
타이타닉 데이터 전처리하기
데이터 적재
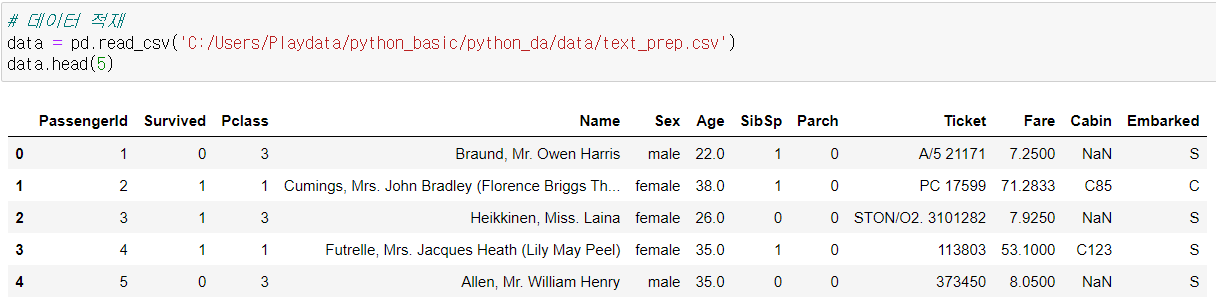
- 컬럼 목록을 불러와서 컬럼 목록을 대문자로 만들어보자.
- 방법은 여러가지가 있다.
- .map(), rename()

- 결과
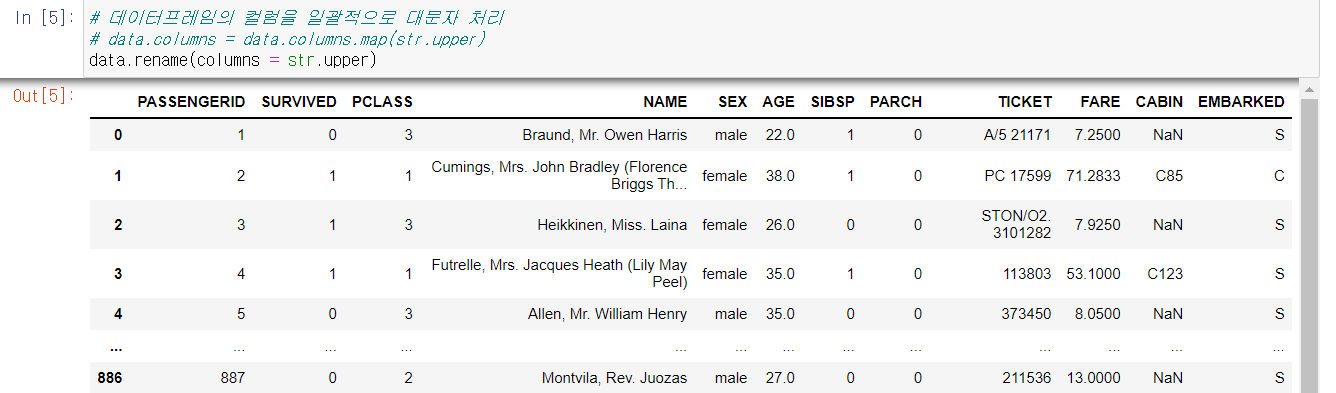
- .map(), rename()
- 방법은 여러가지가 있다.
map() / apply()
-
데이터프레임 / 시리즈 데이터타입에 대해서 함수 적용(동일한 작업을 반복)
- 각 컬럼
- 각 로우
-
가설1 : 혹시 성별과 생존율과의 상관관계가 있는가?(성별 전처리)
-
성별 컬럼 변경 : 남자를 0, 여자를 1로 가지는 컬럼 추가하기.
-
역시 여러가지 방법이 있다.
-
방법 1 : 딕셔너리 이용법 {'male':0, ....}
- data['sex_num'] = data['Sex'].map({'male':0, 'female':1})
-
방법 2 : 함수를 선언해 각 로우값을 리턴하는 방법
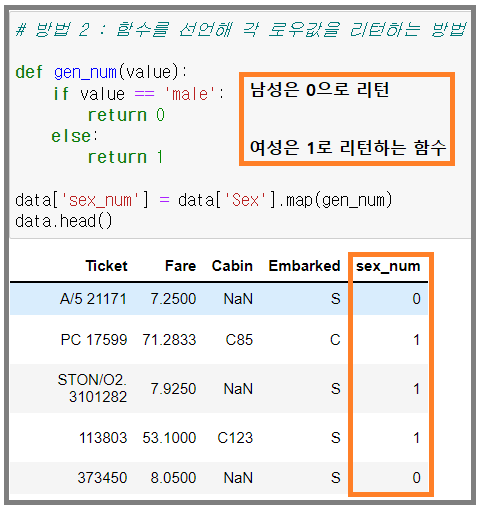
-
새로운 컬럼을 생성하여 해당 값을 부여하였다. 전처리 시 가급적 원본은 보존하는 것이 현명하다.
-
-
-
가설2 : 이름의 길이와 생존율과 상관관계가 있는가?(이름 전처리)
- 이름 길이 컬럼을 만들고 (스칼라 처리)
- 자체 함수 제작 (내가 짠 코드)
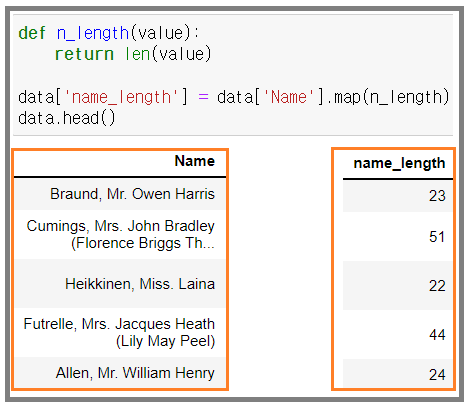
- 더 효율적인 코드(함수 필요없이 직접 조작 가능)

