최댓값
최댓값 알고리즘(Maximum Algorithm)은 주어진 집합(set) 또는 리스트(list)에서 가장 큰 값을 찾는 알고리즘이다.
주어진 데이터 집합에서 가장 큰 값을 찾아서 반환하는데, 이를 수행하기 위해서는 먼저 데이터 집합의 첫 번째 값을 최댓값으로 설정한다. 그리고 나서 데이터 집합을 처음부터 끝까지 순회하면서 각 원소를 현재 최댓값과 비교합니다. 만약 현재 원소가 최댓값보다 크다면, 최댓값을 해당 원소로 변경한다. 데이터 집합을 모두 순회한 후 최종적으로 최댓값을 반환한다.
데이터 집합의 크기가 작은 경우에는 빠른 성능을 보이지만 데이터 집합의 크기가 매우 큰 경우에는 성능 문제가 발생할 수 있다.
1. 루프를 이용한 방법
루프를 이용한 방법은 주어진 리스트에서 가장 큰 값을 찾는 가장 기본적인 방법이다. 이 방법은 리스트의 처음부터 끝까지 반복하면서 현재까지 찾은 최댓값을 기록하고, 새로운 값이 현재 최댓값보다 크면 최댓값을 업데이트하는 방식이다.
def find_max(numbers):
max_num = numbers[0] # 첫 번째 값을 최댓값으로 설정
for num in numbers:
if num > max_num: # 현재 원소가 최댓값보다 크다면
max_num = num # 최댓값을 해당 원소로 변경
return max_num2. 내장함수 max()를 이용한 방법
파이썬은 max()라는 내장함수를 제공한다. 이 함수를 이용하면 간단하게 주어진 리스트에서 최댓값을 찾을 수 있다.
def max_algorithm(lst):
return max(lst)최솟값
최댓값과 반대로 가장 적은 값을 찾는 알고리즘.
def find_min(numbers):
min_num = numbers[0] # 첫 번째 값을 최솟값으로 설정
for num in numbers:
if num < min_num: # 현재 원소가 최솟값보다 작다면
min_num = num # 최솟값을 해당 원소로 변경
return min_numnumbers = [3, 1, 4, 2, 5]
min_num = min(numbers)
print(min_num) # 출력 결과: 1최빈값
최빈값 알고리즘은 주어진 데이터 집합에서 가장 빈번하게 등장하는 값, 즉 최빈값을 찾는 알고리즘이다. 예를 들어, 주어진 데이터가 [1, 2, 3, 2, 4, 2, 5, 2]와 같은 경우, 최빈값은 2이다. 최빈값은 통계학이나 데이터 분석에서 많이 사용되는 개념 중 하나로, 데이터의 특성을 파악하는 데 중요한 역할을 한다.
최빈값 알고리즘을 구현하는 방법은 여러 가지가 있지만, 가장 기본적인 방법은 주어진 데이터에서 각 숫자가 몇 번 등장했는지를 세는 것이다. 이를 위해서는 반복문을 사용하여 각 숫자가 몇 번 등장했는지를 세면 된다. 그리고 가장 많이 등장한 숫자를 찾으면 최빈값을 구할 수 있다.
def mode(numbers):
counts = {} # 각 숫자가 등장한 횟수를 저장하는 딕셔너리
for num in numbers:
if num in counts:
counts[num] += 1
else:
counts[num] = 1
mode_num = None # 최빈값을 저장할 변수
max_count = 0 # 최빈값의 등장 횟수를 저장할 변수
for num, count in counts.items():
if count > max_count:
mode_num = num
max_count = count
return mode_num입력: 숫자 리스트 numbers
출력: 최빈값 mode_num
- 빈 딕셔너리 counts를 생성한다.
- numbers의 모든 요소 num에 대해서 다음을 반복한다.
- 만약 num이 counts의 키(key)에 있다면, 해당 값을 1 증가시킨다.
- 그렇지 않으면, num을 counts의 새로운 키로 추가하고 값을 1로 설정한다.
- 최빈값 mode_num을 저장할 변수 mode_num을 None으로 초기화한다.
- 최빈값의 등장 횟수를 저장할 변수 max_count를 0으로 초기화한다.
- counts의 모든 키-값 쌍 (num, count)에 대해서 다음을 반복한다.
- 만약 count가 max_count보다 크다면, mode_num을 num으로 설정하고 max_count를 count로 갱신한다.
- mode_num을 반환한다.
mode() 함수를 이용하여 간단하게 최빈값을 출력할 수 있다.
