 감소하고 있다. 전수조사의 장점은 표본조사가 주지 못하는 패턴이나 정보를 제공해준다는 데 있다.
질보다 양으로
빅데이터 성공 사례로 자주 언급되는 구글의 자동번역 시스템 구축과정은 데이터의 양이 질보다 중요함을 잘 보여준다. 빅데이터를 다룰 때, 질보다 양이 중요한 또 다른 이유가 있다. 데이터 수가 증가함에 따라 사소한 몇 개의 오류 데이터가 '대세에 영향을 주지 못하는' 경향이 늘어나기 때문이다.
인과관계에서 상관관계로
기존의 과학적 발견법은 이론에 기초해서 수집할 변인을 결정하고 엄격한 실험을 통해 잘 정제된 데이터를 얻고 이를 정교한 이론적 틀에 맞취 분석한 후 변수 간에 인과관계를 찾으려 했다. 이러한 접근법은 데이터를 얻는데 드는 비용이 매우 비쌌던 시대의 모델이다. 비즈니스 상황에서는 인과관계를 모르고 상관관계 분석만으로 충분한 경우가 있다.
데이터 크기를 나타내는 범위
1테라바이트 = 1,024기가바이트(Gigabyte)
1엑사바이트 = 1,024 페타바이트(Petabyte)
1페타바이트(Petabyte) = 1,024테라바이트(Terabytes)
1제타바이트(Zettabyte) = 1,024 엑사바이트(Exabytes)
다음 중 빅데이터 본질적 변화가 아닌 것은
1) 표본 조사, 인과관계
2) 상관관계, 전수조사
3) 사후처리, 데이터의 양적 크기
4) 상관관계, 사후처리
02. 빅데이터의 가치와 영향
1. 빅데이터 가치(빅데이터의 가치 선정이 어려운 이유)
데이터의 활용 방식 : 데이터의 재사용, 재조합(Mashup), 다목적용 데이터 개발 등이 일반화되면서 특정 데이터를 언제, 어디서, 누가 활용할지 알 수 없다.
재사용 사례 : 구글 검색결과를 저장 후 재사용한다.
다목적용 사례 : 전기 자동차의 (배터리 충전 시간 & 주유소 최적위치), CCTV(절도범 & 구매정보)
재조합 사례 : 휴대전화 전자파와 뇌종양 관계
데이터가 기존에 없던 가치 창출을 한다
아마존 킨들 전자책 읽기 관련 데이터 분석을 하면 독서 패턴을 알 수 있다.
페이스북 소셜커머스 그래프
분석 기술의 발달의 데이터에 가치에 영향을 준다. 기존에는 가치가 없는 데이터도 새로운 분석 기법으로 가치를 만든다
SNS 비정형 데이터 이용한 텍스트마이닝 활용
2. 데이터 영향(기업, 정부, 개인)
기업
(혁신) 빅데이터를 활용해 소비자의 행동을 분석하고 시장 변동을 예측해 비즈니스 모델을 혁신하거나 신사업을 발굴할 수 있다.
(경쟁력제고) 빅데이터를 원가절감, 제품 차별화, 기업활동의 투명성 제고 등에 활용하면 경쟁사보다 강한 경쟁력을 확보하는데 도움이 된다.
(생산성 향상) 빅데이터를 활용해 기업들의 운용 효율성이 증가하면, 산업 전체의 생산성이 향상되고 국가 전체로서는 GDP가 올라가는 효과를 거둘 수 있다.
정부
(환경 탐색) 정부는 기상, 인구 이동, 각종 통계, 법제 데이터 등을 수집해 사회 변화를 추정하고 각종 재해 관련 정보를 추출할 수 있다.
(상황분석) 이렇게 수집된 데이터를 바탕으로 사회관계방 분석이나 시스템 다이내믹스, 복잡계 이론과 같은 분석 방식을 적용해 미래 의제를 도출할 수 있다.
(미래대응) 이렇게 도출된 미래 의제에 대한 대응 방안 역시 빅데이터를 통해 얻을 수 있다. 미래 사회 도래에 대비한 법제도 및 거버넌스 시스템 정비 방향, 미래 성장 전략, 국가 안보 등에 대한 정보를 빅데이터가 제공할 수 있기 때문이다.
개인
(목적에 따라 활용) 개인은 아직까지 대부분 빅데이터 활용 대상의 위치에 머물러 있지만, 빅데이터를 서비스로 제공하는 기업들이 출현하고 비용이 지속적으로 하락하면서, 경제력 여력이 있는 정치인이나 대중 가수 등이 빅데이터를 활용하는 사례가 나타나고 있다.
맥킨지는 빅데이터 보고서(2011)를 통해 빅데이터가 가치를 만들어내는 방식으로 5가지를 선정했다.
투명성 제고로 연구개발 및 관리효율성 제고
시뮬레이션을 통한 수요 포착 및 주요 변수 탐색으로 경쟁력 강화
고객 세분화 및 맞춤 서비스 제공
알고리즘을 활용한 의사결정 보조 혹은 대체
비즈니스 모델과 제품, 서비스의 혁신
3. 비즈니스 모델
1. 빅데이터 활용 사례
구글의 검색엔진, 월마트의 구매패턴 분석, IBM 왓슨 의료 분야에 활용
정부의 실시간 교통정보 활용, CCTV 국가안전에 활용
정치인의 사회관계망분석을 통한 유세, 가수의 팬 음악청취 기록 분석 활용 등
아마존의 킨들에 쌓이는 전자책 읽기 관련 데이터 분석해 저자들에게 제공
넷플릭스 추천 알고리즘, Cine Match, Dinosour Planet, Gravity, Pragmatic Chaos로 진화하면서 추천 정확도 증가
핀테크(Fintech)는 금융(Financial)과 기술(Technology)의 합성어로, 금융과 IT의 융합을 통한 금융서비스 및 산업의 변화를 통칭한다.
2. 빅데이터 활용 테크닉
연관규칙학습(Assocation rule Learning)
어떤 변수 간에 주목할 만한 상관관계가 있는지를 찾아내는 방법이다.
ex.
슈퍼마켓에서 상관관계가 높은 상품을 함께 진열(기저귀와 우유)
유형분석(Classification tree Analysis)
사용자가 어떤 특성을 가진 집단에 속하는가 와 같은 문제를 해결하고자 할 때 사용
ex.
온라인 수강생들을 특성에 따라 분류
유전 알고리즘(Genetic Algorithm)
최대의 시청률을 얻으려면 어떤 프로그램을 어떤 시간대에 방송해야 하는가와 같은 문제를 해결할 때 사용한다. 최적화의 매커니즘을 찾아가는 방법이다. 즉 최적화가 필요한 문제의 해결책을 자연선택, 돌연변이 등과 같은 매커니즘을 통해 점진적으로 진화시켜 나가는 방법이다.
ex
연료 효율적인 차를 개발하기 위해 어떻게 원자재와 엔지니어링을 결합해야 하는가
기계학습(Machine Learning)
기존의 시청 기록을 바탕으로 "시청자가 현재 보유한 영화 중에서 어떤 것을 가장 보고 싶어할까"와 같은 문제를 해결할 때 사용한다. 기계학습은 훈련 데이터로부터 학습한 알려진 특성을 활용해 '예측'하는 일에 초점을 맞춘다. 이 기법은 이메일에 스팸 메일을 필터링 기법으로 사용되며, 사용자의 기호를 학습해 추천 서비스를 제공할 때도 사용한다.
회귀분석(Regression Analysis)
분석가는 독립변수를 변화하며, 종속변수가 어떻게 변하는지를 보면 두 변수간에 관계를 파악한다. 이 기법은 "사용자의 만족도가 충성도에 어떻게 영향을 미치는가" 이웃들과 그 규모가 집값에 어떤 영향을 미치는가?등과 같은 문제 해결을 위해서도 사용한다.
감정분석(Sentiment Analysis)
새로운 환불 정책에 대한 고객의 평가는 어떤가?를 알고 싶을 때 활용한다. 이 기법에서는 특정 정책에 대해 말하거나 글을 쓴 사람의 감정을 분석한다. 호텔에서 고객의 코멘트를 받아 서비스를 개선하거나 소셜 미디어에 나타난 의견을 바탕으로 고객이 원하는 것을 찾아낼 때 이 기법이 활용된다.
ex.
소셜 미디어에 나타난 의견을 바탕으로 고객이 원하는 것을 찾을 때 사용한다.
소셜 네트워크 분석(Social network analysis) = 사회관계망(SNA)
소셜 네트워크 분석은 '특정인과 다른 사람이 몇 촌(Degree of seperation)정도의 관계인가'를 파악할 때 사용한다. 이를 통해 오피니언 리더(Ophinion leader), 즉 영향력이 있는 사람을 찾아낼 수 있으며, 고객들 간 소셜 관계를 파악할 수 있다.
04. 위기 요인과 통제 방안
1. 위기 요인 및 통제 방안
사생활 침해
(위기 요인)
빅데이터 시대가 본격화되면서 우리를 둘러싼 정보 수집 센서들의 수가 점점 늘어나고 있고, 특정 데이터가 본래 목적 외에 가공 처리돼 2차, 3차적 목적으로 활용될 가능성이 증가하면서, 사생활 침해를 넘어 사회/경제적 위협으로 변형될 수 있다. 이러한 상황을 방지하기 위해 익명화 기술이 발전되고 있으나, 아직도 충분하지 않다는 의견이 많다.
(통제 방안)
개인 정보의 활용에 대해 개인이 매번 동의하는 것은 경제적으로도 매우 비효율적이다. 따라서 사생활 침해 문제를 개인정보 제공자의 동의를 통해 해결하기 보다는 개인정보 사용자에게 책임을 지움으로써 개인정보 사용 주체가 보다 적극적인 보호 장치를 강구하게 하는 쇼과가 발생할 것으로 기대한다.
책임 원칙의 훼손
(위기 요인)
빅데이터 기반 분석과 예측 기술이 발전하면서 정확도가 증가한 만큼, 분석 대상이 되는 사람들은 예측 알고리즘의 희생양이 될 가능성이 증가한다. 미국 경찰관들은 컴퓨터 알고리즘 분석에 따라 특정 지역을 순찰한다. 그 결과 강력 범죄 발생률이 상당수 감소하는 성과를 거둔 것으로 나타났다. 그러나 이러한 알고리즘의 예측을 더 진전시키면 영화 '마이너리티 리포트'에 나오는 것처럼 범죄 예측 프로그램에 의해 범행을 저지르기 전에 체포할 수 있다.
(통제 방안)
책임원칙 훼손위기의 통제방안으로는 기존의 책임 원칙을 좀 더 보강하고 강화할 수밖에 없다. 특정 기업이 담합할 가능성이 높다고 판단할 예측 알고리즘의 판단을 근거로 해당 기업을 처벌하면 안 되고, 실제 담합한 결과에 대해서만 처벌해야 한다.
데이터의 오용
(위기 요인)
빅데이터는 일어난 일에 대한 데이터에 의존한다. 그것을 바탕으로 미래를 예측하는 것은 적지 않은 정확도를 가질 수 있지만 항상 맞을 수 없다. 주어진 데이터에 잘못된 인사이트를 얻어 비즈니스에 직접 손실을 불러올 수 있다.
(통제 요인)
이러한 문제를 해결하기 위해 알고리즘에 대한 접근법을 보장해야 한다는 목소리가 높아지고 있다. 나아가 접근권뿐만 아니라 객관적인 인증방안을 도입하자는 의견도 제시되고 있으며, 알고리즘이 부당함을 반증할 수 있는 방법을 명시해 공개할 것을 주문하기도 한다.
빅데이터의 위기 요인과 통제 방안에 대한 설명 중 올바르지 않는 것은?
1) 데이터 오용의 위기 요소에 대한 대응책으로 알고리즘에 대한 접근권 보장과 알고리즈미스트가 필요하다
2) 특정인이 채용이나 대출 등에서 예측 자료에 의한 불이익을 당할 가능성을 최소화하는 장치를 마련하는 것이 필요하다
3) 책임원칙 훼손 위기에 대한 통제 방안으로 개인정보 활용에 대한 동의제를 책임제로 전환하는 것이 효과적이다.
4) 사생활침해 가능성도 함께 증가하고 있기 때문에 개인정보 활용에 대한 가이드라인 제정에 대한 요구가 급증하고 있다.
2. 데이터 3법 주요 개정 내용
데이터 3법은 데이터이용을 활성화하는 개인정보보호법, 정보통신망 이용촉진 및 정보보호 등에 관한 법률(이하 정보통신망법), 신용 정보의 이용 및 보호에 관한 법률(이하 신용정보법) 등 3가지 법률을 통칭한다.
마이데이터 산업
2020년 8월 5일부터 개정된 데이터 3법이 시행되는데, 이때부터 금융 분야 마이데이터 사업을 하려면 금융위원회부터 허가를 얻은 후 개인의 동의 하에 타 기업에 저장된 개인정보 활용이 가능하다
이로 인해 개인은 통합 데이터를 이용한 맞춤형 금융서비스를 제공받고, 기업은 새로운 비즈니스 모델 실행이 가능하게 되었다. 네이버 파이낸셜, 카카오페이, 비바리퍼블리카, 뱅크샐러드 등과 여러 은행들이 뛰어든 그 사업이 바로 마이데이터 사업이다.
데이터 3법 주여 개정 내용
데이터이용 활성화를 위한 가명정보개념 도입
관련법률의 유사, 중복 규정을 정비하고 추진체계를 일원화하는 등 개인정보 보호 협치(거버넌스) 체계의 효율화
데이터 활용에 따른 개인정보처리자의 책임 강화
모호한 개인정보판단 기준의 명확화
3. 달라진 개인정보 보호법
개정 개인정보 보호법 2020년 8월 5일 시행
개인정보 판단 기준 명확화
개인정보의 판단기준 세부화, 익명 정보는 법 적용 대상이 아님을 명시
개정 전(기존)
개인 정보 : 살아있는 개인에 관한 정보
개정 후(달라지는 점)
개인 정보
1) 살아있는 개인에 관한 정보
2) 개인 정보를 익명처리한 정보
가명 처리된 정보(가명 정보)는 통계작성, 과학적 연구, 공익적 기록 보존등의 목적으로 동의 없이 처리 가능
수집 목적과 합리적 관련 범위 내에서 활용 확대
개정 전(기존)
개인정보 수집 이용 또는 제공 시 사전에 목적을 구체적으로 정하고, 그 목적의 범위에서 이용/제공 가능
목적변경 시 정보주체의 재동의 필요
개정 후(달라지는 점)
당초 수집 목적과 합리적으로 관련된 범위 내에서 정보주체의 동의 없이 개인 정보 이용 제공 가능
고려 사항 :
정보주체에게 불이익이 발생하는지 여부, 암호화 등 안전성 확보조치 여부
개인정보보호 추진 체계 효율화
개정 전(기존)
행안부, 방송위. 개인정보위 등 분야별 감독 기구 상이
개정 후(달라지는 점)
개인정보보호 위원회로 감독 기구 일원화
개인 정보 처리자 책임성 강화 :
가명처리 처리 및 결합시 안정성 확보에 필요한 기술적/관리적 및 물리적 조치 의무, 재식별 금지 의무, 위반시 벌칙 조항이 신설
4. 개인정보 처리단계별 보호
1) 개인정보의 수집/이용
개인정보수집 : 정보주체로부터 직접 이름, 주소, 전화번호 등의 정보를 제공받는 것뿐만 아니라 정보 주체에 관한 모든 형태의 개인 정보를 취득하는 것을 말한다.
정보원칙 : 개인 정보는 정보주체로부터 직접 수집이 원칙이냐 필요한 경우 제3자(국가 기관, 신용평가기관 등), 공개된 자료원(인터넷, 전화번호부) 등에서 수집 이용 가능
2) 개인 정보의 수집 및 수집 목적내 이용이 가능한 경우
정보주체의 동의를 받는 경우
법률에 특별한 규정이 있거나 법령상 의무를 준수하기 위하여 불가피한 경우
공공기관이 법령 등에서 정하는 소관 업무의 수행을 위하여 불가피한 경우
정보주체와의 계약의 체결 및 이행을 위하여 불가피하게 필요한 경우
명백히 정보주체 등의 급박한 생명, 신체, 재산의 이익을 위해 필요한 경우
(정보주체의 권리보다 우선하는) 개인정보처리자의 정당한 이익 달성을 위하여 필요한 경우
3) 개인정보 수집/이용 동의 시 필수 고지 사항
개인정보의 수집/이용 목적
수집하려는 개인정보의 항목
개인 정보의 보유 및 이용 기간
동의를 거부할 권리가 있다는 사실 및 동의 거부에 따른 불이익이 있는 경우에는 그 불이익의 내용
4) 개인정보의 수집 제한
개인정보를 수집할 때에는 그 목적에 필요한 범위에서 최소한의 개인 정보만을 적법하게 정당하게 수집하여야 한다.
개인 정보수집 처리자는 '정보주체가 필요 최소한의 정보 외의 개인정보 수집에 동의하지 않는다'라는 이유로 정보주체에게 재화 또는 서비스의 제공을 거부할 수 없다.
(1) 민감 정보/고유식별정보 처리제한
예외적으로 정보주체에게 별도 동의를 얻거나, 법령에서 구체적으로 허용된 경우에 한하여 처리 가능하다
민감 정보
사상/신념
노동조합/정당의 가입/철회
정치적 견해
건강/성 생활 등에 대한 정보
유전자 검사 등의 결과로 얻어진 유전정보
범죄경력자료에 해당하는 정보
고유식별정보
주민등록번호
외국인등록번호
여권번호
운전면허번호
5) 데이터 비식별화
비식별기술
가명처리
제거방법 :
개인정보 중 주요 식별요소를 다른 값으로 대체하여 개인식별을 곤란하게 한다.
예시
홍길동, 35세, 서울 거주, 한국대 재학
-> 임꺽정, 30대, 서울 거주, 한국대 재학
총계처리 또는 평균값 대체
데이터의 총합 값을 보임으로써 개별 데이터의 값을 보이지 않도록 한다.
예시
임꺽정 180cm, 홍길동 170cm
이콩쥐 160cm, 김팥쥐 150cm
-> 물리학과 학생 키 합 660cm, 평균키 165cm
데이터 값(가치) 삭제
데이터 공유, 개방 목적에 따라 데이터셋에 구성된 값 중에 필요 없는 값 또는 개인 식별에 중요한 값을 삭제
예시
홍길동, 35세, 서울 거주, 한국대 졸업
-> 35세 서울 거주
주민등록번호 901206-1234567
-> 90년대 생, 남자
개인과 관련된 날짜 정보(자격 취득일자, 합격일) 연 단위로 처리
연예인/정치인 등의 가족 정보(관계정보), 판례 및 보도 등에 따라 공개되어 있는 사건과 관련되어 있음을 알 수 있는 정보
데이터 마스킹
공개된 정보 등과 결합하여 개인을 식별하는데 기여한 확률이 높은 주요 개인식별자가 보이지 않도록 처리하여 개인을 식별하지 못하도록 한다.
예시
홍길동, 35세, 서울 거주, 한국대 재학
-> 홍OO , 35세, 서울 거주, OO대학 재학
5. 미래의 빅데이터
데이터 : 모든 것을 데이터화하는 추세를 빅데이터 시대에서 피할 수 없다. 특정한 목적없이 생산된 데이터라도 창의적으로 재활용면서 가치를 만들어낼 수 있기 때문이다.
기술 : 빅데이터 분석 알고리즘의 진화가 가속화될 것이다. 알고리즘은 데이터 양의 증가에 따라 정확도가 증가하는 일반적인 경향이 있다. 그것은 알고리즘을 학습시킬 수 있는 데이터의 양이 증가하면서 알고리즘도 스마트해지는 경향이 있음을 의미한다.
인력 : 데이터사이언티스트와 알고리즈미스트의 역할이 중요해질 것으로 전망된다. 데이터사이언티스트는 빅데이터의 다각도 분석을 통해 인사이트 도출하고 이를 조직 전략 방향 제시에 활용할 줄 아는 기획자로서 전문가 역할을 할 것으로 기대된다.
3장. 가치창조를 위한 데이터 사이언스와 전략 인사이트
01. 빅데이터 분석과 전략 인사이트
1. 빅데이터 열풍과 회의론
CRM을 비롯한 IT 솔루션은 일종의 공포 마케팅이 잘 통하는 영역이다. 처음엔 여기저기 도입만 하면 마치 모든 문제를 한 번에 해소할 것처럼 강조하다가 나중에는 분위기에 합류하지 못하면 위험에 처할지도 모른다는 공포 분위기가 조성된다. 그래서 거액을 투자해 하드웨어 박스와 솔루션을 도입한다. 하지만 이걸 어떻게 활용하고 어떻게 가치를 뽑아내야 할지 첫 번째 물음부터 다시 해야 하는 사태가 벌어진다. 빅데이터 열풍 또한 이와 유사한 패턴과 흐름을 반복하고 있다. 현재 소개되면 많은 빅데이터 성공 사례가 실은 기존의 분석 프로젝트를 포장해 놓은 게 태반이다. 국내 빅데이터 업체들이 성과 내기에 급급해 기존 분석을 빅데이터 분석으로 포장하는데 열을 올린다고 지적한다.
2. 왜 싸이월드는 페이스북이 되지 못했나?
구글이나 링크드인, 페이스북과 같은 성공적인 인터넷 기업들은 대부분 데이터 분석과 함께 시작되고, 분석이 내부 의사결정에 결정적 정보를 제공한다. 반면 싸이월드는 직관에 근거해 의사결정을 내리는 회사에 머물고 있었다. 즉 데이터 분석에 기초해 전략적 통찰을 얻고, 효과적인 의사결정을 내리고, 구체적인 성과를 만들어내는 체계가 없었기 때문이다.
