- Jupyter Notebook 실행
jupyter notebook과 mysql 모두 같은(sql_ws) 폴더에서 시작
Python으로 MySql 접속 후 사용하는 방법
- Python에서 MySql을 사용하기 위해서는 먼저 MySql Driver를 설치한다.
pip install mysql-connector-python- 설치 확인
import mysql.connector- MySQl에 접속하기 위한 코드
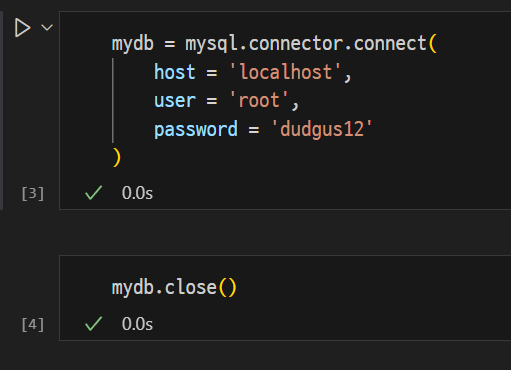
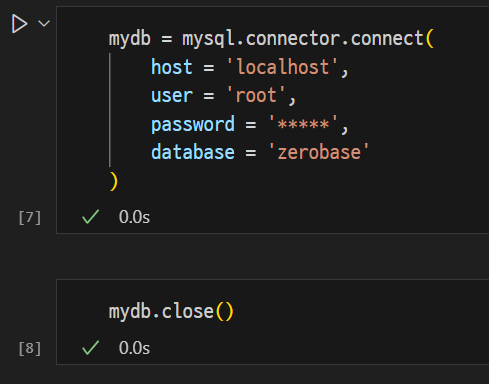
mydb = mysql.connector.connect(
host = '<hostname>',
user = '<username>',
password = '<password>'-
local DB 연결
-
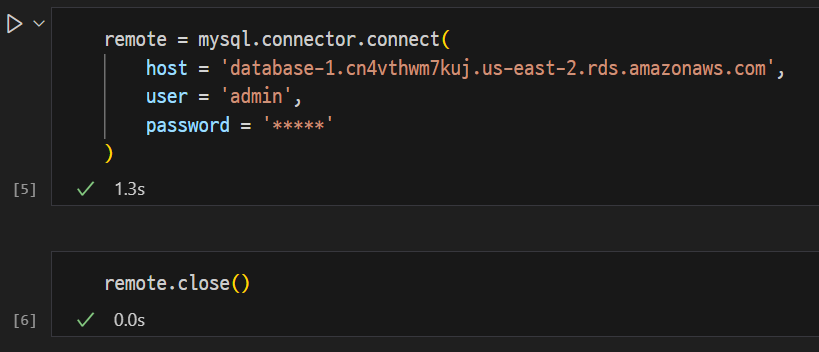
AWS RDS DB 연결
-
쿼리를 실행하기 위한 코드 (테이블 생성, 삭제)
cur = remote.cursor()
cur.execute('CREATE TABLE sql_file (id int, filename varchar(16))')remote = mysql.connector.connect(
host = 'database-1.cn4vthwm7kuj.us-east-2.rds.amazonaws.com',
user = 'admin',
password = '******',
database = 'zerobase'
)
cur = remote.cursor()
cur.execute('DROP TABLE sql_file')
remote.close()SQL File을 실행하는 코드
remote = mysql.connector.connect(
host = 'database-1.cn4vthwm7kuj.us-east-2.rds.amazonaws.com',
user = 'admin',
password = '******',
database = 'zerobase'
)
cur = remote.cursor()
sql = open('test_03.sql').read()
cur.execute(sql)
remote.close()- SQL File 내에 쿼리가 여러 개 존재하는 경우
remote = mysql.connector.connect(
host = 'database-1.cn4vthwm7kuj.us-east-2.rds.amazonaws.com',
user = 'admin',
password = '******',
database = 'zerobase'
)
cur = remote.cursor()
sql = open('test_04.sql').read()
for result_iterator in cur.execute(sql, multi=True):
if result_iterator.with_rows:
print(result_iterator.fetchall())
else:
print(result_iterator.statement)
remote.commit()
remote.close()Fetch All
sql_file 테이블 조회
cur = remote.cursor(buffered=True)
cur.execute("SELECT * FROM sql_file")
result = cur.fetchall()
for result_iterator in result:
print(result_iterator)Read CSV
import pandas as pd
df = df.read_csv('police_station.csv')
df.head()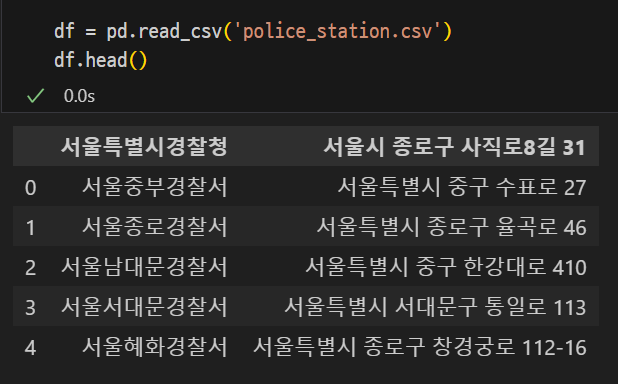
읽어올 양이 많은 경우 cursor 생성 시 buffer 설정을 해준다.
remote = mysql.connector.connect(
host = 'database-1.cn4vthwm7kuj.us-east-2.rds.amazonaws.com',
user = 'admin',
password = '******',
database = 'zerobase'
)
cur = remote.cursor(buffered=True)
sql = 'insert into police_station values (%s,%s)'
for i, row in df.iterrows():
cur.execute(sql,tuple(row))
print(tuple(row))
remote.commit()
remote.close()cur = remote.cursor(buffered=True)
cur.execute('select * from police_station')
result = cur.fetchall()
result
df = pd.DataFrame(result)
df.head()

씨앗 데이터 분석가.