데이터 입출력
1. csv 파일 적재
-
pd.read_csv()
- 컬럼명이 존재하는 데이터
- 컬럼명이 없는 데이터
- 구분자 설정
-
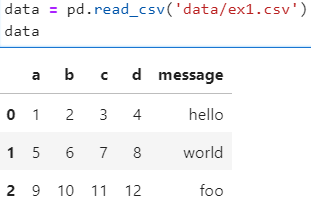
data/ex1.csv 파일 읽기(컬럼명이 존재하는 csv파일)
- read_csv 기본동작 : 첫 행 데이터를 컬럼으로 사용
- 절대 경로 :
- 파이썬 파일 경로
C:\Users\Playdata\python_basic\python_da~~.ipynb - csv 파일 경로
C:\Users\Playdata\python_basic\python_da\data\ex1.csv
- 파이썬 파일 경로
- 파이썬 주피터노트북 파일과 같은 폴더에 있기 때문에 상대 경로만 써도 된다.
- 위 경로에서 겹치는 부분을 제하고 달라지는 분기점부터 입력하면된다.
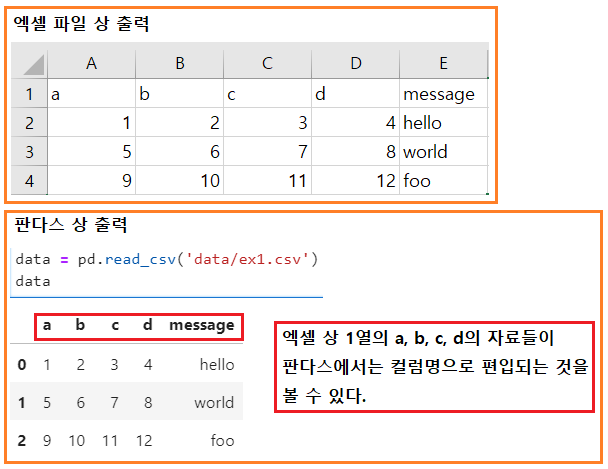
- csv파일 상 출력 vs 판다스 출력
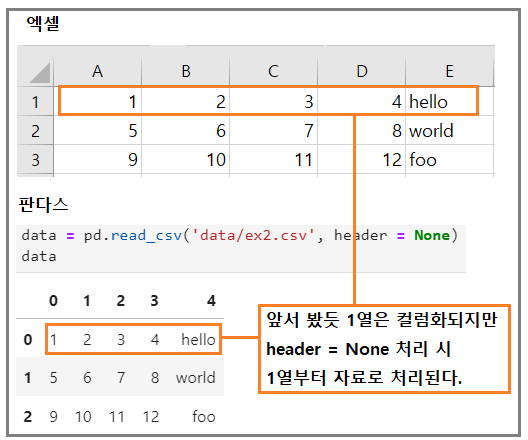
-
header = None
- 컬럼, 로우명 없이 데이터만 있는 자료들을 처리할 때 사용
- 컬럼명 a, b, c, d, e 를 data 변수에 부여해보세요.
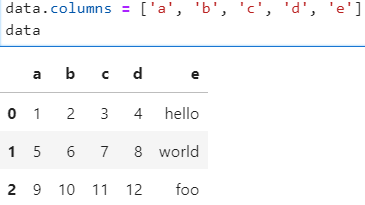
- 컬럼명 a, b, c, d, e 를 data 변수에 부여해보세요.
- 컬럼, 로우명 없이 데이터만 있는 자료들을 처리할 때 사용
-
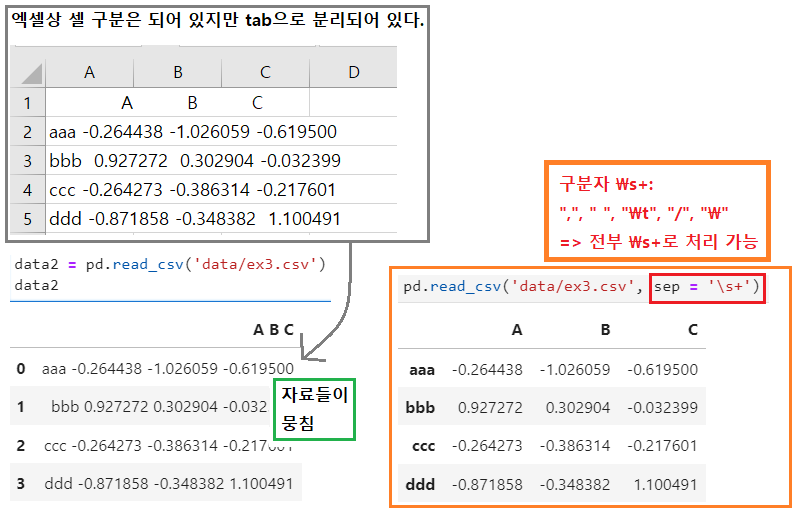
기본 구분자가 맞지 않아 자료 구분이 제대로 되어 있지 않은 경우
- 기본 구분자 = ,
- read_csv() : sep 파라미터 : \s+로 전부 구분자 처리 가능
-
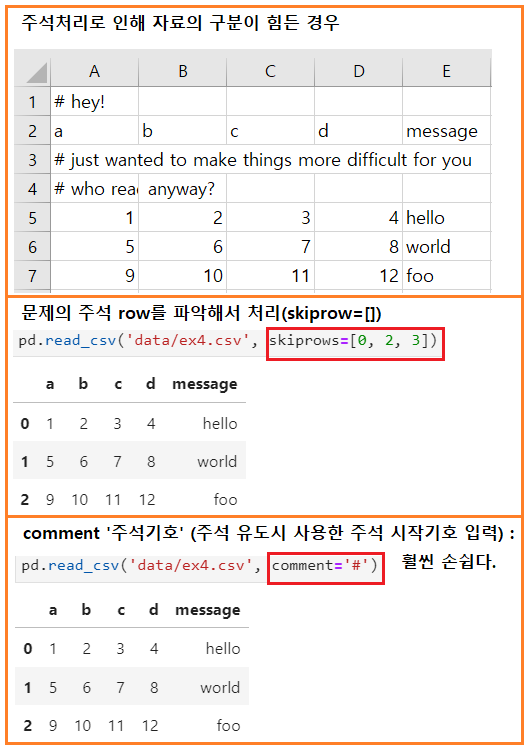
주석 처리
2. 엑셀 파일 읽기
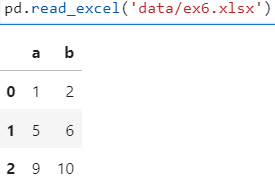
- 기본적으로 첫번째 시트에 있는 데이터를 읽어와서 데이터프레임으로 저장
- 모든 시트를 읽기 위해서는 sheetname 인자를 None으로 설정
- 모든 시트의 데이터를 읽어서 사전 형태로 저장
- key = 시트의 이름, value = 각 시트에 있는 데이터들을 저장한 데이터프레임
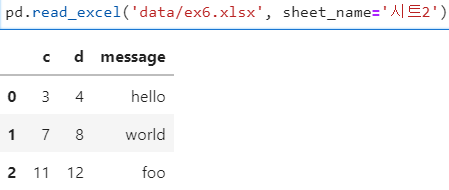
- 특정 시트만 읽기 위해서는 sheetname 인자에 '시트명' 설정

