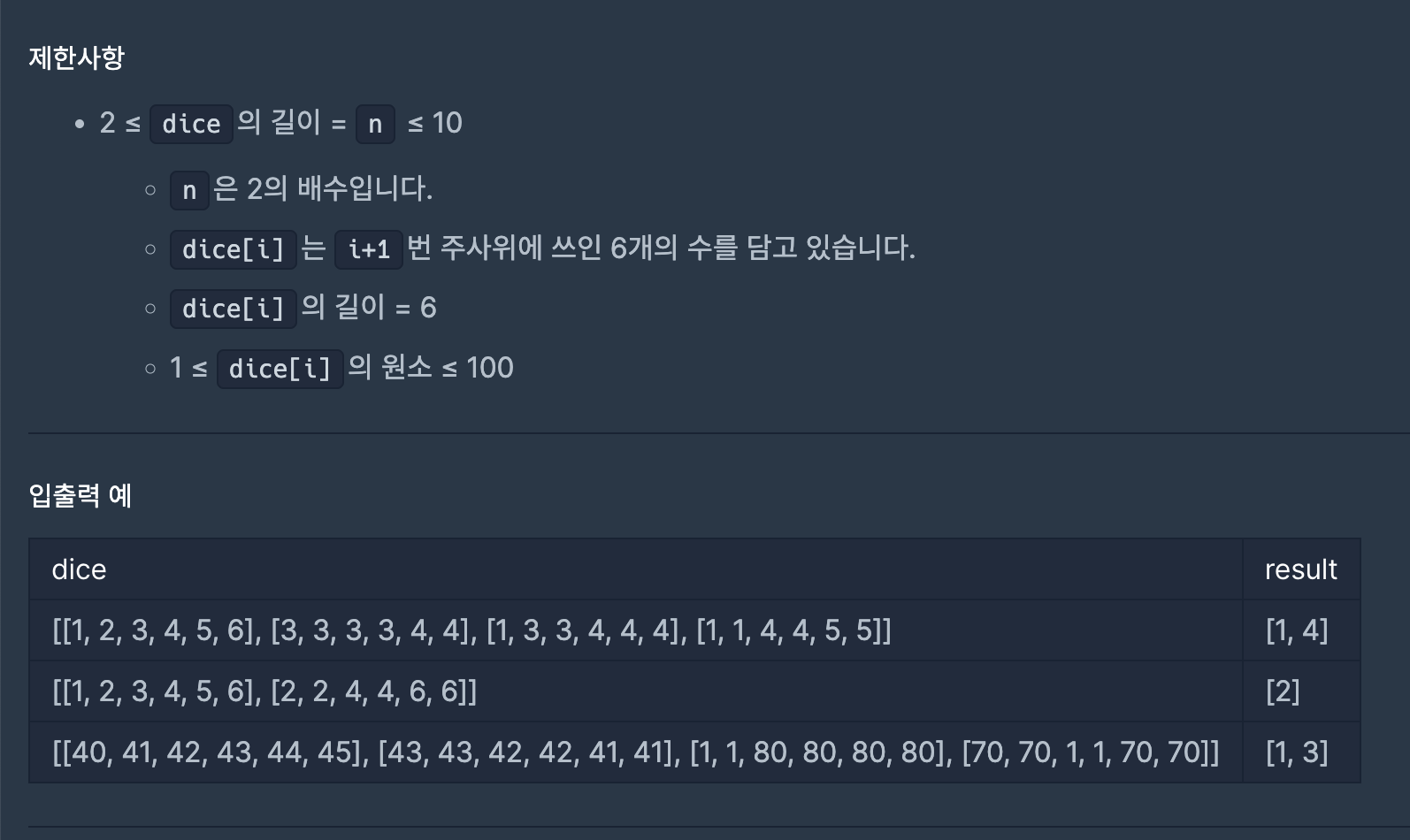
https://school.programmers.co.kr/learn/courses/30/lessons/258709

문제파악
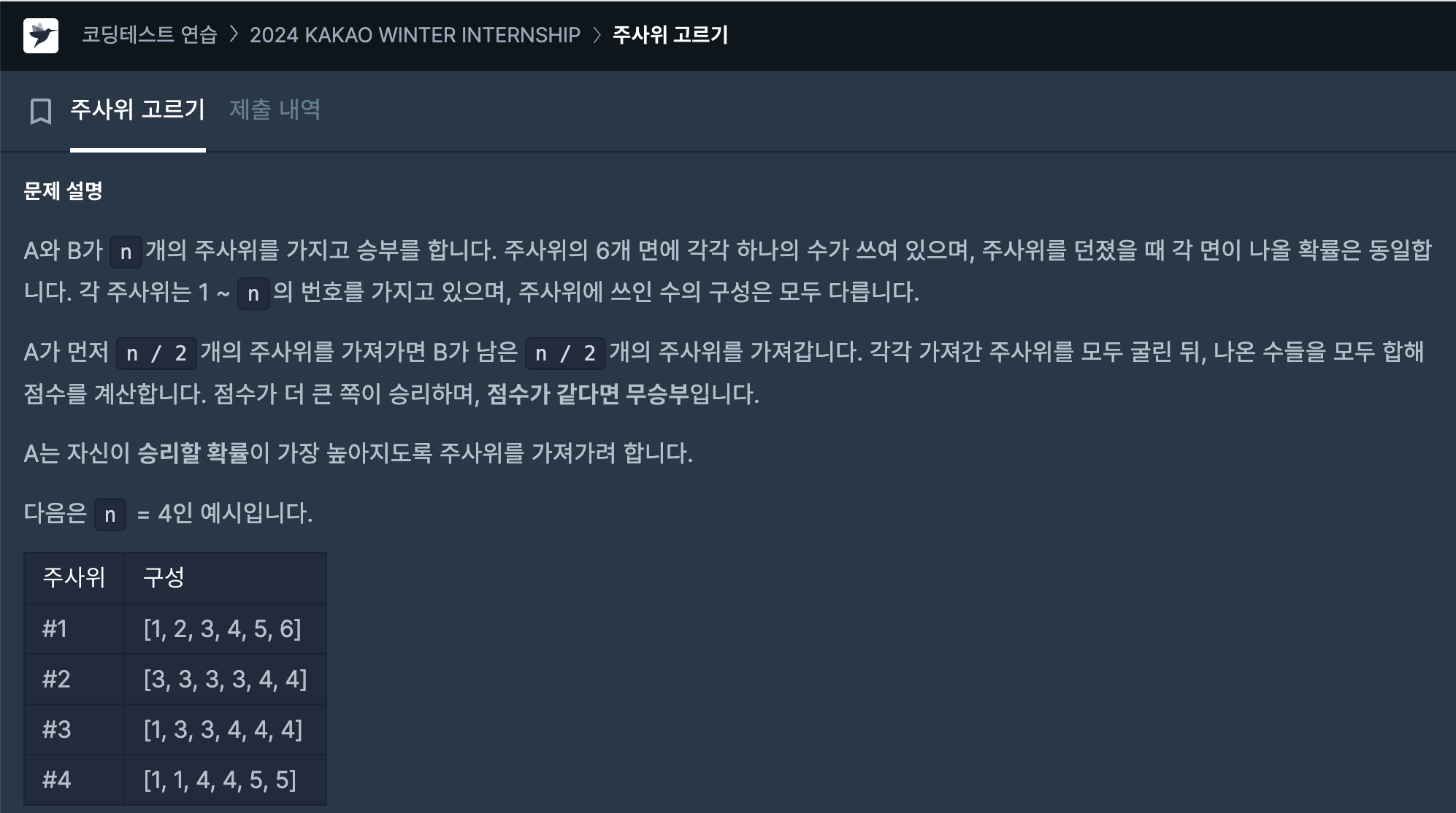
주사위 n개가 주어진다.
사람은 A, B 둘이 존재한다.
A,B 가 각각 주사위를 2/n 개씩 가져가서 한번에 굴린다.
그리고 나온 주사위 눈의 합이 큰 사람이 이긴다.
이 때 주사위의 눈을 1,2,3,4,5,6이 아니라 정육면체긴 한데 적혀있는 value값이 각각 다르다.