전형적인 의사결정 오류
로직 오류
- 부정확한 가정을 하고 테스트를 하지 않는 것
- 시간을 충분히 들여 대안들을 이해하지 않거나 데이터를 정확하게 해석하지 않는 것
프로세스 오류- 결정에서 분석과 통찰력을 고려하지 않는 것
- 대안을 진지하게 고려하지 않는 것
- 데이터 수집이나 분석이 너무 늦어 사용할 수 없게 되는 것
3. 빅데이터 분석, 'Big'이 핵심이 아니다
'빅'한 데이터를 보유하고 있으면 거기서 무너가 쓸 만한 걸 찾아내고 가치를 창출할 수 있을 것이라고 생각한다. 하지만 더 많은 데이터가 더 많은 가치로 바로 연결된다고 볼 수 없다. 데이터의 양이 아니라 유형의 다양성과 관련이 있다. 빅데이터가 가져다주는 기회는 데이터의 크기에 있다가보다 음성, 텍스트, 이미지, 비디오 같은 새롭고 다양한 정보 원천의 활용에 있다.
4. 전략적 통찰이 없는 분석의 함정
한국의 경영 문화는 여전히 분석을 국소적인 문제 해결 용도로 사용하는 단계에 머물고 있다. 빅데이터는 고사하고 내부의 '스몰' 데이터도 활용하지 않는 경우가 더 많지 않을까 한다. 자칫 분석이 경쟁의 본질을 제대로 바라보지 못할 때 아무짝에도 쓸모없는 분석 결과들만 잔뜩 쏟아내게 되고 마는 것이다.
분석 지향성의 중요도 조사
상당한 의사결정 지원 / 분석 역량을 갖춤
폭넓은 가치 분석적 통찰력을 갖춘다.
산업 평균 이상의 분석 역량을 갖춘다
전체조직에서 분석을 활용
전략적 통찰없이 복잡화 최적화 또는 단순히 분석을 많이 사용하는 것이 경쟁우위를 가져다 주지 않는다.
이 조사는 34개국 18개 산업에 이르는 371개 기업에 재직 중인 경영진을 대상으로 이뤄졌다. 한 가지 특징적인 부분은 성과가 높은 기업이 성과가 낮은 기업보다 분석에 대한 태도와 분석의 응용 부분은 차이가 발생했지만 산업평균이상의 분석역량을 갖췄다고 응답한 비율이 77%에 달한 것에 비해
가치 분석적 통찰력을 갖췄다고 응답한 비율은 그 절반에도 못 미치는 36%에 불과했다. 그만큼 기업의 핵심 가치와 관련해 전략적 통찰력을 가져다 주는 데이터 분석을 내재화하는 것이 쉬운 일이 아닌 것이다.
5. 일차적인 분석 vs. 전략 도출 위한 가치 기반 분석
우선적으로 일차원적인 분석을 통해서도 해당 부서나 업무 영역에서도 상당한 효과를 얻을 수 있다. 이런 일차원적인 분석 경험이 즌가하고 분석의 활용 범위를 더 넓고 전략적으로 변화시켜야 한다. 전략적 인사이트를 주는 가치 기반 분석을 위해서는 우선 사업과 이에 영향을 미치는 트렌드에 대한 큰 그림을 그려야 한다. 인구통계학적 변화, 경제 사회 트렌드, 고객 니즈의 변화 등을 고려하고 또 다른 대변화가 어디서 나타날지도 예측해야 한다. 이처럼 큰 그림에서 폭넓게 사업을 바라보지 못한다면 비즈니스 성과와 경쟁력의 핵심인 전략적 이슈를 다룰 수 없다.
금융 서비스 : 신용 점수 산정, 사기 탐지, 고객 수익성 분석
소매업 : 재고 보충, 수요 예측
제조업 : 맞춤형 상품 개발, 신상품 개발
에너지 : 트레이딩, 공급, 수요 예측
온라인 : 웹 매트릭스, 사이트 설계, 고객 추천
02. 전략 인사이트 도출을 위한 필요 역량
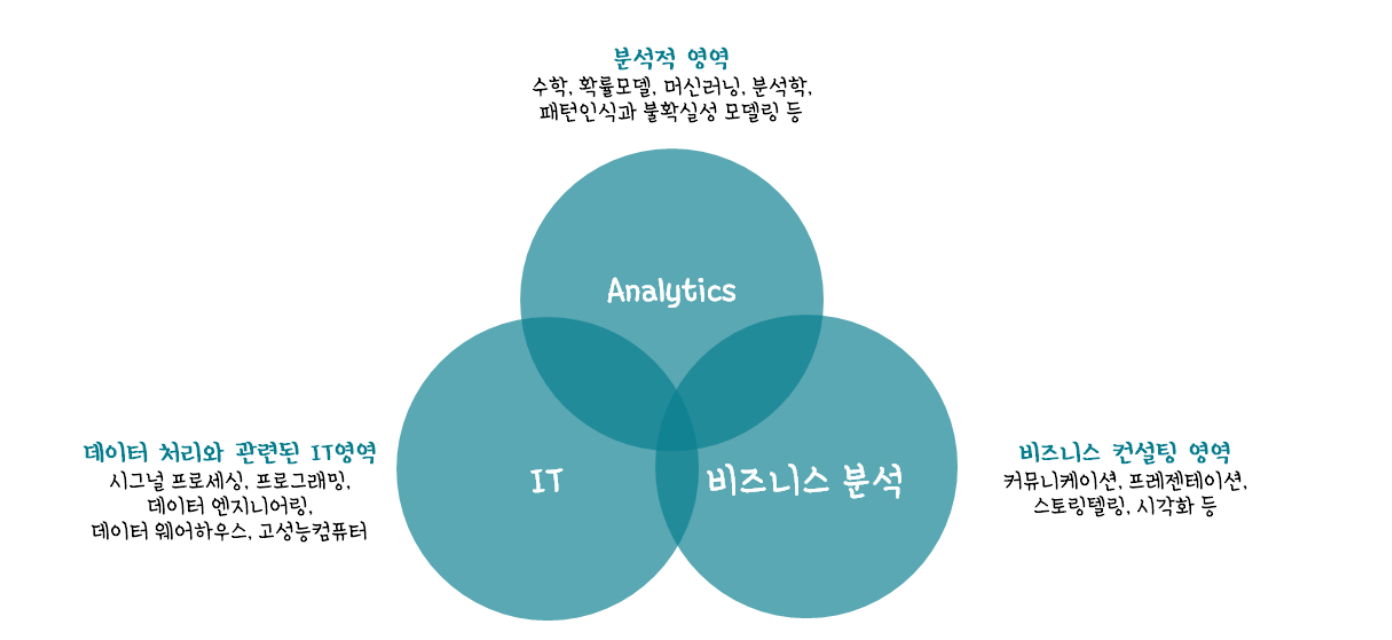
1. 데이터 사이언스의 의미와 역할
데이터 사이언스는 정형 또는 비정형을 막론하고 인터넷, 휴대전화, 감시용 카메라 등에서 생성되는 숫자와 문자, 영상 정보 등 다양한 유형의 데이터를 대상으로 한다. 데이터 사이언스가 기존의 통계학과 다른 점은 데이터 사이언스는 전략적 통찰을 추구하고 비즈니스 핵심 이슈에 답을 하고, 사업의 성과를 견인해 나갈 수 있다. 이것이 단순한 데이터 분석과 데이터 사이언스를 가른다.
Gartner가 본 데이터 사이언티스트의 역량
데이터 관리
분석 모델링
비즈니스 분석
소프트 스킬
2. 데이터 사이언스의 구성 요소
데이터 사이언스 3대 구성요소
3. 데이터 사이언티스트의 역량
외국의 각 전문가들은 강력한 호기심 (Intensive Curiosity)이야말로, 데이터 사이언티스트의 중요한 특징이라고 생각한다. 여기서 호기심이란 문제의 이면을 파고들고, 질문들을 찾고, 검증 가능한 가설을 세우는 능력을 의미한다. 우리의 빅데이터 환경에서 일하는 데이터 사이언티스트들은 주로 데이터 처리 분석 기술과 관련된 하드 스킬만 요구받고 있는 것처럼 보인다. 하지만 이러한 하드 스킬은 데이터 사이언티스트가 갖춰야 하는 능력의 절반에 불과하다. 나머지 절반은 통찰력 있는 분석, 설득력 있는 전달, 협력 등 소프트 스킬이다.
Hard Skill
빅데이터에 대한 이론적 지식 : 관련 기법에 대한 이해와 방법론 습득
분석 기술에 대한 숙련 : 최적의 분석 설계 및 노하우 축적
Soft SKill
통찰력 있는 분석 : 창의적 사고, 호기심, 논리적 비판
설득력 있는 전달 : 스토리텔링, Visualization
다분야 간 협력 : Communication
4. 데이터 사이언스 : 과학과 인문의 교차로
데이터 사이언스는 과학과 인문의 교차로에 서 있다고 할 수 있다. 그래서 세계적인 데이터 사이언스 전문가들이 이구동성으로 데이터 사이언티스트에게 스토리텔링, 커뮤니케이션, 열정, 직관력, 비판적 시각, 글쓰기 능력,대화 능력 등이 필요하다고 강조한다. 그리고 이러한 능력들은 대부분의 인문학의 주요 주제들이다.
5. 전략적 통찰력과 인문학의 부활
최근의 사회경제적 환경의 변화는 세 가지 정도의 특징적 흐름을 보이는 것으로 요약해 볼 수 있을 것이다.
단순 세계화에서 복잡한 세계화로의 변화이다. 다양성과 각 사회의 정체성과 그 맥락, 관계, 연결성, 창조성 등이 키워드로 대두되게 되었다.
비즈니스의 중심이 제품 생산에서 서비스로 이동이다. 제품이 고장이 나더라도 오히려 얼마나 뛰어난 고객 서비스를 제공해주느냐가 더 중요하게 되었다.
경제와 산업의 논리가 생산에서 시장 창조로 바뀌었다. 지금의 핵심은 해로운 현지화 패러다임에 근거한 시장 창조로 이동하였다.
6. 데이터 사이언티스트에 요구되는 인문학적 사고의 특성과 역할
아래 표는 데이터 사이언티스트가 다룰 수 있는 6가지 핵심 질문들을 간단하게 제시한다. 첫 번째 차원은 단순히 정보를 활용한다고 할 수 있는 정도의 수준이다. 과거 정보들은 무슨 일이 일어났는지, 정도를 요약해 주는 보고서 같은 단순한 형태로 정리된다. 두 번째 차원은 통찰력을 제시하는 단계다. 이 단계에서는 분석의 여러 두구들을 활용해 더 깊이 파고들어 간다. 이를 통해 사업 성과를 좌우하는 핵심적인 문제에 대해 훨씬 깊이 있고 유용한 대답을 얻을 수 있다.
Information
과거 : 무슨 일이 일어났는가? 리포팅
현재 : 무슨 일이 일어나고 있는가? 경고
미래 : 무슨 일이 일어날 것인가? 추출
Insight
과거 : 어떻게, 왜 일어났는가 모델링
현재 : 차선 행동은 무엇인가? 권고
미래 : 최악, 최선의 상황은? 예측, 최적화
최고의 데이터 사이언티스트는 정량 분석이라는 과학과 인문학적 통찰에 근거한 합리적인 추론을 탁월하게 조합한다.
7. 데이터 분석 모델링에서 인문학적 통찰력의 적용 사례
인간을 바라보는 유형별 세가지 관점
인간을 타고난 성향의 관점에서 바라보는 것이다. 인간을 변하지 않는 존재로 상정하고 있다.
인간을 행동적 관점에서 바라보는 것이다. 현재의 신용 리스크 모델은 인간을 행동적 관점에서 바라보고 있다.
인간을 상황적 관점에서 바라보는 것이다. 통상 특정 행동을 거듭하는 사람이 그 행동을 앞으로도 반복할 확률이 높다.
빅데이터 사이언티스트의 요구 역량에 해당되는 소프트스킬(SoftSkill)에 대한 설명 중 가장 적절하지 않은 것은
1) 통찰력 분석 2) 설득력 있는 전달 3) 다분야간 협력4) 빅 데이터에 대한 이론적 지식
03. 빅데이터 그리고 데이터 사이언스의 미래
1. 빅데이터의 시대
전 세계적으로 생성된 디지털 정보량이 2011년 기준으로 1.8제타바이트나 된다는 것은 널리 알려진 이야기다. 이는 대한민국 모든 사람이 18만 년 동안 쉬지 않고 1분마다 트위터에 3개의 글을 게시하는 양과 같다고 한다.
2. 빅데이터 회의론을 넘어 : 가치 패러다임의 변화
우리를 둘러싼 내외부의 환경들이 급변하고 있다. 세상이 빠르게 변할 때일수록 그 변화의 물결을, 그 물결의 흐름을 잘 읽어야 한다. 많은 신기술과 신상품, 서비스들은 이러한 가치 패러다임의 작동 원리에 맞아 떨어질 때 성공을 거두게 된다. 가치 패러다임 변화는 크게 3단계로 구분해 볼 수 있다.
'디지털화(Digitalization)'이다. 아날로그의 세상을 어떻게 효과적으로 디지털화하는가가 이 시대의 가치를 창출해내는 원천이었다. 그 대표 주자가 바로 빌 게이츠였다.
다음 단계의 가치 패러다임은 빌 게이츠가 제대로 보지 못한 '연결(Connection)'이란 것이다. 새로운 시대에서 디지털화된 정보와 대상들은 이제 서로 연결되기 시작했다. 이 연결을 얼마나 효과적이고 효율적으로 제공해주느냐가 이 시대의 성패를 가름한다. 지금도 인터넷에는 사람, 기기 등 상당히 많은 대상이 서로 연결되어 있지만 '사물 인터넷(Internet Of Things)'의 성숙과 함께 앞으로는 연결이 더 증가하고 극도로 복잡해질 것이다.
향후에는 "복잡한 연결을 얼마나 효과적이고 믿을 만하게 관리해주는가"의 이슈인 '에이전시(Agency)'가 키워드로 등장팔 확률이 매우 높다.
3. 데이터 사이언스의 한계와 인문학
아무리 정량적인 분석이라도 명심해야 할 것은 모든 분석은 가정에 근거한다는 사실이다. 아무리 뛰어난 모델도 항상 이러한 가정을 깔고 있다. 대표적인 예로 2008년 전후한 글로벌 금융 위기는 바로 이러한 잘못된 분석의 사용이 얼마나 엄청난 결과를 가져올 수 있는지를 보여주는 사건이다. 훌륭한 데이터 사이언티스트는 인문학자들처럼 모델의 능력에 대해 항상 의구심을 가지고, 가정들과 현실의 불일치에 대해 끊임없이 고찰하고, 분석모델이 예측할 수 없는 위험을 살피기 위해 현실 세계를 쳐댜봐야 한다.
스마트 팩토리
스마트 팩토리는 사물인터넷 기반으로 밸류체인의 모든 과정(기획, 설계, 생산, 유통, 서비스 등)에 관여 및 연계 활동을 하며, 공장 안팎의 모든 요소가 연계되어 공장의 모든 단계를 자동화, 디지털화한다.
4장 데이터 분석 기획의 이해
01 분석 기획 방향성 도출
1. 분석 기획의 특징
분석 기획이란 실제 분석을 수행하기에 앞서 분석을 수행할 과제의 정의 및 의도했던 결과를 도출할 수 있도록 이를 적절하게 관리할 수 있는 방안을 사전에 계획하는 일련의 작업이다.
분석 과제 및 프로젝ㅇ트를 직접 수행하는 것은 아니지만, 어떠한 목표(What)를 달성하기 위하여 어떤 데이터를 가지고 어떤 방식(How)을 수행할지에 대한 일련의 계호기을 수립하는 작업이기 때문에 성공적인 분석 결과를 도출하기 위한 중요한 사전 작업이다.
세 가지 여역에 대한 고른 역량과 시각이 필요하다. 분석을 기획했다는 것은 해당 문제 영역에 대한 전문성 역량 및 통계학적 지식을 활용한 분석역량과 분석의 도구인 데이터 및 분석의 도구인 데이터 및 프로그래밍 기술 역량에 대한 균형 잡힌 시각을 가지고 방향성 및 계획을 수립해야 한다는 것을 의미한다.
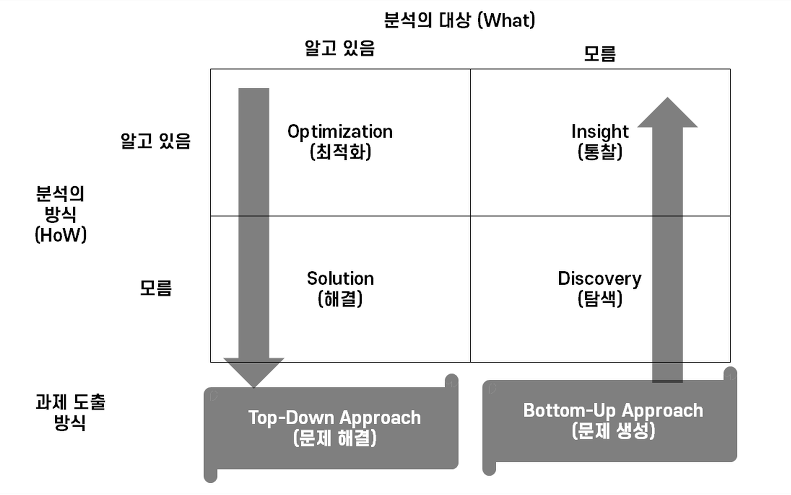
1) 분석 주제 유형
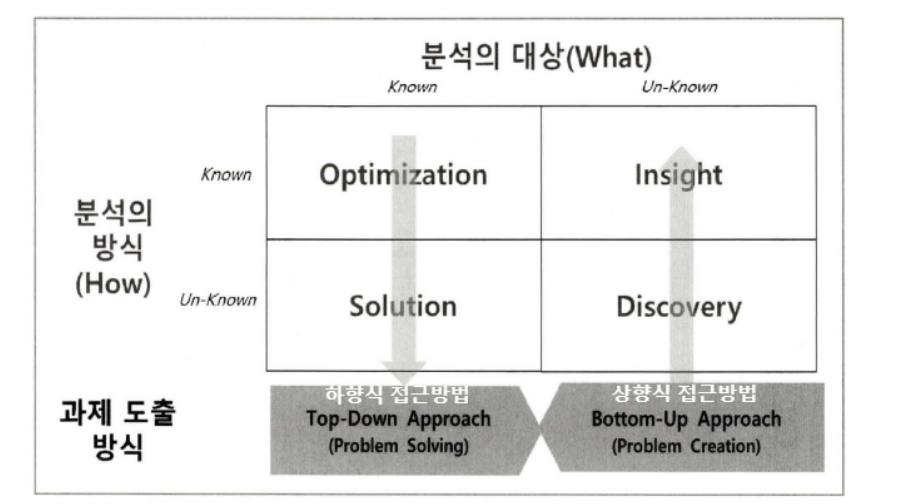
분석의 대상 및 분석의 방법에 따라서 아래 그림과 같이 4가지로 나누어진다.
분석의 주제 및 기법의 특성상 이러한 4가지 유형은 서로 융합적으로 반복하게 된다.
Optimization : 분석 대상 및 분석 방법을 이해하고 현 문제를 최적화의 형태로 수행
Solution : 분석 과제는 수행되고, 분석 방법을 알지 못하는 경우 솔루션을 찾는 방식으로 분석 과제 수행
Insight : 분석 대상이 불분명하고 분석 방법을 알고 있는 경우 인사이트 도출
Discovery : 분석 대상, 방법을 모른다면 발견을 통하여 분석 대상 자체를 새롭게 도출
분석의 대상이 명확하게 무엇인지 모르는 경우에 기존 분석 방식을 활용하여 새로운 지식을 도출하는 분석 주제 유형은 무엇인가
1. Optimization
2. Insight
3. Solution
4. Discovery
2) 목표 시점별 분석 기획 방안
목표 시점별로는 당면한 과제를 빠르게 해결하는 "과제 중심적인 접근 방식"과 지속적인 분석 내재화를 위한 "장기적인 마스터 플랜 방식"으로 나누어 볼 수 있으며 이 둘은 융합적으로 적용하는 것이 바람직하다
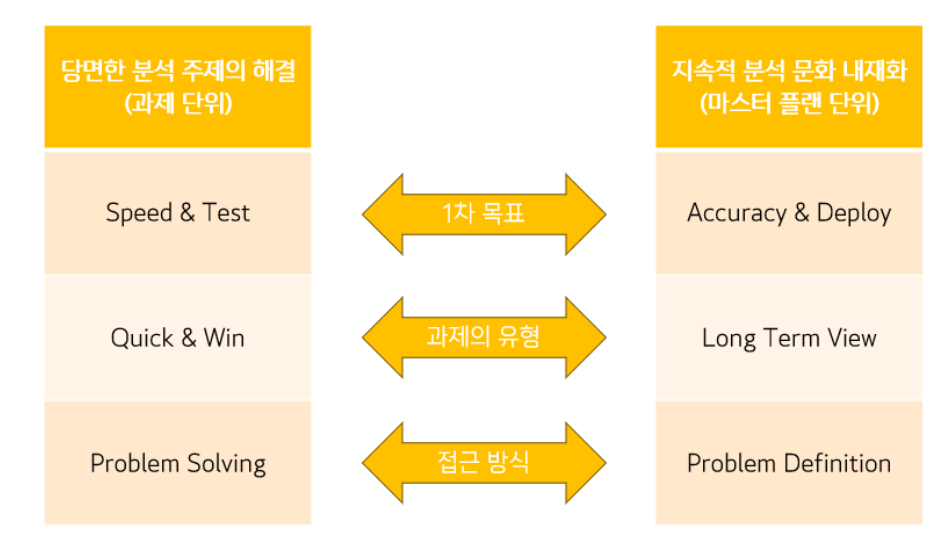
Quick-win(즉각적인 실행을 통한 성과 도출)은 프로세스 진행 과정에서 일반적인 상식과 경험으로 원인이 명백한 경우 불합리한 요소를 개선 단계까지 미루지 않고, 바로 개선함으로써 과제를 단기로 달성하고 추진하는 과정을 말한다.
