크롤링
-
웹에서 원하는 자료를 컴퓨터에게 수집해오도록 하는 기술
-
requests 라이브러리를 활용한 브라우저 없는 크롤링
-
selenium 라이브러리를 활용한 물리 드라이버 크롤링
-
urllib 라이브러리를 활용한 api 크롤링 등이 있다.
-
크롤러의 역할은 원하는 정보를 포함한 자료를 수집해오는 것까지이며
-
실제로 원하는 데이터를 용도에 맞게 처리하는 것은 BeautifulSoup가 담당한다.
1. selenium 설치
- anaconda navigator 에서 좌측 environment를 선택합니다.
- 중간 base(root) 우측에 붙어있는 재생버튼 클릭 -> open terminal을 선택합니다.
- 열리는 cmd 창에서 pip install selenium을 입력합니다.
- 이건 Git bash에서 설치한 모습이지만 cmd에서 설치해도 비슷한 화면이 도출된다.
2. selenium 불러오기
- 크롤링 작업을 위한 라이브러리 import
- 셀레니움 설치 후 커널 리스타트 후 실행
from bs4 import BeautifulSoup
from selenium import webdriver
import requests - 코드 진행 지연을 위한 time import
import time- 셀레니움 설치 전에 실행 시 오류 발생.
- 셀레니움 설치가 끝났다면 크롬 드라이버를 설치해야 한다.
3. Chrome driver 설치
- 크롬드라이버 다운받기
- 크롬창 우측 상단 메뉴 클릭
- 밑에서 두 번째에 있는 "도움말" 항목에 마우스 갖다대기
- Chrome정보 클릭하기
- Chrome정보에 나온 버전(강사 컴퓨터는 현재 크롬 101버전 사용중) 확인하기
- https://chromedriver.chromium.org/downloads
위 주소로 접속해서 버전에 맞는 다운로드 링크로 가기 - chromedriver zip파일 받아서 내부 chromedriver.exe파일에 대한 압축을 주피터노트북 코드가 있는 쪽에 풀기
(window -> win32, 리눅스 맥 등은 맞는버전으로)
- 네이버 창을 1초 후에 오픈 후 2초 후에 종료하기.

- 네이버에서 로그인 버튼 클릭 후 아이디 비밀번호 기입하기(네이버에서는 크롬 드라이버에 의한 자동 로그인을 막아놔서 후속 작업은 수동으로 해야 된다.)

- !!중요!! XPATH를 추출하는 방법 : 네이버 화면에서 F12 클릭 후 나타나는 박스의 좌측 상단에 네모 안에 마우스 표시를 클릭하여 영역을 찾는다. 그 후 표시된 영역 우클릭 copy -XPTH copy 선택
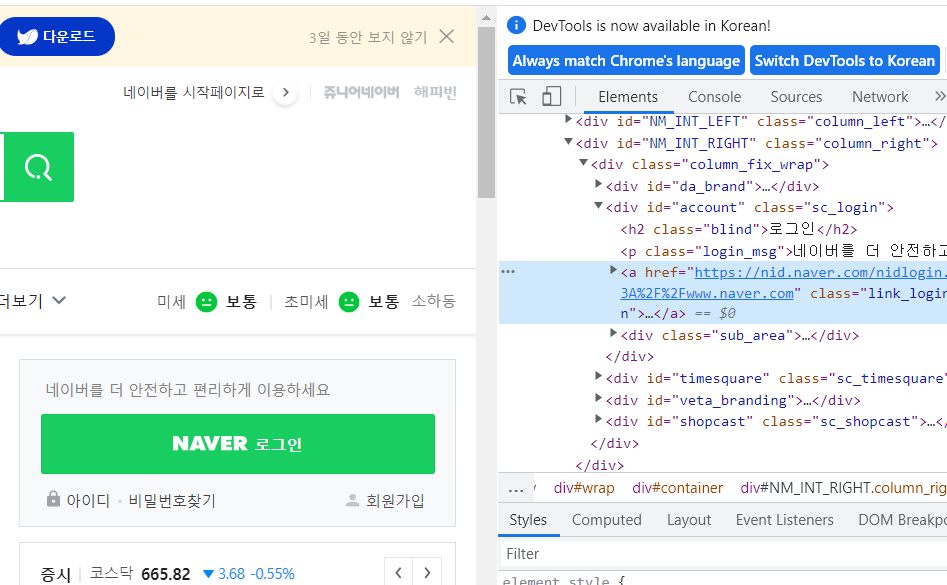
- !!중요!! XPATH를 추출하는 방법 : 네이버 화면에서 F12 클릭 후 나타나는 박스의 좌측 상단에 네모 안에 마우스 표시를 클릭하여 영역을 찾는다. 그 후 표시된 영역 우클릭 copy -XPTH copy 선택
- 로그인

4. 교보문고 베스트셀러를 크롤링 해보자.
-
교보문고 베스트셀러 브라우저 접속

-
브라우저가 특정 페이지에 접근했을 때, 해당 페이지 소스코드 전체를 긁어와서 필요한 데이터를 추려나가는 방식이다.
-
셀레니움의 역할은 전체 소스 코드를 크롤링 하는 것이다.(크롤링 한 소스 코드들의 모습)

-
이후 필요한 소스 코드를 BeautifulSoup 로 정제해서 사용한다. BeautifulSoup 는 수집 기능 라이브러리가 아니라 소스를 해석하는 기능이다.)