import statistics
data = [1, 2, 3, 2, 4, 2, 5, 2]
mode_num = statistics.mode(data)
print(mode_num) # 출력 결과: 2연습 문제
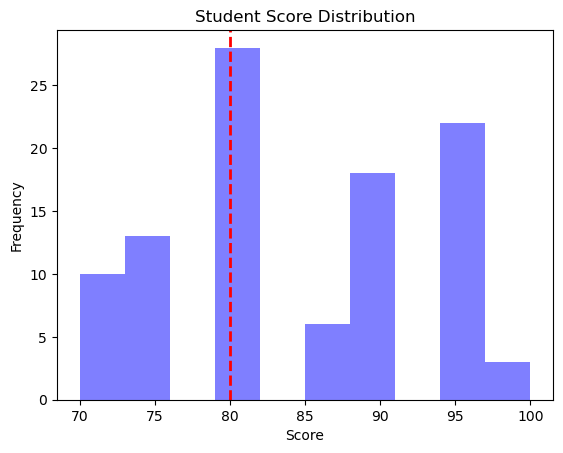
최빈값 알고리즘을 이용해서 학생 100명의 점수 분포 나타내기
[80, 90, 75, 95, 80, 90, 95, 95, 80, 95, 80, 75, 80, 90, 95, 80, 95, 95, 95, 90, 90, 80, 95, 80, 70, 95, 75, 75, 70, 90, 90, 70, 70, 90, 95, 95, 80, 75, 100, 95, 85, 80, 75, 90, 70, 80, 80, 80, 90, 80, 90, 95, 95, 85, 70, 90, 85, 95, 75, 70, 80, 75, 80, 80, 90, 85, 95, 90, 90, 75, 80, 70, 95, 85, 90, 80, 100, 90, 80, 80, 75, 80, 85, 80, 90, 95, 95, 70, 75, 95, 80, 80, 75, 95, 80, 70, 100, 75, 80, 80]
import matplotlib.pyplot as plt
def mode(numbers):
counts = {} # 각 숫자가 등장한 횟수를 저장하는 딕셔너리
for num in numbers:
if num in counts:
counts[num] += 1
else:
counts[num] = 1
mode_num = None # 최빈값을 저장할 변수
max_count = 0 # 최빈값의 등장 횟수를 저장할 변수
for num, count in counts.items():
if count > max_count:
mode_num = num
max_count = count
return mode_num
# 학생 점수 리스트
scores = [80, 90, 75, 95, 80, 90, 95, 95, 80, 95, 80, 75, 80, 90, 95, 80, 95, 95, 95, 90, 90, 80, 95, 80, 70, 95, 75,
75, 70, 90, 90, 70, 70, 90, 95, 95, 80, 75, 100, 95, 85, 80, 75, 90, 70, 80, 80, 80, 90, 80, 90, 95, 95, 85,
70, 90, 85, 95, 75, 70, 80, 75, 80, 80, 90, 85, 95, 90, 90, 75, 80, 70, 95, 85, 90, 80, 100, 90, 80, 80, 75,
80, 85, 80, 90, 95, 95, 70, 75, 95, 80, 80, 75, 95, 80, 70, 100, 75, 80, 80]
# 최빈값 계산
mode_score = mode(scores)
# 히스토그램 그리기
plt.hist(scores, bins=10, alpha=0.5, color='b')
plt.axvline(x=mode_score, color='r', linestyle='dashed', linewidth=2)
plt.title("Student Score Distribution")
plt.xlabel("Score")
plt.ylabel("Frequency")
plt.show()
근삿값
근삿값 알고리즘은 수치해석에서 사용되는 방법 중 하나로, 함수의 근사치를 구하는 알고리즘이다. 특정 값(참값)에 가장 가까운 값.
근삿값을 구하는 알고리즘은 다양하게 있다.
1. 이분법
def bisection(f, a, b, tolerance=0.0001):
"""
이분법을 이용하여 함수 f의 근사값을 구하는 함수
:param f: 근을 구하려는 함수
:param a: 탐색 구간의 왼쪽 끝 값
:param b: 탐색 구간의 오른쪽 끝 값
:param tolerance: 허용 오차
:return: f(x)=0 인 x 값
"""
# 탐색 구간의 중간값을 구한다.
c = (a + b) / 2
# 허용 오차보다 작아질 때까지 탐색한다.
while abs(f(c)) > tolerance:
# 중간값의 부호와 왼쪽 끝 값의 부호가 같으면 왼쪽 구간을 버리고 오른쪽 구간으로 이동한다.
if f(c) * f(a) > 0:
a = c
# 중간값의 부호와 오른쪽 끝 값의 부호가 같으면 오른쪽 구간을 버리고 왼쪽 구간으로 이동한다.
elif f(c) * f(b) > 0:
b = c
# 중간값이 근사값이므로 반환한다.
else:
return c
# 탐색 구간의 중간값을 다시 구한다.
c = (a + b) / 2
return c
def f(x):
return x**2 - 2
root = bisection(f, 0, 2, 0.0001)
print(root) # 1.414215087890625
2. 뉴턴-래프슨 방법
def newton_raphson(f, df, x0, tol=1e-6, max_iter=100):
"""
주어진 함수 f와 도함수 df, 초기값 x0를 이용하여 뉴턴-래프슨 방법으로 근을 찾는 함수
f: 찾고자 하는 근을 가지고 있는 함수
df: f의 도함수
x0: 초기값
tol: 허용 오차
max_iter: 최대 반복 횟수
return: f(x) = 0인 x값(근)
"""
i = 0
while i < max_iter:
x1 = x0 - f(x0) / df(x0) # 뉴턴-래프슨 공식
if abs(x1 - x0) < tol:
return x1
x0 = x1
i += 1
return x0 # 최대 반복 횟수에 도달한 경우 마지막 x값 반환
3. for문
def approximate_root(f, a, b, n):
"""
함수 f와 구간 [a, b], 시도할 값의 개수 n을 받아서
이분법을 이용해 f(x) = 0인 근사값 x를 찾아 반환하는 함수
"""
# 이분법을 시작하기 전, f(a)와 f(b)의 부호가 같은지 확인
if f(a) * f(b) > 0:
return None
# n개의 시도값으로 이분법 수행
for i in range(n):
x = (a + b) / 2
if f(x) == 0:
return x
elif f(a) * f(x) < 0:
b = x
else:
a = x
# n번의 시도 동안 근사값을 찾지 못한 경우, None 반환
return None