2. 분석 기획 시 고려사항
1) 가용한 데이터(Available Data)
분석을 위한 데이터의 확보가 필수적이다. 데이터 유형에 따라서 적용 가능한 솔루션 및 분석 방법이 다르기 때문에 유형에 대한 분석이 선행적으로 이루어져야 한다.
ex) 정형 데이터, 비정형 데이터, 반정형 데이터
(1) 수집 데이터의 형태에 따른 분류
데이터를 형태에 따라 분류해보면 정형 데이터, 반정형 데이터, 비정형 데이터로 나눌 수 있다.
정형 데이터(Structured Data)
정형 데이터(Structured Data)는 관계형 데이터베이스 시스템의 테이블과 같이 고정된 컬럼에 저장되는 데이터와 파일, 그리고 지정된 행과 열에 의해 데이터의 속성이 스프레드시트 형태의 데이터도 있을 수 있다.
관계형 데이터베이스 시스테므이 정형 데이터를 비정형 데이터(Unstructured Data)와 비교할 때 가장 큰 차이점은 데이터의 스키마를 지원하는 것이다.
정형 데이터의 경우 스키마 구조를 가지고 있기 때문에 데이터를 탐색하는 과정인 테이블 탐색, 컬럼 구조 탐색, 로우 탐색 순으로 정형화되어 있다.
정형 데이터의 예 : RDBMS의 테이블들(단일 테이블 혹은 조인한 테이블을 포함), 스프레드시트
반정형 데이터(Semi-Structured Data)
정형 데이터는 데이터의 스키마 정보를 관리하는 DBMS와 데이터 내용이 저장되는 데이터 저장소로 구분되지만, 반정형 데이터는 데이터 내부에 정형 데이터의 스키마에 해당되는 메타데이터를 갖고 있으며, 일반적으로 파일 형태로 저장된다.
반정형 데이터의 경우 데이터 내부에 데이터 구조에 대한 메타 정보를 갖고 있기 때문에 어떤 형태를 가진 데이터인지 파악하는 것이 필요하다
데이터 내부에 있는 규칙성을 파악해 데이터를 파싱할 수 있는 파싱 규칙을 적용한다.
반정형 데이터의 예 : URL 형태로 존재, HTML, 오픈 API 형태로 제공, XML, JSON 로그 형태, 웹로그 IOT에서 제공하는 센서 데이터
파싱(Parsing)은 어떤 페이지(문서; html)에서 내가 원하는 데이터를 특정 패턴이나 순서로 추출해 가공하는 것을 말한다.
비정형 데이터(Unstructured Data)
비정형 데이터(Unstructured Data)는 데이터 세트가 아닌 하나의 데이터가 수집 데이터로 객체화되어 있다. 언어 분석이 가능한 텍스트 데이터나 이미지, 동영상 같은 멀티미디어 데이터가 대표적인 비정형 데이터이다.
웹에 존재하는 데이터의 경우 html 형태로 존재하여 반전형 데이터로 구분할 수도 있지만, 특정한 경우 텍스트 마이닝을 통해 데이터를 수집하는 경우도 존재하므로 명확한 구분도 어렵다.
비정형 데이터의 예 : 동영상, 이미지, 소셜 데이터의 텍스트
데이터 저장 방식
RDB
관계형 데이터를 저장하거나 수정하고 관리할 수 있게 해주는 데이터베이스
SQL 문장을 통하여 데이터베이스의 생성, 수정 및 검색 등 서비스를 제공
도구 : Oracle, MSSQL, MySQL 등
NoSQL
Not-Only SQL의 약자이며 비관계형 데이터 저장소로 기존의 전통적인 방식의 관계형 데이터베이스와는 다르게 설계된 데이터베이스
MongoDB, Cassandra. HBase, Redis
분산 파일 시스템(Distributed File System)
분산된 서버의 로컬 디스크에 파일을 저장하고 파일의 읽기, 쓰기등과 같은 연산을 운영체제가 아닌 API를 제공하여 처리하는 파일 시스템
도구 : HDFS 등
2) 적절한 유스케이스(Proper Use-Case) 탐색
유사 분석 시나리오 및 솔루션이 있다면 이를 최대한 활용하는 것이 중요하다
3) 장애 요소들에 대한 사전 계획 수립이 필요(Low Barrier of Execution)
정확도를 올리기 위해서는 기간과 투입 리소스가 늘어나게 되는데 이것은 비용 상승으로 이어질 수 있으므로 많은 사전 고려가 필요하다 일회성 분석으로 그치지 않고 조직의 역량을 내재화하기 위해서는 충분하고 계속적인 교육 및 활용 방안 등의 변화관리(Change Management)는 고려되어야 한다.
분석 기획 고려 사항 중 장애 요소에 대한 부적절한 설명은
1. 데이터 유형에 따라서 적용 가능한 솔루션 및 분석 방법이 다르기 때문에 요형에 대한 분석이 선행적으로 이루어져야 한다.
2. 유사 분석 시나리오 및 솔루션이 있다면 이를 최대한 활용하는 것이 중요하다
3. 장애요소들에 대한 사전 계획 수립이 필요하다
4. 이해하기 쉬운 모델보다는 복잡하고 정교한 모형이 더 효과적이다.
02 분석 방법론
1. 분석 방법론 개요
데이터 분석을 효과적으로 기업에 정착하기 위해서는 이를 체계화하는 절차와 방법이 정리된 데이터 분석 방법론의 수립이 필수적이다.
일반적으로 방법론은 계층적 프로세스 모델(Stepwised Process Model)의 형태로 구성된다. 최상위 계층은 단계(Phase)로서 프로세스 그룹(Process Group)을 통하여 완성된 단계별 완료보고서가 생성된다.
각 단계는 여러 개의 태스크(Task)로 구성되는데 각 태스크는 단계를 구성하는 단위 활동으로 구성되며 마지막 계층은 스탭(Step)으로 입력 자료, 처리 및 도구, 출력 자료로 구성된 단위 프로세스이다.
분석 방법론의 구성요소
상세한 절차(Procedure)
방법(Methods)
도구와 기법(Tools & Techniques)
템플릿과 산출물(Templates & Outputs)
1) 기업의 합리적 의사결정의 중요성
최근 기업 경쟁력을 향상하기 위하여 데이터 분석 및 활용의 중요성이 강조되고 있다.
지금까지 기업들은 일반 수준의 품질목표나 재무성과를 달성하기 위하여 데이터 기반의 의사결정보다는 경험과 감에 의한 판단만으로도 어느 정도 목표를 달성할 수 있었다.
그러나 극한의 글로벌 경쟁 환경에서는 더 이상 경험과 감에 의한 의사결정으로는 한계가 있음을 인식하고 데이터 기반의 의사결정을 위하여 많은 노력을 기울이고 있다.
고정관념, 편향된 생각, 프레이밍 효과 등은 기업의 합리적인 의사졀정을 가로막는 장애요소에 해당된다.
결국 데이터 깁나의 의사결정을 하기 위해서는 기업 문화의 변화와 업무 프로세스 개선이 필요하다.
프레이밍 효과(Framing Effect)는 문제의 표현 방식에 따라 같은 사건이나 상황임에도 불구하고 개인의 판단이나 선택이 달라질 수 있는 현상
기업의 합리적 의사결정의 장애요소에 해당하는 것은
1. 프레이밍, 고정관념
2. 직관력, 프레이밍 효과
3. 비편향적 사고, 고정관념
4. 편향된 생각, 방법론에 근거한 의사결정
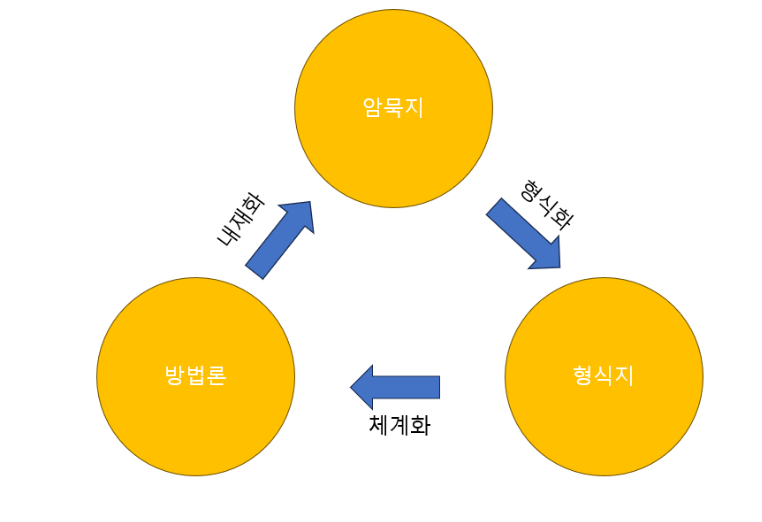
2) 방법론의 생성 과정
일반적으로 방법론의 생성 과정은 개인의 암묵지가 조기의 형식지로 발전하는 형식화 과정을 거치고 이를 체계화하여 문서화하고 이를 최적화된 형식지로 전개됨으로써 방법론이 만들어질 수 있다.
이렇게 만들어진 방법론은 다시 개인에게 전파되고 활용되는 내재화 과정을 거쳐 암묵지로 발전하는 선순환 과정이 진행되면서 조직 내 방법론으 와성될 수 있다.
방법론은 적용 업무의 특성에 따라 다양한 모델을 가질 수 있다
3) 다양한 방법론에 따른 분석모형 프로세스
폭포수(Waterfall) 모델
단계별로 철저한 검토와 승인 과정을 거쳐 확실히 매듭짓고 다음 단계로 진행하는 모델
하향식(Top Down) 진행되지만, 문제나 개선 사항이 발견되면 전 단계로 돌아가는 피드밸 과정을 수행
나선형(Spiral) 모델
여러 번의 개발 과정을 거쳐 점진적으로 프로젝트를 완성해가는 모델
처음 시도하는 프로젝트에 적용이 용이, 반복에 대한 관리체계를 효과적으로 갖추지 못한 경우 프로젝트 진행이 어렵다.
대규모 시스템 소프트웨어 개발에 적합하다
프로토타입(Prototype) 모델
사용자가 요구 사항이나 데이터를 정확히 규정하기 어렵고 데이터 소스도 명확히 파악하기 어려운 상황에서 일단 분석을 시도해보고 그 결과를 확인해가면서 반복적으로 개선해 나가는 방법
프로토타이핑 모델은 요구 사항을 분석한 후 프로토타입을 개발하여 평가글 받는다. 평가 결과에 따라 개발 실행 또는 프로토타입 개선이나 요구사항을 재분석한다. 폭포수 모델의 피드백에 대한 어려움을 보완하기 위해 프로토타이핑 제작과 평가를 추가한다.
폭포수 모델
특징 : 순차적 접근
장점 :
이해가 용이
관리가 편리하다
단점 :
전반부 요구분석 어려움
프로토타이핑 모델
특징 : 프로토타입 개발
장점 :
요구분석 용이
개발 타당성 검증 가능
단점 :
프로토타입 폐기에 따른 비용 증가
나선형 모델
특징 : 위험 분석, 반복 개발
장점 :
위험성 감소와 변경에 유연한 대처
단점 :
단계 반복에 따른 공정관리 어려움
2. KDD 분석 방법론
KDD(Knowledge Discovery in Database)는 1966년 Eayyad가 체계적으로 정리한 데이터마이닝 프로세스로서 데이터베이스에서 의미 있는 지식을 탐색하는 데이터마이닝, 기계학습, 인공지능, 패턴 인식, 데이터 시각화 등에서 응용될 수 잇는 구조를 갖고 있다.
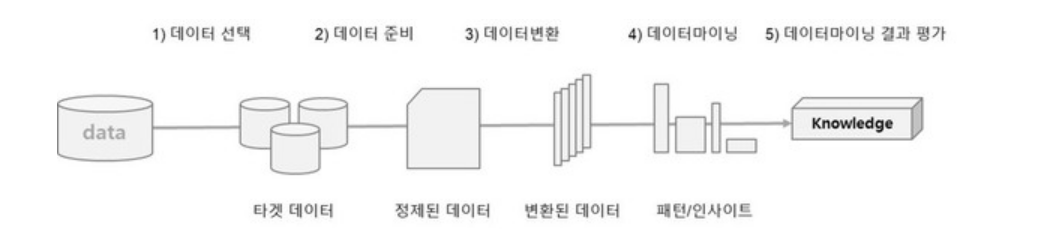
1) KDD 분석 절차
1. 데이터셋 선택(Selection)
분석 대상의 비즈니스 도메인에 대한 이해와 프로젝트의 목표를 설정
데이터마이닝에 필요한 목표데이터 선택
2. 데이터 전처리(Preprocessing)
분석 데이터셋에 포함되어 잇는 잡음(Noise), 이상값(Outlier), 결측치(Missing Value)를 식별하고 필요시 제거
3. 데이터 변환(Transformation)
분석 목적에 맞는 변수를 선택하거나 데이터의 차원을 축소하여 데이터바이닝을 효율적으로 적용할 수 있도록 데이터셋을 변경
4. 데이터 마이닝(Data Mining)
변환된 데이터셋을 이용하여 분석 목적에 맞는 데이터 마이닝 기법을 선택하고 데이터 마이닝 알고리즘을 선택하여 데이터의 패턴을 찾거나 데이터를 분류 또는 예측 등의 마이닝 작업을 시행
5. 데이터 마이닝 결과평가(Interpretation/Evaluation)
분석 결과에 대한 해석과 평가 및 활용
3. CRISP-DM 분석 방법론
CRISP-DM(Cross Industry Standard Process for Data Mining)은 1996년 유럽 연합의 ESPRIT에서 있었던 프로젝트에서 시작되었으며, 계층적 프로세스 모델로서 4개 레벨로 구성되어 있다.
최상위 레벨은 여러 개의 단계(Phases)로 구성되고 각 단계는 일반화 태스크(GeneticTasks)를 포함한다.
일반화 태스크는 데이터 마이닝의 단일 프로세스를 완전하게 수행하는 단위이다.
세 번째 레벨은 세분화 태스크(Specialized Tasks)로 일반화 태스크를 구체적으로 수행하는 레벨이다.
예를 데이터 정제(Data Cleaning)의 일반화 태스크는 범주형 데이터 정제, 연속형 데이터 정제 등으로 구체화된 세부화 태스크가 있다.
마지막으로 레벨인 프로세스 실행(Process Instance)은 데이터 마이닝을 위한 구체적인 실행을 포함한다.
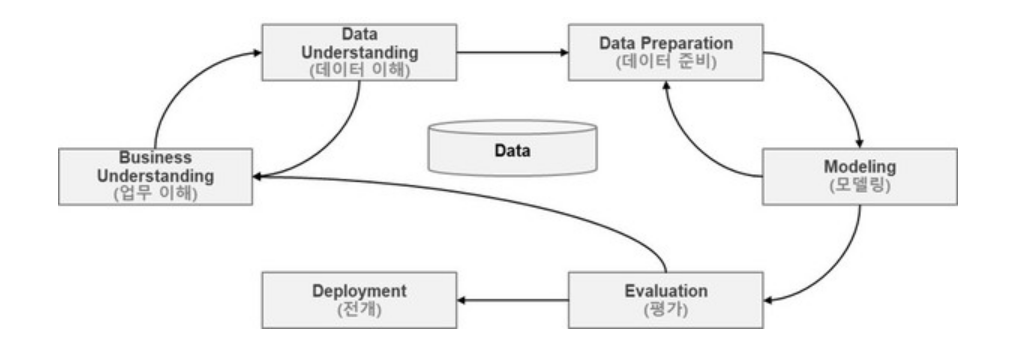
1) CRISP-DM 분석 절차
CRISP-DM 프로세스는 6단계로 구성되어 있으며, 각 단계는 폭포수 모델처럼 일방향으로 구성되어 있지 않고 단계 간 피드백을 통하여 단계별 완성도를 높이게 되어 있다.
1. 업무 이해(Business Understanding)
비즈니스 관점 프로젝트의 목적과 요구 사항을 이해하기 위한 단계로서, 도메인 지식을 데이터 분석을 위한 문제 정의로 변경하고 초기 프로젝트 계획을 수립하는 단계
업무 목적 파악, 상황 파악, 데이터 마이닝 목표 설정, 프로젝트 계획 수립
2. 데이터 이해(Data Understanding)
데이터 이해는 분석을 위한 데이터를 수집하고 데이터 속성을 이해하기 위한 과정으로 구성되고, 데이터 품질에 대한 문제점을 식별하고 숨겨져 있는 인사이트를 발견하는 단계
초기 데이터 수집, 데이터 기술 분석, 데이터 탐색, 데이터 품질 확인
3. 데이터 준비(Data Preparation)
데이터 준비는 분석을 위하여 수집된 데이터에서 분석 기법에 적합한 데이터셋을 편성하는 단계로서 많은 시간 소요
분석용 데이터 셋 선택, 데이터 정제 데이터 통합, 데이터 포맷팅
4. 모델링(Modeling)
다양한 모델링 기법과 알고리즘을 선택하고 모델링 과정에서 사용되는 파라미터를 최적해 나가는 단계, 모델링 단계를 통하여 찾아낸 모델은 테스트용 프로세스와 데이터셋으로 평가하여 모델 최적화(Overfitting) 등의 문제를 발견하고 대응 방안이 마련
모델링 기법 선택, 모델 테스트 계획 설계 모델 작성, 모델 작성, 모델 평가로 구성
5. 평가(Evalaution)
모델링 단계)에서 얻은 모델이 프로젝트의 목적에 부합하는지 평가 이 단계의 목적은 데이터 마이닝 결과를 수용할 것인지 최종적으로 판다
분석 결과 평가, 모델링 과정 평가, 모델 적용성 평가
6. 전개(Deployment)
모델링과 평가 단계를 통하여 완성된 모델을 실제 업무에 적용하기 위한 계획 수립
전개 계획 수립, 모니터링과 모델링 유지 모수 계획 수립, 프로젝트 종료 보고서 작성, 프로젝트 리뷰
과적합(Overfitting)은 기계학습에 학습데이터를 과하게 학습하는 것을 의미한다. 일반적으로 학습데이터는 실제 데이터의 부분집합이므로 학습데이터에 대해서는 오차가 감소하지만 실제 데이터에 대해서는 오차가 증가하게 된다.
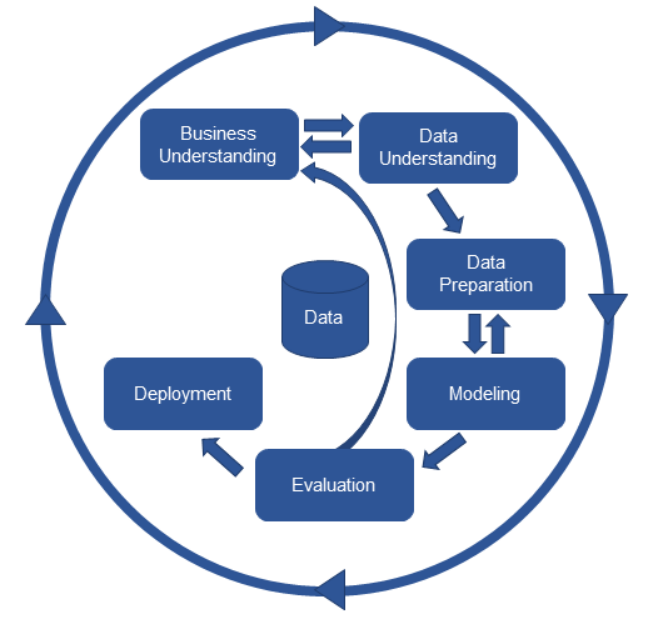
다음 중 CRISP-DM의 모델링 단계의 Task로 올바르지 않은 것은?
1. 모델링 기법 선택
2. 모델 테스트 계획 설계
3. 모델 작성
4. 모델 적용성 평가
2) KDD와 CRISP-DM 비교
KDD
분석 대상 비즈니스 이해
데이터셋 이해(Selection)
데이터 전처리(Preprocessing)
데이터 변환(Transformation)
데이터 마이닝(Data Mining)
데이터 마이닝 결과 평가(Interpretation/Evaluation)
데이터 마이닝 활용
CRISP-DM
업무 이해(Business Understanding)
데이터 이해(Data Understanding)
데이터 준비(Data Preparation)
모델링(Modeling)
평가(Evaluation)
전개(Deployment)
4. 빅데이터 분석 방법론
1) 빅데이터 분석방법론의 계층적 프로세스 모델
빅데이터를 분석하기 위한 방법론은 계층적 프로세스 모델(Stepwised Process Model)로써 3계층으로 구성된다.
단계(Phase)
프로세스 그룹(Process Group)을 통하여 완성된 단계별 산출물이 생성되어야 한다.
각 단계는 기준선(Baseline)으로 설정되어 관리되어야 하며 버전 관리(Configuration Management) 등을 통하여 통제가 이루어져야 한다.
태스크(Task)
각 단계는 여러 개의 태스크(Task)로 구성되는데 각 태스크는 단계를 구성하는 단위 활동으로써 물리적 또는 논리적 단위로 품질검토의 항목이 될 수 있다.
스탭(Step)
WBS(Work Breakdwon Structure)의 워크패키지에 해당되고 입력 자료(Input), 처리 및 도구(Process & Tool), 출력자료(Output)로 구성된 단위 프로세스(Unit Process)이다.