-
driver.page_source는 source 변수에 전체 페이지 소스를 문자로 저장함
-
-
BeautifulSoup(소스코드, "html.parser") 로 입력시 해당 코드를 html 형식으로 인식함. (그래서 전체 소스를 가져온 source 변수와 BS4를 적용한 parsed_source 변수가 타입이 다른 것이다.)

- 해당 str(문자열) 자료를 html형식으로 인식시키는 것을 "파싱" 이라고 합니다.
- 책을 소유하고 있다고 그 책에 대해 반드시 이해하고 있는건 아니듯 책 내용을 읽어서 이해하고 지식을 구조화해야 비로소 책을 이해하고 있다고 할 수 있는데
- BeautifulSoup도 소스코드가 단순 문자로 존재할때는 기능을 쓸 수 없지만 파싱을 통해 소스코드 구조를 정제하여 (컴퓨터가) 매우 빠르고 쉽게 처리할 수 있게 해줍니다.
-
책 제목, 저자, 가격 데이터 수집
- 파싱된 코드.findall("태그명", class="클래스명", id="아이디명") : 입력시 해당 태그나 클래스에 대한 데이터만 가져올 수 있음
- F12 누른 후 선택 해당 코드 더블 클릭 & 복사

- 타이틀

- 이 자료를 .text로 정제하고 리스트화 한다.(저자 및 가격도 동일 수행)

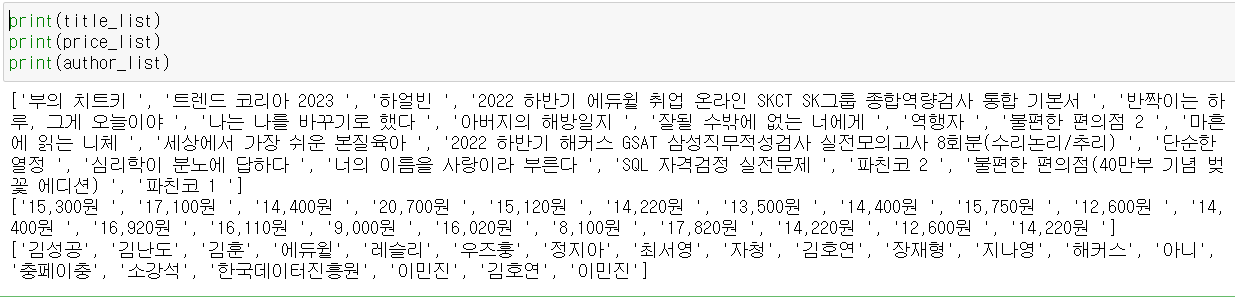
- 책 제목 리스트 출력값

-
필요한 데이터를 모두 리스트화 하였다.
-
리스트로 만든 자료들을 보기 좋게 정리.

- 자료 정리 성공

- 자료 정리 성공
5. codecs 라이브러리
-
파이썬 3.5버전 들어서 내장 라이브러리로 바뀜(예전에는 pip로 설치해야 했었음)
-
파이썬으로 텍스트파일을 제어할 수 있도록(읽어오기, 쓰기) 도와줌
-
콘솔창에 출력된 내용을 txt파일로 옮겨서 출력할때 사용
-
f 변수가 텍스트파일 그 자체처럼 사용함
-
함수 작성법
- .open(파일경로(파일이 존재하지 않으면 새 텍스트 파일 생성),
- encoding="인코딩방식", mode="모드")
-
특이사항
개행은 \r\n으로 처리함- mode => w(기존에 있던 자료 없애고 새 파일 입력)
- mode => a(기존에 있던 자료에 이어서 계속 입력)
- mode => r(텍스트파일에 있던 내용 읽어오기)
-
이를 메모장에 정리 후 다시 메모장의 내용을 파이썬에 출력해보자.
- 메모장에 저장(코덱스 함수를 사용한다. )
- 주의할 점은 코덱스 함수는 항상 f.close() 종료 명령어를 마지막에 써넣어야 자체 종료가 가능하다. (안 넣으면 메모장 종료가 불가능하다고 한다.)

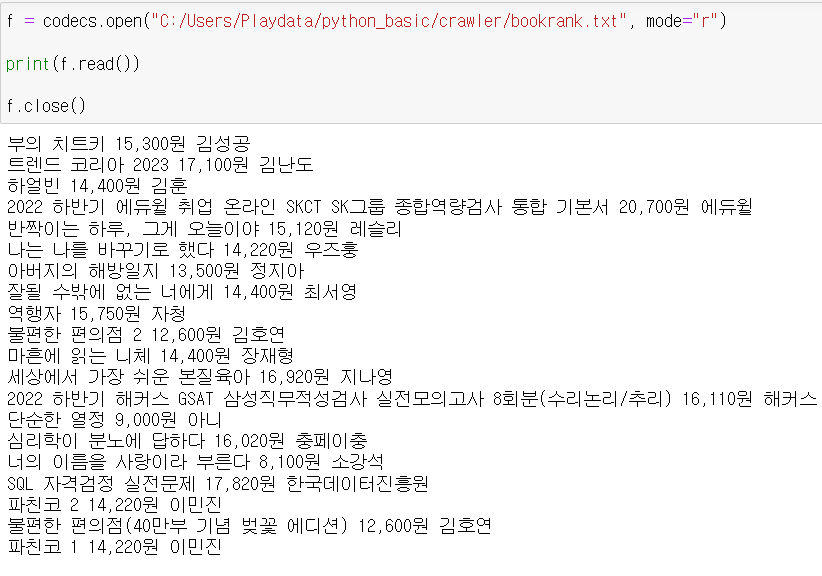
- 메모장 결과값

- 이를 다시 파이썬 출력창에 출력해보자.