그러니 어떤 주사위를 가져가느냐에 따라 이길 확률이 달라진다.
이길 확률을 높이려면 몇번째 주사위를 가져가야 하는 지를 return하는 문제이다.
예시 1
주사위 눈이 담긴 2차원 배열 dice가 이렇게 주어졌다
[[1, 2, 3, 4, 5, 6], [3, 3, 3, 3, 4, 4], [1, 3, 3, 4, 4, 4], [1, 1, 4, 4, 5, 5]]
각각 인덱스 0,1,2,3 주사위가 문제에선 1,2,3,4로 사용된다.
이 예시에서 return이 [1,4] 인데 이는 1번 4번 주사위를 고르면 이길확률이 더 높음을 의미한다.
1 : [1,2,3,4,5,6]
4 : [1,1,4,4,5,5]
2 : [3,3,3,3,4,4]
3 : [1,3,3,4,4,4]
어떻게 접근해야 할까
우선 모든 눈의 합이 큰 주사위를 고르면 될까 싶어 합을 구해본다.
1 : 1+2+3+4+5+6 = 21
4 : 1+1+4+4+5+5 = 20
2 : 3+3+3+3+4+4 = 20
3 : 1+3+3+4+4+4 = 19
얼추 가정이 맞는 것 같기도 하다.
1,4번 주사위 눈의 합 >= 2,3번 주사위 눈의합
그리고 합이 같은 4,2 주사위의 경우
평균이 3.33333 이고 3.33 으로 봤을 때
(관측값 - 평균)^ 2 인 분산을 보면
4번 주사위의 경우 2.8888.. 이나 오고
2번 주사위의 경우 0.222.. 가 나온다.
즉 같은 주사위의 합이라면, 분산이 큰 주사위를 고른다. 가 가정이 되는데..
내 논리가 맞는지 확신이 없어 AI에게 물어본다.

라고 한다.
다시 생각해봤는데 분산을 떠나서 합이 더 크다고 그 주사위가 이길 확률이 높지 않을 수도 있다.
주사위 눈금의 범위는 1이상 100 이하라고 문제에서 명시했고
1 : [100,1,1,1,1] , 합이 104
2 : [20,20,20,20,20] , 합이 100
합이 1이 더 높지만 주사위 2를 고르는게 더 합당해 보인다.
즉 합과 분산을 통해 주사위를 고르는 것이 아니라 모든 경우의 수를 비교하며 어떤 주사위를 고를지 판단해야 한다.
다시 돌아와서
dice가 [[1, 2, 3, 4, 5, 6], [3, 3, 3, 3, 4, 4], [1, 3, 3, 4, 4, 4], [1, 1, 4, 4, 5, 5]] 로 주어졌다면
1번 주사위 : 2,3,4번 주사위와 비교
2번 주사위 : 3,4번 주사위와 비교
3번 주사위 : 4번 주사위와 비교
-> 4+3+2 번 비교 하면 된다.
주사위의 개수 = n
-> nC(2/n) 번 비교하면 된다.
n의 최댓값이 10이며, 10C5 = 252이다.
- 다이스 두개를 인자로 받아 승자를 구해주는 is_winner(dice_A, dice_B) 함수를 만든다.
- is_winner(1,2), is_winner(1,3), is_winner(1,4), is_winner(2,3), is_winner(2,4), is_winner(3,4) 이런식으로 돌려 winner 리스트에 append 한다.
- winner 리스트에서 가장 많이 이긴 두 개의 다이스를 골라 answer 리스트에 넣고 return 한다.
그런데 이 로직도 틀렸다.

라고 한다.
개별 주사위끼리 순위를 매겨 1,2위를 뽑아도 오차가 날 수 있다.
주사위 조합간의 승률을 따져야 한다.
다시 돌아와서
[[1, 2, 3, 4, 5, 6], [3, 3, 3, 3, 4, 4], [1, 3, 3, 4, 4, 4], [1, 1, 4, 4, 5, 5]]
nC2 해서 2개의 주사위를 뽑고,
주사위의 합 리스트를 만들어 거기다가 뽑은 주사위의 합이 될 수 있는 값들을 전부 넣는다.