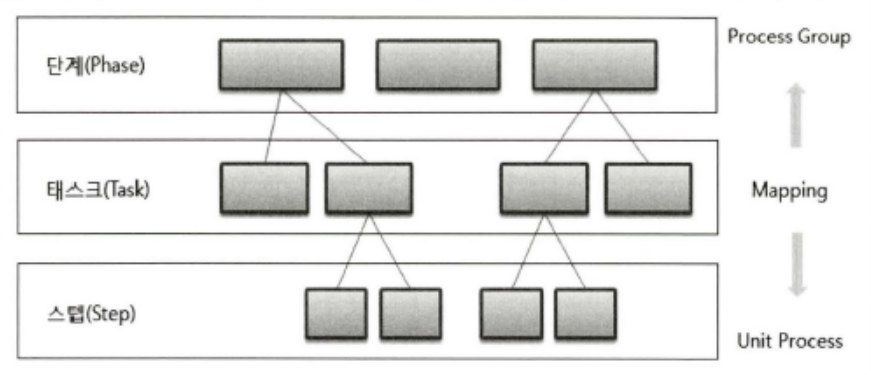
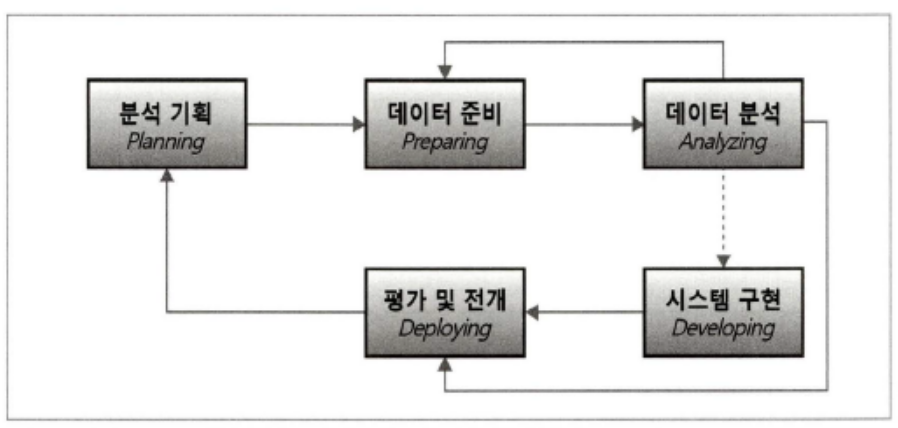
2) 빅데이터 분석 방법론
1. 분석 기획(Planning)
비즈니스 도메인과 문제점을 인식하고 분석 계획 및 프로젝트 수행 계획을 수립
2. 데이터 준비(Preparing)
비즈니스 요구 사항과 데이터 분석에 필요한 원천 데이터를 정의하고 준비
3. 데이터 분석(Analysis)
데이터 분석을 위한 원천 데이터가 확보되면 분석용 데이터셋으로 편성하고 다양한 분석 기법과 알고리즘을 이용
분석 단계를 수행하는 과정에서 추가적인 데이터 확보가 필요한 경우 데이터 준비(Preparing) 단계로 피드백하여 두 단계를 반복하여 진행
시스템 구현(Developing)
데이터 분석 단계를 진행하면서 분석 기획에 맞는 모델링을 도출하고 이를 운영 중인 가동 시스템에 적용하거나 시스템 개발을 위한 사전 검증으로 프로토타입 시스템을 구현
평가 및 전개(Deploying)
데이터 분석 및 시스템 구현 단계를 수행한 후 프로젝트의 성과를 평가하고 정리하거나 모델의 발전 계획을 수립하여 차기 분석 기획으로 전달하는 '평가 및 전개(Deploying)' 단계를 수행하여 빅데이터 분석 프로젝트를 종료
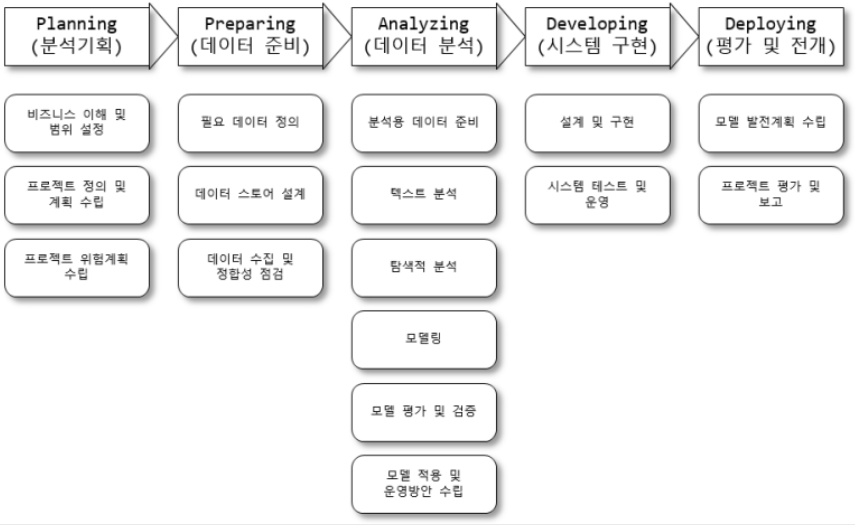
5. 빅데이터 단계별 프로세스
분석 기획
- 비즈니스 이해 범위 및 범위 설정
프로젝트를 참여하는 관계자들이(Stakeholders)의 이해를 일치시키기 위하여 구조화된 프로젝트 범위 정의서인 SOW(Statement of Work)를 작성
- 프로젝트 정의 및 계획 수립
프로젝트의 목표 및 KPI(핵심성과지표), 목표 수준 등을 구체화하여 상세 프로젝트 정의서를 작성
프로젝트 수행 계획서를 작성하는 단꼐로서 프로젝트의 목적 및 배경, 기대효과, 수행방법, 일정 및 추진조직, WBS를 작성한다.
- 프로젝트 위험계획 수립
데이터 분석 위험 식별, 계획 수립 단계에서 빅데이터 분석 프로젝트를 진행하면서 발생 가능한 모든 위험을 식별한다.
예상되는 위험에 대한 대응은 회피(Avoid), 전이(Transfer), 완화(Mitigrate), 수용(Accept)으로 구분하여 위험 관리 계획서를 작성한다.
데이터 준비
- 필요 데이터 정의
정형/비정형/반저형 등의 모든 내/외부 데이터를 포함하고 데이터의 속성, 데이터 오너, 데이터 관련 시스템 담당자 등을 포함하는 데이터 정의서를 작성한다. - 데이터 스토어 설계
일반적으로 관계형 데이터베이스(RDBMS)를 사용하고 데이터의 효율적인 저장과 활용을 위하여 데이터 스토어의 논리적, 물리적 설계를 구분하여 설계한다.
하둡, NoSQL 등을 이용하여 비정형 또는 반정형 데이터를 저장하기 위한 논리적, 물리적 데이터 스토어를 설계한다. - 데이터 수집 및 정합성 점검
크롤링 등의 데이터 수집을 위한 ETL 등의 다양한 도구와 API, 스크립트 프로그램 등을 이용하여 데이터를 수집하고, 수집된 데이터를 설계된 데이터를 스토어에 저장한다.
데이터 분석
- 분석용 데이터 준비
분석 계획 단계에서 비즈니스 이해, 도메인 문제점 인식 프로젝트 정의 등을 이용하여 프로젝트의 목표를 정확하게 인식한다.
데이터 스토어로부터 분석에 필요한 정형/비정형 데이터를 추출한다. - 텍스트 분석
감정 분석(Sentimental Analysis), 토픽 분석(Topic Anaylsis), 오피니언 분석(Ophinion Anaylsis), 소셜 네트워크 분석(SNA) 등을 실시하여 텍스트로부터 분석 목적에 맞는 적절한 모델을 구축한다. - 탐색적 분석
다양한 관점별로 기초 통계량을 산출하고 데이터의 분포와 변수 간의 관계 등 데이터 특성 및 데이터의 통계적 특성을 이해하고 모델링을 위한 기초 자료로 활용한다.
데이터 분석
- 모델링
모델링이란 분석용 데이터를 이용한 가설 설정을 통하여 통계 모델을 만들거나 기계학습을 이용한 데이터의 분류, 예측, 군집 등의 기능을 수행하는 모델을 만드는 과정이다.
데이터 분할, 데이터 모델링, 모델 적용 및 운영 방안 - 모델 평가 및 검증
프로젝트 정의서의 모델 평가 기준에 따라 모델을 객관적으로 평가하고 품질 관리 차원에서 모델 평가 프로세스를 진행한다.
시스템 구현
정의 및 구현
모델링 테스크에서 정의된 알고리즘 설명서와 데이터 시각화 보고서를 이용하여 시스템 및 아키텍처 설꼐 사용자 인터페이스 설계를 진행한다.
설계서를 바탕으로 패키지를 활용하여 프로그램을 구축한다.
시스템 테스트 및 운영
단위 테스트, 통합 테스트, 시스템 테스트 실시
평가 및 전개
모델발전 계획수립
개발된 모델의 지속적인 운영과 기능 향상을 위한 발전 계획을 상헤하게 수립한다.
프로젝트 평가 보고
프로젝트 성과를 정량적, 정성적으로 평가하고 프로젝트 진행 과정에서 산출된 지식, 프로세스, 출력 자료를 지식 자산화하고 프로젝트 최종 보고서를 작성한다.
WBS(WOrk Break Structure : 작업 문할 구조도)는 전체 업무를 분류하여 구성요소로 만든 후 각 요소를 평가하고 일정별로 계획하며 그것을 완주할 수 있는 사람에게 할당해주는 역할을 한다.
위험에 대한 대응 방법
회피(Avoid) : 위험의 영향도가 너무 커서 위험을 회피
전이(Transfer) : 위험의 영향을 다른 사람(방법)으로 전가시킴, 하자보수보증 등이 예
완화(Migration) : 어떠한 방법을 통해 영향도를 감소시키는 방법
수용(Accept) : 위험을 고스란히 수용하고 인력 투입 등의 방법으로 대응 처리
ETL(Extract Transform Load)은 데이터의 추출(Extraction), 변환(Transformation), 적재(Loading)의 약자로 비즈니스 인털리전스(BI) 구현을 위한 기본 구성 요소 가운데 하나다. ETL 툴은 다양한 원천 데이터를 취함해 데이터를 추출하고 하나의 공통된 포맷으로 변환해 데이터 웨어하우스(DW)나 데이터 마트(DM) 등에 적재하는 과정을 지원하는 툴을 의미한다.
크롤링(Crawling) 혹은 스크레이핑(Scrapping)은 웹페이지를 그대로 가져와서 데이터를 추출해내는 행위이다. 크롤링하는 소프트웨어는 크롤러(Crawler)라고 부른다
의사 코드(Psuedocode)는 특정 프로그래밍 언어의 문법에 따라 쓴 것이 아니라, 일반적인 언어로 코드를 흉내내어 알고리즘을 써 놓은 코드를 말ㄴ한다. 특정 언어로 프로그램을 작성하기 전에 알고리즘의 모델을 대략적으로 모델링하는데 쓰인다.
빅데이터 분석 방법론에 대한 설명으로 옳지 않은 것은
1. 시스템 구현단계에서는 정보보안은 중요한 문제가 아니다.
2. 모델링 태스크에서는 모델의 과적합과 일반화를 위하여 데이터를 분할 한다.
3. 단순한 데이터 분석이나 데이터 마이닝을 통한 분석 보고서를 분석 보고서를 작성하는 것으로 프로젝트가 종료되는 경우에는 시스템 구현 단계를 수행할 필요가 없다.
4. 프로젝트 위험계획 수립에 대응으로 회피, 전이, 완화, 수용이 있다.
03 분석 과제 발굴
분석 과제는 풀어야 할 다양한 문제를 데이터 분석 문제로 변환한 후 이해관계자들이 이해하고 프로젝트로 수행할 수 있는 과제 정의서 형태로 도출한다.
분석 과제를 도출하기 위한 방식은 크게 하향식 접근 방법(Top Down Approach)과 상향식 접근 방법(Bottom Up Approach)가 있다.
하향식 접근 방법(Top Down Approach)
문제가 주어지고 이에 대한 해답을 찾기 위하여 각 과정이 체계적으로 단계화되어 수행하는 방식
상향식 접근 방법(Bottom Up Approach)
문제의 정의 자체가 어려울 경우 데이터를 기반으로 문제의 재정의 및 해결방안을 탐색하고 이를 지속적으로 개선하는 방식 데이터를 활용하여 생각하지 못했던 인사이트를 도출하고 시행착오를 통해서 개선해 가는 상향식 접근 방식의 유용성이 점차 증가하고 있는 추세
분석 과제 발굴을 두 가지 방법으로 나누었지만, 실제 새로운 상품을 개발하거나 전략수립 등 중요한 의사결정을 할 때에는 상향식 접근 방법과 하향식 접근 방법이 혼용이 되어 사용되며, 동적인 환경에서 분석의 가치를 높일 수 있는 최적의 의사결정을 위해서는 두 가지 접근방식이 상호보완 관계있을 때 가능하다.
상향식 접근 방법과 하향식 접근 방식의 혼용
디자인 씽킹(Design Thinking)이란 시작 단계에서 대상을 자세히 관찰하고 그 상황이나 대상에 공감함으로써 많은 가능성과 아이디어를 생각한다. 그 이후 많은 아이디어를 내고 그것을 다시 필터링하고 이 과정을 반복함으로써 최선의 결과를 얻는다.
디자인 씽킹은 사용자들과 공감하는 것에서 시작해 아이디어를 발산하고 곧 수렴하는 과정을 거쳐 많은 프로토타이핑과 피드백을 통해 발전하는 과정이다.
디자인 씽킹 프로세스는 결국 상향식 접근 방식의 발산 단계(Diverse)와 도출된 옵션을 분석하고 검증하는 하향식 접근 방식의 수렴 단계(Converse)를 반복적으로 수행하는 상호 보완 접근 방식이라 할 수 있다.
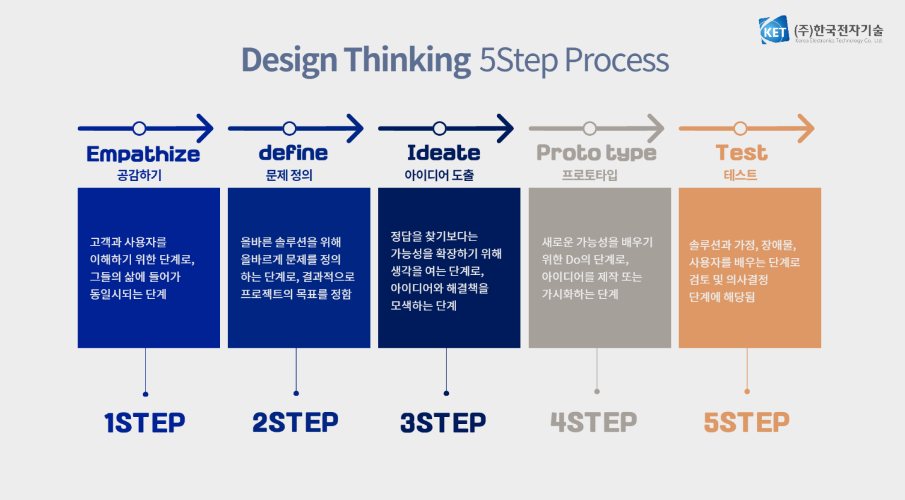
디자인 씽킹 프로세스 5단계
Empathize : 사용자 인터뷰 등을 통해 고객의 문제에 공감하는 단계
Define : 첫 번째 얻는 통찰을 바탕으로 고객의 진짜 문제를 정의하는 과정
ex. pain point 발굴
Ideate : 현실 가능성을 고려하지 않고 자유롭게 고객에게 적합한 해결 방안을 제시
ex. pain point 개선 중심
Prototype : 새로운 아이디어를 프로토타입으로 만들어 보거나 서비스에 대한 시나리오를 만들어 보는 단계
Test : 1차적으로 완성된 프로토타입에 대한 고객의 피드백을 바탕으로 프로토타입을 개선해 보는 단계
1. 하향식 접근 방식(Top Down Approach)
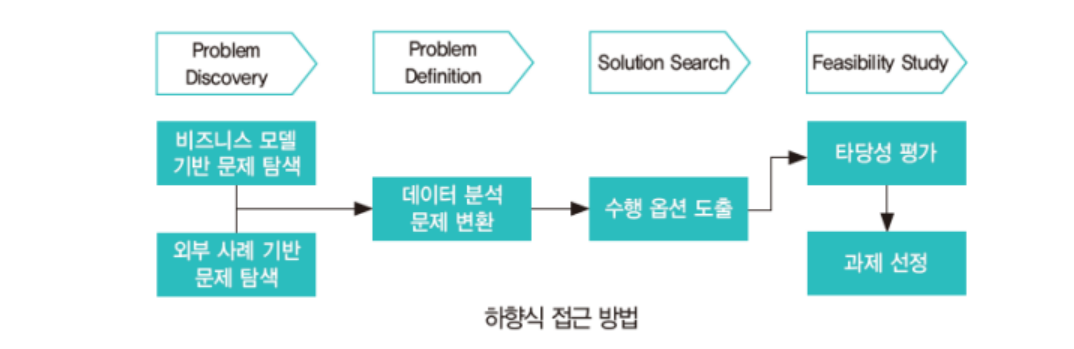
현황 분석 또는 인식된 문제점, 전략으로부터 기화나 문제를 탐색(Problem Discovery), 해당 문제를 데이터 문제로 정의(Problem Definition)한 후 해결방안 탐색(Solution Search) 그리고 데이터 분석의 타당성 평가(Feasibility Study)를 거쳐 분석 과제를 도출하는 과정으로 이루어진다.
플랫폼 비즈니스 모델
채스브로(Chesbrough, 2003)와 쿠스마노와 가우어(Cusumano & Gawer, 2002)는 플랫폼 비즈니스 모델을 "플랫폼이 가치 창출과 이익실현의 중심인 비즈니스 모델"이라고 했고, 히라노 아쓰시 말은 "복수그룹의 요구를 중개함으로써 그룹간 상호작용을 환기시키고 그 시장의 경제권을 만드는 산업 기반형 비즈니스 모델"이라고 했다.
1) 문제 탐색(Problem Discovery) 단계
(1) 비즈니스 모델 기반 문제 탐색
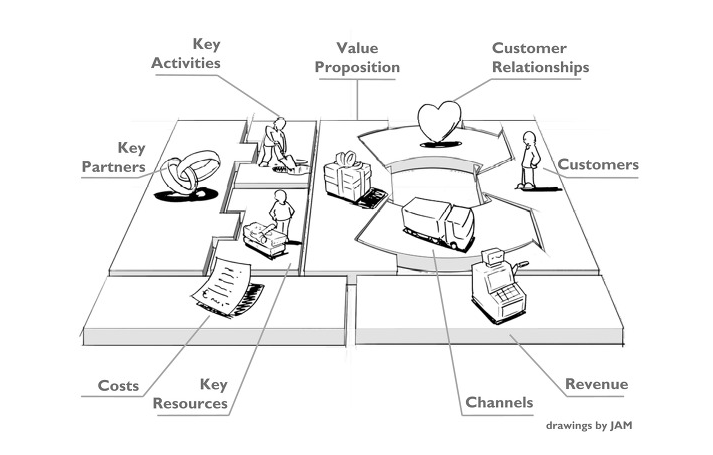
비즈니스 모델 틀을 활용하여 가치가 창출될 문제를 누락 없이 도출할 수 있다.
비즈니스 모델 관점에서 해당 기업의 사업 모델을 도식화한 비즈니스 모델 캔버스의 9가지 블록을 단순화하여 업무, 제품, 고객 단위로 문제를 발굴하고, 이를 관리하는 두 가지의 영역인 규제와 감사 영역과 지원 인프라 영역에 대한 기회를 추가로 도출하는 작업을 수행한다.
업무(Operation) :
제품 및 서비스를 생산하기 위해서 운영하는 내부 프로세스 및 주요 자원 관련 주제 도출
ex. 생산공정 최적화, 재고량 최소화
제품(Product) : 생산 및 제공하는 제품/서비스를 개선하기 위한 관련 주제 도출
ex. 제품의 주요 기능 개선
고객(Customer) : 제품/서비스르 제공받는 사용자 및 고객, 이를 제공하는 채널의 관점에서 관련 주제 도출
ex. 고객 전화 대기 시간 최소화
규제와 감사(Regularization and Audit) : 제품 생산 및 전달 과정 프로세스 중에서 발생하는 규제 및 보완의 관점에서 도출
ex. 제공 서비스 품질의 이상 징후 관리, 새로운 환경 규제 시 예상되는 제품 추출등
지원인프라(IT & Human Resouce) : 분석을 수행하는 시스템 영역 및 이를 운영/관리하는 인력의 관점에서 주제 도출
ex. EDW 최적화, 적정 운영 인력 도출 등
(2) 분석 기회 발굴의 범위 확장
현재의 사업 방식 및 비즈니스에 대한 문제 해결은 최적화 및 단기 과제 형식으로 도출될 가능성이 높기 때문에 새로운 문제의 발굴 및 장기적인 접근을 위해서는 기업이 현재 수행하고 있는 비즈니스 뿐만 아니라 환경과 경쟁 구도의 변화 및 역량의 재해석을 통한 혁신(Innovation)의 관점에서 분석 기회를 추가 도출하는 것이 요구된다.
현재 사업을 영위하고 있는 환경, 경쟁자, 보유하고 있는 역량, 제공하고 있는 시장 등을 넘어서 거시적 관점의 요인, 경쟁자의 동향, 시장의 니즈 변화, 역량의 재해석 등 새로운 관점의 접근을 통해 새로운 유형의 분석 기회 및 주제 발굴을 수행해야 한다.
이러한 작업을 수행할 때는 분석가 뿐만 아니라 해당 기능을 수행하는 직원 및 관련자에 대한 폭넓은 인터뷰와 워크숍 형태의 아이디어 발굴 작업이 필요하다.