- 파일 읽기(첫 번째 시트만 자동으로 읽어옴. 디폴트)
- 두 번째 시트 읽기 : sheet_name = '시트명'
- 모든 시트 다 읽어오기
- sheet_name 파라미터 설정 : None
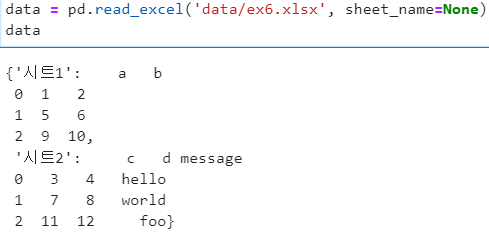
- sheet_name 파라미터 설정 : None
- key값, value값 출력

- 시트1, 시트2의 데이터를 각각 변수 data1, data2에 저장하기
- data1, data2 = data.values()
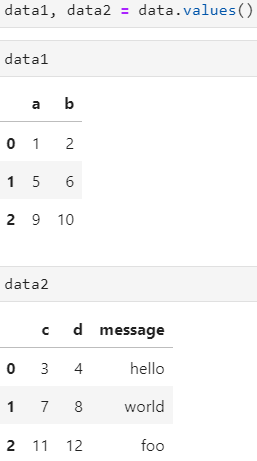
- data1, data2 = data.values()

가즈아~