데이터 전처리
- 데이터 형식에 대한 처리
- 공백 문자
- str.strip() : 양쪽 공백 제거
- str.lstrip() : 왼쪽 공백 제거
- str.rstip() : 오른쪽 공백 제거- 데이터 타입
- 불규칙한 대소문자
- 불규칙한 구분기호
- 유효하지 않은 문자
- 불규칙한 날짜 및 시간 표기
- 공백 문자
1. 날짜 형식
-
날짜 데이터 1 : 양식별 날짜 데이터 생성

- 시리즈 형태로 저장

- str 타입을 datetime 타입으로 변환 후 pandas 저장

- str 타입으로 저장 후 데이터 타입 변경
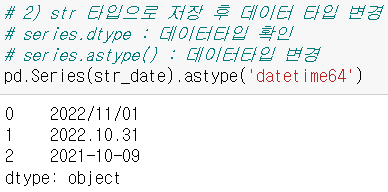
- 시리즈 형태로 저장
-
날짜 데이터 2 : timestamp 타입
- timestamp : 기준 시각(1970.01.01 00:00:00 UTC)로부터 몇 초가 경과했는지 표기
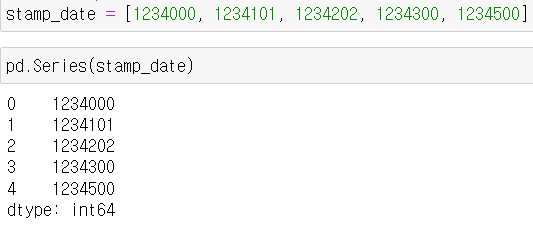
- datetime 타입으로 변환 후 저장
- timestamp의 기본 unit = ns(nano seconds) 나노초 : 10억분의 1초
- unit의 종류 = ns(default), D(days), s(seconds), ms(milli seconds), us(micro seconds)
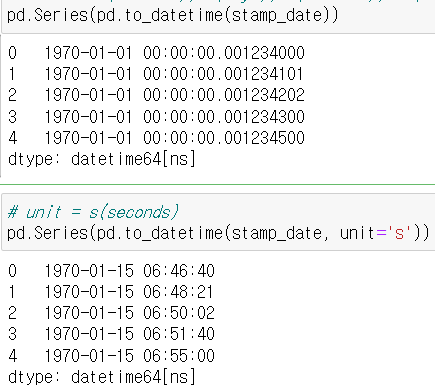

- 너무 먼 시간은 에러를 출력한다.(오버플로우 에러 : 2038년 문제(Y2K와 유사) - 너무 먼 시간은 표현 불가)

- timestamp : 기준 시각(1970.01.01 00:00:00 UTC)로부터 몇 초가 경과했는지 표기
2. 라벨 형식 통일
- 데이터 인코딩 작업에 포함
- map()
- dictionary 타입으로 encoding map을 생성해서 적용
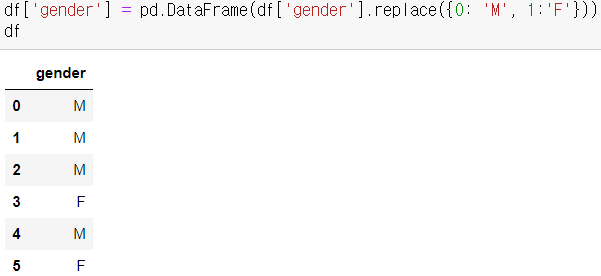
gender = 0(남자), 1(여자)
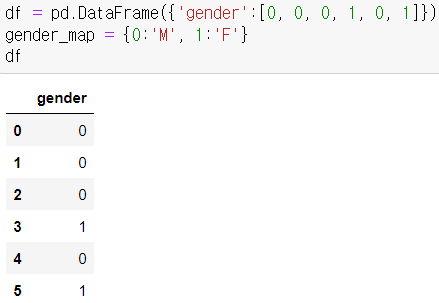
- df 변수의 'gender' 컬럼의 값을 map 함수를 이용해 0은 M으로, 1은 F로 변환