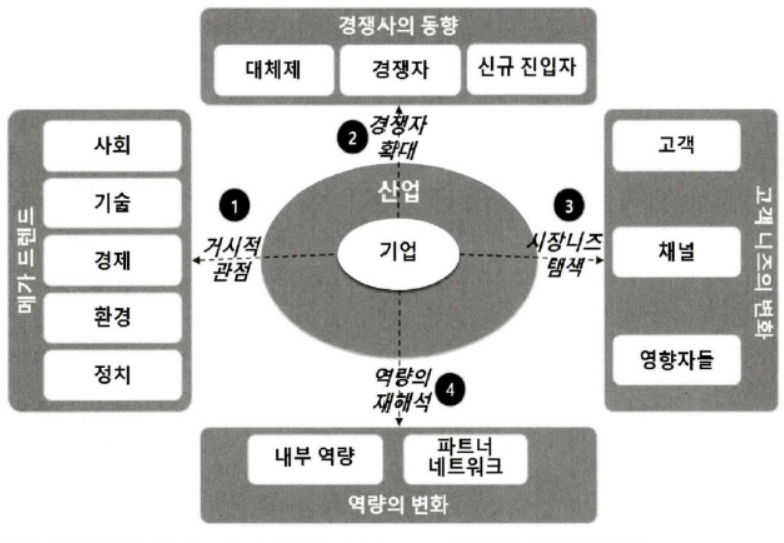
거시적 관심의 요인
STEEP로 요약되는 사회(Social), 기술(Technological), 경제(Economy), 환경(Environmental), 정치(Political) 영역으로 나누어서 좀 더 폭넓게 기획 탐색을 수행한다.
사회(Social)
비즈니스 모델의 고객 영역에 존재하는 현재 고객을 확장하여 전체 시장을 대상으로 사회적, 문화적, 구조적 트렌드 변화에 기반한 분석 기회 도출
노령화, 밀레니엄 세대 등장
기술(Technological)
과학, 기술, 의약 등 최신 기술의 등장 및 변화에 따른 역량 내재화와 제품, 서비스 개발에 대한 분석 기회 도출
나노기술, IT 융합 기술
경제(Economic)
산업과 금융 전망늬 변동성 및 경제 구조 변화 동향에 따른 시장의 흐름을 파악하고 이에 대한 분석 기회 도출
원자재 가격, 환율
환경(Environmental)
환경과 관련된 정부, 사회단체, 시민사회의 관심과 규제 동향을 파악하고 이에 대한 분석 기회 도출
원가절감 및 정보 가시화
정치(Political)
주요 정책 방향, 정세, 지정학적 동향 등의 거시적인 흐름을 토대로 한 분석 기회 도출
원자재 구매, 거래선 다변화
경쟁자 확대 관점
사업 영역의 직접 경쟁사 영역 및 제품 서비스의 대체재 영역과 신규진입자 영역 등으로 관점을 확대하여 위협이 될 수 있는 상황에 대한 분석 기회 발굴의 폭을 넓혀서 탐색한다.
대체제(Substitute)
융합적인 경쟁 환경에서 현재 생산을 수행하고 있는 제품/서비스의 대체제를 파악하고 이를 고려한 분석 기회 도출
현재 오프라인으로 제공하고 있는 자사의 상품 서비스를 온라인으로 제공하는 것에 대한 탐색 및 잠재적 위협 파악
경쟁자(Competitior)
현재 생산하고 있는 제품 서비스의 주용 경쟁사에 대한 동향을 파악하고 이를 고려한 분석 기회 도출
식별된 주요 경쟁사의 제품 서비스카탈로그 및 전략을 분석하고 이에 대한 잠재적 위협 파악
신규진입자(Customer)
현재 직접적인 제품 서비스의 경쟁자는 아니지만, 향후 시장에 대하여 파과적인 역할을 수행할 수 있는 신규진입자에 대한 동향을 파악하고 이를 고려한 분석 기회 도출
새로운 제품에 대한 클라우드 소식 서비스인 kickstarter의 주요 제품을 분석하고 자사의 제품에 대한 잠재적 위협 파악
다음 중 경쟁자확대 관점의 영역이 아닌 것은
1. 대체재 영역
2. 경쟁자 영역
3. 신규진입자 영역
4. 채널 영역
시장의 니즈 탐색
고객 영역과 고객과 접촉하는 역할을 수행하는 채널 영역 및 고객의 구매와 의사결정에 영향을 미치는 영향자를 영역에 대한 관점을 바탕으로 분석 기회를 탐색한다.
고객(Customer)
고객의 구매 동향 및 요구를 더욱 깊게 이해하여 제품 서비스의 개선 필요에 필요한 분석 기회 도출
철강 기업의 경우 조선 산업과 자동차 산업의 동향 및 주요 거래선의 경영 현황 등을 파악하고 분석 기회 도출
채널(Channel)
영업사원, 직판 대리점, 홈페이지 등 자체적으로 운영하는 채널 뿐만 아니라 최종 고객에게 상품 서비스를 전달하는 가능한 경로를 파악하여 해당 경로에 존재하는 채널별로 부석 기회를 확대하여 탐색
은행의 경우 인터넷전문 은행 등 온라인 채널의 등장에 따른 변화에 대한 전략분석 기획 도출
영향자들(Influence)
기업 의사결정에 영향을 미치는 주주 투자자 협회 및 기타 이해관계자의 주요 관점 사항에 대해서 파악하고 분석 기회 탐색
M&A 시장 확대에 따른 유사 업종의 신규 기업 인수 기회 탐색
역량의 재해석 관점
내부 역량 영역뿐만 아니라 해당 조직의 비즈니스에 영향을 미치는 파트너 네트워크 영역을 포함한 활용 가능한 역량을 토대로 폭넓은 분석 기회를 탐색한다.
내부역량(Competency)
지적 재산권, 기술력 등 기본적인 것뿐만 아니라 중요하면서도 자칙 간과하기 쉬운 지식, 기술, 스킬 등의 노하우와 인프라적인 유형 자산에 대해서 폭넓게 재해석하고 해당 영역에서 분석 기회를 탐색한다.
자사 소유 부동산을 활용한 부가가치 창출 기회 발굴 등
파트너와 네트워크(Partners & Networks)
자사가 직접 보유하고 있지 않지만 밀접한 관계를 유지하고 있는 관계사와 공급사 등의 역량을 활용해 수행할 수 있는 기능을 파악해보고 이에 대한 분석 기회를 추가적으로 도출
수출입 통관 노하우를 활용한 추가 사업 기회 탐색
(3) 외부 참조 모델 기반 문제 탐색
유사 동종 사례 벤치마킹을 통한 분석 기회 발굴은 제공되는 산업별 업무 서비스별 분석 테마 후보 그룹을 통해 "Qucik & Easy" 방식으로 필요한 분석 기회가 무엇인지에 대한 아이디어를 얻고 기업에 적용할 분석 테마 후보 목록을 워크숍 셩태의 브레인스토밍읕 통해 빠르게 도출하는 방법이다.
특히 현재 환경에서는 데이터를 활용하지 않은 업종 및 업무 서비스가 사실상 존재하지 않기 때문에 업무에 활용되는 사례들을 발굴하여 자사의 업종 및 업무 서비스에 적용할 수 있다.
산업 및 업종을 불문하고 데이터 분석 사례를 기반으로 분석 테마 후보 그룹을 미리 정의하고 그 후보 그룹을 통해 해당 기업에서 벤치마킹할 대상인 분석 기회를 고려한다면 빠르고 쉽게 분석 기회를 도출할 수 있다.
(4) 분석 유즈 케이스(Anaylytics Use Case)
현재의 비즈니스 모델 및 유사 동종 사례 탐색을 통해서 빠짐없이 도출한 분석 기회들을 구체적인 과제로 만들기에 앞서 분석 유즈 케이스로 표기하는 것이 필요하다.
분석 유즈 케이스는 풀어야 할 문제에 대한 상세한 설명 및 해당 문제를 해결했을 때 발생하는 효과를 명시함으로써 향후 데이터 분석 문제로의 전환 및 적합성 평가에 활용한다.
재무
자금 시재 예측
일별로 예정된 자금 지출과 입금을 추정
지금 과부족 현상 예방, 지금 운용 효율화
구매 최적화
구매 유형과 구매자별로 과거 실적과 구매 조건을 비교,분석하여 구매 방안 도출
구매 비용 절감
2) 문제 정의(Problem Solving)
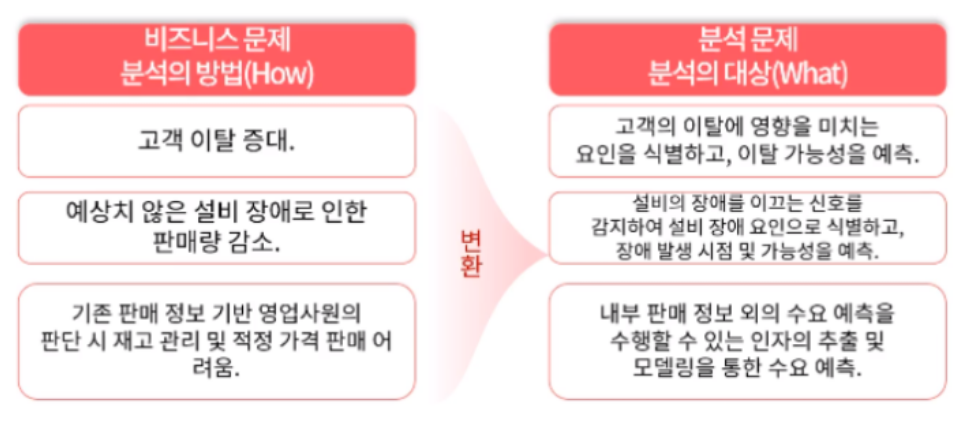
식별된 비즈니스 문제를 데이터의 문제로 변환하여 정의하는 단계이다. 필요한 데이터 및 기법을 정의하기 위한 데이터 분석의 문제로의 변환을 수행하게 된다.
앞서 수행한 문제 탐색의 단계가 무엇을(What) 어떤 목적으로(Why) 수행해야 하는 지에 대한 관점이었다면 문제 정의(Problem Definition) 단계에서는 이를 달성하기 위해서 데이터 및 기법(How)을 정의하기 위한 데이터 분석의 문제로의 변환을 수행하게 된다.
데이터 분석 문제의 정의 및 요구 사항은 분석을 수행하는 당사자뿐만 아니라 해당 문제가 해결되었을 때 효용을 얻을 수 있는 최종 사용자(End User) 관점에서 이루어져야 한다.
데이터 분석 문제가 잘 정의되었을 때 필요한 데이터의 정의 및 기법 발굴이 용이하기 때문에 가능한 정확하게 분석의 관점으로 문제를 재정의할 필요가 있다.
ex.
'고객 이탈의 증대'라는 비즈니스 문제는 '고객의 이탈에 영향을 미치는 요인을 식별하고 이탈 가능성을 예측'하는 데이터 분석 문제로 전환
3) 해결 방안 탐색(Solution Search) 단계
이 단계에서는 정의된 데이터 분석 문제를 해결하기 위한 다양한 방안이 모색된다.
동일한 데이터 분석 문제라 해도 어떤 데이터 또는 분석 시스템을 사용할 것인지에 따라서 소요되는 예산 및 활용 가능한 도구가 다르기 때문에 다각도로 고려할 필요가 있다.
기존 정보 시스템의 단순한 보완으로 분석이 가능한지, 엑셀 등의 간단한 도구로 분석이 가능한지, 또는 하둡 등 분산병렬처리를 활용한 빅데이터 분석 도구를 통해 보다 체계적으로 심도 있는 방안이 고려되는지 등등 여러 대안이 도출될 수 있다.
분석 역량을 기존에 가지고 있는지 파악하여 보유하고 있지 않는 경우에는 교육이나 전문 인력 채용을 통한 역량을 확보하거나 분석 전문 업체를 활용하여 과제를 해결하는 방안에 대해 사건 검토를 수행한다.
4) 타당성 검토(Feasibility Study) 단계
경제적 타당도
비용대비 편익 분석 관점이 필요하다. 비용 항목은 데이터, 시스템, 인력, 유지보수 등과 같은 분석 비용으로 구성된다.
비용편익분석 결과를 적용함으로써 추정되는 실질적 비용 절감 추가적 매출과 같은 경제적 가치로 산출된다.
데이터 및 기술적 타당도
데이터 분석에는 데이터 존재 여부, 분석 시스템 환경, 그리고 분석역량이 필요하다
특히 분석 역량의 경우 실제 프로젝트 수행 시 걸림돌이 되는 경우가 많기 때문에 기술적 타당성 분석 시 역량 확보 방안을 사전에 수립해야 한다.
이를 효과적으로 평가하기 위해서는 비즈니늣 지식과 기술적 지식이 요구되기 때문에 비즈니스 분석가, 데이터 분석가, 시스템 엔지니어 등과의 협업이 수반되어야 한다.
2. 상향식 접근 방식(Bottom Up Approach)
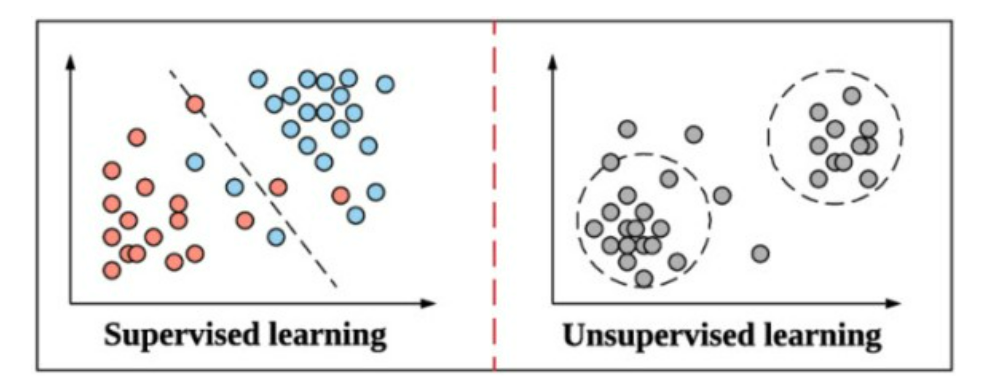
문제의 정의 자체가 어려운 경우 데이터를 기반으로 문제의 재정의 및 해결 방안을 탐색하고 이를 지속적으로 개선하는 방식이며, 일반적으로 상향식 접근 방식의 데이터 분석은 비지도 학습(Unsupervised Learning) 방법에 의해 수행된다.
통계적 분석에서는 인과관계(원인과 결과) 분석을 위해 가설을 설정하고 이를 검정하기 위해 모집단으로 표본을 추출하고, 그 표본을 이용한 가설검정을 실시하는 방식으로 문제를 해결한다.
그러나 빅데이터 환경에서는 이와 같은 논리적인 인과관계 분석뿐만 아니라 상관관계 분석 또는 연관분석을 통하여 다양항 문제 해결에 도움을 받을 수 있다. 즉 인과관계로부터 상관관계 분석으로의 이동이 빅데이터 분석에서의 주요 변화라고 할 수 있다.
상향식 접근 방법은 결국 다양한 원천 데이터로부터 분석을 통하여 통찰력과 지식을 얻는 접근방법을 말한다.
1) 기존 하향식 접근법의 한계를 극복하기 위한 방법론
- 접근 방법인 논리적 단계별 접근법은 문제의 구조가 분명하고 문제를 해결하고 해결책을 도출하기 위한 데이터 분석가 및 의사결정자가 존재하고 있음을 가정하기 때문에 솔루션 도출에는 유효하지만 새로운 문제 탐색에는 한계가 있다.
따라서 기존의 논리적인 단계별 접근법에 기반한 문제해결 방식은 최근 복잡하고 다양한 환경에서 발생하는 문제에는 적합하지 않을 수 있다.
이를 해결하기 위한 방법으로 스탠포드 대학의 디스쿨(d.school)은 디자인 씽킹(Design Thinking) 접근법을 통해서 전통적인 분석적 사고를 극복하려고 하였다.
디자인 씽킹은 답을 미리 내는 것이 아니라 사물을 있는 그대로 인식하는 'What' 관점에서 보아야 한다는 것이다.
객관적으로 존재하는 데이터 그 자체를 관찰하고 실제적으로 행동을 옮김으로써 대상을 좀 더 잘 이해하는 방식으로의 접근을 의미한다. 이와 같은 점을 고려하여 d.school에서는 디자인씽킹 프로세스의 첫 단계인 감정이입(Empathize)을 특히 강조하고 있다.
2) 지도학습과 비지도학습
(1) 지도학습(Supervised Learning)
-
명확한 목적 하에 데이터 분석을 실시한 것을 지도학습이라고 하며 분류, 추출, 예측, 최적화를 통해 사용자의 주도하에 분석을 실시하고 지식을 도출하는 것이 목적이다.
-
지도 학습의 경우 결과로 도출하는 값에 대해서 사전에 인지하고 어떠한 데이터를 넣었을 때 어떠한 결과가 나올 지를 예측하는 것이라면 비지도학습의 경우 목표값을 사전에 정의하지 않고 데이터 자체만을 가지고 도출함으로써 해석이 용이하지 않지만 새로운 유형의 인사이트를 도출하기에 유용한 방식으로 활용할 수 있다.
-
빅데이터 환경에서는 논리적인 인과관계 분석뿐만 아니라 상관관계 또는 연관분석을 통하여 다양한 문제에 도움을 받을 수 있다. 즉 인과관계(Know-Why)로부터 상관관계(Know-Affinity) 분석으로의 이동이 빅데이터 분석에서의 주요 변화라고 할 수 있다.
-
다량의 데이터 분석을 통해서 "왜" 그러한 일이 발생했는지 역으로 추적하면서 문제를 도출하거나 재정의 할 수 있는 것이 상향식 접근 방법이다.
(2) 비지도학습(UnSupervised Learning)
- 일반적으로 상향식 접근방식의 데이터 분석은 비지도 학습에 의해 수행된다.
- 비지도학습은 데이터 분석의 목적이 명확히 정의된 형태의 특정 필드 값을 구하는 것이 아니라 데이터 자체의 결합, 연관성, 유사성 등을 중심으로 데이터의 상태를 표현하는 것이다.
- 데이터 마이닝 기법을 예로 들면 장바구니 분석, 군집 분석, 기술 통계 및 프로파일링 등이 이에 속한다.
(3) 빅데이터 분석 환경에서의 프로토타이핑 필요성
1. 문제에 대한 인식 수준
문제 정의가 불명확하거나 이전에 접해보지 못한 새로운 문제일 경우 사용자 및 이해관계자는 프로토타입을 이용하여 문제를 이해하고 이를 바탕으로 구체화하는데 도움을 받을 수 있다.
2. 필요데이터 존재 여부의 불확실성
문제 해결을 위해 필요한 데이터의 집합이 모두 존재하지 않을 경우 그 데이터의 수집을 어떻게 할 것인지 또는 그 데이터를 다른 데이터로 대체할 것인지 등에 대한 데이터 사용자와 분석가 간의 반복적이고 순환적인 협의 과정이 필요하다.
대체 불가능한 데이터가 존재하는지 사전에 확인한다면 불가능한 프로젝트를 수행하는 리스크를 사전에 방지할 수 있다.
3. 데이터의 사용 목적의 가변성
데이터 가치는 사전에 정해닞 수집목적에 따라 확정되는 것이 아니고 그 가치를 지속적으로 변화할 수 있다.
조직에서 보유 중인 데이터라 하더라도 기존의 데이터 정의를 재검토하여 데이터의 사용 목적과 범위를 확대할 수 있을 것이다.
예를 들면 이동 통신사에서 수집하는 사용자의 위치 추적은 사용자의 호출을 효율적으로 처리하기 위한 원래의 목적으로부터 사용자들이 특정 시간에 많이 모이는 장소가 어디인지를 분석하는 정보를 활용이 가능하다.
다음 중 프로토타이핑에 관한 설명으로 옳은 것은
1. 신속하게 해결책 모형 제시, 상향식 접근 방법에 활용한다
2. 빠른 결과보다 모델의 정확성에 중점을 둔 기법이다.
3. 워터폴 방식처럼 전체적인 플랜을 짜고 문서를 통해 개발한다.
4. 대표적인 하향식 접근 방식이라고 할 수 있다.
- 분석 과제 정의
분석 과제 정의서는 향후 프로젝트 수행 계획의 입력물로 사용되기 때문에 수행하는 이해관계자가 프로젝트의 방향을 설정하고 성공 여부를 판별할 수 있는 주요한 자료를 명확하게 작성해야 한다.
분석 과제 정의서를 통해 분석별로 필요한 소스 데이터, 분석 방법, 데이터 인수 및 분석의 난이도, 분석 수행 주기, 분석 결과에 대한 검증 오너쉽, 상세 분석 과정 등을 정의한다.
분석 데이터 소스는 내/외부의 비구조적인 데이터와 소셜 미디어 및 오픈 데이터까지 범위를 확장하여 고려하고 분석방법 또한 상세하게 작성한다.
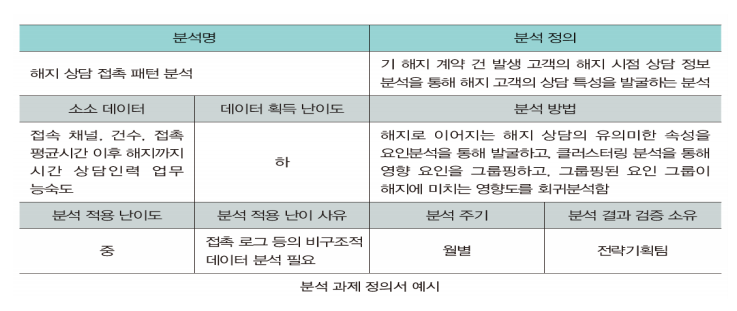
다음 중 분석 과제 정의서에 대한 설명 중 옳지 않는 것은
1. 분석 과제 정의서는 소스 데이터, 데이터 입수 및 분석 난이도, 분석 방법 등에 대한 항목이 포함되어야 한다.