[1,2,3,4,5,6]과 [3,3,3,3,4,4] 리스트를 뽑았다면
36개의 합이 나올 것이다.
[4,4,4,4,5,5,5,5,5,5,6,6,6,6,6,6,7,7,8,8,8,8,9,9,9,9,9,9,10,10]
그리고 안뽑은 나머지 두개의 주사위의 합 리스트도 구한다.
[2,2,5,5,6,6,4,4,7,7,8,8,4,4,7,7,8,8,5,5,8,8,9,9,5,5,8,8,9,9,5,5,8,8,9,9]
그리고 36개의 원소와 36개의 원소 크기 차이를 구한다.
앞 합 - 뒷 합 해서 양수가 나오면 앞 합 주사위 승, 음수가 나오면 뒷 합 주사위 승
그렇다면 이쯤에서 시간복잡도를 생각해봐야 한다.
전체 시행 횟수는
n개의 주사위 중 절반을 선택하는 경우의 수 x 고른 절반의 주사위들의 합 리스트를 생성 x 나머지 절반의 주사위 들의 합 생성해 비교 해야 하므로
nC(n/2) 6^(n/2) 6^(n/2) 이 된다.
프로그래머스 기준으로 Python에서 약 1억(10⁸) 연산 넘으면 거의 시간초과이다.
n이 최댓값 10일때,
10C5 6^5 6^5 의 연산을 할 경우
252 x 7776 * 7776
= 15,234,477,952
즉 약 1.5 × 10¹⁰ 번 연산 이며 시간초과이다.
그러니 시간 복잡도를 줄여야 한다.
이진 탐색을 떠올리면 시간을 줄일 수 있다.
그리고 이진 탐색을 떠올리는 사고의 전환은 이러하다.
| 단계 | 사고 전환 |
|---|---|
| ① | 전수 비교로 시작한다. |
| ② | 비교 대상이 “정렬 가능한 값”임을 인식한다. |
| ③ | “작은 게 몇 개냐?”는 누적 개수 문제로 바꾼다. |
| ④ | 누적 개수를 빠르게 구하려면 → 이진탐색(bisect) 혹은 prefix sum |
| ⑤ | 시간복잡도 O(N²) → O(N log N)로 줄인다. |
해답 및 풀이
from itertools import combinations
from bisect import bisect_left
# dices는 2차원 배열 [[1, 2, 3, 4, 5, 6], [3, 3, 3, 3, 4, 4], [1, 3, 3, 4, 4, 4], [1, 1, 4, 4, 5, 5]]
def solution(dices):
n = len(dices)
half = n // 2
idx_all = list(range(n)) # ex) [0,1,2,3,4]
def sums_of(indexes): # indexes는 합칠 주사위의 인덱스
# 주사위 합 분포 생성
sums = [0]
for i in indexes:
faces = dices[i] # 주사위의 눈금
nxt = []
for s in sums: #
for f in faces:
nxt.append(s + f)
sums = nxt
return sums # 길이 6 ** len(indices)
best_win = -1
best_pick = None
# 모든 A조합을 돌고, B조합과 쌍으로 한번에 평가
for A in combinations(idx_all, half): # nC(n/2)
B = tuple(i for i in idx_all if i not in A) # idx_all 순회하면서 i가 A에 들어있지 않으면 B에 추가
sums_A = sums_of(A)
sums_B = sums_of(B)
# A가 이기는 경우의 수 : A합 > B합
sums_B.sort()
win_A = 0
for a in sums_A:
win_A += bisect_left(sums_B, a)
# B가 이기는 경우의 수도 계산
sums_A.sort()
win_B = 0
for b in sums_B:
win_B += bisect_left(sums_A, b)
# 더 많은 승수를 가진 쪽을 후보로
if win_A >= win_B:
cand_win, cand_pick = win_A, A
else:
cand_win, cand_pick = win_B, B
# 최대 승수 갱신
if cand_win > best_win or cand_win == best_win:
best_win = cand_win
best_pick = cand_pick
# 1-base로 변환해 오름차순 리스트 반환
return [i + 1 for i in best_pick]
sums_of 함수의 흐름
주사위 인덱스를 인자로 받아 주사위 눈금의 합 리스트를 만드는 함수인
sums_of 함수의 흐름을 보자
def sums_of(indexes): # indexes는 합칠 주사위의 인덱스
# 주사위 합 분포 생성
sums = [0]
for i in indexes:
faces = dices[i] # 주사위의 눈금
nxt = []
for s in sums: #
for f in faces:
nxt.append(s + f)
sums = nxt
return sums # 길이 6 ** len(indices)예를 들어,
indexes = [0, 2] 라면
→ dices[0] = [1, 2, 3, 4, 5, 6]
→ dices[2] = [1, 3, 3, 4, 4, 4]
i에 0과 2가 들어가는데
1) i = 0,
faces = dices[0]
= [1,2,3,4,5,6]
sums 가 [0] 이라
nxt.append(s+f) 에서 그냥 f가 다 들어가
sums = [1,2,3,4,5,6] 이 된다.