- 이름 길이 컬럼을 만들고 (스칼라 처리)
-
가설 분석
- Survived : 0은 사망 / 1은 생존
성별 : 0은 남자 / 1은 여자
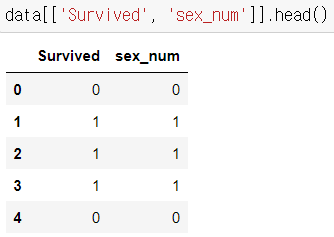
- Survived : 0은 사망 / 1은 생존
-
성별이 영향을 줬는지 여부 확인하기
- 상관계수를 구하면 컬럼간 관계를 유추할 수 있습니다.
- 0.5 정도면 꽤나 상관관계가 있다고 판단할 수 있다.
- 0.3 정도면 통계학에서는 무관한 것으로 판단한다.
- 0.9 정도는 다중공산성을 의심해야 한다.
- 상관관계 분석
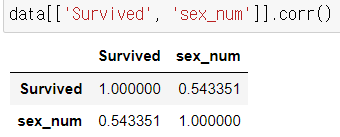
- 0.5이상의 결과값으로 보아 성별과 생존 간 연관성이 큰 것을 알 수 있다.
- 나머지 가설이었던 이름 길이에 관한 가설은 연관성이 떨어지는 것을 알 수 있다.
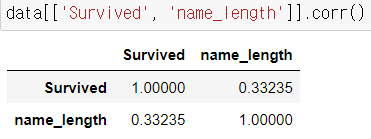
- 상관계수를 구하면 컬럼간 관계를 유추할 수 있습니다.
-
가설3 : 그렇다면 요금과의 상관도는 어떨까?
- fare 데이터를 소수점 첫 번째 자리에서 반올림한 실수형으로 표기를 변경 후 새로운 컬럼으로 추가(fare_ceil)
- 파이썬 내장함수 : round()
- numpy 함수 : np.ceil()
- fare_ceil 컬럼에 반올림한 데이터를 채우고 전처리
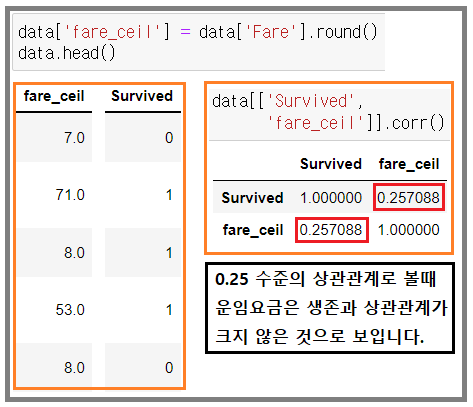
- fare_ceil 컬럼에 반올림한 데이터를 채우고 전처리
-
가설4 : 나이는 생존율과 상관관계가 있을까?
- 상관관계 분석
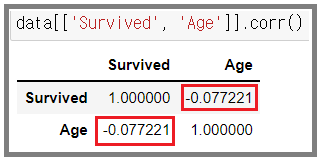
- 마이너스 값이 미약하게 나오는 것으로 보아 역의 관계가 있지만 상관관계는 딱히 없다는 것을 알 수 있다.
- 하지만 노약자를 보호하는 인간의 본성을 생각해볼때 그래프가 U자형으로 이루어져 상관도가 낮게 나왔을 가능성도 배제할 수 없다.
- 즉 연령대별로 분석도 해 볼 필요가 있다.
- 내가 짠 코드

- 하지만 추가로 인덱싱하는 것이 더 빠르다.
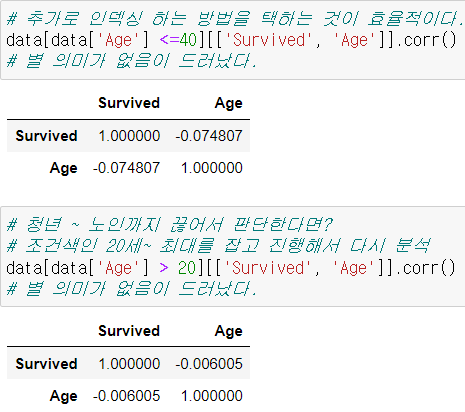
- 큰 의미가 없었다고 한다.
- 상관관계 분석

가즈아~