2. 분석 과제 정의서는 프로젝트를 수행하는 이해관계자가 프로젝트의 방향을 설정하고 성공 여부를 판별할 수 있는 자료이다.
3. 분석 과제 정의서는 프로젝트 계획서를 작성하기 위한 중간 결과로써 구성 항목으로 도출할 필요가 없다.
4. 분석 과제 정의서는 분석 모델에 적용될 알고리즘과 분석 모델의 기반이 되는 Feature가 포함될 필요는 없다
04 분석 프로젝트 관리 방안
과제 형태로 도출된 분석 기회 프로젝트를 통해서 그 가치를 증명하고 목표를 달성해야 한다.
분석 프로젝트는 다른 프로젝트 유형처럼 범위, 일정, 품질, 리스크, 의사소통 등 영역별 관리가 수행되어야 하며 다양한 데이터에 기반한 분석 기법을 적용하는 특성 때문에 아래 표와 같이 5가지 속성을 고려하여 추가적인 관리가 필요하다
Data size
분석하고자 하는 데이터의 양을 고려한 관리방안 수립이 필요하다. 하둡 환경에서 엄청난 데이터양을 기반으로 분석하는 것과 기존 정형 데이터베이스에 있는 시간당 생성되는 데이터를 분석할 때의 관리방식은 차이가 날 수밖에 없다.
Data Complexity
BI 프로젝트처럼 정형 데이터가 분석 마트로 구성되어 있는 상태에서 분석하는 것과 달리 텍스트, 오디오, 비디오 등의 비정형 데이터 및 다양한 시스템에 산재되어 있는 원천 데이터들을 통합해서 분석 프로젝트를 진행할 때는 초기 데이터의 확보와 통합 외에도 해당 데이터에 잘 적용될 수 있는 분석모델의 선정 등에 대한 사전 고려가 필요하다.
Speed
분석 결과가 도출되었을 때 이를 활용하는 시나리오 측면에서의 속도를 고려해야 한다. 일 단위, 주 단위 성적의 경우에는 배치(Batch) 형태로 작업이 되어도 무방하지만, 실시간으로 사기(Fraud)를 탐지하거나, 고객에게 개인화된 상품, 서비스를 추천하는 경우에는 분석 모델의 적용 및 계산이 실시간으로 수행되어야 하기 때문에 프로젝트 수행 시 분석모델의 성능 및 속도를 고려한 개발 및 테스트가 수행되어야 한다.
Analytic Complexity
분석 모델의 정확도와 복잡도는 트레이드 오프(Trade Off) 관계가 존재한다. 분석 모델이 복잡할수록 정확도는 올라가지반 해석이 어려워지는 단점이 존재하므로 이에 대한 기준점을 사전에 정의해 두어야 한다.
Accuracy & Precision
Accuracy는 모델과 실제 값 사이의 차이가 적다는 정확도를 의미하고, Precision은 모델을 지속적으로 반복했을 때의 편차의 수준으로서 일관적으로 동일한 결과를 제시한다는 것을 의미한다. 분석의 활용적인 측면에서는 Accuaracy가 중요하며, 안정적인 측면에서는 Precision이 중요하다. 그러나 Accuracy와 Precision은 트레이드오프가 되는 경우가 많기 때문에 모델의 해석 및 적용 시 사전에 고려해야 한다.
1. 분석 프로젝트의 특징
분석가의 목표는 분석의 정확도를 높이는 것이지만 프로젝트의 관점에서는 도출된 분석 과제를 잘 구현하여 원하는 결과를 얻고 사용자가 원활하게 활용할 수 있도록 전체적인 과정을 고려해야 하기 때문에 개별적인 분석 업무 수행 뿐만 아니라 전반적인 프로젝트 관리 또한 중요한 일이다.
분석 프로젝트에서는 데이터의 영역과 비즈니스 영역의 현황을 이해하고 프로젝트의 목표인 분석의 정확도 달성과 결과에 대한 가치 이해를 전달하는 조정자로써 분석가의 역할이 중요하다.
조정자로써 분석가 해당 프로젝트의 관리자까지 겸임하게 되는 경우가 대부분이므로 프로젝트 관리 방안에 대한 이해와 주요 관리포인트를 사전에 숙지하는 것이 필수적이다.
분석 프로젝트는 도출된 결과의 재해석을 통한 지속적인 반복 및 정교화가 수행되는 경우가 대부분이므로 프로토타이핑 방식의 애자일(Agile) 모델에 대한 고려도 필요하다.
데이터 분석의 지속적인 반복 및 개선을 통하여 의도했던 결과에 더욱 가까워지는 형태로 프로젝트가 진행될 수 있도록 적절한 관리 방안 수립이 사전에 필요하다.
지속적인 반복이 요구되는 분석 프로세스의 특성을 이해한 프로젝트 관리 방안을 수립하는 것이 중요하다.
분석 과제 정의서를 기반으로 프로젝트를 시작하되 지속적인 개선 및 변경을 염두에 두고 기간 내에 가능한 최선의 결과를 도출할 수 있도록 프로젝트 구성원들과 협업하는 것이 분석 프로젝트의 특징이다.
애자일(Agile) 모델이란 전체적인 플랜을 짜고 문서를 통해 주도해 나가던 과거의 방식(워터풀 모델)과 달리 앞을 예측하며 개발하지 않고 일정한 주기를 가지고 끊임없이 프로토타입을 만들어내며 필요할 때마다 요구 사항을 더하고 수정하여 커다란 소프트웨어를 개발해 나가는 방식이다.
2. 분석 프로젝트 관리 방안
분석 프로젝트는 데이터 분석의 특성을 살려 프로젝트 관리 지침(KS A ISO21500 : 2013)을 기본 가이드로 활용하게 된다.
프로젝트 관리 지침의 프로젝트 관리 체계는 통합, 이해관계자, 자원, 시간, 원가, 리스크, 품질, 조달, 의사소통의 10개 주제 그룹으로 구성되어 있다.
특히 분석 프로젝트의 경우에는 각각의 관리 영역에서 일반 프로젝트와 다르게 좀 더 유의해야 할 요소가 존재한다.
각 영역에서 분석 프로젝트가 가지게 되는 특성과 고려해야 할 주요과리 항목은 아래표와 같다.
분석 프로젝트 영역별 주요 관리 항목
범위(Scope)
분석 기획 단계의 프로젝트 단위가 분석을 진행하면서 데이터의 형태와 양 또는 적용되는 모델의 알고리즘에 따라 범위가 빈번하게 변경된다.
분석의 최종결과물이 분석 보고서 형태인지 시스템인지에 따라서 투입되는 자원 및 범위가 크게 변경되므로 사전에 충분한 고려가 필요함
시간(Time)
데이터 분석 프로젝트는 초기에 의도했던 결과(모델)가 나오지 쉽지 않기 때문에 지속적으로 반복되어 많은 시간이 소요될 수 있다
분석 결과에 대한 품질이 보장된다는 전제로 타임박싱(Time Boxing) 기법으로 일정 관리를 진행하는 것이 필요하다
원가(Cost)
외부 데이터를 활용한 데이터 분석인 경우 고가의 비용이 소요될 수 있으므로 사전에 충분한 조사가 필요함
오픈 소스 도구 외에 프로젝트 수행 시 의도했던 결과를 달성하기 위하여 상용버전의 도구가 필요할 수 있음
품질(Quality)
분석 프로젝트를 수행한 결과에 대한 품질 목표를 사전에 수립하여 확정해야 함
프로젝트 품질을 품질통제와 품질보증으로 나누어 수행되어야 한다
통합(Integration)
프로젝트 관리 프로세스들이 통합적으로 운영될 수 있도록 관리한다
조달(Procurement)
프로젝트 관리 프로세스들이 통합적으로 운영될 수 있도록 관리한다
Poc(Proof of Concept) 형태의 프로젝트는 인프라 구매가 아닌 클라우드 등의 다양한 방안을 검토할 필요가 있다.
자원(Resource)
고급 분석 및 빅데이터가 아키텍처링을 수행할 수 있는 인력의 공급이 부족하므로 프로젝트 수행 전 전문가 확보 검토 필요
리스크(Risk)
분석에 필요한 데이터 미확보로 분석 프로젝트 진행이 어려울 수 있어 관련 위험을 식별하고 대응방안을 사전에 수립해야 한다
데이터 및 분석 알고리즘의 한계로 품질목표를 달성하기 어려울 수 있어 대응방안을 수립할 필요가 있다.
의사소통(Communication)
전문성이 요구되는 데이터 분석의 결과를 모든 프로젝트 이해관계자가 공유할 수 있도록 해야 한다.
프로젝트의 원활한 진행을 위한 다양한 의사소통체계가 마련 필요
이해관계자(Stakeholder)
데이터 분석 프로젝트는 데이터 전문가 비즈니스 전문가, 분석 전문가 시스템 전만가 등 다양한 전문가가 참여하므로 이해관계자의 식별과 관리가 필요하다.
데이터 분석 프로젝트 실행과정의 관리 사항으로 적절하지 않은 것은
1. 분석 과제는 분석 전문가의 상상력을 요구하므로 일정을 제한하는 일정 계획은 적절하지 못하다.
2. 분석 과제는 많은 위험이 있어 사전에 위험을 식별하고 대응 방안을 수립해야 한다.
3. 분석 과제는 적용되는 알고리즘에 따라 범위가 변할 수 있어 범위 관리가 중요하다.
4. 프로젝트 관리 프로세스들이 통합적으로 운영될 수 있도록 관리를 해야 한다.
5장 분석 마스터플랜
01 분석 마스터플랜 수립
분석을 수행하기 위한 요구사항을 과제 단위로 도출하고 이를 관리하기 위한 분석과제 발굴 및 분석 프로젝트 관리방안을 살펴보았다.
분석과제를 잘 수행하는 것도 중요하지만 지속적으로 분석이 주는 가치를 체계적으로 관리하고 분석역량을 내재화하려고 하면 단기적인 과제 수행뿐만 아니라 중/장기적 관점의 마스터플랜 수립이 필요하다.
분석 마스터플랜은 분석 대상이 되는 과제를 도출하고 우선순위를 평가하며 단기적인 세부 이행 계획과 중/장기적인 로드맵을 작성해야 한다.
분석 로드맵 상의 과제들이 잘 수행되도록 하기 위해서는 분석 거버넌스 체계 수립이 필수적이며, 분석 역량을 높이기 위하여 현재 분석 수준이 어떤지를 살펴보는 분석 성숙도 측정이 필요하다.
마지막 분석 거버넌스의 체계의 구성 요소인 인프라, 데이터, 조직 및 인력, 관리 프로세스 교육 및 변화관리에 대한 방안도 수립해야 한다.
1. 분석 마스터플랜 수립 프레임워크
중/장기적 관점의 마스터플랜 수립을 위해서는 분석 과제를 대상으로 전략적 중요도 비즈니스 성과 및 ROI(투자회수율) 분석 과제의 실행 용이성 등 다양한 기준을 고려해 적용할 우선 순위를 설정할 필요가 있다.
분석을 업무에 내재화할 것인지, 별도의 분석 화면ㅇ으로 일단 적용할 것인지, 분석 데이터를 내부의 데이터로 한정할 것인지, 외부의 데이터까지 포함할 것인지, 분석 기술은 어느 기술 요소까지 적용할 것인지 등 분석의 적용 범위 및 방식에 대해서도 종합적으로 고려하여 데이터 분석을 실행하기 위한 로드맵을 수립한다.
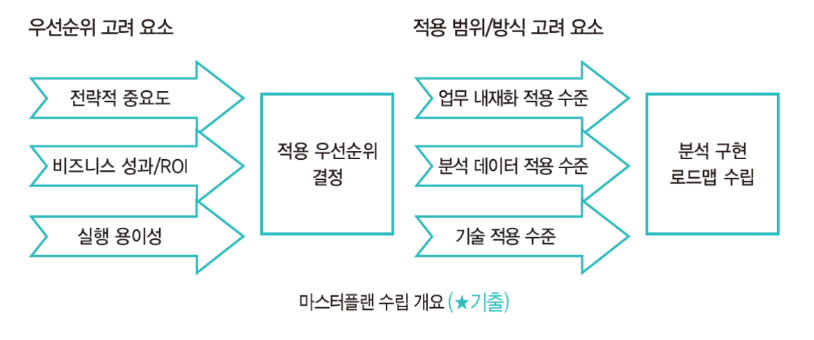
분석 마스터 플랜은 일반적인 ISP(정보전략계획) 방법론을 활용하되 데이터 분석 기획의 특성을 고려하여 수행하고 기업에서 필요한 데이터 분석 과제를 빠짐없이 도출한 후 과제의 우선순위를 결정하고 단기 및 중/장기로 나누어 계획을 수립한다.
정보전략계획(ISP, Information Strategy Planning)은 기업의 경영 목표 달성에 필요한 전략적 주요 정보를 포착하고 주요 정보를 지원하기 위한 전사적 관점의 정보 구조를 도출하며, 이를 수행하기 위한 전략 및 실행 계획을 수립하는 전사적인 종합정보 추진 계획이다.
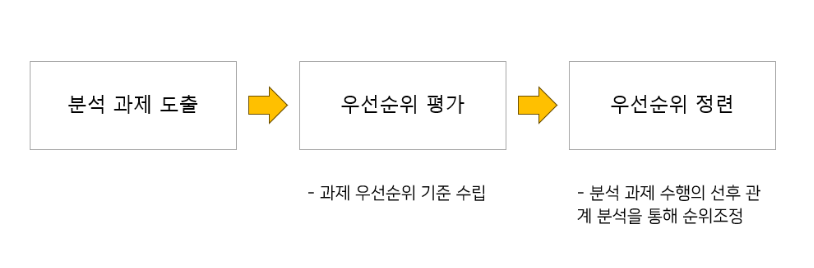
2. 수행 과제 도출 및 우선순위 평가
우선순위 평가는 정의된 데이터 과제에 대한 실행 순서를 정하는 것으로 업무 영역별로 도출된 분석 과제를 우선순위 평가 기준에 따라 평가하고 과제 수행의 선/후행 관계를 고려하여 적용 순위를 조정해 최종 확정한다.
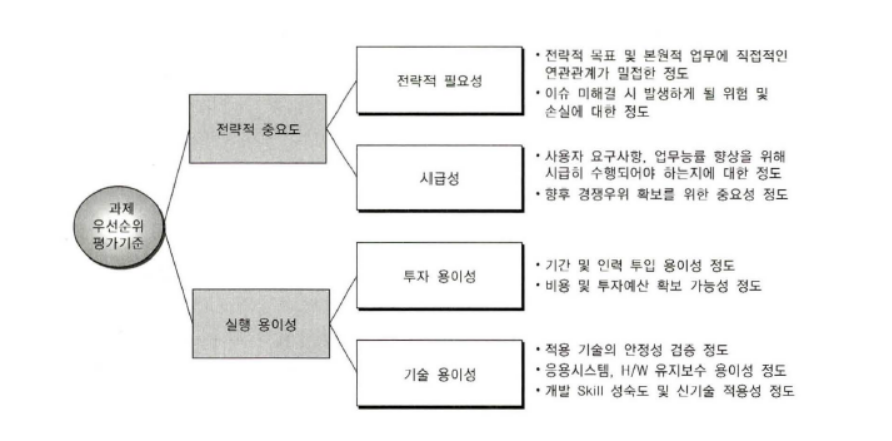
1) 일반적인 IT 프로젝트의 우선순위 평가
ISP와 같은 일반적인 IT 프로젝트는 과제의 우선순위 평가를 위해 전략적 중요도, 실행 용이성 등 기업에서 고려하는 중요 가치 기준에 따라 다양한 관점에서의 우선 순위 기준을 수립하여 평가한다.
데이터 분석 과제의 우선순위 평가 기준은 그 기업이 당면한 상황에 따라 다르고 기존의 IT 프로젝트의 우선순위 평가 기준과도 다른 관점에서 살펴볼 필요가 있다.
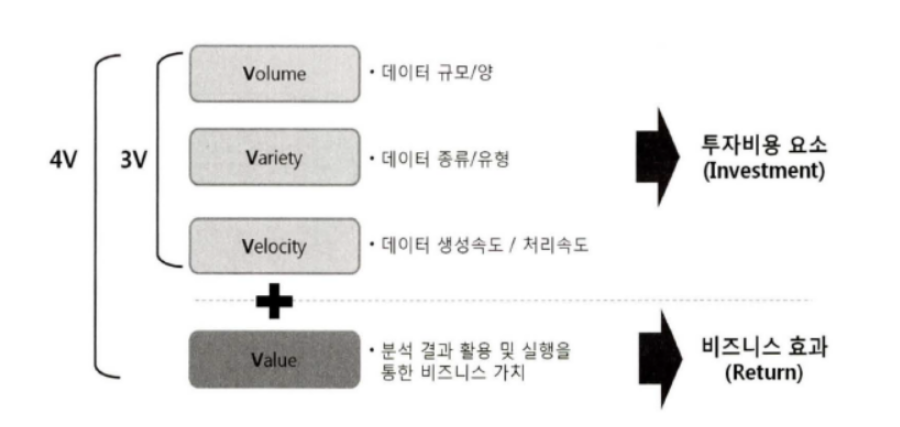
2) ROI(Return On Investment, 투자자본수익률) 관점에서 보는 4V
빅데이터를 4V를 ROI 관점으로 보면 Volume, Variety, Velocity 등 3V 투자비용(Investment), Value는 비즈니스 효과 요소라고 볼 수 있다.
이는 기업이 데이터 분석을 통해 추구하거나 달성하고자 하는 목표 가치라고 정의할 수 있다.
ROI는 누적 순효과/총비용 만약 어떤 프로젝트의 누적된 총 순이익이 총비용의 1배라면, ROI는 100%라고 표현할 수 있는 것이다. IT-ROI이란 IT 투자 비용 대비 IT 투자성과를 도출하는 것으로 IT 투자 성과는 IT가 비즈니스 성과 향상에 기여하는 바를 재무적으로 환산한 것을 의미한다.
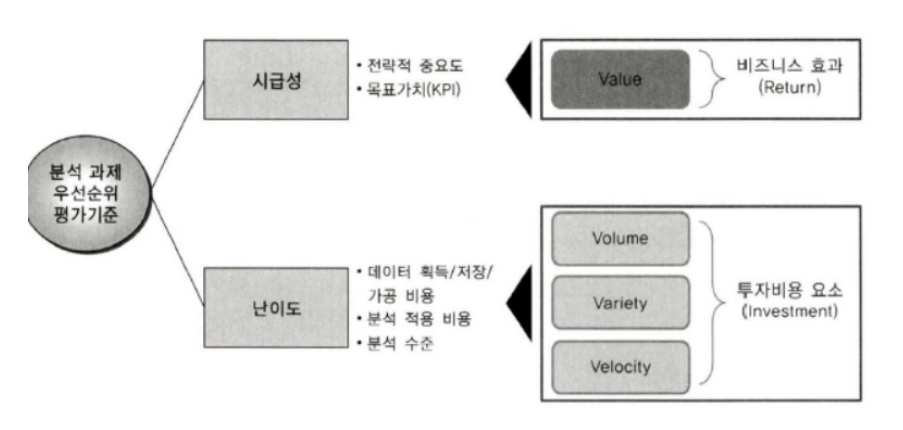
3) ROI 관점에서의 분석 과제 우선순위 평가 기준
시급성
- 판단 기준은 전략적 중요도가 핵심이며, 이는 전략적 중요도가 시점에 시점에 따라 시급성 여부를 고려할 수 있다는 띃이다.
- ex. 현재는 미래보다 시급성이 높다.
난이도
- 현시점에서 과제를 추진하는 것이 비용과 범위 측면을 고려했을 때 바로 적용하기 쉬운 것인지 또는 어려운 것인지를 판단하는 것이다.
- 과제의 범위를 시범과제(Pilot 또는 PoC) 형태로 일부 수행할 것이지, 아니면 처음부터 크게 수행할 것인지, 또 데이터 소스는 기업 내부의 데이터로부터 우선 활용하고 외부 데이터까지 확대해 나갈 것인지에 대한 난이도를 고려해볼 수 있다.
- 난이도는 해당 기업의 현 상황에 따라 조율할 수 있다. '분석 거버넌스 체계 수립'에서 제시하는 분석 준비도 및 성숙도 진단 결과에 따라 해당 기업의 분석 수준을 파악하고 이를 바탕으로 분석 적용 범위 및 방법에 따라 난이도를 조정할 수 있다.
4) 포트폴리오 사분면 분석을 통한 과제 우선순위를 선정하는 기법
우선순위 기준을 난이도와 시급성을 고려하여 우선 추진해야 하는 분석 과제와 제한된 자원을 고려하여 단기적 또는 중장기적으로 추진해야 하는 분석 과제 등을 4가지 유형으로 구분하여 분석 과제 우선순위를 결정한다.
분석 과제의 적용 우선순위를 '시급성'에 둔다면 3 -> 4 -> 2 영역 순이며, 난이도를 기준으로 둔다면 3 -> 1 -> 2 영역 순으로 의사결정을 할 수 있다.