2) i = 2,
faces = dices[2]
= [1,3,3,4,4,4]
for s in sums: # 현재 sums = [1,2,3,4,5,6]
for f in faces: # faces = [1,3,3,4,4,4] , 6*6번 반복이 된다.
nxt.append(s + f)
sums = nxts가 1일때,
nxt = [1+1, 1+3, 1+3, 1+4, 1+4, 1+4] => [2,4,4,5,5,5]
s가 2일때,
nxt = [2,4,4,5,5,5 에다가 3,5,5,6,6,6 이어 붙여짐]
.
.
.
이런식으로
s = 6 일때 36개의 합 원소들이 append 되는 로직이다.
B = tuple(i for i in idx_all if i not in A) # idx_all 순회하면서 i가 A에 들어있지 않으면 B에 추가
코드는
tmp = []
for i in idx_all:
if i not in A: # A에 없으면
tmp.append(i)
B = tuple(tmp)늘여쓰면 이렇게 된다.
이진 탐색 besect_left
# A가 이기는 경우의 수 : A합 > B합
sums_B.sort()
win_A = 0
for a in sums_A:
win_A += bisect_left(sums_B, a)bisect_left(sorted_list,x) 는
정렬된 리스트에서 x를 왼쪽에 끼워 넣을 수 있는 인덱스를 반환한다.
즉, sorted_list 안에서 x보다 작은 원소의 개수를 알려줌.
arr = [1, 2, 4, 4, 5]
bisect_left(arr, 4) → 2 # (4보다 작은 원소는 [1,2] 두 개)
bisect_left(arr, 6) → 5 # (6보다 작은 원소는 전부 다섯 개)
bisect_left(arr, 0) → 0 # (0보다 작은 건 없음)다시 위 코드에서
1. sums_B를 오름차순 정렬.
-
sums_A의 각 합 a에 대해,
sums_B 안에서 a보다 작은 원소의 개수를 센다.
→ bisect_left(sums_B, a) 결과가 바로 그 개수. -
이걸 전부 더하면,
“A합이 B합보다 큰 (A,B)쌍”의 총 개수가 된다.
예시
sums_A = [4, 5, 6]
sums_B = [2, 3, 7]
sums_B.sort() → [2, 3, 7]| a | bisect_left(sums_B, a) | 의미 |
|---|---|---|
| 4 | 2 | 4보다 작은 B합은 [2,3] → 2개 승리 |
| 5 | 2 | 5보다 작은 B합은 [2,3] → 2개 승리 |
| 6 | 2 | 6보다 작은 B합은 [2,3] → 2개 승리 |
마무리하며
이 문제는 완전 탐색으로 우선 접근하며 최대 시간복잡도를 떠올려보고, 그냥은 불가능하다 & 이진 탐색으로 이으며 마무리해야 하는 문제였다.
정렬 가능한 리스트나 이터러블한 객체에서 어떠한 값보다 더 작거나 큰 값의 개수를 구해야 한다면 bisect 라이브러리에 bisect_left() 를 떠올리자.