- 데이터 프레임에도 반영해보기.
- 내가 한 방법
df['gender'] = pd.DataFrame(df['gender'].replace(0, 'M').replace(1, 'F')) - 이 코드가 더 맞는 방법으로 보인다.
- df['gender'] = pd.DataFrame(df['gender'].replace([0, 1], ['M', 'F'])
- 혹은 df['gender'] = pd.DataFrame(df['gender'].replace({0: 'M', 1:'F'}))
- 내가 한 방법
- dictionary 타입으로 encoding map을 생성해서 적용
3. 문자 형식(대소문자, 기호 등) 통일
-
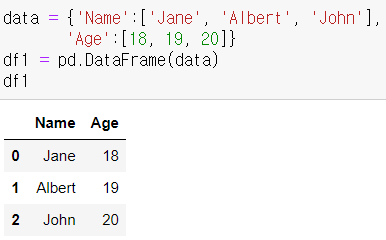
데이터 프레임 생성
-
여러가지 전처리
-
컬럼명 바꾸기
- 빈 리스트에 소문자로 변경한 컬럼을 모두 적재한 뒤 대입

- 바로 적용 후 대입하는 방법도 있다.(.str처리를 안해주면 에러 발생)

- 함수 사용도 가능
- 내부 요소(NAME컬럼)의 모든 자료를 소문자로 통일
- age : 정수 자료이므로 고칠 필요가 없음. 따라서 배제.
- .apply(함수명) / .map으로 대체해서 사용 가능하다.
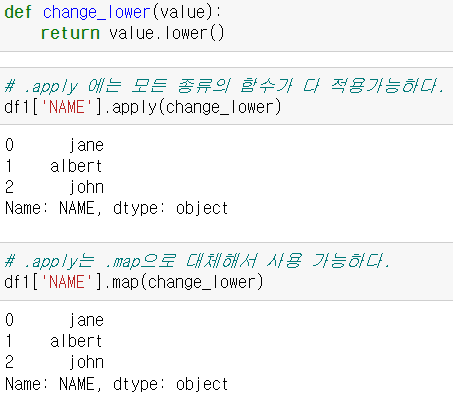
- 해당 함수의 리턴값으로 컬럼 내부 값을 일괄적으로 교체해주는 명령어
- 빈 리스트에 소문자로 변경한 컬럼을 모두 적재한 뒤 대입
-
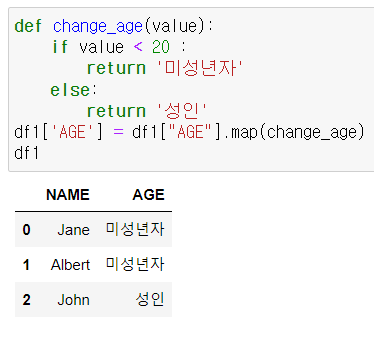
AGE 컬럼의 값을 20이상이면 "성인" 19이하면 "미성년자"를 리턴하도록 is_adult() 함수로 정의해보자.
- 내가 만든 함수(작동 잘 함)

- 더 좋아보이는 방법(바로 리턴 적용하기)
- 내가 만든 함수(작동 잘 함)
-
데이터 값에 대한 처리
-
결측값 # NAN 값
-
이상치
-
단순 중복 데이터
-
동일한 의미, 다른 명칭의 중복 데이터
-
중복속성(다중공선성) : 독립 변수들 간의 성질이 비슷하여 거의 같은 속성을 가진 경우 가중치를 2배로 만드므로 빼주는게 좋다.
ex> 승리 경기를 수집하는데 15점 이상 낸 승리 경기의 경우 15점 이상이라는 조건을 제거하는 것이 좋다. / 타율과 안타율을 둘 다 고려하는 경우 -
불규칙한 데이터 수집(간격, 단위) # 매 분 정보 수집 - 몰아서 정보 수집하는 경우 밀도가 내려감
-
데이터 적재하기
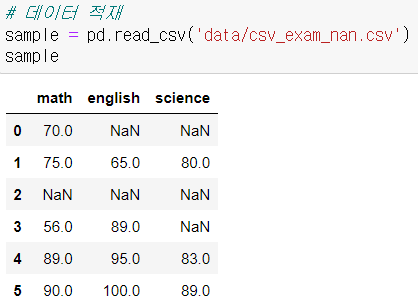
결측치 처리 - 삭제
-
종류
- 결측치가 하나라도 있는 레코드 삭제
- 모든 값이 결측인 레코드 삭제
- 결측치가 하나라도 있는 데이터만 선택
-
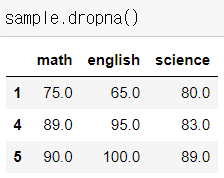
결측치가 하나 이상인 레코드(row) 삭제
- df.dropna(how='any'(default), inplace=True)
- inplace 파라미터 : 원본에 바로 반영
- sample.dropna() # how ='any' 가 default
- 과락 책정 등의 기능에 사용할 수 있다.
- df.dropna(how='any'(default), inplace=True)
-
모든 값이 결측치인 레코드만 삭제
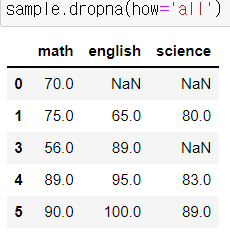
-
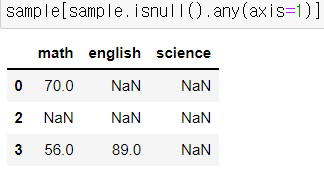
결측치가 하나라도 있는 데이터만 선택
- isnull().any() 코드의 원리는 조건색인과 같다는 것을 알 수 있다.
- df[df.isnull().any(axis=1)] : any는 컬럼별로 True인 값들만 출력
-
isnull() 함수 활용
- .isnull()은 모든 셀을 구분해서 NaN가 있는 셀은 True, 아닌 셀은 False를 출력합니다.
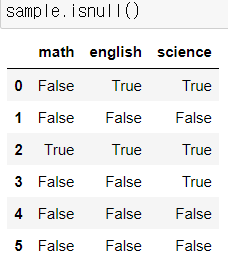
- any는 해당 컬럼에 isnull()의 결과값이 True인 셀이 존재하는지 체크해줍니다.
- 디폴트는 axis=0(컬럼 기준으로 결측치 있음, 없음 여부 조사)

- axis=1 을 기입하면 로우 기준으로 판단합니다.
- 몇 번 row에 결측치가 있고, 몇 번에 없는지 True, False로 보여줍니다.
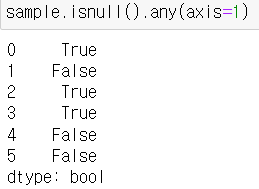
- 몇 번 row에 결측치가 있고, 몇 번에 없는지 True, False로 보여줍니다.
- 결측치 개수를 세는 법 (C언어 기반이므로 False=0, True=1)

- .isnull()은 모든 셀을 구분해서 NaN가 있는 셀은 True, 아닌 셀은 False를 출력합니다.
결측치 처리 - 대체값
-
연속형(숫자형) : 임의값(0 등,...), mean, median, 예측값, 도메인 지식 활용
-
명목형(문자형) : mode(최빈값), 예측값, 도메인지식 활용
-
연속형 (임의의 값으로 대체)
-
df.fillna(v)
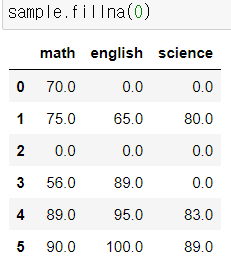
-
mean
- 특징
- 전체 데이터의 평균값
- sample : 6 * 3 모든 데이터에 대한 평균
- df.mean() : 컬럼별로 평균값 (전체 평균 시 다른 방법 사용)
- NaN를 제외한 평균으로 계산

- 특징
-
df.values() : Array 타입의 연산으로 NaN값이 하나라도 있다면 최종결과도 NaN
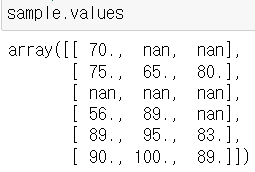
- sample.values.mean() -> 전체 평균을 구할 수 있지만 NaN
- Array 내부에 NaN 값이 존재하기 때문에
- sample.values.mean() -> 전체 평균을 구할 수 있지만 NaN
-
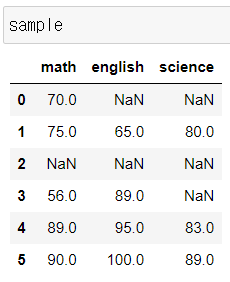
그래서 결측치 값을 부여해서 활용하는 방법을 사용하게 된다.
- 예시 : df.fillna(0)으로 결측치를 보완하고 => mean() 평균을 구하는 방식을 사용
- NaN가 0으로 대체된 평균을 먼저 구한 다음, 그 평균값으로 결측치를 메꿔주세요.
- 내가 한 방법
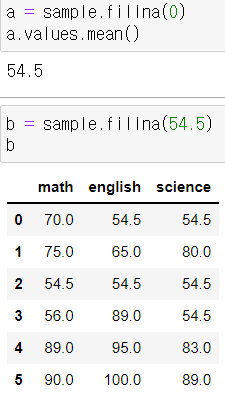
- 더 좋아보이는 방법
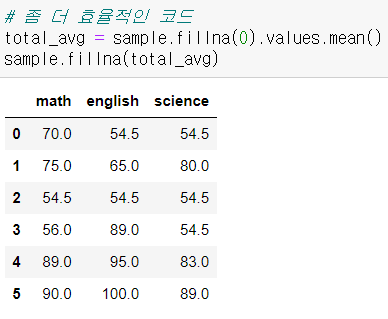
- 내가 한 방법
-
과목별 조회
- mean : 결측치가 존재하는 속성(변수 = 컬럼)의 평균값
- sample : math/en/sc 컬럼에 존재하는 결측치 -> math/en/sc 컬럼의 평균값
- df.mean() : 컬럼별 평균
- 인덱싱으로 과목별 평균 조회
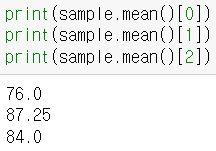
- 컬럼 지정 후 평균 구하기
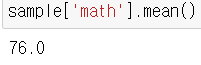
- fillna를 이용해 수학, 영어, 과학 컬럼에 각각 컬럼의 평균값을 결측치 대신 대입이 가능하다.

- 컬럼 지정 후 평균 구하기
-
하지만 이 모든 활용은 원본에는 영향이 없다.
-
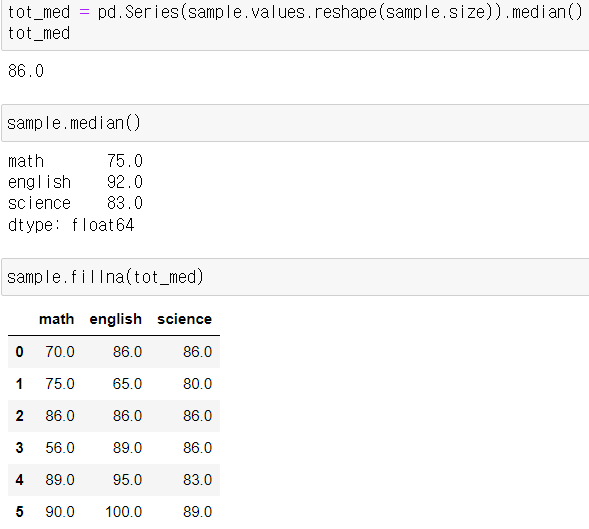
median의 활용
- 전체 데이터에 대한 중위값
- 펜더스 시리즈나 데이터프레임은 벡터함수 연산시 자동으로 NaN을 배제합니다.
- 따라서 전체데이터의 중위값을 구하기 위해 먼저 Series로 바꿔줍니다.
- sample.size를 .reshape()에 넣어주면 자동으로 1차원 배열로 크기를 맞춰서 바꿔줍니다.
- NaN값을 유지한채로 전체 중위값을 구하기 위해 이런 방법을 사용합니다.(왜 이런 방법을 사용하는가?에 대한 대답)
-
-
명목형 (문자에 대한 판단 - 최빈값 등)
- 활용 가능 함수들
- mode - 범주형 데이터에서는 최빈값을 사용
- describe()
- value_counts()
- collections 라이브러리의 Counter 모듈
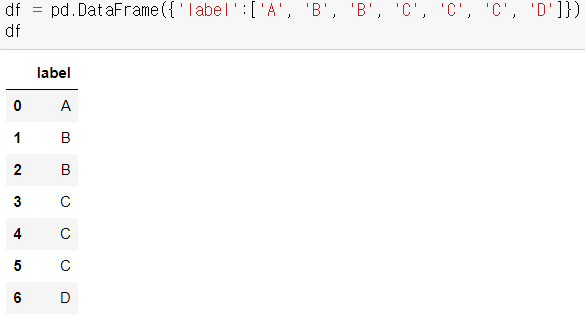
- 데이터 프레임 생성
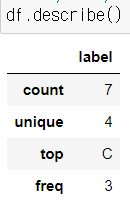
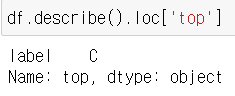
- describe() 함수
- .describe()는 통계분석에 사용합니다.
- count 로우은 총 데이터의 개수
- unique는 데이터의 유형이 몇 개인지
- top은 가장 많이 나온 요소가 무엇인지
- freq는 top 빈도가 몇 번인지
- loc 함수로 row 별 검색이 가능하다.
- Series로 변경하기 위해 label 컬럼을 지정한 후, value_counts()를 이용해 각 범주별 개수를 구할 수 있다.

- collection 함수

- Counter 함수를 통해 각 범주별 자료 개수 도출

- most_common() : 갯수순으로 나열해줌

- 데이터프레임에도 Counter함수를 쓸 수 있다.
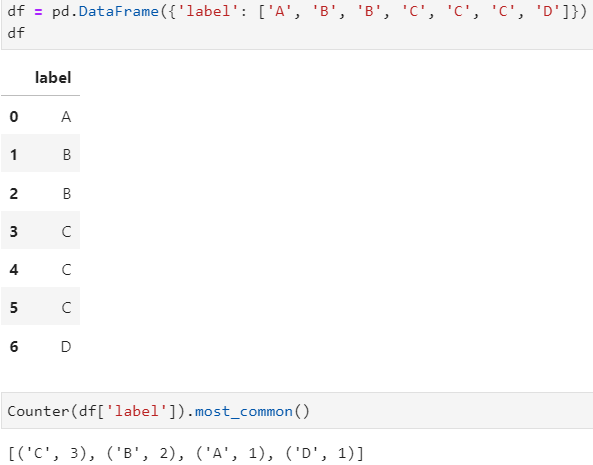
- Counter 함수를 통해 각 범주별 자료 개수 도출
- 활용 가능 함수들
데이터 단위 통일
표준화(Standardization)
- 평균을 기준으로 얼마나 떨어져 있는지를 파악
- sklearn에서 제공하는 전처리 클래스
- preprocessing 클래스
- scaler() : 전체 자료의 분포를 평균 0, 표준편차 1이 되도록 스케일링
- minmax_scale() : 최대/최소값이 각각 1, 0이 되도록 스케일링
- StandardScaler() : scaler() 함수와 동일한 동작
- preprocessing 클래스
- 표준화 : (요소값(하나의 데이터) - 평균) / 표준편차
- 삼성전자 vs 작은회사 주식 시세
- 몸무게 vs 키
- 표준화 결과 : 몸무게 음수, 키 양수
- 해석 : 몸무게는 평균 이하, 키는 평균 이상(=>마른몸)
- 전처리 기능을 제공하는 scikitlearn 라이브러리 및 모듈 가져오기 및 배열 생성
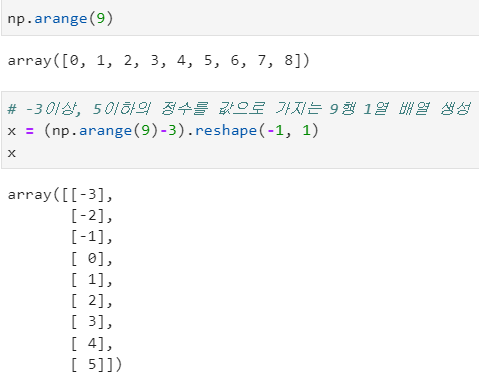
- x의 타입은 Array이다.
- scale(x) 역시 numpy Array이다.
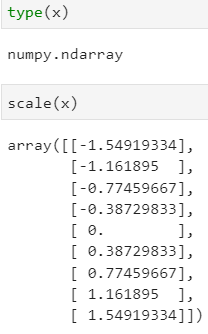
- scale(x) 역시 numpy Array이다.
- 데이터프레임 생성 (3개 컬럼 : x, scale(x), minmax_scale(x))
- scaler() : 전체 자료의 분포를 평균 0, 표준편차 1이 되도록 스케일링
- minmax_scale() : 최대/최소값이 각각 1, 0이 되도록 스케일링
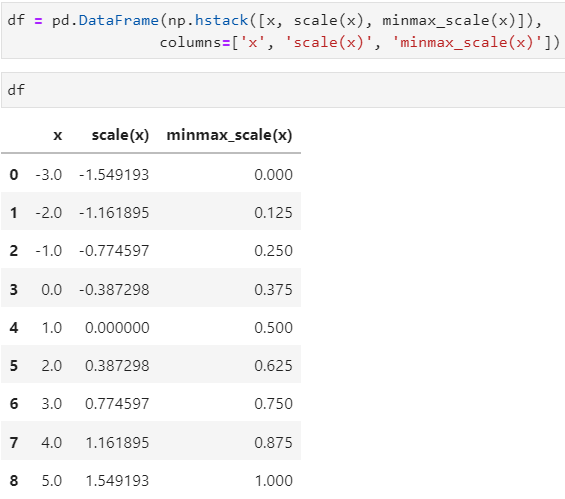
- x의 타입은 Array이다.
scale(x)에 대하여
자료값에 따르면
평균 : 1
표준편차 : 2.73 / 실제 표준편차 값 : 2.738613
2.73을 1로 보면 0.387만큼 떨어져있다.
그럼 실제 스케일로 보면 0.387 * 2.73 = 1.05651
: 왜 1과 차이가 나는가? 구체적 수치로 해봐도 차이가 난다.
- 아마 계산에 있어서 이런 차이가 발생하는 것은 내부적 계산에 있어서 어떤 보정이 작용하였을 것이라는 생각이 든다. 일단 우리가 일반적으로 알고 있는 평균과 표준편차를 통해 계산한 비율 변환과 차이가 난다. 왜인지 알게 되면 다시 적기로 한다.