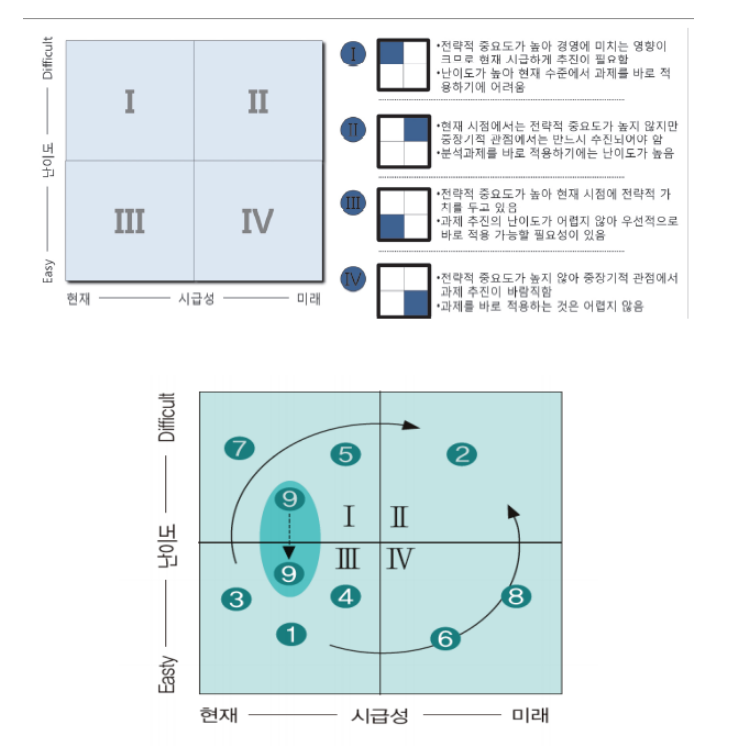
1 사분면 : 전략적 중요도가 높아 경영에 미치는 영향이 크므로 현재 시급하게 추진이 필요하다. 난이도가 높아 현재 수준에서 과제를 바로 적용하기에는 어렵다
2 사분면 : 현재 시점에서는 전략적 중요도가 높지 않지만 중장기적 관점에서는 만드시 추진되어야 한다. 분석 과제를 바로 적용하기에는 난이도가 높다.
3 사분면 : 전략적 중요도가 높아 현재 시점에 전략적 가치를 두고 있다. 과제 추진의 난이도가 어렵지 않아 우선적으로 바로 적용 가능한 필요성이 있다.
4 사분명 : 전략적 중요가 높지 않아 중/장기적 관점에서 과제 추진이 바람직하다. 과제를 바로 적용하는 것은 어렵지 않다.
5) 분석 과제 우선순위 조정
- 데이터 양, 데이터 특성, 분석 범위 등에 따라 난이도 조정은 경영진 또는 실무 담당자의 의사결정에 따라 적용 우선순위를 조정할 수 있다. 예를 들어 위의 그림에서 9번 과제와 같이 1사분면에 위치한 분석과제는 데이터의 양, 데이터의 특성, 분석 범위 등에 따라 난이도를 조율함으로써 적용 우선순위를 조정할 수 있다.
- 기술적 요소에 따라서도 적용 우선순위를 조정할 수 있다. 기본적으로 대용량 데이터 분석은 데이터 저장/처리/분석을 위한 새로운 기술 요소들로 인하여 운영 중인 시스템에 영향을 미친다. 이때 기존 시스템에 미치는 영향을 최소화하여 적용하거나 또는 운영 중인 시스템과 별도 분리하여 시행함으로써 난이도 조율을 통해 우선순위를 조정할 수 있다.
- 분석 범위에 따라서 적용/우선순위를 조정할 수 있다. 분석 과제의 전체 범위를 한 번에 일괄적으로 적용하여 추진할 것인지, 일부 범위를 한정하여 시범 과제 형태로 추진하고 평가를 통하여 분석 범위를 확대할 것인지에 대한 의사결정이 필요하다.
다음 중 ROI 요소를 고려하여 분석 과제에 대한 우선순위 평가 기준에 대한 설명 중 적절하지 않는 것은
1. 전략적 중요도에 따른 시급성이 가장 중요한 기준이다.
2. 데이터를 생성, 저장, 가공, 분석하는 비용과 현재 기업의 분석 수준을 고려한 난이도 역시 적용 우선순위를 선정하는데 중요한 기준이 될 수 있다.
3. 난이도는 해당 기업의 현 상황에 따라 조율할 수 없다.
4. 난이도는 현 시점에서 과제를 추진하는 것이 비용측면과 범위측면에서 바로 적용하기 쉬운 것인지 또는 어려운 것인지에 대한 판단 기준이다.
3. 이행 계획 수립
1) 로드맵 수립
분석 과제에 대한 포트폴리오 사분면 분석을 통해 결정된 과제의 우선순위를 토대로 분석 과제별 적용 범위 및 방식을 고려하여 최종적인 실행 우선순위를 결정한 후 단계적 구현 로드맵을 수립한다.
2) 세부 이행계획 수립
데이터 분석 체계는 고전적인 폭포수(Waterfall) 방식도 있으나 반복적인 정련 과정을 통하여 프로젝트의 완성도를 높이는 방식을 주로 사용한다. 이러한 반복적인 분석 체계는 모든 단계를 반복하기보다 데이터 수집 및 확보와 분석 데이터를 준비하는 단계를 순차적으로 진행하고, 모델링 단계는 반복적으로 수행하는 혼합형을 많이 적용한다. 이러한 특성을 고려하여 세부적인 일정계획도 수립해야 한다.
02 분석 거버넌스 체계 수립
1. 거버넌스 체계 개요
거버넌스(Governance)는 정보라는 의미의 Government와 같은 어원을 가지고 있는 단어인데, Government보다는 더 폭넓은 의미로 진화하여 기업, 비영리 기관 등에서 규칙, 규범 및 행동이 구조화되고, 유지되고, 규제되고 책임을 지는 방식 및 프로세스를 지칭한다.분석 거버넌스는 기업에서 데이터가 어떻게 관리되고 유지되고 규제되는지에 대한 내부적인 관리 방식이나 프로세스를 의미한다데이터 거버넌스는 데이터의 품질 보장, 프라이버시 보호, 데이터 수명 관리, 전담 조직과 규정 정립, 데이터 소유권과 권리권 명확화 등을 통하여 데이터가 적시에 필요한 사람에게 제공되도록 체계를 확립하는 것이다. 데이터 거버넌스가 확립되지 못하면 개인 프라이버시 관련 데이터로 인해 '빅 브라더'의 우려가 현실화될 가능성이 높다.
빅브라더는 정보의 독점으로 사회를 통제하려는 관리 권력 혹은 그러한 사회체계를 일컫는 말로, 사회학적 통찰과 풍자로 유명한 영국의 소설가 조지 오웰의 소설 <1984>에서 비롯된 용어이다.
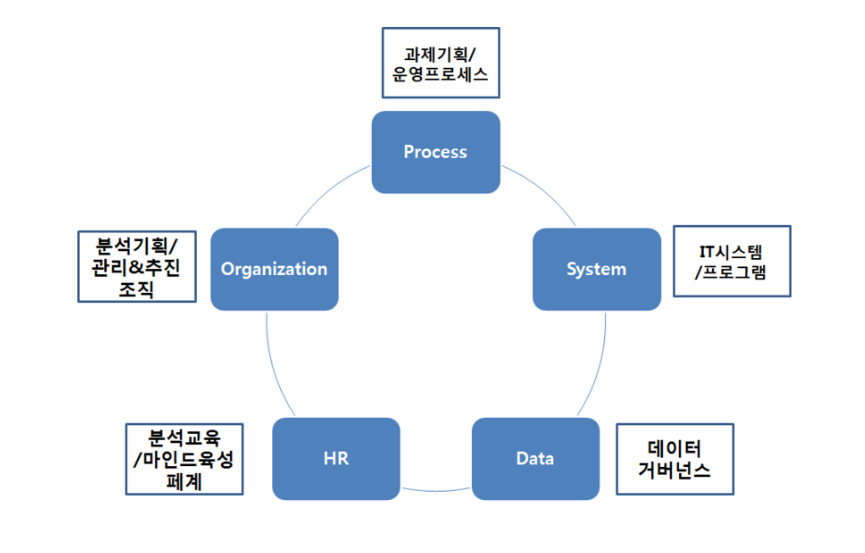
1) 분석 거버넌스 체계 구성요소
마스터플랜 수립 시점에서 데이터 분석의 지속적인 적용과 확산을 위한 거버넌스 체계는 분석 기획 및 관리를 수행하는 조직(Organization), 과제 기획 및 운영 프로세스(Process), 분석 관련 시스템(System), 데이터(Data), 분석 관련 교육 및 마인드 육성 체계(Human Resource)로 구성된다.
2. 데이터 분석 성숙도 모델 및 수준 진단
- 많은 기업에서 빅데이터는 화두가 되고 있으며 데이터를 어떻게 분석 활용하느냐가 기업의 경쟁력을 좌우하는 궁극적 요소로 인식되고 있다.
- 한 관점에서 기업들은 데이터 분석의 도움 여부의 활용에 대한 명확한 분석 수준을 점검할 필요가 있다.
- 터 분석 수준 진단을 통해 데이터 분석 기반을 구현하기 위해 무엇을 준비하고 보완해야 하는지 등 분석의 유형 및 분석의 방향성을 결정할 수 있다.
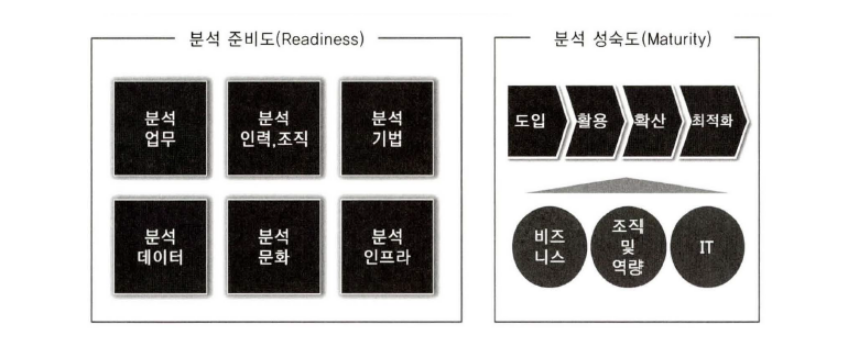
- 아래 그림의 데이터 분석 수준을 분석 수준 진단 프레임워크와 같이 6개 영역에서의 분석 준비도와 3개 영역에서의 분석 성숙도를 함께 평가함으로써 수행될 수 있다.
1) 분석 준비도
- 분석을 위한 준비도 및 성숙도를 진단하는 궁극적인 목표는 각 기업이 수행하는 현재의 분석 수준을 명확히 이해하고, 분석 수준 진단 결과를 토대로 미래의 목표 수준을 정의하는데 있다.
- 데이터를 활용한 분석의 경쟁력 확보를 위해 어떠한 영역에 선택과 집중을 해야 하는지, 어떤 관점을 보완해야 하는지 등 개선 방안을 도출할 수 있다.
2) 데이터 분석 준비도 프레임워크
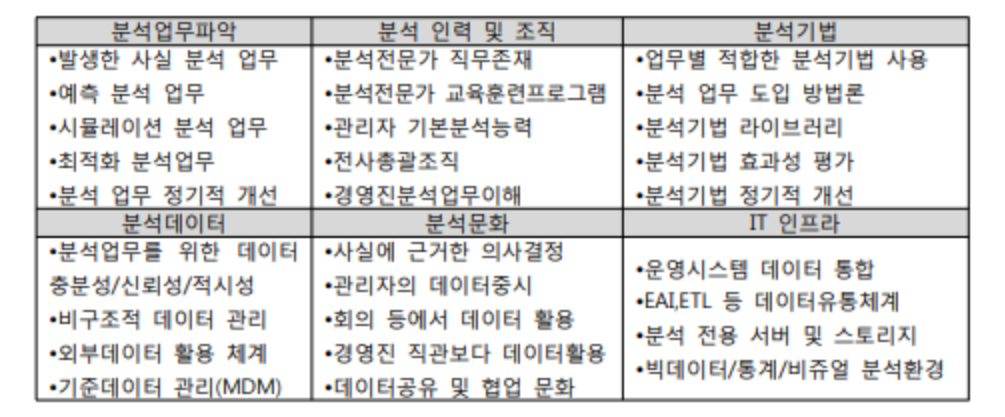
- 분석 준비도(Readliness)는 기업의 데이터 분석 도입의 수준을 파악하기 위한 진단 방법으로 아래 그림과 같이 분석 업무, 인력 및 조직, 분석 기법, 분석 데이터, 분석 문화, IT 인프라 등 총 6가지 영역을 대상으로 현 수준을 파악한다.
- 진단 영역별로 세부 항목에 대한 수준을 파악하고 진단 결과 전체 요건 중 일정 수준 이상 충족하면 분석 업무를 도입하고, 충족하지 못하면 먼저 분석 환경을 조정한다.
능력 성숙도 통합 모델(Capability Maturity Model Integration, CMMI)은 소프트웨어 개발 및 전산 장비 운영 업체들의 업무 능력 및 조직의 성숙도를 평가하가 위한 모델을 말한다.
CMMI는 기존 능력 성숙도 모델(CMM)을 발전시키는 것으로서 기존의 소프트웨어 품질보증 기분으로 사용되던 SW-CKMM과 시스템 엔지니어링 분야의 품질 보증 기준으로 사용되던 SE-CMM을 통합하여 개발한 후속 평가 모델이다.
CMMI는 1~5단계까지 있으며, 5단계가 가장 높은 수준이다. CMMI는 소프트웨어 개발 및 전산 장비 운영 분야의 품질 관련 국제 공인 기준으로 사용되고 있다.
3) 분석 성숙도 모델
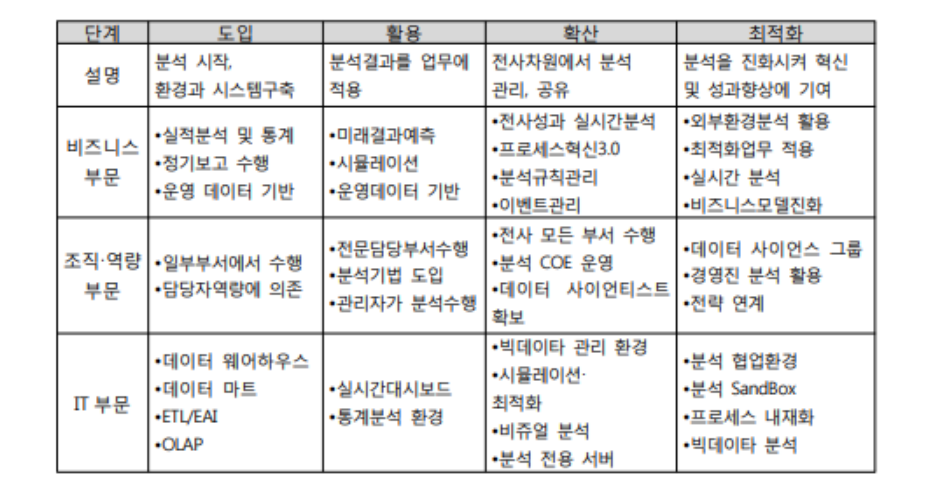
- 분석 성숙도 진단을 비즈니스 부문, 조직 역량 부문, IT 부문 등 3개의 부문을 대상으로 성숙도 수준에 따라 도입 단계, 활용 단계, 확신 단계, 최적화 단계로 구분해 살펴볼 수 있다.
- 소프트웨어공학에서는 시스템 개발 업무 능력과 성숙도(Maturity)를 파악하기 위해 CMMI(Capability Maturity Model Integration) 모델을 기반으로 조직의 성숙도를 평가한다.
- 업무 프로세스 자체의 성숙도와 이러한 업무 프로세스 관리와 개선을 위한 조직의 역량을 CMMI에 기반한 업무 프로세스 성숙도 모형으로 평가한다.
- 분석 성숙도 진단은 비즈니스 부문, 조직/역량 부문, IT 부문 등 3개 부문을 대상으로 성숙도 수준에 따라 도입 단계, 활용 단계, 확산 단계, 최적화 단계로 구분해 살펴볼 수 있다.
샌드박스(Sandbox)란 데이터 과학자 및 심층 분석가들이 사용할 수 있도록 설계된 영역이다. 모든 사용자가 데이터를 추가할 수 있으며, 거버넌스 프로세스가 반드시 필요하지는 않는다.
CoF(Center of Excellence)는 조직 내 새로운 역량을 만들고 확산하기 위한 전문가들의 조합으로 구성된 조직으로 분석 업무를 전사적으로 총괄하는 조직이다.
분석 준비도는 기업의 데이터 분석 도입 수준을 파악하기 위한 진단 방법으로 총 6가지 영역에 대상으로 현수준을 의미한다. 다음 중 분석 업무 파악 영역에 해당하지 않는 것은?
1. 발생한 사실 분석 업무
2. 예측 분석 업무
3. 최적화 분석 업무
4. 통계 분석 업무
4) 분석 수준 진단 결과
아래 그림 사분면 분석 같이 분석 관점에서 4가지 유형으로 분석 수준 진단 결과를 구분하여 향후 고려해야 하는 데이터 분석 수준에 대한 목표 방향을 정의하고, 유형별 특성에 따라 재선 방안을 수립할 수 있다.
해당 기업의 분석 준비도와 성숙도 진단 결과를 토대로 기업의 현재 분석 수준을 객관적으로 파악할 수 있다.
이를 토대로 유관 업종 또는 경쟁사의 분석 수준과 비교하여 분석 경쟁력 확보 및 경화를 목표 수준을 설정할 수 있다.
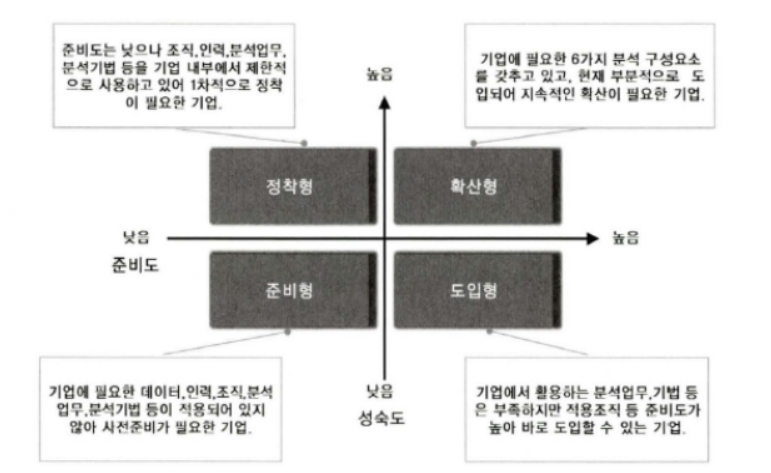
(1) 분석 관점에서 4가지 유형
준비형
데이터 분석을 위한 낮은 준비도와 낮은 성숙도 수준에 있는 기업들이다. 해당 위치의 기업들을 분석을 위한 데이터, 조직 및 인력, 분석 업무(분석 기법)등이 적용되지 않음으로 인해 사전 준비가 필요한 유형이라고 할 수 있다.
정착형
준비도는 낮은 편이지만 조직, 인력, 분석 업무, 분석 기법 등을 기업 내부에서 제한적으로 사용하고 있다. 우선적으로 분석의 정착이 필요한 기업이 이 유형에 속한다.
도입형
기업에서 활용하는 분석 업무 및 분석 기법 등은 부족한 상태이지만, 조직 및 인력 등 준비도가 높은 유형으로 바로 데이터 분석을 바로 도입할 수 있는 기업이 여기에 속한다.
확산형
데이터 분석을 위해 기 업에 필요한 6가지 분석 구성 요소를 모두 갖추고 있으며 현재 부분적으로 도입해 지속적인 확산이 가능한 기업이 이 유형에 속한다.
3. 분석 지원 인프라 방안 수립
- 분석 과제 단위별로 별도의 분석 시스템을 구축하는 경우, 관리의 복잡도 및 비용의 증대라는 부작용이 나타나게 한다. 따라서 분석 마스터플랜을 기획하는 단계에서 부터 장기적이고 안정적으로 활용할 수 있는 확장성을 고려한 플랫폼 구조를 도입하는 것이 적절하다.
- 플랫폼이란 단순한 분석 응용프로그램 뿐만 아니라 분석 서비스를 위한 응용 프로그램이 실행될 수 있는 기초를 이루는 컴퓨터 시스템을 의미하며 일반적으로 하두웨어에 탑재되어 데이터 분석에 필요한 프로그래밍 환경과 실행 및 서비스 환경을 제공하는 역할을 수행한다.
- 이러한 분석 플랫폼이 구성되어 있는 경우에는 새로운 데이터 분석 니즈가 존재할 경우 개별적인 분석시스템을 추가하는 방식이 아닌 서비스를 추가적으로 제공하는 방식으로 확정성을 높일 수 있다.
4. 데이터 거버넌스 체계 수립
빅데이터는 데이터의 크기로 그 의미의 절대성을 갖는 것은 아니다. 그러나 실시간으로 쏟아지는 비정형/반정형의 데이터는 조직이나 프로젝트 단위의 데이터 관리 체계로는 솔루션이 될 수 었고, 전사 차원의 체계적인 데이터 거버넌스의 필요성이 부각된다.
데이터 거버넌스란 전사 차원의 모든 데이터에 대하여 정책 및 지침, 표준화, 운영 조직 및 책임 등의 표준화된 관리 체계를 수립하고 운영을 위한 프레임워크 및 저장소를 구축하는 것을 말한다. 특히 마스터 데이터, 메타 데이터, 데이터 사전을 데이터 거버넌스의 중요한 관리 대상이다.
기업은 데이터 거버넌스 체계를 구축함으로써 데이터의 가용성, 유용성, 통합성, 보안성, 안전성을 확보할 수 있으며, 이는 빅데이터 프로젝트를 성공으로 이끄는 기반이 된다.
데이터 거버넌스는 독자적으로 수행될 수도 있지만 전사차원의 IT 거버넌스나 EA(Enterprise Architecture)의 구성요소로 구축되는 경우도 있다.
빅데이터 거버넌스와 데이터 거버넌스의 차이점
빅데이터 거버넌스는 이러한 데이터 거버넌스의 체계에 더하여 빅데이터의 효율적인 관리 다양한 데이터의 관리체계 데이터 최적화, 정보보호, 데이터 생명주기 관리, 데이터 카테고리 관리 책임자(Data Stewrard)지정등을 포함한다.
1) 데이터 거버넌스 구성 요소
데이터 거버넌스의 구성 요소인 원칙(Principal), 조직(Organization), 프로세스(Process)는 유기적인 조합을 통하여 데이터를 비즈니스 목적에 부합하고 최적의 정보 서비스를 제공할 수 있도록 효과적으로 관리한다.
원칙
데이터를 유지/관리하기 위한 지침과 기여도
보안, 품질, 기준, 변경 관리
조직
데이터를 관리할 조직의 역할과 책임
데이터 관리자, 데이터베이스 관리자 데이터 아키텍트(Data Architect)
프로세스
데이터 관리를 위한 활동과 체계
작업 절차, 모니터링 활동, 측정 활동
마스터 데이터(Master Data)
자주 변하지 않고 자료 처리 운용에 기본 자료로 제공되는 자료의 집합, 마스터 파일의 내용을 뜻하기도 한다. 예를 들ㅇ면, 인사 데이터에서 이름, 생년월일, 급여, 주소, 혈액형 등이 포함될 수 있다.
데이터 사전(Data Dictionary)
데이터에 관한 정보를 수집/보관/제공하기 위한 장치, 데이터 사전은 데이터 자원관리의 중요한 요소의 하나로, 자료의 이름, 표현 방식, 자료의 의미와 사용 방식, 다른 자료와의 관계를 저장한다.
2) 데이터 거버넌스 체계 요소
데이터 표준화
데이터 표준화는 데이터 표준 용어 설명, 명명 규칙(Name Rule), 메타데이터 구축, 데이터 사전 구축 등의 업무로 구성된다.
데이터 표준 용어는 표준 단어 사전, 표준 도메인사전, 표준코드 등으로 구성되며 사전 간 상호검증이 가능하도록 점검 프로세스를 포함해야 한다.
명명 규칙은 필요 시 언어별(한글, 영어 등 외국어)로 작성되어 매핑 상태를 유지해야 한다.
메타 데이터 사전은 데이터의 데이터 구조 체계(Data Structure Architecture)나 메타 엔티티 관계 다이어그램을 제공한다.
데이터 관리 체계
데이터 정합성 및 활용의 효율성을 위하여 표준 데이터를 포함한 메타 데이터와 데이터 사전의 관리 원칙을 수립한다.
수립된 원칙에 근거하여 항목별 상세한 프로세스를 만들고 관리와 운영을 위한 담당자 및 조직별 역할과 책임을 상세하게 준비한다.
빅데이터의 경우 데이터의 양의 급증으로 데이터의 생명 주기 관리 방안(Data Life Management)을 수립하지 않으며 데이터 가용성 및 관리 비용 증대 문제에 직면하게 될 수 있다.
데이터 저장소 관리
메타데이터 및 표준 데이터를 관리하기 위한 전사 차원의 저장소를 구성한다.
저장소는 데이터 관리 체계 지원을 위한 워크플로우 및 관리용 응용 소프트웨어를 지원하고 관리 대상 시스템과의 인터페이스를 통한 통제가 이루어져야 한다.
데이터 구조 변경에 따른 사전영향평가도 수행되어야 효율적인 활용이 가능하다.
표준화 활동
데이터 거버넌스의 체계를 구축한 후 표준 준수 여부를 주기적으로 점검하고 모니터링을 실시한다.
거버넌스의 조직 내 안정적 정착을 위한 계속적인 변화관리 및 주기적인 교육을 진행한다.
지속적인 데이터 표준화 개선 활동을 통하여 실용성을 높여야 한다.
메타 제이터와 데이터 사전의 관리 원칙을 수립하고, 빅데이터의 경우 데이터 생명 주기 관리 방안의 수립에 해당되는 데이터 거버넌스 체계를 무엇이라고 하는가
1. 데이터 표준화
2. 데이터 관리 체계
3. 데이터 저장소 관리
4. 표준화 활동
5. 데이터 조직 및 인력 방안 수립
- 빅데이터의 등장에 따라 기업의 비즈니스도 많은 변화를 겪고 있다. 이러한 비즈니스 변화를 인식하고 차별된 경쟁력을 확보하는 수단으로 데이터 과제 발굴, 기술 검토 및 전사 업무 적용 계획 수립 등 데이터를 효과적으로 분석 활용하기 위해 기획 및 운영을 관리할 수 있는 전문 분석조직의 필요성이 제기되고 있다.
- 이를 위해 다양한 분야의 지식과 경험을 가진 인력과 업무 담당자 등으로 구성된 전사 또는 부서 내 조직으로 구성할 수 있다. 특히 분석 업무 수행 주체에 따라 그림과 같이 세 가지 유형의 조직 구조로 살펴볼 수 있다.
1) 분석 조직의 개요
아래 그림은 분석 조직의 목표와 역할, 조직 구성을 설명하고 있다. 데이터 분석 조직은 기업의 경쟁력 확보를 위해 데이터 분석 가치를 발견하고, 이를 활용하여 비즈니스를 최적화하는 목표를 갖고 구성되어야 한다.
이를 위해 기업의 업무 전반에 걸쳐 다양한 분석 과제를 발굴해 정의하고, 데이터 분석을 통해 의미있는 인사이트를 찾아 실행하는 역할을 수행할 수 있어야 한다.
다양한 분야의 지식과 경험을 가진 인력과 업무 담당자 등으로 구성된 전사 또는 부서 내 조직으로 구성될 수 있다.

2) 분석 조직 및 인력 구성 시 고려사항
분석 전문조직은 아래 표와 같이 조직구조 및 인력 구성을 고려해 기업에 최적화된 형태로 구성해야 한다.
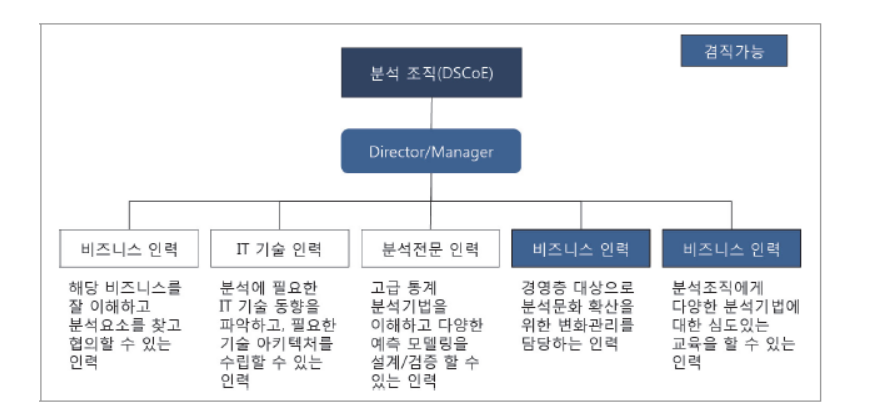
3) 분석 업무 수행 주체에 따른 3가지 유형
데이터 분석을 위한 조직 구조는 다양한 형태로 살펴볼 수 있는데 특히 분석 업무 수행 주체에 따라 다음과 같이 3가지 유형의 조직 구조로 살펴볼 수 있다.
데이터 분석을 위한 다양한 형태의 분석 조직을 구성하여 운영할 수 있지만, 어떠한 조직 구조가 적합한 형태라고 단정 지을 수 없다.
따라서 각 기업이 처한 환경과 특성을 고려하여 적절한 분석조직을 구성해야 한다.
분석조직이 갖추어져 있다 하더라도 조직 구성원의 분석 역량을 하루아침에 성장하는 것도 아니고 한 사람이 데이터 분석과 관련된 모든 역량을 다 갖추기는 현실적으로 어렵다.
따라서 전문 역량을 갖춘 각 분야의 인재들을 모아 조직을 구성하는 것이 바람직하다
집중형 조직 구조
조직 내에 별도의 독립적인 분석 전담조직을 구성하고 회사의 모든 분석 업무를 전담조직에서 담당한다.
분석 전담조직 내부에서 전사 분석과제의 전략적 중요도에 따라 우선순위를 정하여 추진할 수 있다.
일부 협업 부서와 분석 업무 중복 또는 이원화될 가능성이 있다.
기능 중심형 조직구조
일반적으로 분석을 수행하는 셩태이며, 별도의 분석 조직을 구성하지 않고 각 해당 업무부서에서 직접 분석하는 형태이다.
특징으로 전사적 관점에서 핵심 분석이 어려우며, 특정 업무 부서에 국한된 분석을 수행할 가능성이 높거나 일부 중복된 분석 업무를 수행할 수 있는 조직구조다.
분산형 조직 구조
분석 조직의 인력들을 협업부서에 배치해 분석 업무를 수행하는 형태다
전사 차원에서 분석 과제의 우선순위를 선정해 수행이 가능하며, 분석 결과를 신속하게 실무에 적용할 수 있는 장점이 있다
다음 중 집중형 구조의 특징으로 가장 부적절한 것은
1. 전담 분석 업무를 별도 독립된 분석 전담 조직에서 담당한다.
2. 분석 결과에 대한 신속한 실행이 가능하다.
3. 전략적 중요도에 따라 분석 조직이 우선순위를 정하여 추진할 수 있다.
4. 현업 업무부서의 분석 업무와 이중화 또는 이원화될 가능성이 높다
6. 분석 과제 관리 프로세스 수립
- 분석 마스터 플랜이 수립되고 초기 데이터 분석 과제가 성공적으로 수행되는 경우, 지속적인 분석 니즈 및 기회가 분석 과제 형태로 도출될 수 있고, 이런 과정에서 분석 조직이 수행할 주요한 역할 중의 하나가 분석 과제의 기획 및 운영이므로 이를 체계적으로 관리하기 위한 프로세스를 수립해야 한다.
- 분석 과제 관리 프로세스는 크게 과제발굴과 과제수행 및 모니터링으로 나누어진다.
1) 과제발굴
과제발굴 단계에서는 개별 조직이나 개인이 도출한 분석 아이디어를 발굴하고 이를 과제화하여 분석 과제 풀(Pool)로 관리하면서 분석 프로젝트를 선정하는 작업을 수행한다.
2) 과제수행
과제 수행 단계에서는 분석을 수행할 팁을 구성하고 분석과제 실행 시 지속적인 모니터링과 과제 결과를 공유하고 개선하는 절차를 수행한다.
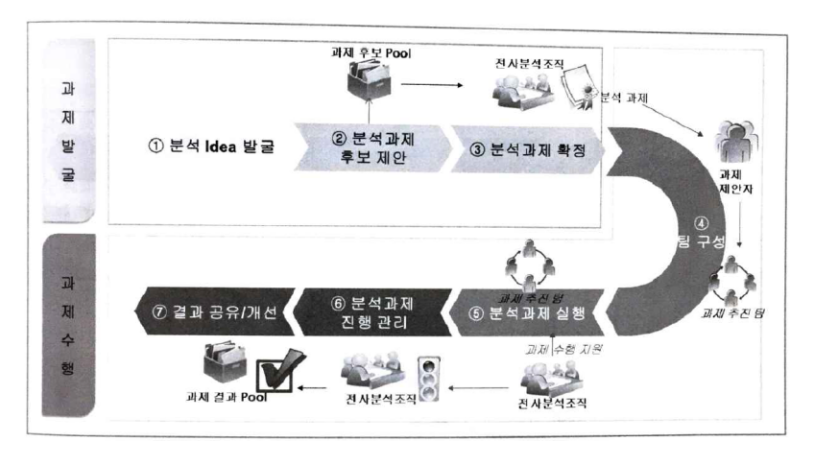
결과적으로 분석조직이 지속적으로 관리 프로젝트를 수행함으로써 조직 내 분석 문화 내재화를 확보하고 해당 과제를 진행하면서 만들어진 시사점(Lesson Learned)을 포함한 결과물을 풀(Pool)에 축적하고 관리함으로써 향후 유사한 분석 과제 수행시 시행착오를 최소화하고 프로젝트를 효율적으로 진행할 수 있다.
7. 분석 교육 및 변화 관리
최근 구성원들에게 데이터 분석 교육을 받도록 독려하는 기업이 늘고 있다. 엔지니어가 입사하면 코드베이스나 문화를 교육시키는 엔지니어 훈련 프로그램을 운영하는 경우이다.
더 나아가 엔지니어 뿐만 아니라 마케팅, 기획, 서비스, 관리 등 모든 부서의 구성원을 대상으로 데이터 분석 훈련 프로그램을 운영하기도 한다.
이러한 배경에는 모든 구성원들이 직접 데이터를 보고, 분석하고 가설을 검증할 수 있는 능력을 갖춤으로써 데이터 활용을 통한 비즈니스 가치를 전사적으로 확대하기 위해서다.
1) 분석 도입에 대한 문화적 대응
예전에는 기업 내 데이터 분석가가 담당했던 일을 모든 구성원이 데이터를 분석하고 이를 바로 업무에 활용할 수 있도록 조직 전반에 분석 문화를 정착시키고 변화시키려는 시도로 볼 수 있다.
체계의 도입 시에는 저항 및 기존 형태로 되돌아가는 관성이 존재하기 때문에 분석의 가치를 극대화하고 내재화하는 안정적인 추진기로 접어들기 위해서는 분석에 관련된 교육 및 마인드 육성을 위한 적극적인 변화 관리가 필요하다.
빅데이터의 등장은 많은 비즈니스 영역에서 변화를 가져왔다. 이러한 변화에 보다 적극적으로 대응하기 위해서는 기업에 맞는 적합한 분석 업무를 도출하고 가치를 높여줄 수 있도록 분석 조직 및 인력에 대한 지속적인 훈련을 실시하여야 한다.
또한 경영진이 데이터에 기반한 의사결정을 할 수 있는 기업 문화를 정착시키려는 변화관리를 지속적으로 계획하고 수행하여야 한다.
2) 분석 교육의 목표
분석 교육의 목표는 단순한 툴 교육이 아닌 분석 역량을 확보하고 강화하는 것에 초점을 맞추어 진행되어야 한다.
분석 기획자에 대한 데이터 분석 큐레이션 교육, 분석 실무자에 대한 데이터 분석 기법 및 도구에 대한 교육, 업무 수행자에 대한 분석 기회 발굴 및 시나리오 작성법 등 분석적인 사고를 업무를 적용할 수 있도록 다양한 교육을 통해 조직 구성원 모두에게 분석기반의 업무를 정착시킬 수 있어야 한다.
이를 통해 데이터를 바라보는 관점, 데이터의 분석과 활용 등이 기업 문화로 자연스럽게 스며들어 확대되어야 한다.
6장. R 기초와 데이터 마트
01. R 기초
1. 분석 환경의 이해
1) 통계 패키지 R의 역사
R 프로그램은 미국 벨 연구소의 John Chamber가 개발한 S 언어를 기반으로 한다.
뉴질랜드의 오클랜드 대학교 로스 이하카와 로버트 젠트맨에 의해서 개발되었다.
2000년 최초 1Version 시작으로 현재까지 4.0.2 버전까지 버전업되어 있다.
2) 통계 패키지 R의 특징
오픈 소스(Open Source)이다.
데이터 핸들링이 우수하다 : 텍스트, CSV, 엑셀, SAS, SPSS, Stata, DB 등의 다양한 데이터를 읽어오는 기능이 있다.
인터프리터 언어다
우수한 그래픽 기능 : 2D, 3D, 동적 그래프 직원
다양한 형태(벡터, 행렬, 배열, 데이터 프레임, 리스트)의 데이터 구조를 지원하므로 분석 대응력이 좋다.
데이터는 메모리(RAM)에서 작동하기 떄문에 속도가 빠르다.
3) R Studio
R을 지원하는 GUI(Graphic User Interface)가 다양하게 있으며, 대표적으로 RStudio, Microsoft Visual Studio, R Commander 등이 있다.
R Studio는 크게 4개의 영역으로 구분되어 있으며 여러 정보를 동시에 확인할 수 있어 작업이 편리하다.
스크립트(Script) 창
Batch 모드로 R Script를 작성하고 실행할 수 있는 창이다.
R Studio 창에서 작성한 Script를 실행하려면 Ctrl + R 또는 Ctrl + Enter 또느 블록 설정 후 RStudio Script 창의 상단 메뉴인 'Run' 단추를 클릭하는 세 가지 방법 중에서 본인이 편한 것을 사용하면 된다.
R 콘솔
R 프로그램을 짜고 실행할 수 있으며, R Script 창 혹은 Console 창에서 작성한 프로그램의 실행(계산) 결과 보기, 패키지 설치, 오류 메시지 등을 확인할 수 있다.
R 프로그램을 자주 사용하는 분이라면 R Script 창에서 프로그램을 작성하고 실행한 후 -> Console 창 -> Environment 창 -> Plot 창으로 보는 식으로 사용할 가능성이 높다
환경(Environment) / 히스토리(History)
환경 창에서 현재 실행 중인 R 프로젝트에서 선언된 변수, 함수, 데이터셋 등의 정보를 살펴볼 수 있다.
히스토리 창에서는 현재까지 정상적으로 실행한 명령어들이 나타난다.
2. R 언어와 문법
1) R의 기초
R을 처음 시작하면 >라는 프롬포트(prompt)가 나타난다.
프롬포트는 사용자의 입력을 기다린다는 표시다.
+는 덧셈, -는 뺄셈, *는 곱셈, /는 나눗셈이며 ^는 거듭제곱을 뜻한다
사칙연산에 대한 연산자나 연산자간의 우선순위는 괄호 -> 거듭제곱 -> 곱하기 나누기 -> 더하기 뺴기
'#' 표시가 붙으면 이하의 내용은 주석을 의미한다.
대소문자를 구분함으로 주의해서 사용해야 한다
R의 변수명은 알파벳, 숫자, _(언더스코어), .(마침표)로 구성되며, -(하이픈)은 사용할 수 없다. 첫 글자는 알파벳 또는 .으로 시작해야 한다. 만약 .으로 시작한다면 .뒤에는 숫자가 올 수 없다.
R의 가장 큰 장점은 단시일 내에 업데이트 되는 패키지의 이용 가능이다
R 콘솔에서 install.packages("패키지명")를 이용하여 직접적인 인스톨이 가능하다
패키지 인스톨 후 library() 함수 또는 require() 함수를 이용해 패키지를 구동한다.
기본 연산자 실행
> 2+3
[1] 5
> 3-1
[1] 2
> 1*2
[1] 2
> (1*3)/2
[1] 1.5
> {2*3}^2
[1] 36
> 1+2;3+4
[1] 3
[1] 7
> x=1
> y=2
> x+y
[1] 32) 할당 연산자
할당 : 변수나 객체에 값을 정의하는 것을 말한다
할당 연산자로 '=', '<-' 사용한다.
주의 '=' R에서는 같다는 의미가 아니다.
R에서 같다는 '=='으로 표기한다.
연산자
<-,=
설명 : 오른쪽의 값을 왼쪽의 이름에 저장
입력 내용 :x-> 3, x=3
동일한 값 3
3) 비교 연산자
두 개 값에 대한 비교로서 맞으면 TRUE, 맞지 않으며 FALSE 값을 갖는다.
>
설명 : 크다
입력 내용 :3>4
결과 : FALSE
>=
설명 : 크거나 같다
입력 내용 :3>=4
결과 : FALSE
==
설명 : 같다
입력 내용 :3==4
결과 : FALSE
!
설명 : 부정
입력 내용 :!(3==4)
결과 : TRUE
4) 논리 연산자
두 개 이상의 조건을 비교하여 결괏값을 출력한다.
&
설명 : AND의 개념(두 개의 조건을 동시에 만족할 때만 TRUE가 되는 논리 연산)
입력 내용 :TRUE & FALSE
결과 :FALSE
|
설명 : OR의 개념(두 개의 조건 중에서 하나만 만족해도 TRUE가 되는 논리 연산)
입력 내용 :TRUE | FALSE
결과 :TRUE
논리 연산자 결과 규칙
논리연산자 벡터를 숫자형 벡터로 사용하는 경우 자동적으로 'TRUE'는 1의 값을 할당바드며 'FALSE'는 0의 값을 받는다.
3. R의 데이터 구조
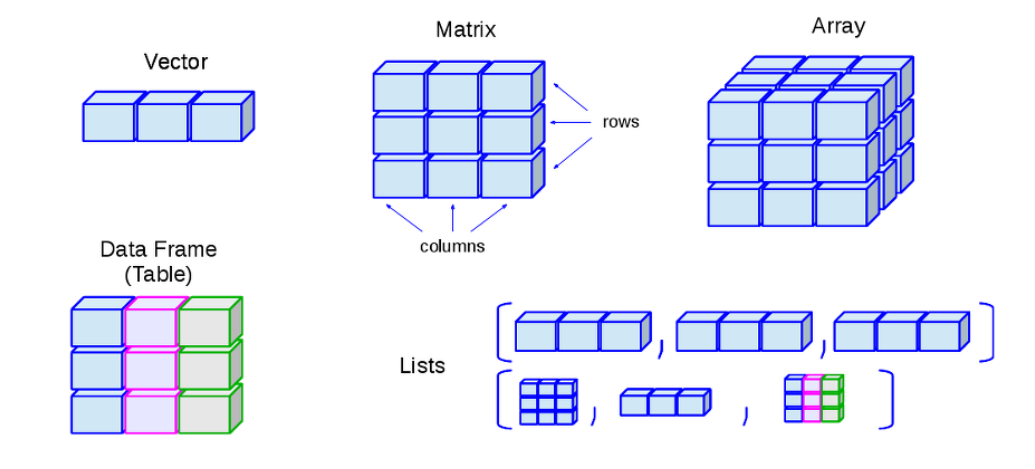
R의 특수 형태
NULL:
